 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaformer: Fast and Accurate Parallel Transformer for Non-autoregressive End-to-End Speech Recognition
Paper and Code
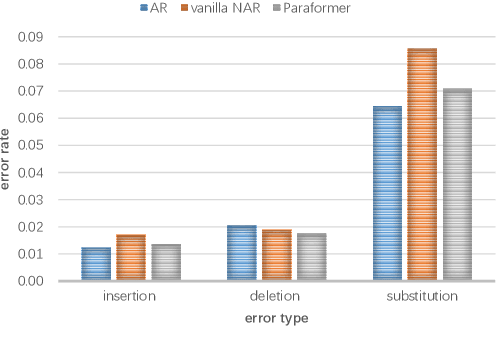
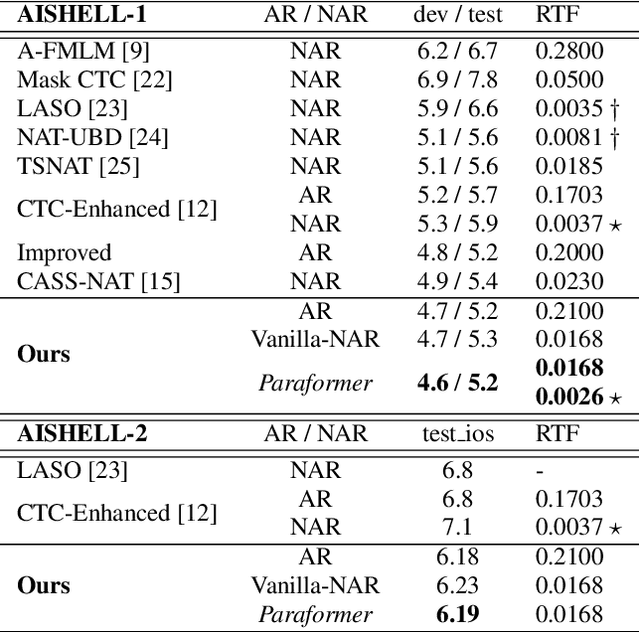
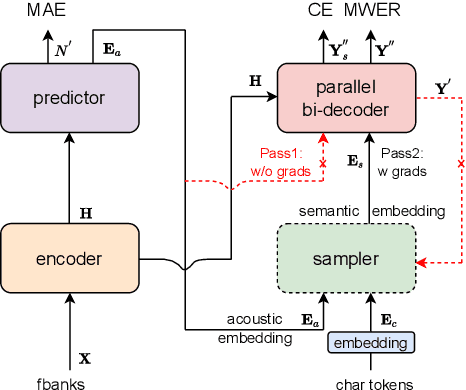
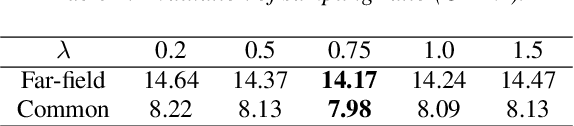
Transformers have recently dominated the ASR field. Although able to yield good performance, they involve an autoregressive (AR) decoder to generate tokens one by one, which is computationally inefficient. To speed up inference, non-autoregressive (NAR) methods, e.g. single-step NAR, were designed, to enable parallel generation. However, due to an independence assumption within the output tokens, performance of single-step NAR is inferior to that of AR models, especially with a large-scale corpus. There are two challenges to improving single-step NAR: Firstly to accurately predict the number of output tokens and extract hidden variables; secondly, to enhance modeling of interdependence between output tokens. To tackle both challenges, we propose a fast and accurate parallel transformer, termed Paraformer. This utilizes a continuous integrate-and-fire based predictor to predict the number of tokens and generate hidden variables. A glancing language model (GLM) sampler then generates semantic embeddings to enhance the NAR decoder's ability to model context interdependence. Finally, we design a strategy to generate negative samples for minimum word error rate training to further improve performance. Experiments using the public AISHELL-1, AISHELL-2 benchmark, and an industrial-level 20,000 hour task demonstrate that the proposed Paraformer can attain comparable performance to the state-of-the-art AR transformer, with more than 10x speedup.