 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
An Initialization Scheme for Meeting Separation with Spatial Mixture Models
Apr 04, 2022
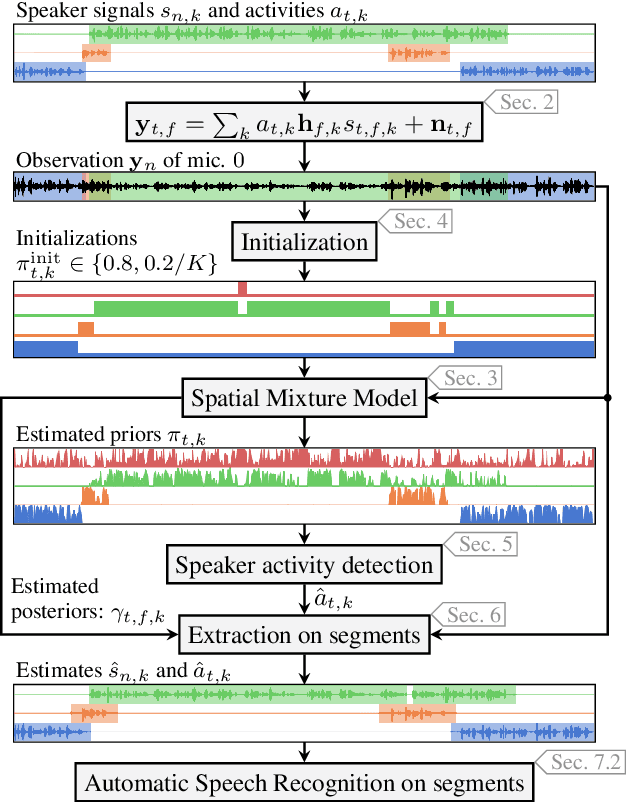
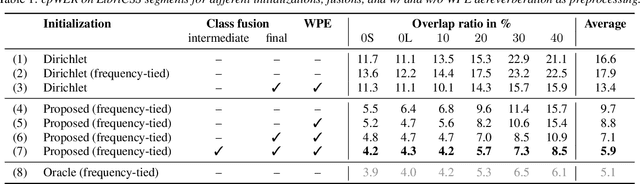
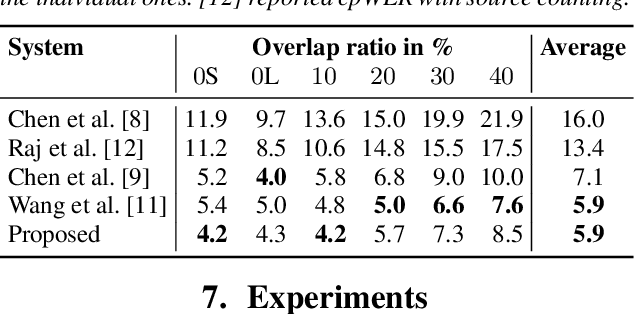
Spatial mixture model (SMM) supported acoustic beamforming has been extensively used for the separation of simultaneously active speakers. However, it has hardly been considered for the separation of meeting data, that are characterized by long recordings and only partially overlapping speech. In this contribution, we show that the fact that often only a single speaker is active can be utilized for a clever initialization of an SMM that employs time-varying class priors. In experiments on LibriCSS we show that the proposed initialization scheme achieves a significantly lower Word Error Rate (WER) on a downstream speech recognition task than a random initialization of the class probabilities by drawing from a Dirichlet distribution. With the only requirement that the number of speakers has to be known, we obtain a WER of 5.9 %, which is comparable to the best reported WER on this data set. Furthermore, the estimated speaker activity from the mixture model serves as a diarization based on spatial information.
LightSpeech: Lightweight and Fast Text to Speech with Neural Architecture Search
Feb 08, 2021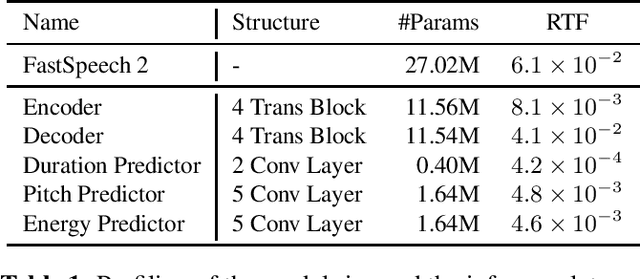
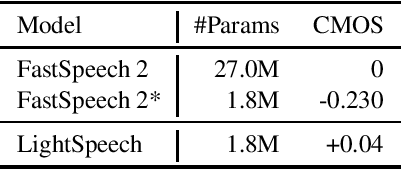

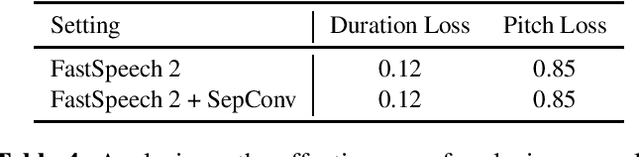
Text to speech (TTS) has been broadly used to synthesize natural and intelligible speech in different scenarios. Deploying TTS in various end devices such as mobile phones or embedded devices requires extremely small memory usage and inference latency. While non-autoregressive TTS models such as FastSpeech have achieved significantly faster inference speed than autoregressive models, their model size and inference latency are still large for the deployment in resource constrained devices. In this paper, we propose LightSpeech, which leverages neural architecture search~(NAS) to automatically design more lightweight and efficient models based on FastSpeech. We first profile the components of current FastSpeech model and carefully design a novel search space containing various lightweight and potentially effective architectures. Then NAS is utilized to automatically discover well performing architectures within the search space. Experiments show that the model discovered by our method achieves 15x model compression ratio and 6.5x inference speedup on CPU with on par voice quality. Audio demos are provided at https://speechresearch.github.io/lightspeech.
Efficient conformer: Progressive downsampling and grouped attention for automatic speech recognition
Sep 08, 2021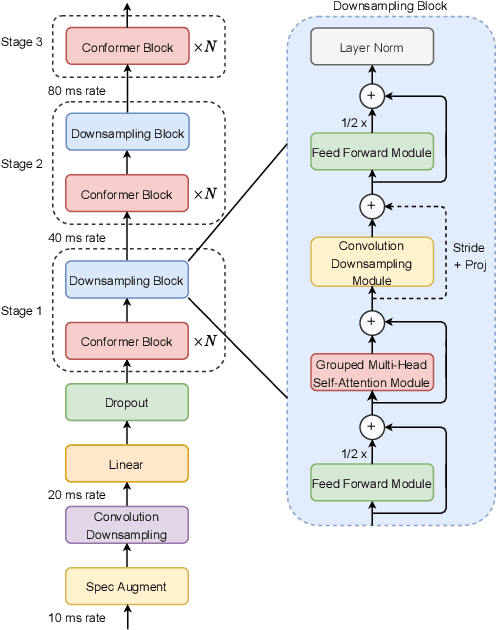
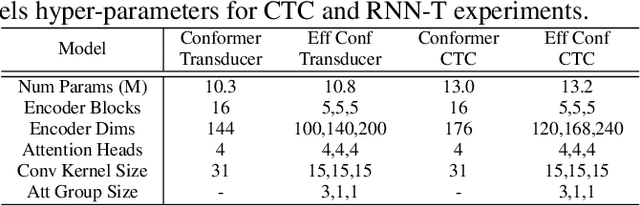

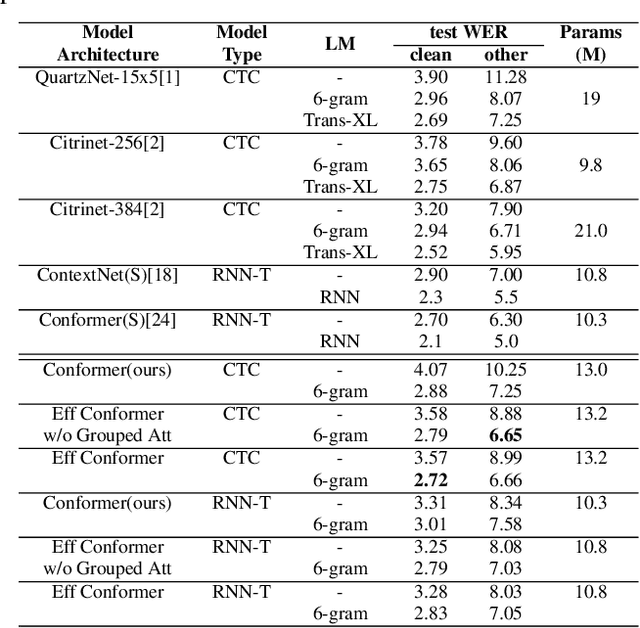
The recently proposed Conformer architecture has shown state-of-the-art performances in Automatic Speech Recognition by combining convolution with attention to model both local and global dependencies. In this paper, we study how to reduce the Conformer architecture complexity with a limited computing budget, leading to a more efficient architecture design that we call Efficient Conformer. We introduce progressive downsampling to the Conformer encoder and propose a novel attention mechanism named grouped attention, allowing us to reduce attention complexity from $O(n^{2}d)$ to $O(n^{2}d / g)$ for sequence length $n$, hidden dimension $d$ and group size parameter $g$. We also experiment the use of strided multi-head self-attention as a global downsampling operation. Our experiments are performed on the LibriSpeech dataset with CTC and RNN-Transducer losses. We show that within the same computing budget, the proposed architecture achieves better performances with faster training and decoding compared to the Conformer. Our 13M parameters CTC model achieves competitive WERs of 3.6%/9.0% without using a language model and 2.7%/6.7% with an external n-gram language model on the test-clean/test-other sets while being 29% faster than our CTC Conformer baseline at inference and 36% faster to train.
Punctuation Restoration in Spanish Customer Support Transcripts using Transfer Learning
May 27, 2022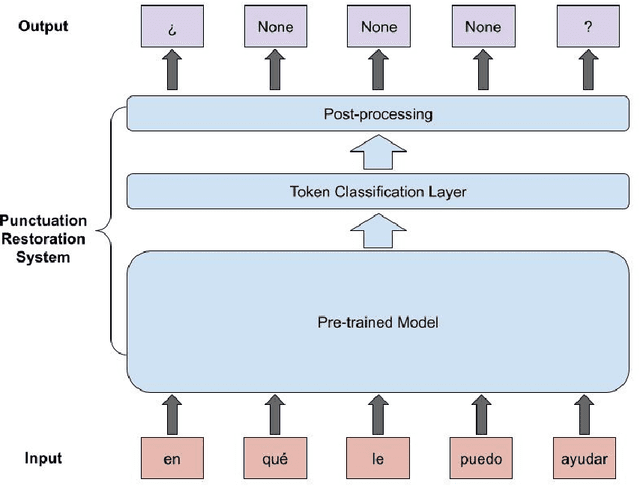

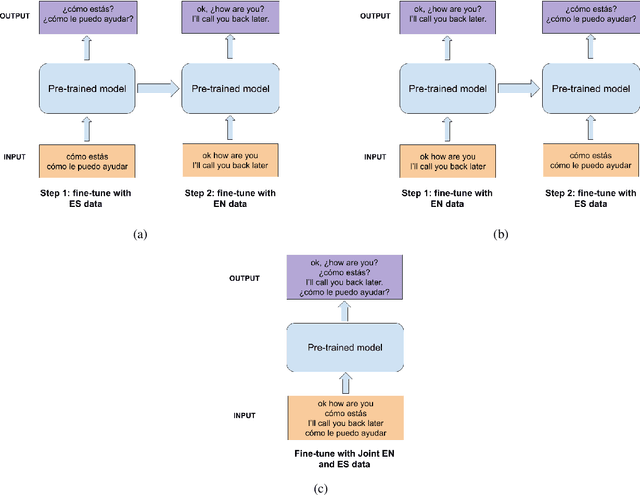
Automatic Speech Recognition (ASR) systems typically produce unpunctuated transcripts that have poor readability. In addition, building a punctuation restoration system is challenging for low-resource languages, especially for domain-specific applications. In this paper, we propose a Spanish punctuation restoration system designed for a real-time customer support transcription service. To address the data sparsity of Spanish transcripts in the customer support domain, we introduce two transfer-learning-based strategies: 1) domain adaptation using out-of-domain Spanish text data; 2) cross-lingual transfer learning leveraging in-domain English transcript data. Our experiment results show that these strategies improve the accuracy of the Spanish punctuation restoration system.
Improving the Training Recipe for a Robust Conformer-based Hybrid Model
Jun 26, 2022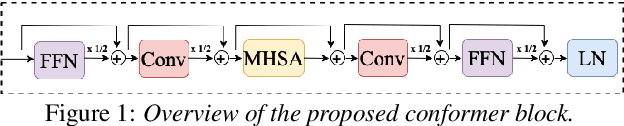
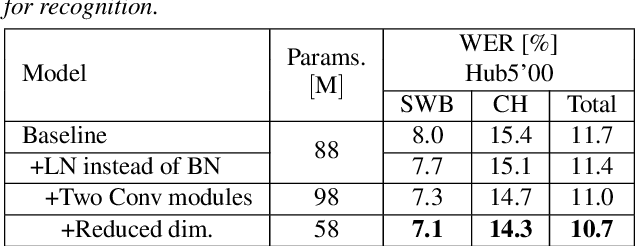
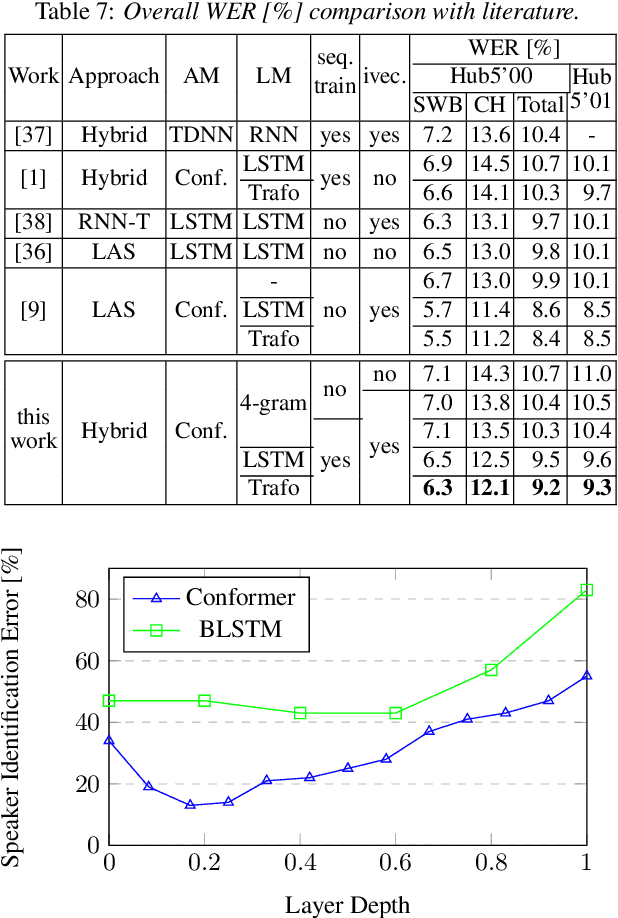
Speaker adaptation is important to build robust automatic speech recognition (ASR) systems. In this work, we investigate various methods for speaker adaptive training (SAT) based on feature-space approaches for a conformer-based acoustic model (AM) on the Switchboard 300h dataset. We propose a method, called Weighted-Simple-Add, which adds weighted speaker information vectors to the input of the multi-head self-attention module of the conformer AM. Using this method for SAT, we achieve 3.5% and 4.5% relative improvement in terms of WER on the CallHome part of Hub5'00 and Hub5'01 respectively. Moreover, we build on top of our previous work where we proposed a novel and competitive training recipe for a conformer-based hybrid AM. We extend and improve this recipe where we achieve 11% relative improvement in terms of word-error-rate (WER) on Switchboard 300h Hub5'00 dataset. We also make this recipe efficient by reducing the total number of parameters by 34% relative.
Contrastive Unsupervised Learning for Speech Emotion Recognition
Feb 12, 2021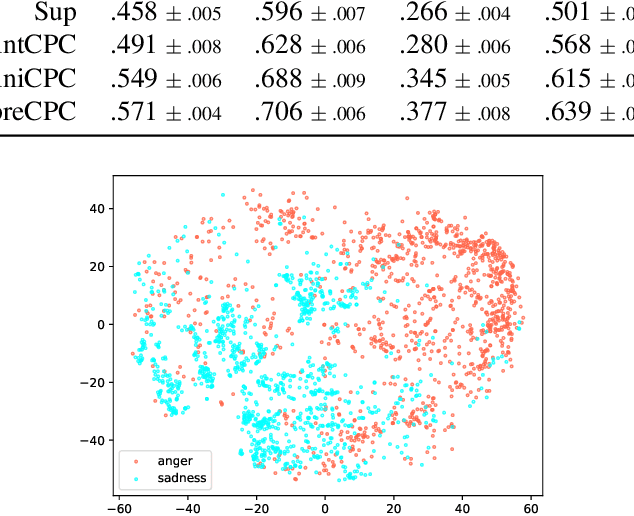

Speech emotion recognition (SER) is a key technology to enable more natural human-machine communication. However, SER has long suffered from a lack of public large-scale labeled datasets. To circumvent this problem, we investigate how unsupervised representation learning on unlabeled datasets can benefit SER. We show that the contrastive predictive coding (CPC) method can learn salient representations from unlabeled datasets, which improves emotion recognition performance. In our experiments, this method achieved state-of-the-art concordance correlation coefficient (CCC) performance for all emotion primitives (activation, valence, and dominance) on IEMOCAP. Additionally, on the MSP- Podcast dataset, our method obtained considerable performance improvements compared to baselines.
Self-Attention Generative Adversarial Network for Speech Enhancement
Oct 18, 2020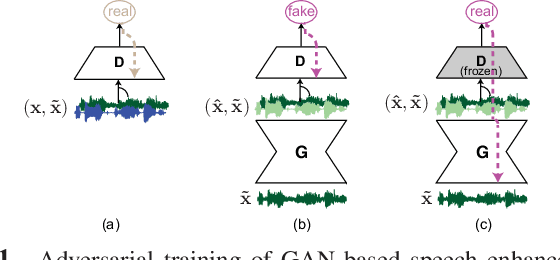
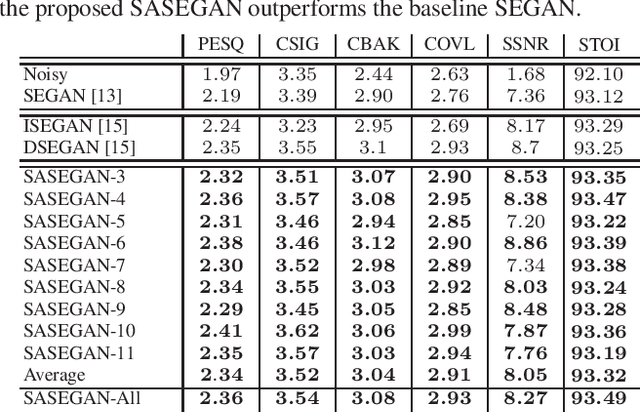
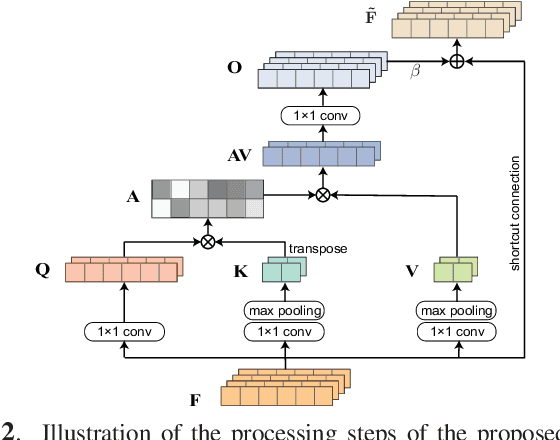
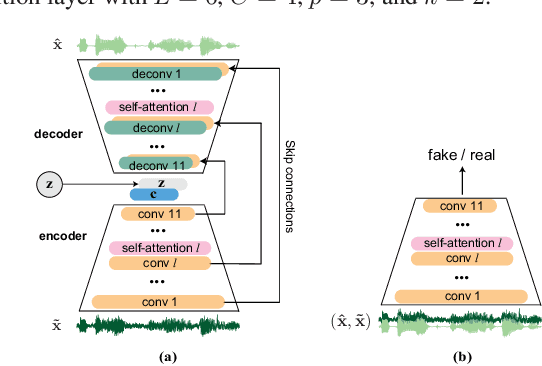
Existing generative adversarial networks (GANs) for speech enhancement solely rely on the convolution operation, which may obscure temporal dependencies across the sequence input. To remedy this issue, we propose a self-attention layer adapted from non-local attention, coupled with the convolutional and deconvolutional layers of a speech enhancement GAN (SEGAN) using raw signal input. Further, we empirically study the effect of placing the self-attention layer at the (de)convolutional layers with varying layer indices as well as at all of them when memory allows. Our experiments show that introducing self-attention to SEGAN leads to consistent improvement across the objective evaluation metrics of enhancement performance. Furthermore, applying at different (de)convolutional layers does not significantly alter performance, suggesting that it can be conveniently applied at the highest-level (de)convolutional layer with the smallest memory overhead.
Non-linear frequency warping using constant-Q transformation for speech emotion recognition
Feb 08, 2021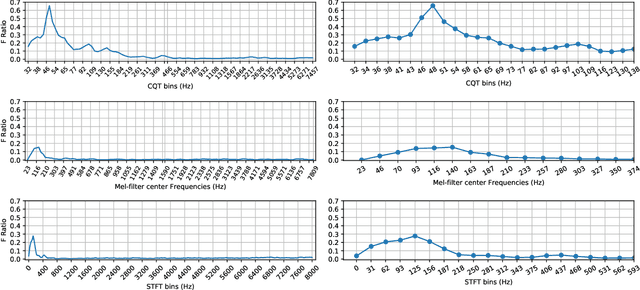
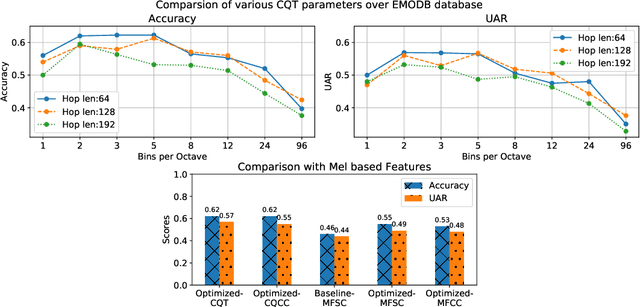

In this work, we explore the constant-Q transform (CQT) for speech emotion recognition (SER). The CQT-based time-frequency analysis provides variable spectro-temporal resolution with higher frequency resolution at lower frequencies. Since lower-frequency regions of speech signal contain more emotion-related information than higher-frequency regions, the increased low-frequency resolution of CQT makes it more promising for SER than standard short-time Fourier transform (STFT). We present a comparative analysis of short-term acoustic features based on STFT and CQT for SER with deep neural network (DNN) as a back-end classifier. We optimize different parameters for both features. The CQT-based features outperform the STFT-based spectral features for SER experiments. Further experiments with cross-corpora evaluation demonstrate that the CQT-based systems provide better generalization with out-of-domain training data.
Cross-Modal ASR Post-Processing System for Error Correction and Utterance Rejection
Jan 10, 2022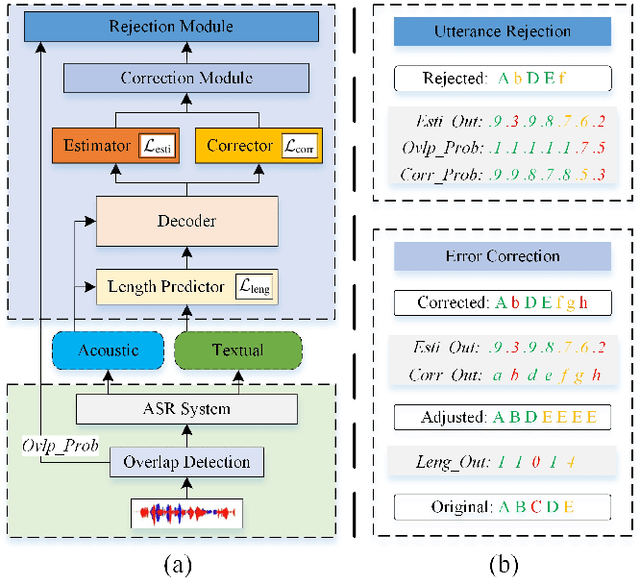

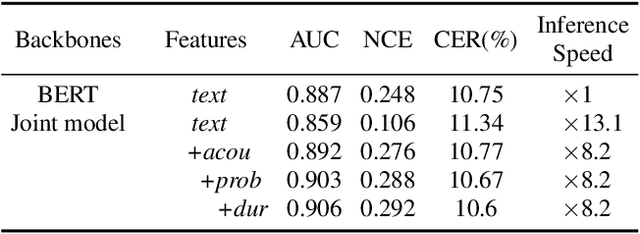
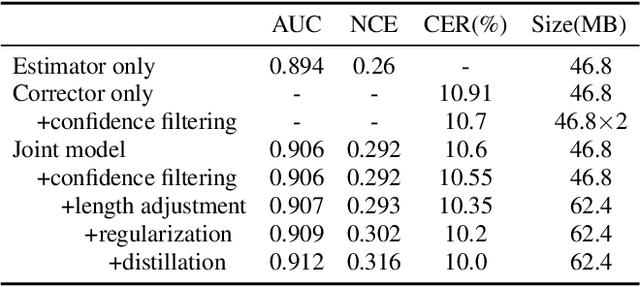
Although modern automatic speech recognition (ASR) systems can achieve high performance, they may produce errors that weaken readers' experience and do harm to downstream tasks. To improve the accuracy and reliability of ASR hypotheses, we propose a cross-modal post-processing system for speech recognizers, which 1) fuses acoustic features and textual features from different modalities, 2) joints a confidence estimator and an error corrector in multi-task learning fashion and 3) unifies error correction and utterance rejection modules. Compared with single-modal or single-task models, our proposed system is proved to be more effective and efficient. Experiment result shows that our post-processing system leads to more than 10% relative reduction of character error rate (CER) for both single-speaker and multi-speaker speech on our industrial ASR system, with about 1.7ms latency for each token, which ensures that extra latency introduced by post-processing is acceptable in streaming speech recognition.
Blind Estimation of Room Acoustic Parameters and Speech Transmission Index using MTF-based CNNs
Mar 14, 2021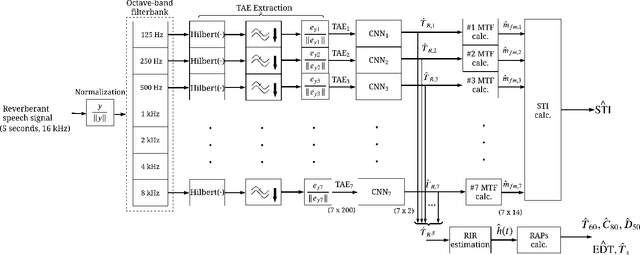
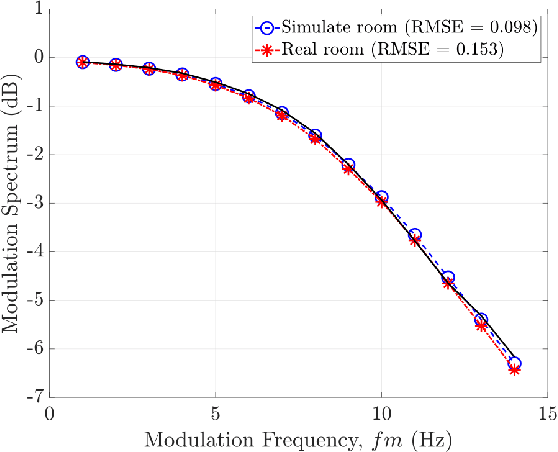
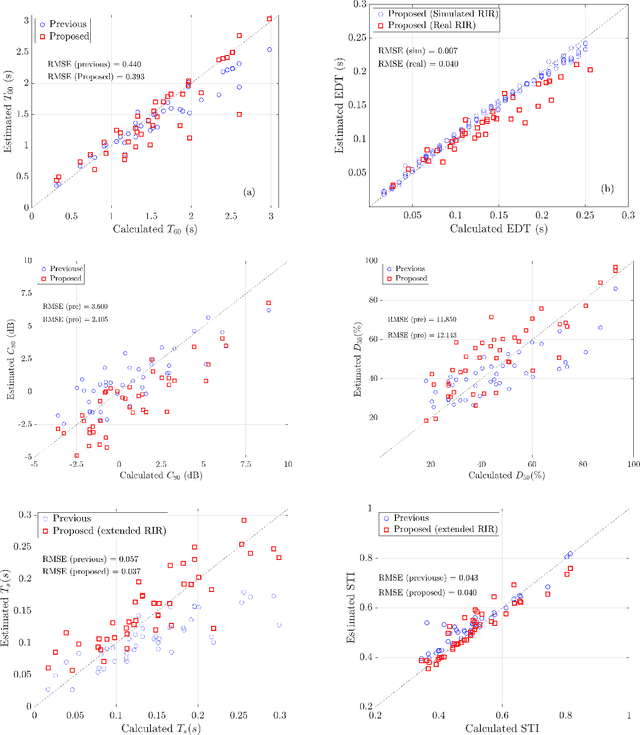
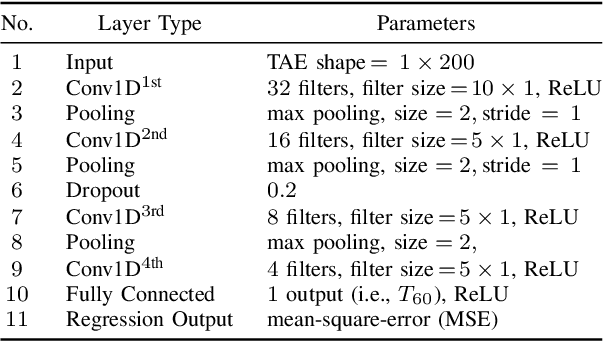
This paper proposes a blind estimation method based on the modulation transfer function and Schroeder model for estimating reverberation time in seven-octave bands. Therefore, the speech transmission index and five room-acoustic parameters can be estimated.