 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Improved Speech Representations with Multi-Target Autoregressive Predictive Coding
Apr 11, 2020
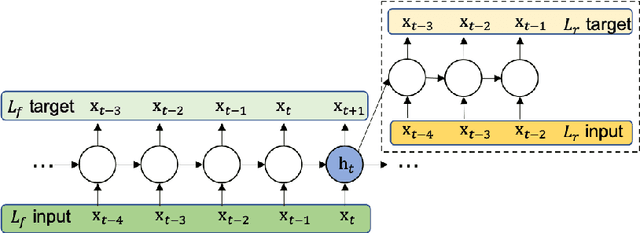
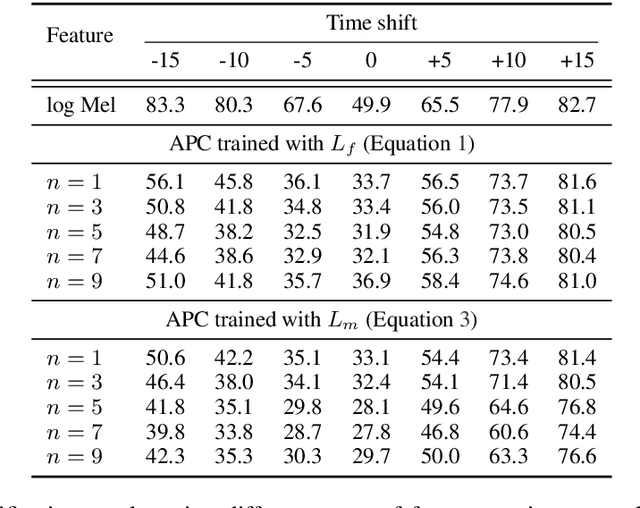
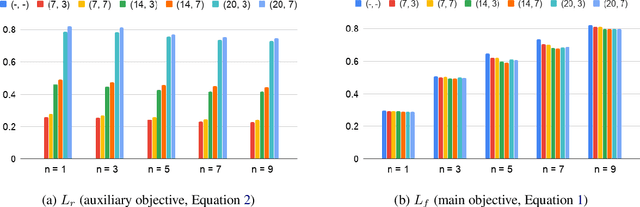

Training objectives based on predictive coding have recently been shown to be very effective at learning meaningful representations from unlabeled speech. One example is Autoregressive Predictive Coding (Chung et al., 2019), which trains an autoregressive RNN to generate an unseen future frame given a context such as recent past frames. The basic hypothesis of these approaches is that hidden states that can accurately predict future frames are a useful representation for many downstream tasks. In this paper we extend this hypothesis and aim to enrich the information encoded in the hidden states by training the model to make more accurate future predictions. We propose an auxiliary objective that serves as a regularization to improve generalization of the future frame prediction task. Experimental results on phonetic classification, speech recognition, and speech translation not only support the hypothesis, but also demonstrate the effectiveness of our approach in learning representations that contain richer phonetic content.
Towards Fluent Translations from Disfluent Speech
Nov 07, 2018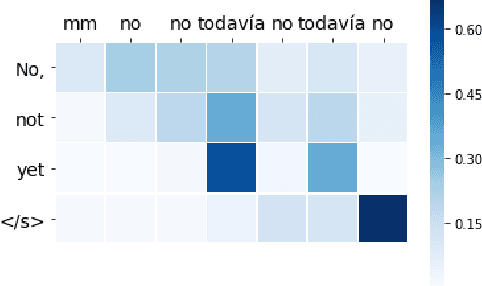
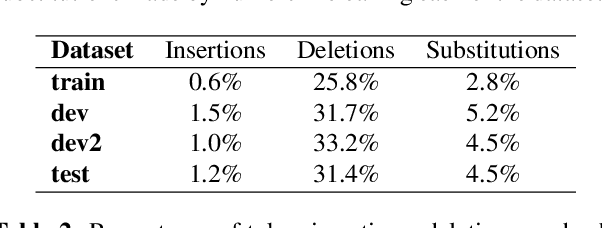
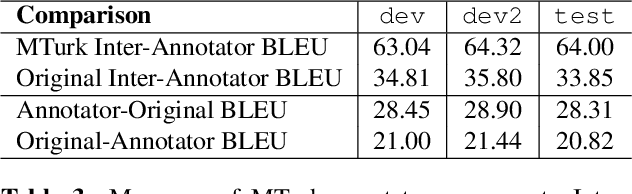
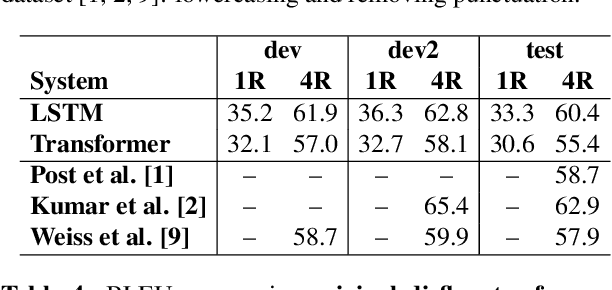
When translating from speech, special consideration for conversational speech phenomena such as disfluencies is necessary. Most machine translation training data consists of well-formed written texts, causing issues when translating spontaneous speech. Previous work has introduced an intermediate step between speech recognition (ASR) and machine translation (MT) to remove disfluencies, making the data better-matched to typical translation text and significantly improving performance. However, with the rise of end-to-end speech translation systems, this intermediate step must be incorporated into the sequence-to-sequence architecture. Further, though translated speech datasets exist, they are typically news or rehearsed speech without many disfluencies (e.g. TED), or the disfluencies are translated into the references (e.g. Fisher). To generate clean translations from disfluent speech, cleaned references are necessary for evaluation. We introduce a corpus of cleaned target data for the Fisher Spanish-English dataset for this task. We compare how different architectures handle disfluencies and provide a baseline for removing disfluencies in end-to-end translation.
Sequence-level self-learning with multiple hypotheses
Dec 10, 2021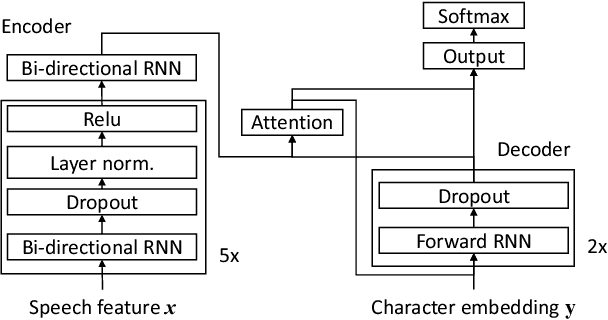
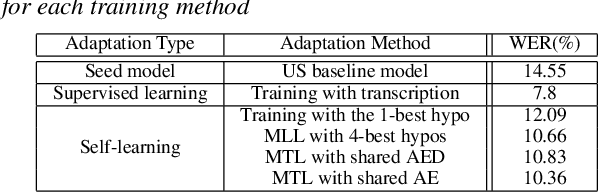
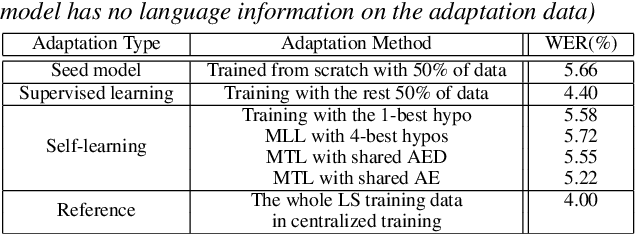
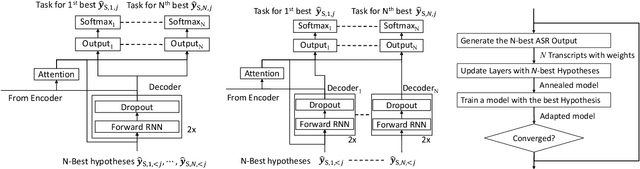
In this work, we develop new self-learning techniques with an attention-based sequence-to-sequence (seq2seq) model for automatic speech recognition (ASR). For untranscribed speech data, the hypothesis from an ASR system must be used as a label. However, the imperfect ASR result makes unsupervised learning difficult to consistently improve recognition performance especially in the case that multiple powerful teacher models are unavailable. In contrast to conventional unsupervised learning approaches, we adopt the \emph{multi-task learning} (MTL) framework where the $n$-th best ASR hypothesis is used as the label of each task. The seq2seq network is updated through the MTL framework so as to find the common representation that can cover multiple hypotheses. By doing so, the effect of the \emph{hard-decision} errors can be alleviated. We first demonstrate the effectiveness of our self-learning methods through ASR experiments in an accent adaptation task between the US and British English speech. Our experiment results show that our method can reduce the WER on the British speech data from 14.55\% to 10.36\% compared to the baseline model trained with the US English data only. Moreover, we investigate the effect of our proposed methods in a federated learning scenario.
Understanding and Detecting Dangerous Speech in Social Media
May 04, 2020
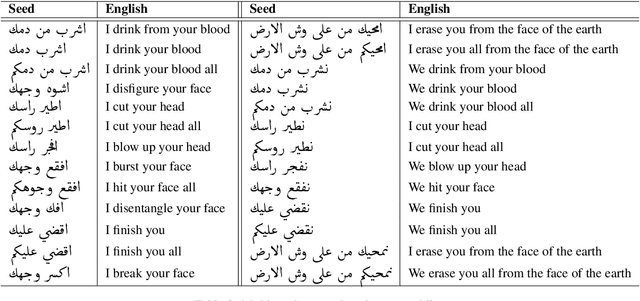
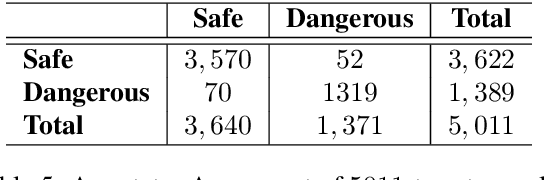
Social media communication has become a significant part of daily activity in modern societies. For this reason, ensuring safety in social media platforms is a necessity. Use of dangerous language such as physical threats in online environments is a somewhat rare, yet remains highly important. Although several works have been performed on the related issue of detecting offensive and hateful language, dangerous speech has not previously been treated in any significant way. Motivated by these observations, we report our efforts to build a labeled dataset for dangerous speech. We also exploit our dataset to develop highly effective models to detect dangerous content. Our best model performs at 59.60% macro F1, significantly outperforming a competitive baseline.
Examining a hate speech corpus for hate speech detection and popularity prediction
May 12, 2018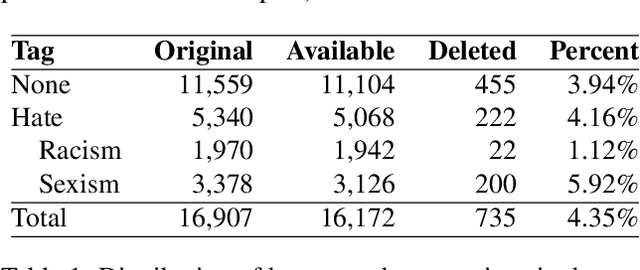
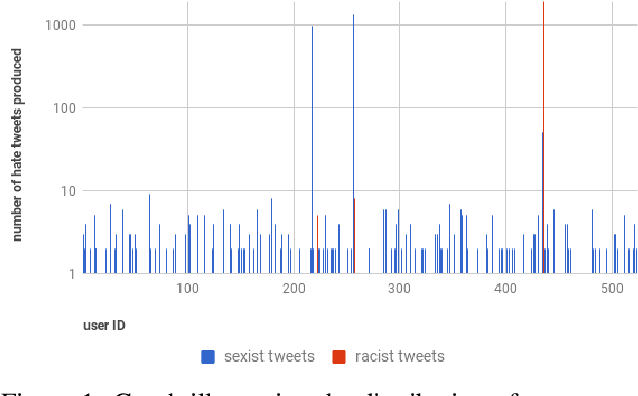
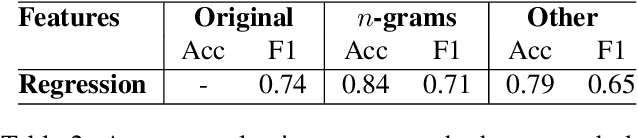
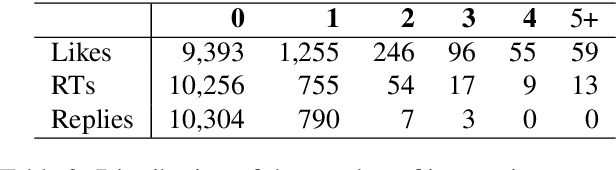
As research on hate speech becomes more and more relevant every day, most of it is still focused on hate speech detection. By attempting to replicate a hate speech detection experiment performed on an existing Twitter corpus annotated for hate speech, we highlight some issues that arise from doing research in the field of hate speech, which is essentially still in its infancy. We take a critical look at the training corpus in order to understand its biases, while also using it to venture beyond hate speech detection and investigate whether it can be used to shed light on other facets of research, such as popularity of hate tweets.
* 8 pages, 1 figure, 10 tables, published in proceedings of 4REAL2018: Workshop on Replicability and Reproducibility of Research Results in Science and Technology of Language
Joint Modeling of Code-Switched and Monolingual ASR via Conditional Factorization
Nov 29, 2021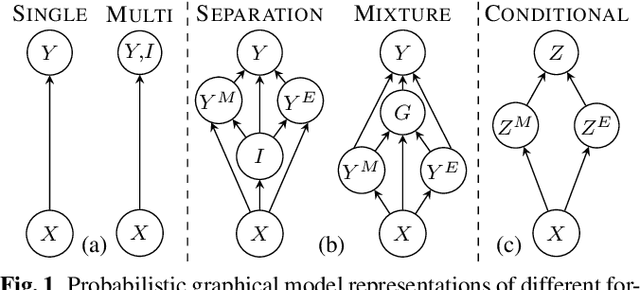
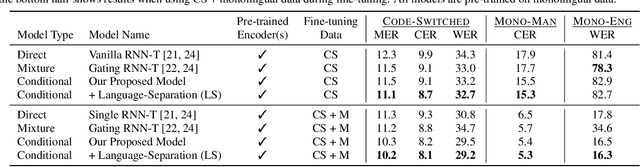
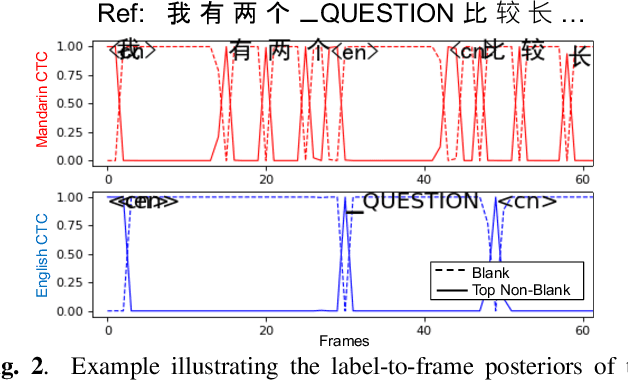
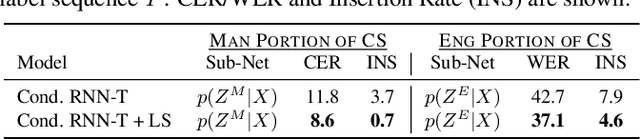
Conversational bilingual speech encompasses three types of utterances: two purely monolingual types and one intra-sententially code-switched type. In this work, we propose a general framework to jointly model the likelihoods of the monolingual and code-switch sub-tasks that comprise bilingual speech recognition. By defining the monolingual sub-tasks with label-to-frame synchronization, our joint modeling framework can be conditionally factorized such that the final bilingual output, which may or may not be code-switched, is obtained given only monolingual information. We show that this conditionally factorized joint framework can be modeled by an end-to-end differentiable neural network. We demonstrate the efficacy of our proposed model on bilingual Mandarin-English speech recognition across both monolingual and code-switched corpora.
ViDA-MAN: Visual Dialog with Digital Humans
Oct 26, 2021
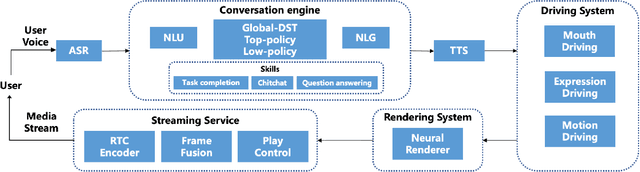
We demonstrate ViDA-MAN, a digital-human agent for multi-modal interaction, which offers realtime audio-visual responses to instant speech inquiries. Compared to traditional text or voice-based system, ViDA-MAN offers human-like interactions (e.g, vivid voice, natural facial expression and body gestures). Given a speech request, the demonstration is able to response with high quality videos in sub-second latency. To deliver immersive user experience, ViDA-MAN seamlessly integrates multi-modal techniques including Acoustic Speech Recognition (ASR), multi-turn dialog, Text To Speech (TTS), talking heads video generation. Backed with large knowledge base, ViDA-MAN is able to chat with users on a number of topics including chit-chat, weather, device control, News recommendations, booking hotels, as well as answering questions via structured knowledge.
Does Visual Self-Supervision Improve Learning of Speech Representations?
May 04, 2020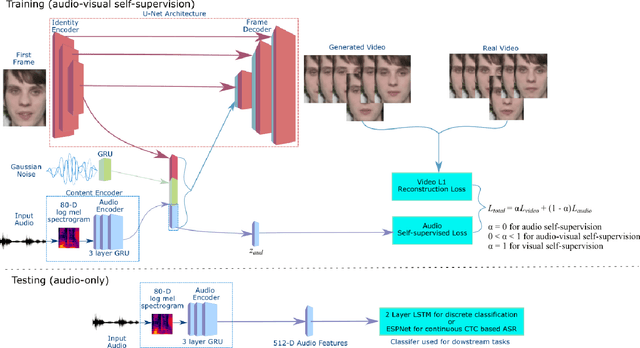
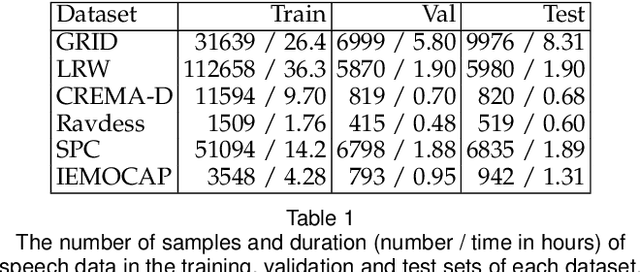
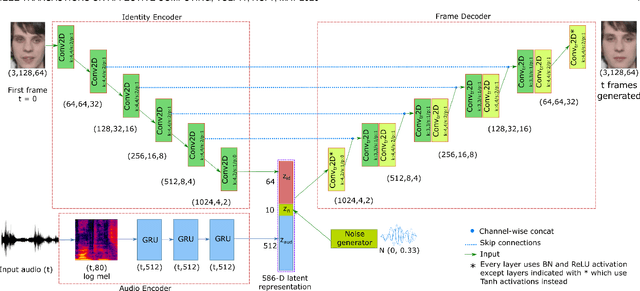
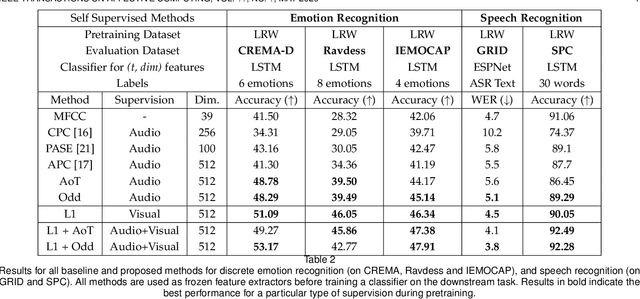
Self-supervised learning has attracted plenty of recent research interest. However, most works are typically unimodal and there has been limited work that studies the interaction between audio and visual modalities for self-supervised learning. This work (1) investigates visual self-supervision via face reconstruction to guide the learning of audio representations; (2) proposes two audio-only self-supervision approaches for speech representation learning; (3) shows that a multi-task combination of the proposed visual and audio self-supervision is beneficial for learning richer features that are more robust in noisy conditions; (4) shows that self-supervised pretraining leads to a superior weight initialization, which is especially useful to prevent overfitting and lead to faster model convergence on smaller sized datasets. We evaluate our audio representations for emotion and speech recognition, achieving state of the art performance for both problems. Our results demonstrate the potential of visual self-supervision for audio feature learning and suggest that joint visual and audio self-supervision leads to more informative speech representations.
NIESR: Nuisance Invariant End-to-end Speech Recognition
Jul 07, 2019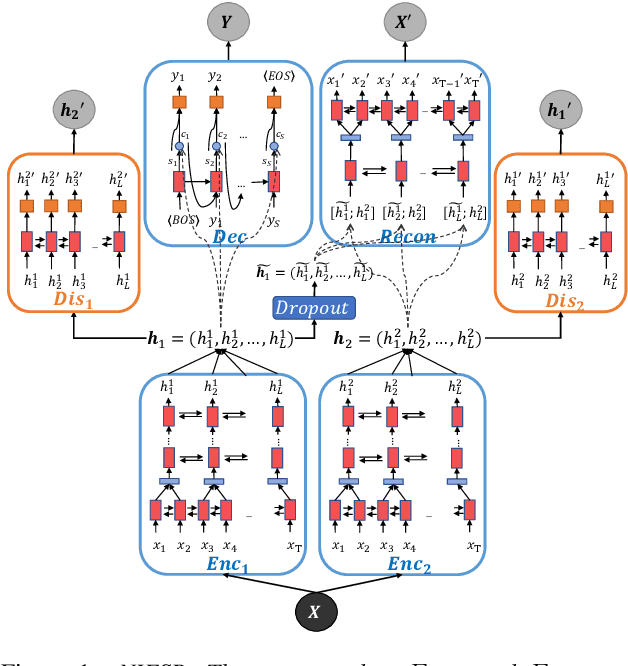

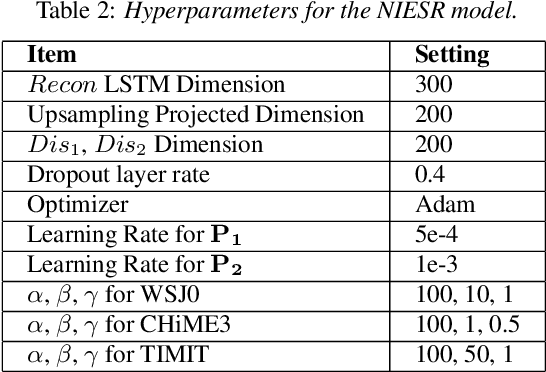
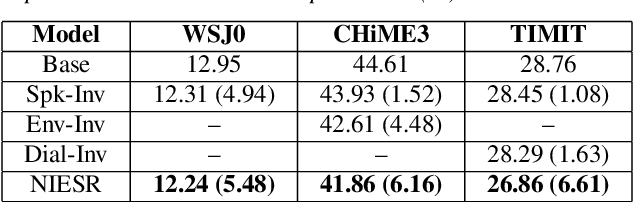
Deep neural network models for speech recognition have achieved great success recently, but they can learn incorrect associations between the target and nuisance factors of speech (e.g., speaker identities, background noise, etc.), which can lead to overfitting. While several methods have been proposed to tackle this problem, existing methods incorporate additional information about nuisance factors during training to develop invariant models. However, enumeration of all possible nuisance factors in speech data and the collection of their annotations is difficult and expensive. We present a robust training scheme for end-to-end speech recognition that adopts an unsupervised adversarial invariance induction framework to separate out essential factors for speech-recognition from nuisances without using any supplementary labels besides the transcriptions. Experiments show that the speech recognition model trained with the proposed training scheme achieves relative improvements of 5.48% on WSJ0, 6.16% on CHiME3, and 6.61% on TIMIT dataset over the base model. Additionally, the proposed method achieves a relative improvement of 14.44% on the combined WSJ0+CHiME3 dataset.
Semi-Supervised Speech Recognition via Graph-based Temporal Classification
Oct 29, 2020

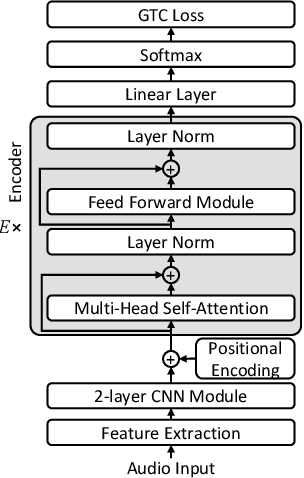
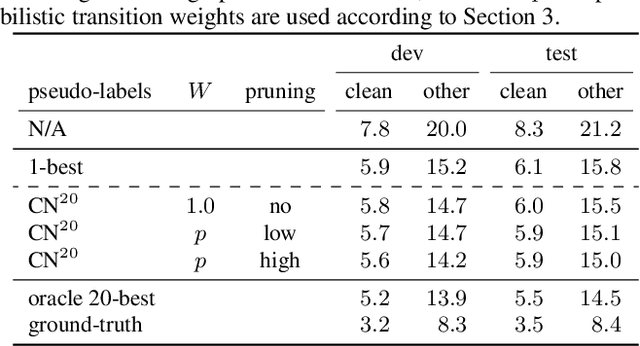
Semi-supervised learning has demonstrated promising results in automatic speech recognition (ASR) by self-training using a seed ASR model with pseudo-labels generated for unlabeled data. The effectiveness of this approach largely relies on the pseudo-label accuracy, for which typically only the 1-best ASR hypothesis is used. However, alternative ASR hypotheses of an N-best list can provide more accurate labels for an unlabeled speech utterance and also reflect uncertainties of the seed ASR model. In this paper, we propose a generalized form of the connectionist temporal classification (CTC) objective that accepts a graph representation of the training targets. The newly proposed graph-based temporal classification (GTC) objective is applied for self-training with WFST-based supervision, which is generated from an N-best list of pseudo-labels. In this setup, GTC is used to learn not only a temporal alignment, similarly to CTC, but also a label alignment to obtain the optimal pseudo-label sequence from the weighted graph. Results show that this approach can effectively exploit an N-best list of pseudo-labels with associated scores, outperforming standard pseudo-labeling by a large margin, with ASR results close to an oracle experiment in which the best hypotheses of the N-best lists are selected manually.