 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLAS: Metric Learning on Attributed Sequences
Nov 08, 2020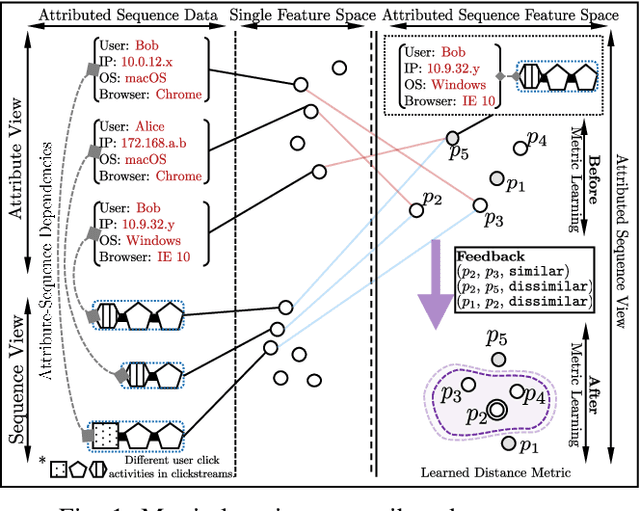
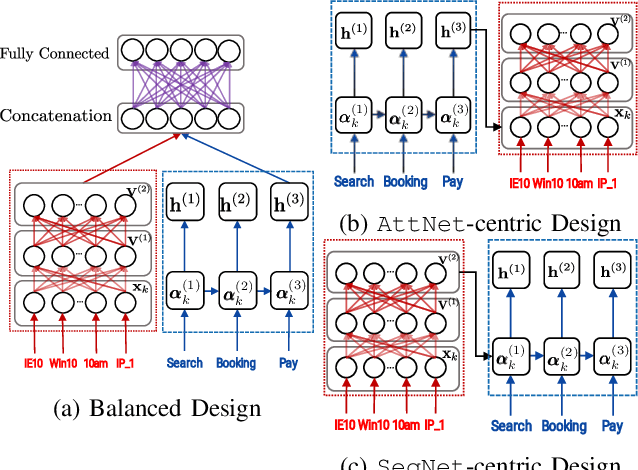
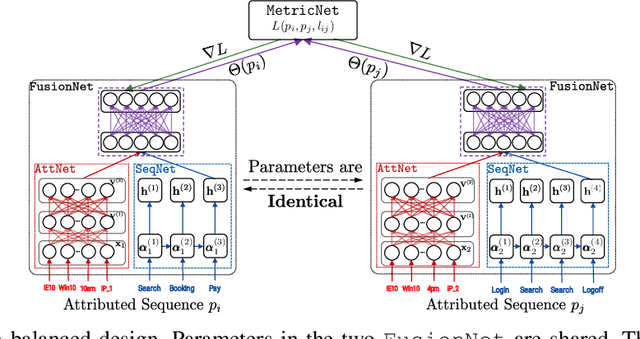

Distance metric learning has attracted much attention in recent years, where the goal is to learn a distance metric based on user feedback. Conventional approaches to metric learning mainly focus on learning the Mahalanobis distance metric on data attributes. Recent research on metric learning has been extended to sequential data, where we only have structural information in the sequences, but no attribute is available. However, real-world applications often involve attributed sequence data (e.g., clickstreams), where each instance consists of not only a set of attributes (e.g., user session context) but also a sequence of categorical items (e.g., user actions). In this paper, we study the problem of metric learning on attributed sequences. Unlike previous work on metric learning, we now need to go beyond the Mahalanobis distance metric in the attribute feature space while also incorporating the structural information in sequences. We propose a deep learning framework, called MLAS (Metric Learning on Attributed Sequences), to learn a distance metric that effectively measures dissimilarities between attributed sequences. Empirical results on real-world datasets demonstrate that the proposed MLAS framework significantly improves the performance of metric learning compared to state-of-the-art methods on attributed sequences.
AIM 2020 Challenge on Real Image Super-Resolution: Methods and Results
Sep 25, 2020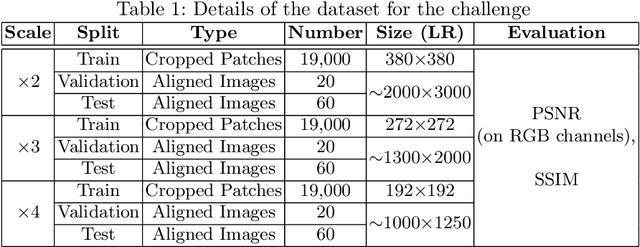
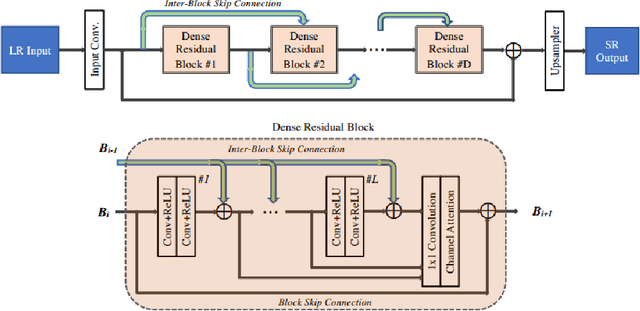
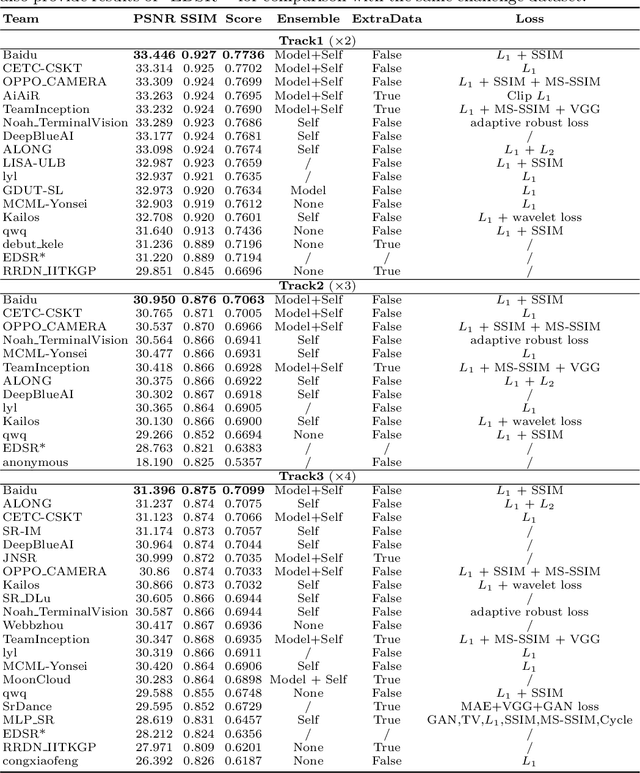
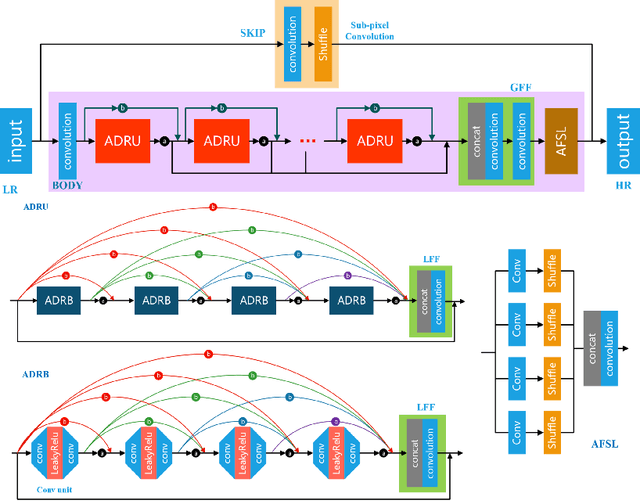
This paper introduces the real image Super-Resolution (SR) challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2020. This challenge involves three tracks to super-resolve an input image for $\times$2, $\times$3 and $\times$4 scaling factors, respectively. The goal is to attract more attention to realistic image degradation for the SR task, which is much more complicated and challenging, and contributes to real-world image super-resolution applications. 452 participants were registered for three tracks in total, and 24 teams submitted their results. They gauge the state-of-the-art approaches for real image SR in terms of PSNR and SSIM.
CycleISP: Real Image Restoration via Improved Data Synthesis
Mar 17, 2020
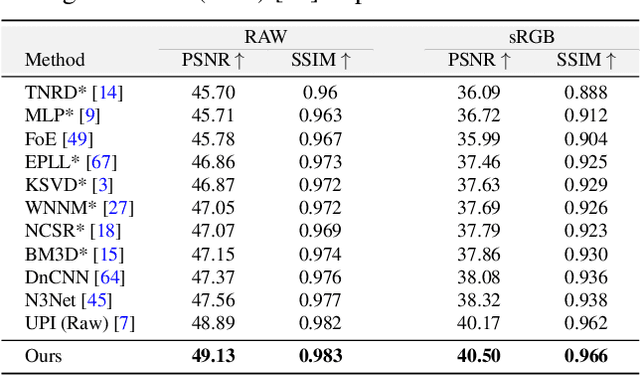
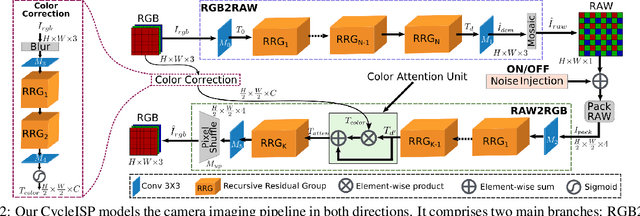
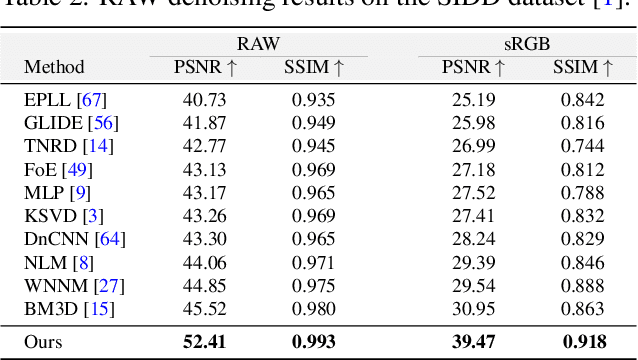
The availability of large-scale datasets has helped unleash the true potential of deep convolutional neural networks (CNNs). However, for the single-image denoising problem, capturing a real dataset is an unacceptably expensive and cumbersome procedure. Consequently, image denoising algorithms are mostly developed and evaluated on synthetic data that is usually generated with a widespread assumption of additive white Gaussian noise (AWGN). While the CNNs achieve impressive results on these synthetic datasets, they do not perform well when applied on real camera images, as reported in recent benchmark datasets. This is mainly because the AWGN is not adequate for modeling the real camera noise which is signal-dependent and heavily transformed by the camera imaging pipeline. In this paper, we present a framework that models camera imaging pipeline in forward and reverse directions. It allows us to produce any number of realistic image pairs for denoising both in RAW and sRGB spaces. By training a new image denoising network on realistic synthetic data, we achieve the state-of-the-art performance on real camera benchmark datasets. The parameters in our model are ~5 times lesser than the previous best method for RAW denoising. Furthermore, we demonstrate that the proposed framework generalizes beyond image denoising problem e.g., for color matching in stereoscopic cinema. The source code and pre-trained models are available at https://github.com/swz30/CycleISP.
Learning Enriched Features for Real Image Restoration and Enhancement
Mar 15, 2020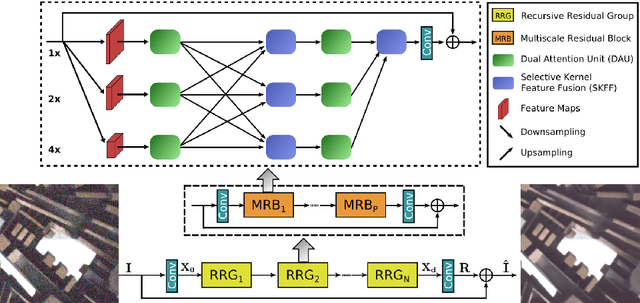

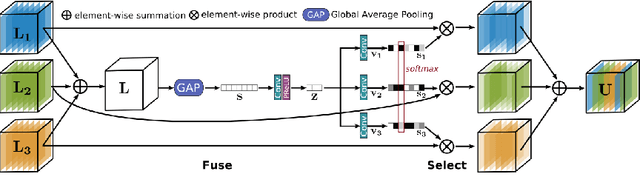
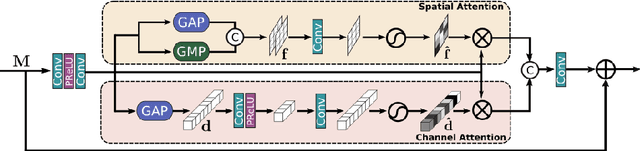
With the goal of recovering high-quality image content from its degraded version, image restoration enjoys numerous applications, such as in surveillance, computational photography, medical imaging, and remote sensing. Recently, convolutional neural networks (CNNs) have achieved dramatic improvements over conventional approaches for image restoration task. Existing CNN-based methods typically operate either on full-resolution or on progressively low-resolution representations. In the former case, spatially precise but contextually less robust results are achieved, while in the latter case, semantically reliable but spatially less accurate outputs are generated. In this paper, we present a novel architecture with the collective goals of maintaining spatially-precise high-resolution representations through the entire network, and receiving strong contextual information from the low-resolution representations. The core of our approach is a multi-scale residual block containing several key elements: (a) parallel multi-resolution convolution streams for extracting multi-scale features, (b) information exchange across the multi-resolution streams, (c) spatial and channel attention mechanisms for capturing contextual information, and (d) attention based multi-scale feature aggregation. In the nutshell, our approach learns an enriched set of features that combines contextual information from multiple scales, while simultaneously preserving the high-resolution spatial details. Extensive experiments on five real image benchmark datasets demonstrate that our method, named as MIRNet, achieves state-of-the-art results for a variety of image processing tasks, including image denoising, super-resolution and image enhancement.
Attributed Sequence Embedding
Nov 03, 2019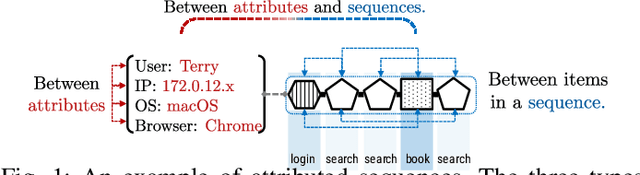
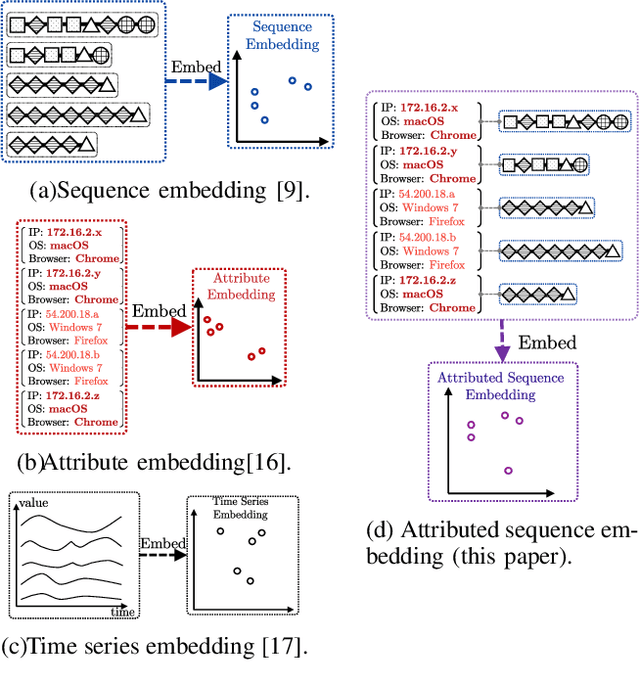
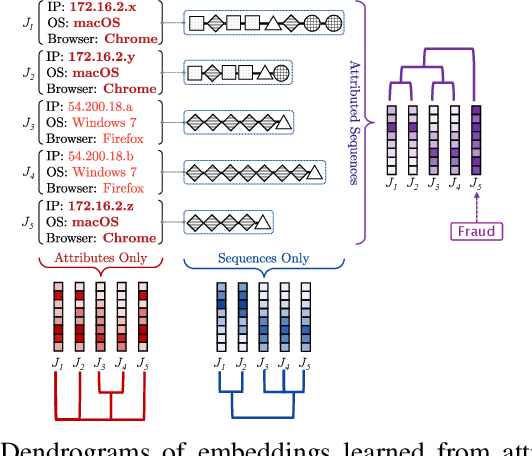
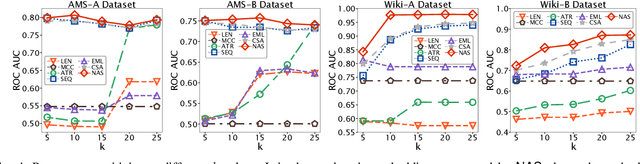
Mining tasks over sequential data, such as clickstreams and gene sequences, require a careful design of embeddings usable by learning algorithms. Recent research in feature learning has been extended to sequential data, where each instance consists of a sequence of heterogeneous items with a variable length. However, many real-world applications often involve attributed sequences, where each instance is composed of both a sequence of categorical items and a set of attributes. In this paper, we study this new problem of attributed sequence embedding, where the goal is to learn the representations of attributed sequences in an unsupervised fashion. This problem is core to many important data mining tasks ranging from user behavior analysis to the clustering of gene sequences. This problem is challenging due to the dependencies between sequences and their associated attributes. We propose a deep multimodal learning framework, called NAS, to produce embeddings of attributed sequences. The embeddings are task independent and can be used on various mining tasks of attributed sequences. We demonstrate the effectiveness of our embeddings of attributed sequences in various unsupervised learning tasks on real-world datasets.
AnimalWeb: A Large-Scale Hierarchical Dataset of Annotated Animal Faces
Sep 11, 2019
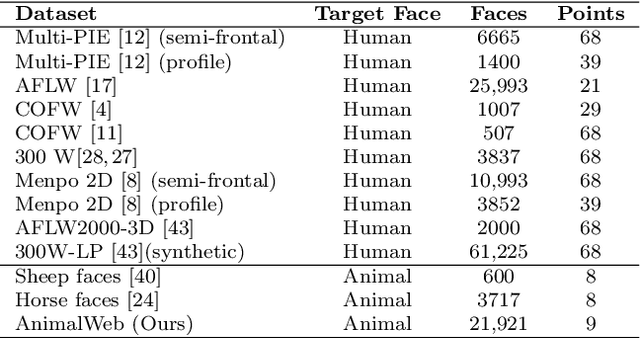

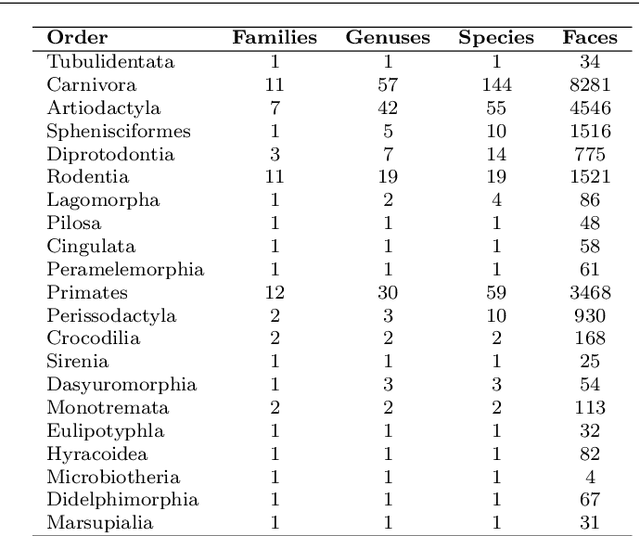
Being heavily reliant on animals, it is our ethical obligation to improve their well-being by understanding their needs. Several studies show that animal needs are often expressed through their faces. Though remarkable progress has been made towards the automatic understanding of human faces, this has regrettably not been the case with animal faces. There exists significant room and appropriate need to develop automatic systems capable of interpreting animal faces. Among many transformative impacts, such a technology will foster better and cheaper animal healthcare, and further advance animal psychology understanding. We believe the underlying research progress is mainly obstructed by the lack of an adequately annotated dataset of animal faces, covering a wide spectrum of animal species. To this end, we introduce a large-scale, hierarchical annotated dataset of animal faces, featuring 21.9K faces from 334 diverse species and 21 animal orders across biological taxonomy. These faces are captured `in-the-wild' conditions and are consistently annotated with 9 landmarks on key facial features. The proposed dataset is structured and scalable by design; its development underwent four systematic stages involving rigorous, manual annotation effort of over 6K man-hours. We benchmark it for face alignment using the existing art under novel problem settings. Results showcase its challenging nature, unique attributes and present definite prospects for novel, adaptive, and generalized face-oriented CV algorithms. We further benchmark the dataset for face detection and fine-grained recognition tasks, to demonstrate multi-task applications and room for improvement. Experiments indicate that this dataset will push the algorithmic advancements across many related CV tasks and encourage the development of novel systems for animal facial behaviour monitoring. We will make the dataset publicly available.
iSAID: A Large-scale Dataset for Instance Segmentation in Aerial Images
May 30, 2019
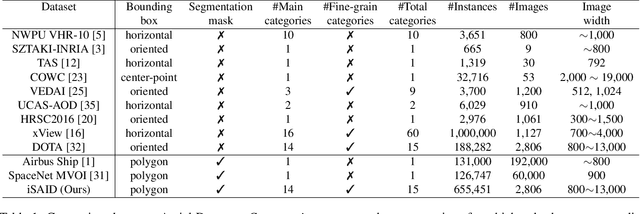
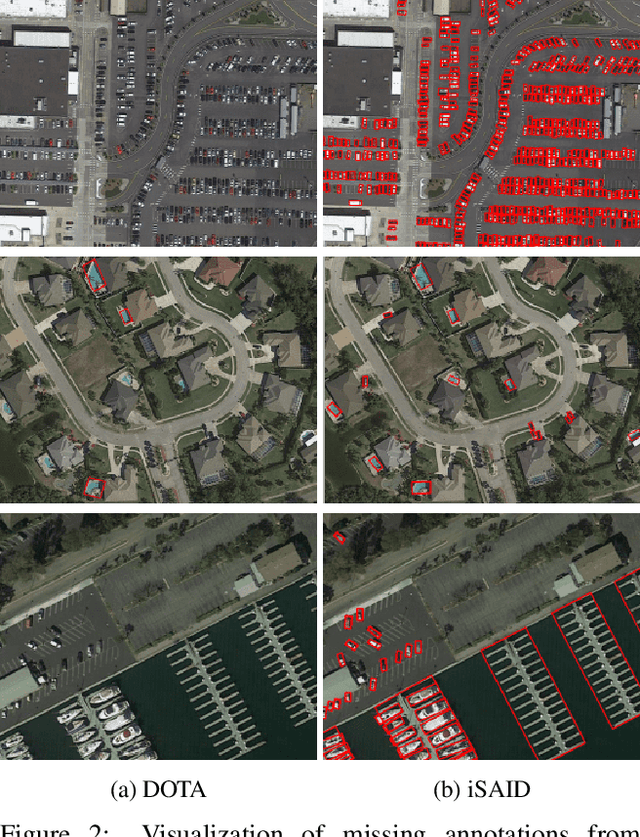
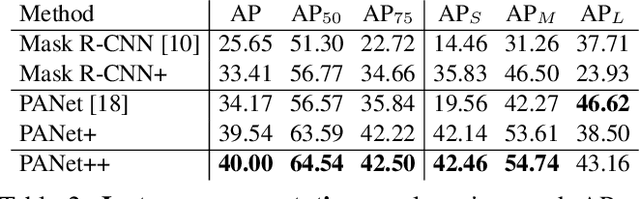
Existing Earth Vision datasets are either suitable for semantic segmentation or object detection. In this work, we introduce the first benchmark dataset for instance segmentation in aerial imagery that combines instance-level object detection and pixel-level segmentation tasks. In comparison to instance segmentation in natural scenes, aerial images present unique challenges e.g., a huge number of instances per image, large object-scale variations and abundant tiny objects. Our large-scale and densely annotated Instance Segmentation in Aerial Images Dataset (iSAID) comes with 655,451 object instances for 15 categories across 2,806 high-resolution images. Such precise per-pixel annotations for each instance ensure accurate localization that is essential for detailed scene analysis. Compared to existing small-scale aerial image based instance segmentation datasets, iSAID contains 15$\times$ the number of object categories and 5$\times$ the number of instances. We benchmark our dataset using two popular instance segmentation approaches for natural images, namely Mask R-CNN and PANet. In our experiments we show that direct application of off-the-shelf Mask R-CNN and PANet on aerial images provide suboptimal instance segmentation results, thus requiring specialized solutions from the research community.
Learning Digital Camera Pipeline for Extreme Low-Light Imaging
Apr 11, 2019


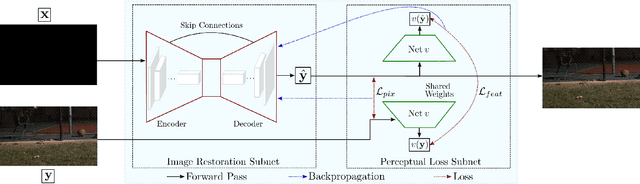
In low-light conditions, a conventional camera imaging pipeline produces sub-optimal images that are usually dark and noisy due to a low photon count and low signal-to-noise ratio (SNR). We present a data-driven approach that learns the desired properties of well-exposed images and reflects them in images that are captured in extremely low ambient light environments, thereby significantly improving the visual quality of these low-light images. We propose a new loss function that exploits the characteristics of both pixel-wise and perceptual metrics, enabling our deep neural network to learn the camera processing pipeline to transform the short-exposure, low-light RAW sensor data to well-exposed sRGB images. The results show that our method outperforms the state-of-the-art according to psychophysical tests as well as pixel-wise standard metrics and recent learning-based perceptual image quality measures.