 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Paraformer: Fast and Accurate Parallel Transformer for Non-autoregressive End-to-End Speech Recognition
Jun 20, 2022
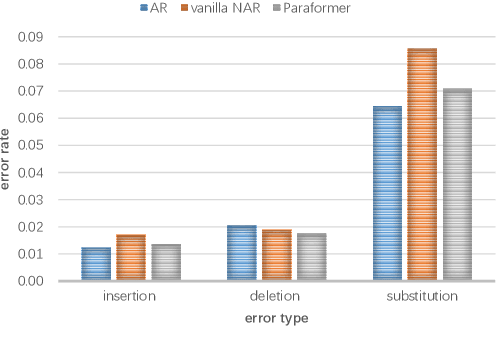
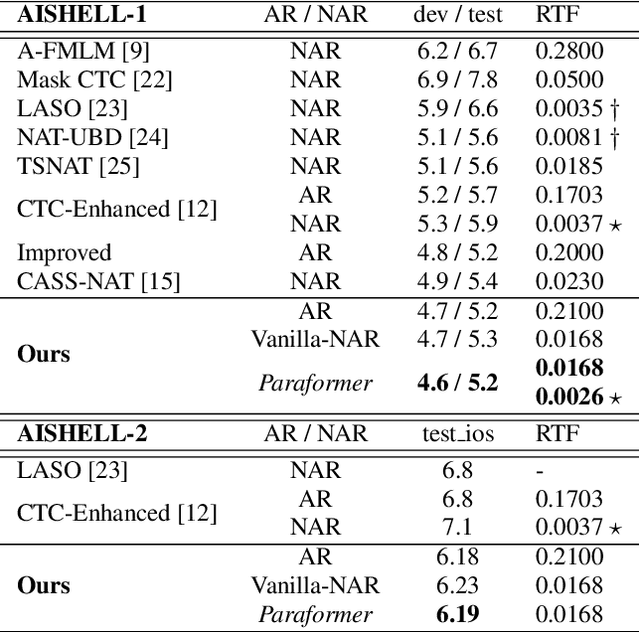
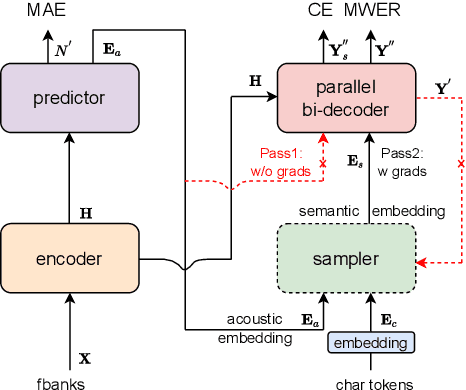
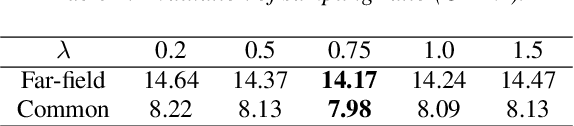
Transformers have recently dominated the ASR field. Although able to yield good performance, they involve an autoregressive (AR) decoder to generate tokens one by one, which is computationally inefficient. To speed up inference, non-autoregressive (NAR) methods, e.g. single-step NAR, were designed, to enable parallel generation. However, due to an independence assumption within the output tokens, performance of single-step NAR is inferior to that of AR models, especially with a large-scale corpus. There are two challenges to improving single-step NAR: Firstly to accurately predict the number of output tokens and extract hidden variables; secondly, to enhance modeling of interdependence between output tokens. To tackle both challenges, we propose a fast and accurate parallel transformer, termed Paraformer. This utilizes a continuous integrate-and-fire based predictor to predict the number of tokens and generate hidden variables. A glancing language model (GLM) sampler then generates semantic embeddings to enhance the NAR decoder's ability to model context interdependence. Finally, we design a strategy to generate negative samples for minimum word error rate training to further improve performance. Experiments using the public AISHELL-1, AISHELL-2 benchmark, and an industrial-level 20,000 hour task demonstrate that the proposed Paraformer can attain comparable performance to the state-of-the-art AR transformer, with more than 10x speedup.
Wave-Tacotron: Spectrogram-free end-to-end text-to-speech synthesis
Nov 06, 2020
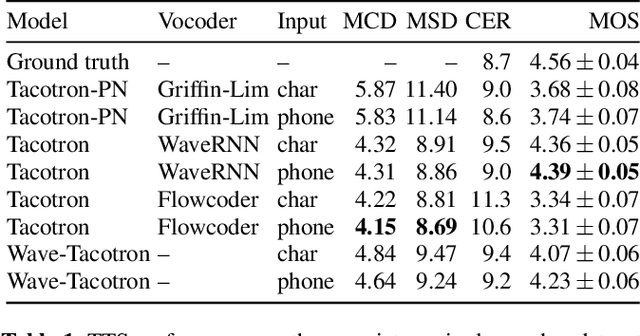
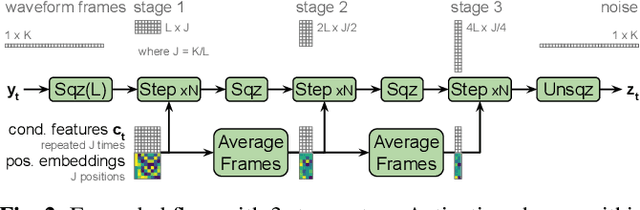
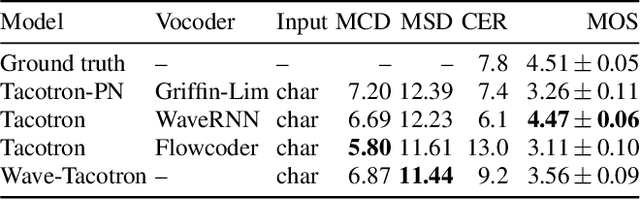
We describe a sequence-to-sequence neural network which can directly generate speech waveforms from text inputs. The architecture extends the Tacotron model by incorporating a normalizing flow into the autoregressive decoder loop. Output waveforms are modeled as a sequence of non-overlapping fixed-length frames, each one containing hundreds of samples. The interdependencies of waveform samples within each frame are modeled using the normalizing flow, enabling parallel training and synthesis. Longer-term dependencies are handled autoregressively by conditioning each flow on preceding frames. This model can be optimized directly with maximum likelihood, without using intermediate, hand-designed features nor additional loss terms. Contemporary state-of-the-art text-to-speech (TTS) systems use a cascade of separately learned models: one (such as Tacotron) which generates intermediate features (such as spectrograms) from text, followed by a vocoder (such as WaveRNN) which generates waveform samples from the intermediate features. The proposed system, in contrast, does not use a fixed intermediate representation, and learns all parameters end-to-end. Experiments show that the proposed model generates speech with quality approaching a state-of-the-art neural TTS system, with significantly improved generation speed.
Towards Natural Bilingual and Code-Switched Speech Synthesis Based on Mix of Monolingual Recordings and Cross-Lingual Voice Conversion
Oct 16, 2020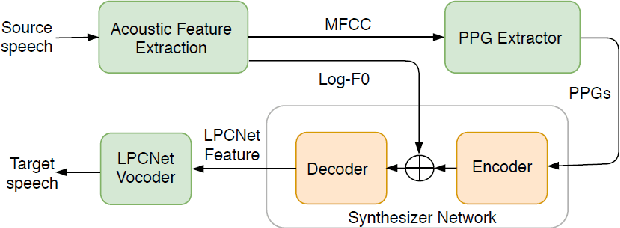

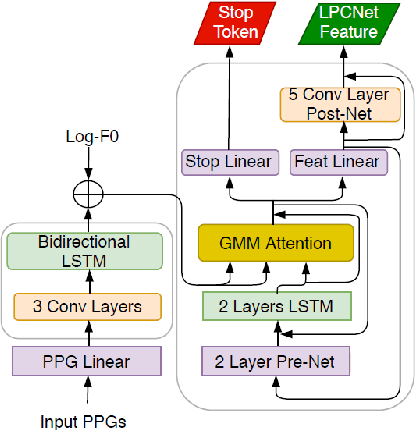
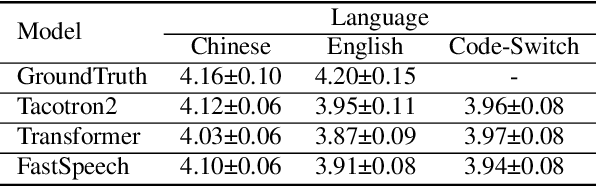
Recent state-of-the-art neural text-to-speech (TTS) synthesis models have dramatically improved intelligibility and naturalness of generated speech from text. However, building a good bilingual or code-switched TTS for a particular voice is still a challenge. The main reason is that it is not easy to obtain a bilingual corpus from a speaker who achieves native-level fluency in both languages. In this paper, we explore the use of Mandarin speech recordings from a Mandarin speaker, and English speech recordings from another English speaker to build high-quality bilingual and code-switched TTS for both speakers. A Tacotron2-based cross-lingual voice conversion system is employed to generate the Mandarin speaker's English speech and the English speaker's Mandarin speech, which show good naturalness and speaker similarity. The obtained bilingual data are then augmented with code-switched utterances synthesized using a Transformer model. With these data, three neural TTS models -- Tacotron2, Transformer and FastSpeech are applied for building bilingual and code-switched TTS. Subjective evaluation results show that all the three systems can produce (near-)native-level speech in both languages for each of the speaker.
Deep Learning-Based Joint Control of Acoustic Echo Cancellation, Beamforming and Postfiltering
Mar 03, 2022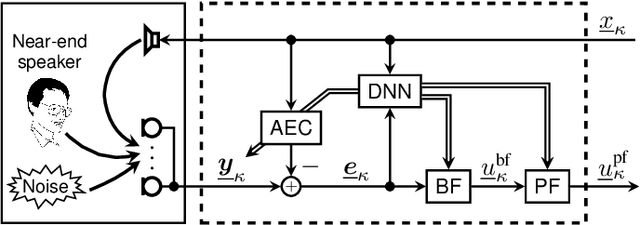
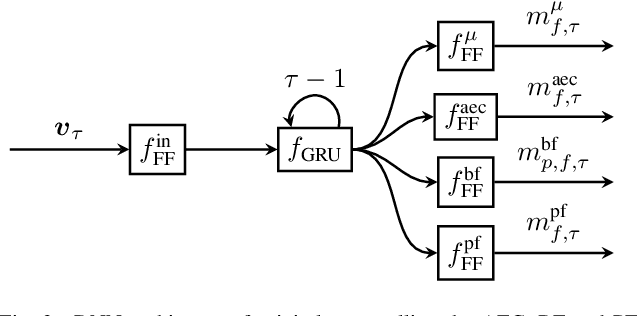
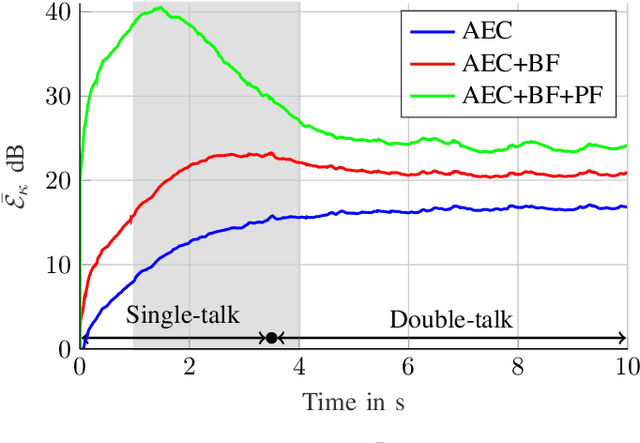
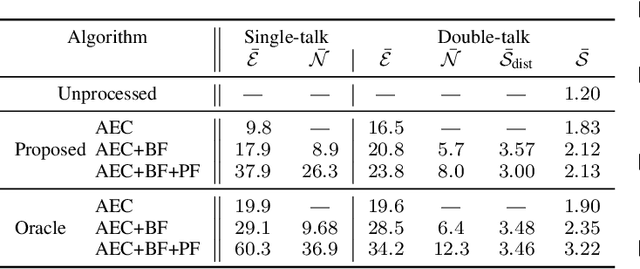
We introduce a novel method for controlling the functionality of a hands-free speech communication device which comprises a model-based acoustic echo canceller (AEC), minimum variance distortionless response (MVDR) beamformer (BF) and spectral postfilter (PF). While the AEC removes the early echo component, the MVDR BF and PF suppress the residual echo and background noise. As key innovation, we suggest to use a single deep neural network (DNN) to jointly control the adaptation of the various algorithmic components. This allows for rapid convergence and high steady-state performance in the presence of high-level interfering double-talk. End-to-end training of the DNN using a time-domain speech extraction loss function avoids the design of individual control strategies.
The Interspeech Zero Resource Speech Challenge 2021: Spoken language modelling
Apr 29, 2021
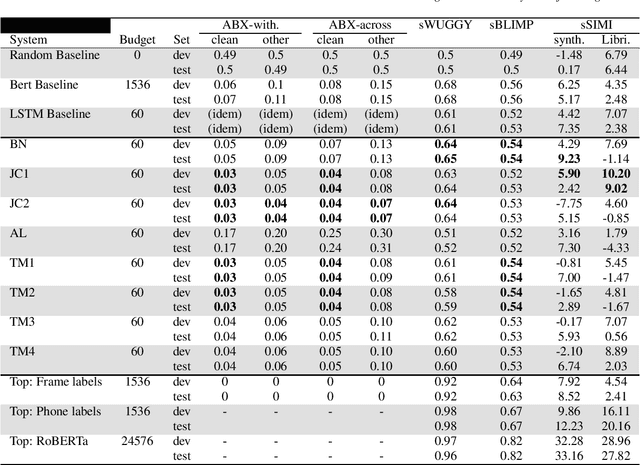
We present the Zero Resource Speech Challenge 2021, which asks participants to learn a language model directly from audio, without any text or labels. The challenge is based on the Libri-light dataset, which provides up to 60k hours of audio from English audio books without any associated text. We provide a pipeline baseline system consisting on an encoder based on contrastive predictive coding (CPC), a quantizer ($k$-means) and a standard language model (BERT or LSTM). The metrics evaluate the learned representations at the acoustic (ABX discrimination), lexical (spot-the-word), syntactic (acceptability judgment) and semantic levels (similarity judgment). We present an overview of the eight submitted systems from four groups and discuss the main results.
Low-Memory End-to-End Training for Iterative Joint Speech Dereverberation and Separation with A Neural Source Model
Oct 13, 2021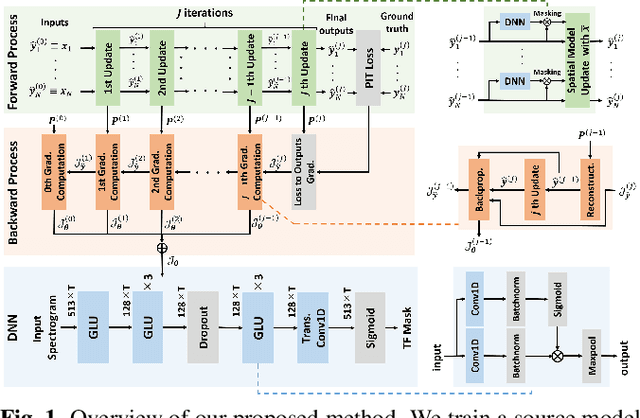

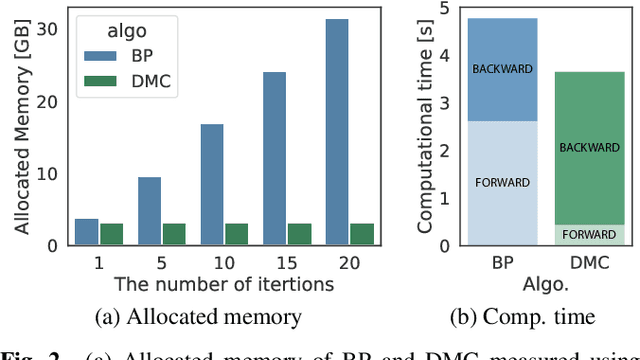
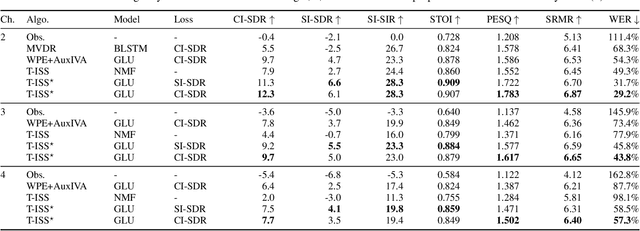
We propose an end-to-end framework for training iterative multi-channel joint dereverberation and source separation with a neural source model. We combine the unified dereverberation and separation update equations of ILRMA-T with a deep neural network (DNN) serving as source model. The weights of the model are directly trained by gradient descent with a permutation invariant loss on the output time-domain signals. One drawback of this approach is that backpropagation consumes memory linearly in the number of iterations. This severely limits the number of iterations, channels, or signal lengths that can be used during training. We introduce demixing matrix checkpointing to bypass this problem, a new technique that reduces the total memory cost to that of a single iteration. In experiments, we demonstrate that the introduced framework results in high-performance in terms of conventional speech quality metrics and word error rate. Furthermore, it generalizes to number of channels unseen during training.
KT-Speech-Crawler: Automatic Dataset Construction for Speech Recognition from YouTube Videos
Mar 01, 2019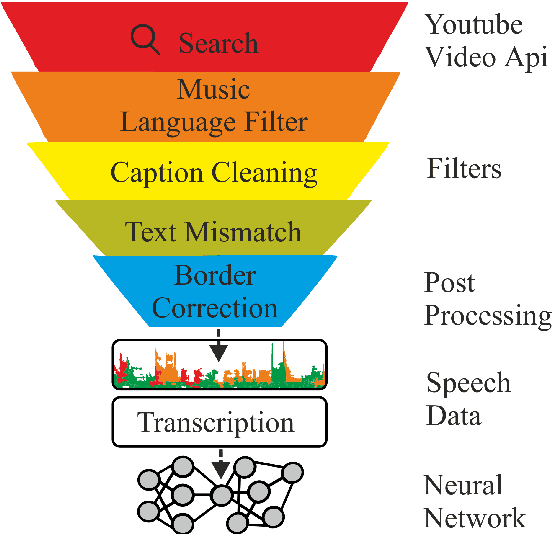
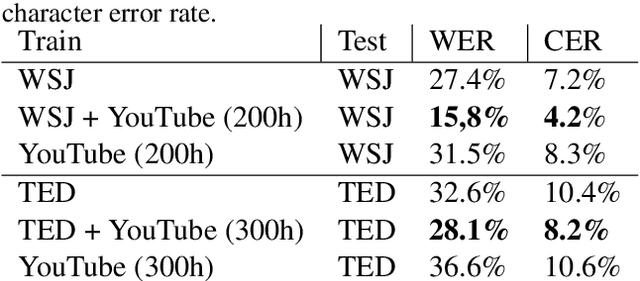
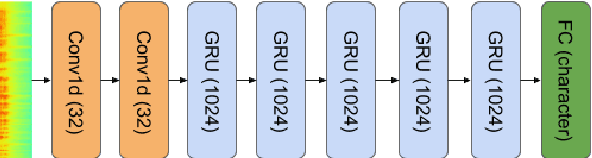
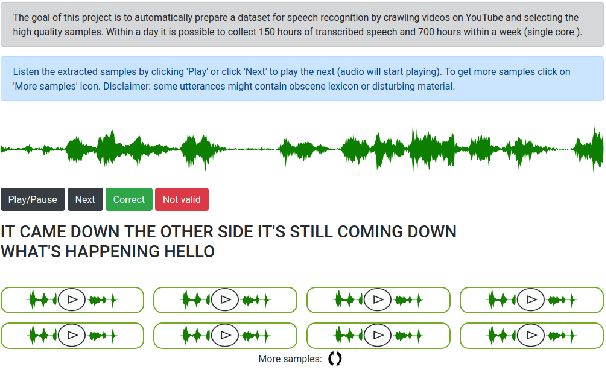
In this paper, we describe KT-Speech-Crawler: an approach for automatic dataset construction for speech recognition by crawling YouTube videos. We outline several filtering and post-processing steps, which extract samples that can be used for training end-to-end neural speech recognition systems. In our experiments, we demonstrate that a single-core version of the crawler can obtain around 150 hours of transcribed speech within a day, containing an estimated 3.5% word error rate in the transcriptions. Automatically collected samples contain reading and spontaneous speech recorded in various conditions including background noise and music, distant microphone recordings, and a variety of accents and reverberation. When training a deep neural network on speech recognition, we observed around 40\% word error rate reduction on the Wall Street Journal dataset by integrating 200 hours of the collected samples into the training set. The demo (http://emnlp-demo.lakomkin.me/) and the crawler code (https://github.com/EgorLakomkin/KTSpeechCrawler) are publicly available.
VoViT: Low Latency Graph-based Audio-Visual Voice Separation Transformer
Mar 08, 2022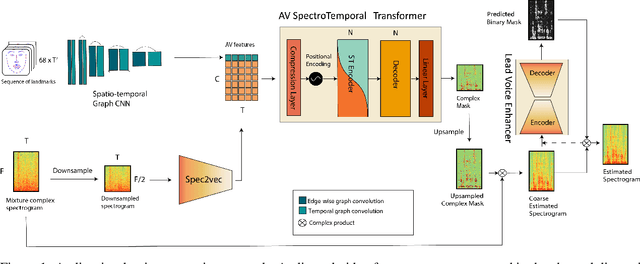
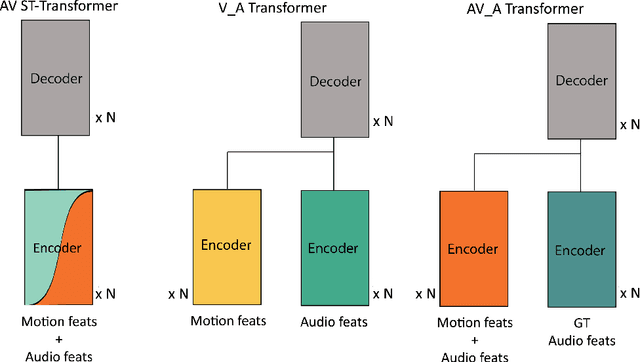

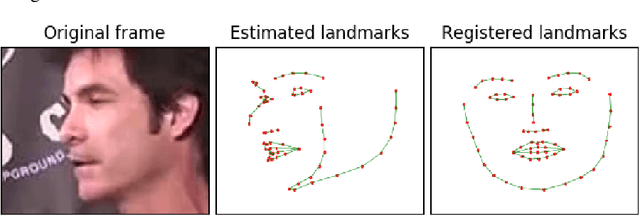
This paper presents an audio-visual approach for voice separation which outperforms state-of-the-art methods at a low latency in two scenarios: speech and singing voice. The model is based on a two-stage network. Motion cues are obtained with a lightweight graph convolutional network that processes face landmarks. Then, both audio and motion features are fed to an audio-visual transformer which produces a fairly good estimation of the isolated target source. In a second stage, the predominant voice is enhanced with an audio-only network. We present different ablation studies and comparison to state-of-the-art methods. Finally, we explore the transferability of models trained for speech separation in the task of singing voice separation. The demos, code, and weights will be made publicly available at https://ipcv.github.io/VoViT/
Internal Language Model Adaptation with Text-Only Data for End-to-End Speech Recognition
Oct 06, 2021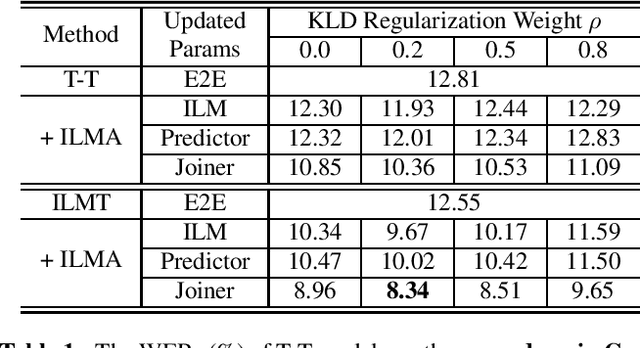
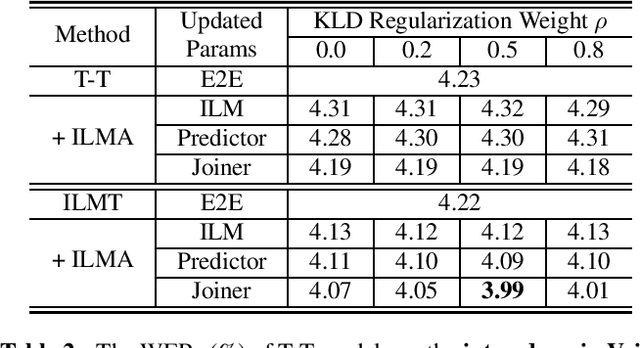
Text-only adaptation of an end-to-end (E2E) model remains a challenging task for automatic speech recognition (ASR). Language model (LM) fusion-based approaches require an additional external LM during inference, significantly increasing the computation cost. To overcome this, we propose an internal LM adaptation (ILMA) of the E2E model using text-only data. Trained with audio-transcript pairs, an E2E model implicitly learns an internal LM that characterizes the token sequence probability which is approximated by the E2E model output after zeroing out the encoder contribution. During ILMA, we fine-tune the internal LM, i.e., the E2E components excluding the encoder, to minimize a cross-entropy loss. To make ILMA effective, it is essential to train the E2E model with an internal LM loss besides the standard E2E loss. Furthermore, we propose to regularize ILMA by minimizing the Kullback-Leibler divergence between the output distributions of the adapted and unadapted internal LMs. ILMA is the most effective when we update only the last linear layer of the joint network. ILMA enables a fast text-only adaptation of the E2E model without increasing the run-time computational cost. Experimented with 30K-hour trained transformer transducer models, ILMA achieves up to 34.9% relative word error rate reduction from the unadapted baseline.
Emotional Speaker Identification using a Novel Capsule Nets Model
Jan 09, 2022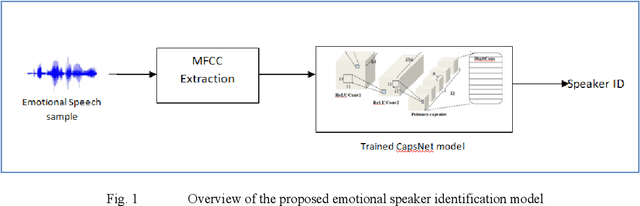

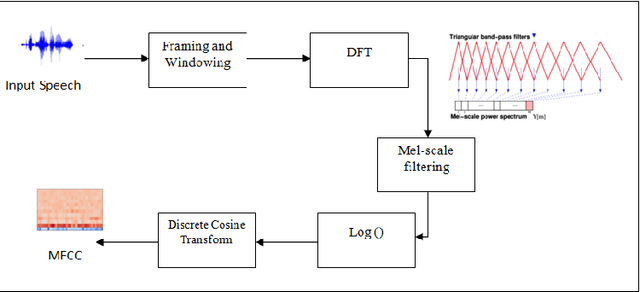
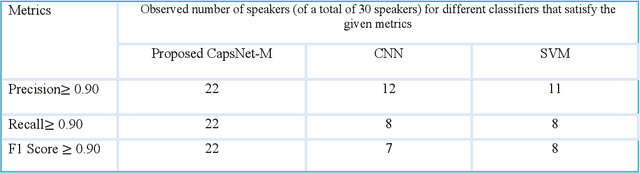
Speaker recognition systems are widely used in various applications to identify a person by their voice; however, the high degree of variability in speech signals makes this a challenging task. Dealing with emotional variations is very difficult because emotions alter the voice characteristics of a person; thus, the acoustic features differ from those used to train models in a neutral environment. Therefore, speaker recognition models trained on neutral speech fail to correctly identify speakers under emotional stress. Although considerable advancements in speaker identification have been made using convolutional neural networks (CNN), CNNs cannot exploit the spatial association between low-level features. Inspired by the recent introduction of capsule networks (CapsNets), which are based on deep learning to overcome the inadequacy of CNNs in preserving the pose relationship between low-level features with their pooling technique, this study investigates the performance of using CapsNets in identifying speakers from emotional speech recordings. A CapsNet-based speaker identification model is proposed and evaluated using three distinct speech databases, i.e., the Emirati Speech Database, SUSAS Dataset, and RAVDESS (open-access). The proposed model is also compared to baseline systems. Experimental results demonstrate that the novel proposed CapsNet model trains faster and provides better results over current state-of-the-art schemes. The effect of the routing algorithm on speaker identification performance was also studied by varying the number of iterations, both with and without a decoder network.