 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking and Rethinking Knowledge Editing for Large Language Models
May 24, 2025Knowledge editing aims to update the embedded knowledge within Large Language Models (LLMs). However, existing approaches, whether through parameter modification or external memory integration, often suffer from inconsistent evaluation objectives and experimental setups. To address this gap, we conduct a comprehensive benchmarking study. In addition to fact-level datasets, we introduce more complex event-based datasets and general-purpose datasets drawn from other tasks. Our evaluation covers both instruction-tuned and reasoning-oriented LLMs, under a realistic autoregressive inference setting rather than teacher-forced decoding. Beyond single-edit assessments, we also evaluate multi-edit scenarios to better reflect practical demands. We employ four evaluation dimensions, including portability, and compare all recent methods against a simple and straightforward baseline named Selective Contextual Reasoning (SCR). Empirical results reveal that parameter-based editing methods perform poorly under realistic conditions. In contrast, SCR consistently outperforms them across all settings. This study offers new insights into the limitations of current knowledge editing methods and highlights the potential of context-based reasoning as a more robust alternative.
Toward Embodied AGI: A Review of Embodied AI and the Road Ahead
May 20, 2025



Artificial General Intelligence (AGI) is often envisioned as inherently embodied. With recent advances in robotics and foundational AI models, we stand at the threshold of a new era-one marked by increasingly generalized embodied AI systems. This paper contributes to the discourse by introducing a systematic taxonomy of Embodied AGI spanning five levels (L1-L5). We review existing research and challenges at the foundational stages (L1-L2) and outline the key components required to achieve higher-level capabilities (L3-L5). Building on these insights and existing technologies, we propose a conceptual framework for an L3+ robotic brain, offering both a technical outlook and a foundation for future exploration.
Toward Generalizable Evaluation in the LLM Era: A Survey Beyond Benchmarks
Apr 26, 2025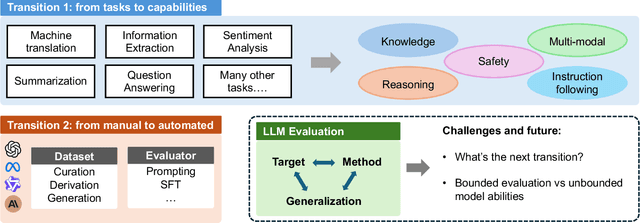
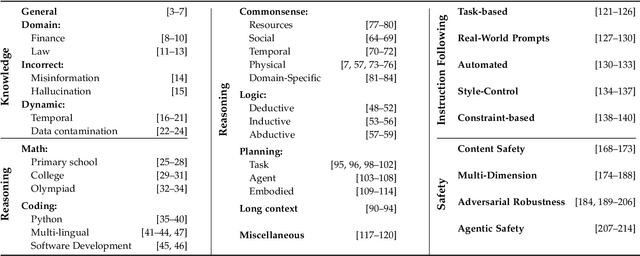
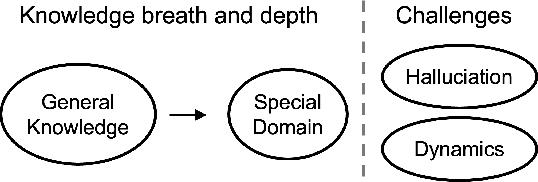
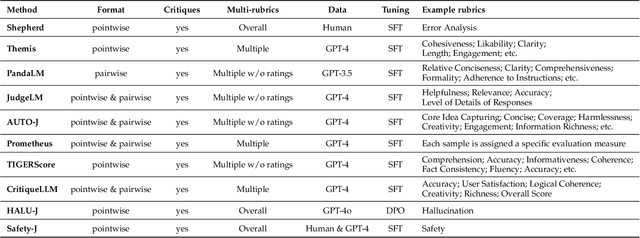
Large Language Models (LLMs) are advancing at an amazing speed and have become indispensable across academia, industry, and daily applications. To keep pace with the status quo, this survey probes the core challenges that the rise of LLMs poses for evaluation. We identify and analyze two pivotal transitions: (i) from task-specific to capability-based evaluation, which reorganizes benchmarks around core competencies such as knowledge, reasoning, instruction following, multi-modal understanding, and safety; and (ii) from manual to automated evaluation, encompassing dynamic dataset curation and "LLM-as-a-judge" scoring. Yet, even with these transitions, a crucial obstacle persists: the evaluation generalization issue. Bounded test sets cannot scale alongside models whose abilities grow seemingly without limit. We will dissect this issue, along with the core challenges of the above two transitions, from the perspectives of methods, datasets, evaluators, and metrics. Due to the fast evolving of this field, we will maintain a living GitHub repository (links are in each section) to crowd-source updates and corrections, and warmly invite contributors and collaborators.
If an LLM Were a Character, Would It Know Its Own Story? Evaluating Lifelong Learning in LLMs
Mar 30, 2025Large language models (LLMs) can carry out human-like dialogue, but unlike humans, they are stateless due to the superposition property. However, during multi-turn, multi-agent interactions, LLMs begin to exhibit consistent, character-like behaviors, hinting at a form of emergent lifelong learning. Despite this, existing benchmarks often fail to capture these dynamics, primarily focusing on static, open-ended evaluations. To address this gap, we introduce LIFESTATE-BENCH, a benchmark designed to assess lifelong learning in LLMs. It features two episodic datasets: Hamlet and a synthetic script collection, rich in narrative structure and character interactions. Our fact checking evaluation probes models' self-awareness, episodic memory retrieval, and relationship tracking, across both parametric and non-parametric approaches. Experiments on models like Llama3.1-8B, GPT-4-turbo, and DeepSeek R1, we demonstrate that nonparametric methods significantly outperform parametric ones in managing stateful learning. However, all models exhibit challenges with catastrophic forgetting as interactions extend, highlighting the need for further advancements in lifelong learning.
Are We Solving a Well-Defined Problem? A Task-Centric Perspective on Recommendation Tasks
Mar 27, 2025Recommender systems (RecSys) leverage user interaction history to predict and suggest relevant items, shaping user experiences across various domains. While many studies adopt a general problem definition, i.e., to recommend preferred items to users based on past interactions, such abstraction often lacks the domain-specific nuances necessary for practical deployment. However, models are frequently evaluated using datasets from online recommender platforms, which inherently reflect these specificities. In this paper, we analyze RecSys task formulations, emphasizing key components such as input-output structures, temporal dynamics, and candidate item selection. All these factors directly impact offline evaluation. We further examine the complexities of user-item interactions, including decision-making costs, multi-step engagements, and unobservable interactions, which may influence model design and loss functions. Additionally, we explore the balance between task specificity and model generalizability, highlighting how well-defined task formulations serve as the foundation for robust evaluation and effective solution development. By clarifying task definitions and their implications, this work provides a structured perspective on RecSys research. The goal is to help researchers better navigate the field, particularly in understanding specificities of the RecSys tasks and ensuring fair and meaningful evaluations.
Knowledge Updating? No More Model Editing! Just Selective Contextual Reasoning
Mar 07, 2025As real-world knowledge evolves, the information embedded within large language models (LLMs) can become outdated, inadequate, or erroneous. Model editing has emerged as a prominent approach for updating LLMs' knowledge with minimal computational costs and parameter changes. This approach typically identifies and adjusts specific model parameters associated with newly acquired knowledge. However, existing methods often underestimate the adverse effects that parameter modifications can have on broadly distributed knowledge. More critically, post-edit LLMs frequently struggle with multi-hop reasoning and continuous knowledge updates. Although various studies have discussed these shortcomings, there is a lack of comprehensive evaluation. In this paper, we provide an evaluation of ten model editing methods along four dimensions: reliability, generalization, locality, and portability. Results confirm that all ten popular model editing methods show significant shortcomings across multiple dimensions, suggesting model editing is less promising. We then propose a straightforward method called Selective Contextual Reasoning (SCR), for knowledge updating. SCR does not modify model parameters but harnesses LLM's inherent contextual reasoning capabilities utilizing the updated knowledge pieces. Under SCR, an LLM first assesses whether an incoming query falls within the scope of an external knowledge base. If it does, the relevant external knowledge texts are contextualized to enhance reasoning; otherwise, the query is answered directly. We evaluate SCR against the ten model editing methods on two counterfactual datasets with three backbone LLMs. Empirical results confirm the effectiveness and efficiency of contextual reasoning for knowledge updating.
A Flexible and Scalable Framework for Video Moment Search
Jan 09, 2025Video moment search, the process of finding relevant moments in a video corpus to match a user's query, is crucial for various applications. Existing solutions, however, often assume a single perfect matching moment, struggle with inefficient inference, and have limitations with hour-long videos. This paper introduces a flexible and scalable framework for retrieving a ranked list of moments from collection of videos in any length to match a text query, a task termed Ranked Video Moment Retrieval (RVMR). Our framework, called Segment-Proposal-Ranking (SPR), simplifies the search process into three independent stages: segment retrieval, proposal generation, and moment refinement with re-ranking. Specifically, videos are divided into equal-length segments with precomputed embeddings indexed offline, allowing efficient retrieval regardless of video length. For scalable online retrieval, both segments and queries are projected into a shared feature space to enable approximate nearest neighbor (ANN) search. Retrieved segments are then merged into coarse-grained moment proposals. Then a refinement and re-ranking module is designed to reorder and adjust timestamps of the coarse-grained proposals. Evaluations on the TVR-Ranking dataset demonstrate that our framework achieves state-of-the-art performance with significant reductions in computational cost and processing time. The flexible design also allows for independent improvements to each stage, making SPR highly adaptable for large-scale applications.
Long Context vs. RAG for LLMs: An Evaluation and Revisits
Dec 27, 2024



Extending context windows (i.e., Long Context, LC) and using retrievers to selectively access relevant information (i.e., Retrieval-Augmented Generation, RAG) are the two main strategies to enable LLMs to incorporate extremely long external contexts. This paper revisits recent studies on this topic, highlighting their key insights and discrepancies. We then provide a more comprehensive evaluation by filtering out questions answerable without external context, identifying the most effective retrieval methods, and expanding the datasets. We show that LC generally outperforms RAG in question-answering benchmarks, especially for Wikipedia-based questions. Summarization-based retrieval performs comparably to LC, while chunk-based retrieval lags behind. However, RAG has advantages in dialogue-based and general question queries. These insights underscore the trade-offs between RAG and LC strategies, offering guidance for future optimization of LLMs with external knowledge sources. We also provide an in-depth discussion on this topic, highlighting the overlooked importance of context relevance in existing studies.
Hesitation and Tolerance in Recommender Systems
Dec 13, 2024User interactions in recommender systems are inherently complex, often involving behaviors that go beyond simple acceptance or rejection. One particularly common behavior is hesitation, where users deliberate over recommended items, signaling uncertainty. Our large-scale surveys, with 6,644 and 3,864 responses respectively, confirm that hesitation is not only widespread but also has a profound impact on user experiences. When users spend additional time engaging with content they are ultimately uninterested in, this can lead to negative emotions, a phenomenon we term as tolerance. The surveys reveal that such tolerance behaviors often arise after hesitation and can erode trust, satisfaction, and long-term loyalty to the platform. For instance, a click might reflect a need for more information rather than genuine interest, and prolonged exposure to unsuitable content amplifies frustration. This misalignment between user intent and system interpretation introduces noise into recommendation training, resulting in suggestions that increase uncertainty and disengagement. To address these issues, we identified signals indicative of tolerance behavior and analyzed datasets from both e-commerce and short-video platforms. The analysis shows a strong correlation between increased tolerance behavior and decreased user activity. We integrated these insights into the training process of a recommender system for a major short-video platform. Results from four independent online A/B experiments demonstrated significant improvements in user retention, achieved with minimal additional computational costs. These findings underscore the importance of recognizing hesitation as a ubiquitous user behavior and addressing tolerance to enhance satisfaction, build trust, and sustain long-term engagement in recommender systems.
Knowledge-Enhanced Conversational Recommendation via Transformer-based Sequential Modelling
Dec 03, 2024



In conversational recommender systems (CRSs), conversations usually involve a set of items and item-related entities or attributes, e.g., director is a related entity of a movie. These items and item-related entities are often mentioned along the development of a dialog, leading to potential sequential dependencies among them. However, most of existing CRSs neglect these potential sequential dependencies. In this article, we first propose a Transformer-based sequential conversational recommendation method, named TSCR, to model the sequential dependencies in the conversations to improve CRS. In TSCR, we represent conversations by items and the item-related entities, and construct user sequences to discover user preferences by considering both the mentioned items and item-related entities. Based on the constructed sequences, we deploy a Cloze task to predict the recommended items along a sequence. Meanwhile, in certain domains, knowledge graphs formed by the items and their related entities are readily available, which provide various different kinds of associations among them. Given that TSCR does not benefit from such knowledge graphs, we then propose a knowledge graph enhanced version of TSCR, called TSCRKG. In specific, we leverage the knowledge graph to offline initialize our model TSCRKG, and augment the user sequence of conversations (i.e., sequence of the mentioned items and item-related entities in the conversation) with multi-hop paths in the knowledge graph. Experimental results demonstrate that our TSCR model significantly outperforms state-of-the-art baselines, and the enhanced version TSCRKG further improves recommendation performance on top of TSCR.