 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgexPQA: Cross-Lingual Product Question Answering across 12 Languages
May 16, 2023Product Question Answering (PQA) systems are key in e-commerce applications to provide responses to customers' questions as they shop for products. While existing work on PQA focuses mainly on English, in practice there is need to support multiple customer languages while leveraging product information available in English. To study this practical industrial task, we present xPQA, a large-scale annotated cross-lingual PQA dataset in 12 languages across 9 branches, and report results in (1) candidate ranking, to select the best English candidate containing the information to answer a non-English question; and (2) answer generation, to generate a natural-sounding non-English answer based on the selected English candidate. We evaluate various approaches involving machine translation at runtime or offline, leveraging multilingual pre-trained LMs, and including or excluding xPQA training data. We find that (1) In-domain data is essential as cross-lingual rankers trained on other domains perform poorly on the PQA task; (2) Candidate ranking often prefers runtime-translation approaches while answer generation prefers multilingual approaches; (3) Translating offline to augment multilingual models helps candidate ranking mainly on languages with non-Latin scripts; and helps answer generation mainly on languages with Latin scripts. Still, there remains a significant performance gap between the English and the cross-lingual test sets.
AfriQA: Cross-lingual Open-Retrieval Question Answering for African Languages
May 11, 2023



African languages have far less in-language content available digitally, making it challenging for question answering systems to satisfy the information needs of users. Cross-lingual open-retrieval question answering (XOR QA) systems -- those that retrieve answer content from other languages while serving people in their native language -- offer a means of filling this gap. To this end, we create AfriQA, the first cross-lingual QA dataset with a focus on African languages. AfriQA includes 12,000+ XOR QA examples across 10 African languages. While previous datasets have focused primarily on languages where cross-lingual QA augments coverage from the target language, AfriQA focuses on languages where cross-lingual answer content is the only high-coverage source of answer content. Because of this, we argue that African languages are one of the most important and realistic use cases for XOR QA. Our experiments demonstrate the poor performance of automatic translation and multilingual retrieval methods. Overall, AfriQA proves challenging for state-of-the-art QA models. We hope that the dataset enables the development of more equitable QA technology.
How to Train Your DRAGON: Diverse Augmentation Towards Generalizable Dense Retrieval
Feb 15, 2023Various techniques have been developed in recent years to improve dense retrieval (DR), such as unsupervised contrastive learning and pseudo-query generation. Existing DRs, however, often suffer from effectiveness tradeoffs between supervised and zero-shot retrieval, which some argue was due to the limited model capacity. We contradict this hypothesis and show that a generalizable DR can be trained to achieve high accuracy in both supervised and zero-shot retrieval without increasing model size. In particular, we systematically examine the contrastive learning of DRs, under the framework of Data Augmentation (DA). Our study shows that common DA practices such as query augmentation with generative models and pseudo-relevance label creation using a cross-encoder, are often inefficient and sub-optimal. We hence propose a new DA approach with diverse queries and sources of supervision to progressively train a generalizable DR. As a result, DRAGON, our dense retriever trained with diverse augmentation, is the first BERT-base-sized DR to achieve state-of-the-art effectiveness in both supervised and zero-shot evaluations and even competes with models using more complex late interaction (ColBERTv2 and SPLADE++).
When Not to Trust Language Models: Investigating Effectiveness and Limitations of Parametric and Non-Parametric Memories
Dec 20, 2022Despite their impressive performance on diverse tasks, large language models (LMs) still struggle with tasks requiring rich world knowledge, implying the limitations of relying solely on their parameters to encode a wealth of world knowledge. This paper aims to understand LMs' strengths and limitations in memorizing factual knowledge, by conducting large-scale knowledge probing experiments of 10 models and 4 augmentation methods on PopQA, our new open-domain QA dataset with 14k questions. We find that LMs struggle with less popular factual knowledge, and that scaling fails to appreciably improve memorization of factual knowledge in the tail. We then show that retrieval-augmented LMs largely outperform orders of magnitude larger LMs, while unassisted LMs remain competitive in questions about high-popularity entities. Based on those findings, we devise a simple, yet effective, method for powerful and efficient retrieval-augmented LMs, which retrieves non-parametric memories only when necessary. Experimental results show that this significantly improves models' performance while reducing the inference costs.
Beyond Counting Datasets: A Survey of Multilingual Dataset Construction and Necessary Resources
Nov 28, 2022While the NLP community is generally aware of resource disparities among languages, we lack research that quantifies the extent and types of such disparity. Prior surveys estimating the availability of resources based on the number of datasets can be misleading as dataset quality varies: many datasets are automatically induced or translated from English data. To provide a more comprehensive picture of language resources, we examine the characteristics of 156 publicly available NLP datasets. We manually annotate how they are created, including input text and label sources and tools used to build them, and what they study, tasks they address and motivations for their creation. After quantifying the qualitative NLP resource gap across languages, we discuss how to improve data collection in low-resource languages. We survey language-proficient NLP researchers and crowd workers per language, finding that their estimated availability correlates with dataset availability. Through crowdsourcing experiments, we identify strategies for collecting high-quality multilingual data on the Mechanical Turk platform. We conclude by making macro and micro-level suggestions to the NLP community and individual researchers for future multilingual data development.
Task-aware Retrieval with Instructions
Nov 16, 2022We study the problem of retrieval with instructions, where users of a retrieval system explicitly describe their intent along with their queries, making the system task-aware. We aim to develop a general-purpose task-aware retrieval systems using multi-task instruction tuning that can follow human-written instructions to find the best documents for a given query. To this end, we introduce the first large-scale collection of approximately 40 retrieval datasets with instructions, and present TART, a multi-task retrieval system trained on the diverse retrieval tasks with instructions. TART shows strong capabilities to adapt to a new task via instructions and advances the state of the art on two zero-shot retrieval benchmarks, BEIR and LOTTE, outperforming models up to three times larger. We further introduce a new evaluation setup to better reflect real-world scenarios, pooling diverse documents and tasks. In this setup, TART significantly outperforms competitive baselines, further demonstrating the effectiveness of guiding retrieval with instructions.
RealTime QA: What's the Answer Right Now?
Jul 27, 2022
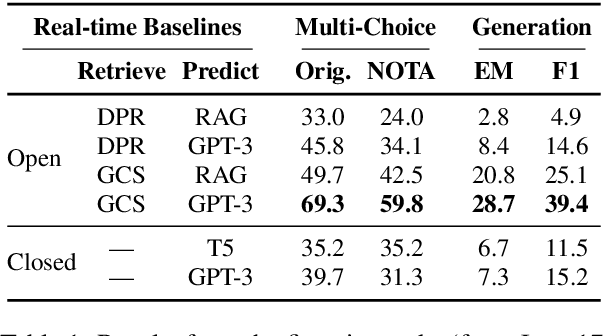
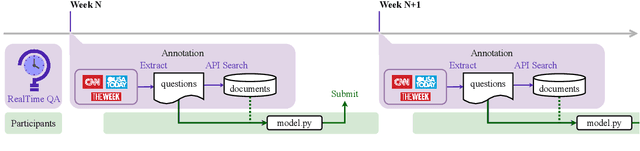
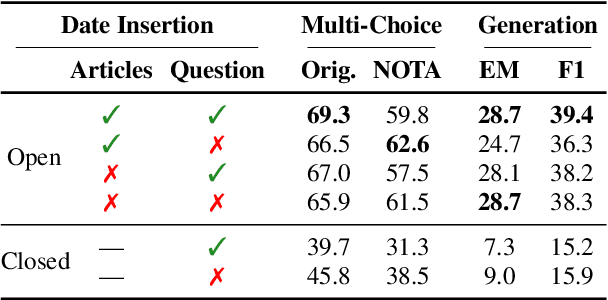
We introduce RealTime QA, a dynamic question answering (QA) platform that announces questions and evaluates systems on a regular basis (weekly in this version). RealTime QA inquires about the current world, and QA systems need to answer questions about novel events or information. It therefore challenges static, conventional assumptions in open domain QA datasets and pursues, instantaneous applications. We build strong baseline models upon large pretrained language models, including GPT-3 and T5. Our benchmark is an ongoing effort, and this preliminary report presents real-time evaluation results over the past month. Our experimental results show that GPT-3 can often properly update its generation results, based on newly-retrieved documents, highlighting the importance of up-to-date information retrieval. Nonetheless, we find that GPT-3 tends to return outdated answers when retrieved documents do not provide sufficient information to find an answer. This suggests an important avenue for future research: can an open domain QA system identify such unanswerable cases and communicate with the user or even the retrieval module to modify the retrieval results? We hope that RealTime QA will spur progress in instantaneous applications of question answering and beyond.
MIA 2022 Shared Task: Evaluating Cross-lingual Open-Retrieval Question Answering for 16 Diverse Languages
Jul 02, 2022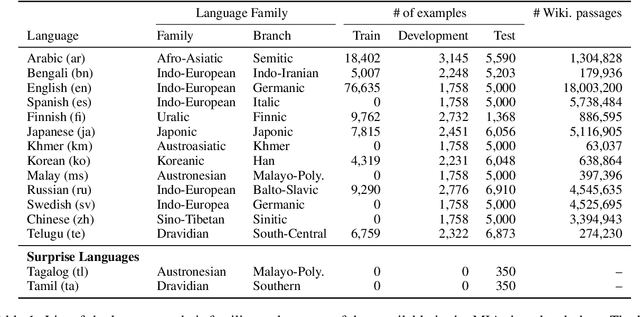
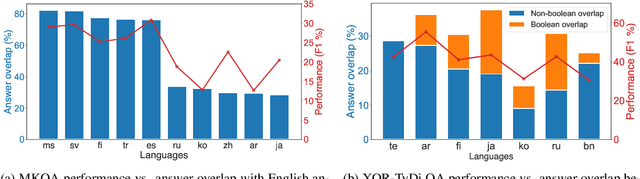
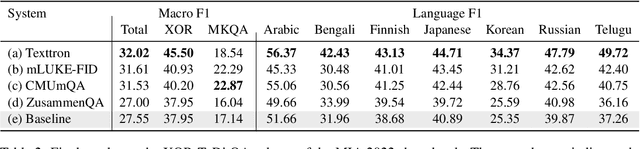
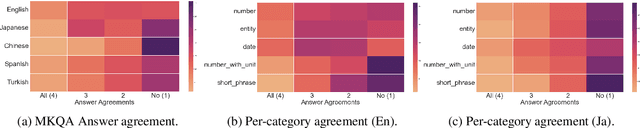
We present the results of the Workshop on Multilingual Information Access (MIA) 2022 Shared Task, evaluating cross-lingual open-retrieval question answering (QA) systems in 16 typologically diverse languages. In this task, we adapted two large-scale cross-lingual open-retrieval QA datasets in 14 typologically diverse languages, and newly annotated open-retrieval QA data in 2 underrepresented languages: Tagalog and Tamil. Four teams submitted their systems. The best system leveraging iteratively mined diverse negative examples and larger pretrained models achieves 32.2 F1, outperforming our baseline by 4.5 points. The second best system uses entity-aware contextualized representations for document retrieval, and achieves significant improvements in Tamil (20.8 F1), whereas most of the other systems yield nearly zero scores.
Attentional Mixtures of Soft Prompt Tuning for Parameter-efficient Multi-task Knowledge Sharing
May 24, 2022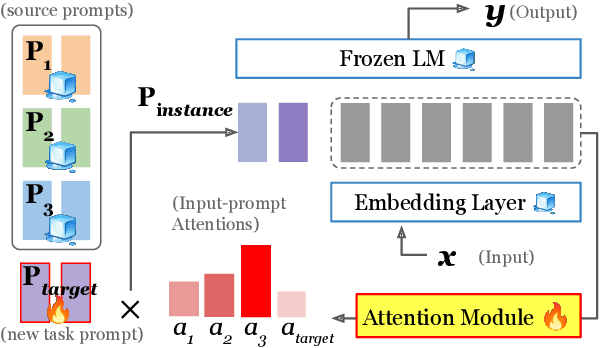

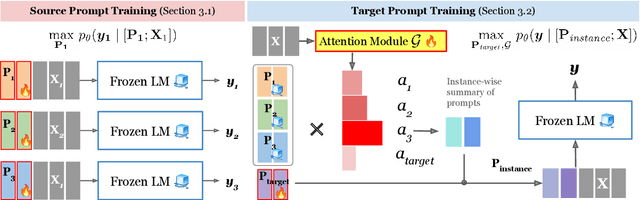
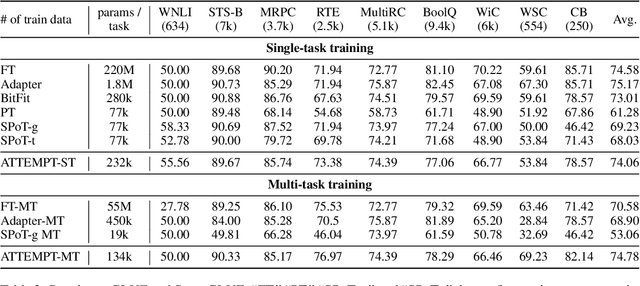
This work introduces ATTEMPT (Attentional Mixture of Prompt Tuning), a new modular, multi-task, and parameter-efficient language model (LM) tuning approach that combines knowledge transferred across different tasks via a mixture of soft prompts while keeping original LM unchanged. ATTEMPT interpolates a set of prompts trained on large-scale source tasks and a newly initialized target task prompt using instance-wise attention computed by a lightweight sub-network trained on multiple target tasks. ATTEMPT is parameter-efficient (e.g., updates 1,600 times fewer parameters than fine-tuning) and enables multi-task learning and flexible extensions; importantly, it is also more interpretable because it demonstrates which source tasks affect the final model decision on target tasks. Experimental results across 17 diverse datasets show that ATTEMPT improves prompt tuning by up to a 22% absolute performance gain and outperforms or matches fully fine-tuned or other parameter-efficient tuning approaches that use over ten times more parameters.
Evidentiality-guided Generation for Knowledge-Intensive NLP Tasks
Dec 16, 2021
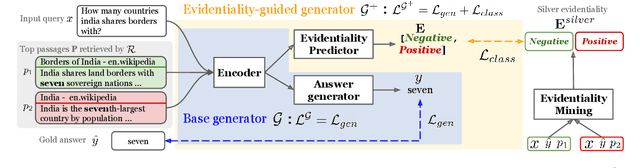
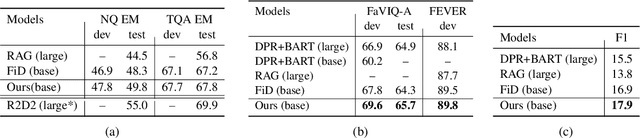
Retrieval-augmented generation models have shown state-of-the-art performance across many knowledge-intensive NLP tasks such as open question answering and fact verification. These models are trained to generate the final output given the retrieved passages, which can be irrelevant to the original query, leading to learning spurious cues or answer memorization. This work introduces a method to incorporate evidentiality of passages -- whether a passage contains correct evidence to support the output -- into training the generator. We introduce a multi-task learning framework to jointly generate the final output and predict the evidentiality of each passage, leveraging a new task-agnostic method to obtain {\it silver} evidentiality labels for supervision. Our experiments on five datasets across three knowledge-intensive tasks show that our new evidentiality-guided generator significantly outperforms its direct counterpart with the same-size model and advances the state of the art on FaVIQ-Ambig. We attribute these improvements to both the auxiliary multi-task learning and silver evidentiality mining techniques.