 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Arabic Diacritization by Learning to Diacritize and Translate
Sep 29, 2021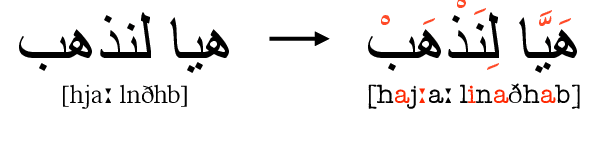

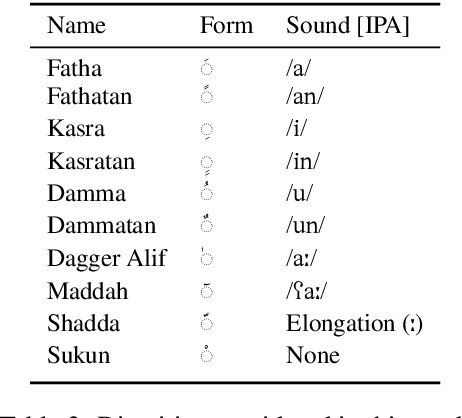
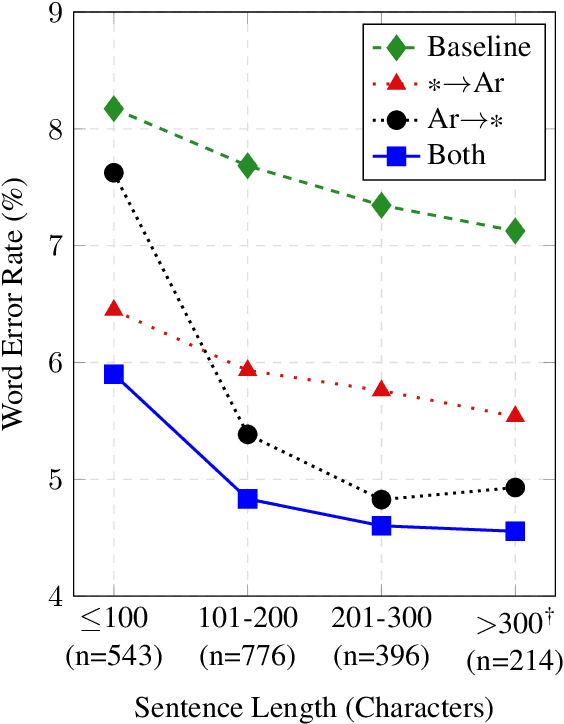
We propose a novel multitask learning method for diacritization which trains a model to both diacritize and translate. Our method addresses data sparsity by exploiting large, readily available bitext corpora. Furthermore, translation requires implicit linguistic and semantic knowledge, which is helpful for resolving ambiguities in the diacritization task. We apply our method to the Penn Arabic Treebank and report a new state-of-the-art word error rate of 4.79%. We also conduct manual and automatic analysis to better understand our method and highlight some of the remaining challenges in diacritization.
AraStance: A Multi-Country and Multi-Domain Dataset of Arabic Stance Detection for Fact Checking
May 18, 2021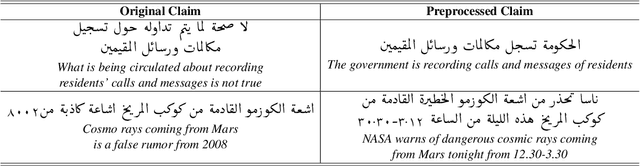

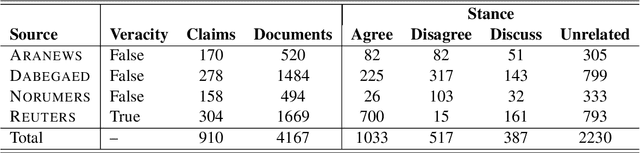
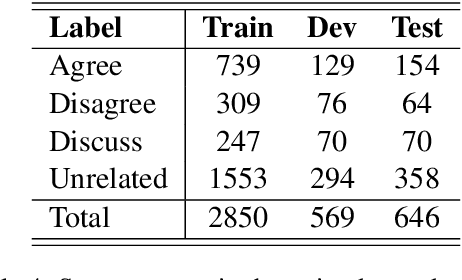
With the continuing spread of misinformation and disinformation online, it is of increasing importance to develop combating mechanisms at scale in the form of automated systems that support multiple languages. One task of interest is claim veracity prediction, which can be addressed using stance detection with respect to relevant documents retrieved online. To this end, we present our new Arabic Stance Detection dataset (AraStance) of 4,063 claim--article pairs from a diverse set of sources comprising three fact-checking websites and one news website. AraStance covers false and true claims from multiple domains (e.g., politics, sports, health) and several Arab countries, and it is well-balanced between related and unrelated documents with respect to the claims. We benchmark AraStance, along with two other stance detection datasets, using a number of BERT-based models. Our best model achieves an accuracy of 85\% and a macro F1 score of 78\%, which leaves room for improvement and reflects the challenging nature of AraStance and the task of stance detection in general.
Understanding and Detecting Dangerous Speech in Social Media
May 04, 2020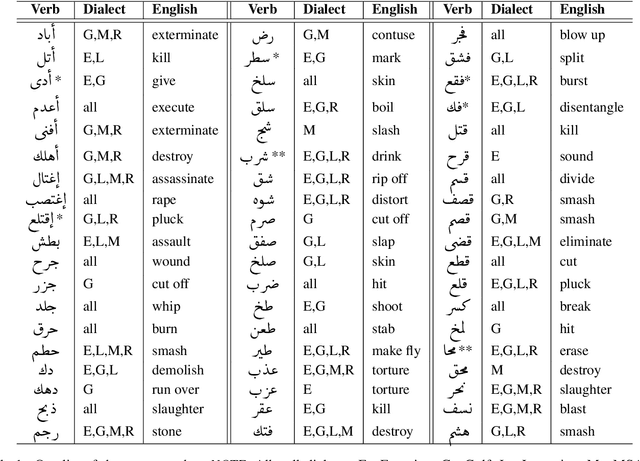
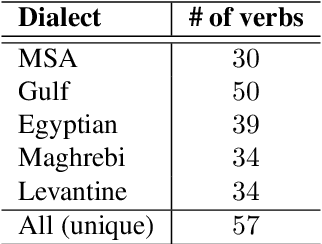
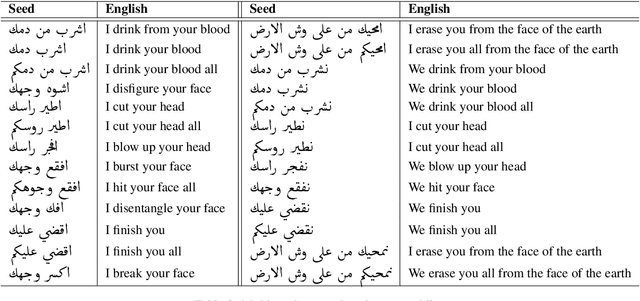
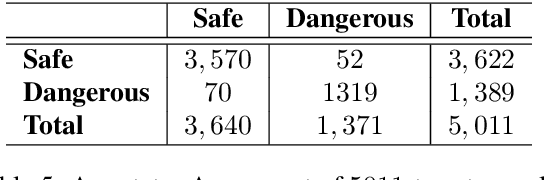
Social media communication has become a significant part of daily activity in modern societies. For this reason, ensuring safety in social media platforms is a necessity. Use of dangerous language such as physical threats in online environments is a somewhat rare, yet remains highly important. Although several works have been performed on the related issue of detecting offensive and hateful language, dangerous speech has not previously been treated in any significant way. Motivated by these observations, we report our efforts to build a labeled dataset for dangerous speech. We also exploit our dataset to develop highly effective models to detect dangerous content. Our best model performs at 59.60% macro F1, significantly outperforming a competitive baseline.