 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer Based Model for Spatiotemporal Feature Learning in EEG Emotion Recognition
Jun 09, 2026Electroencephalography (EEG) is a widely adopted technique for monitoring brain activity, offering valuable insights into neurological states due to its high temporal resolution and cost-effectiveness. To enhance the analysis of complex EEG data, we propose EEG-TransNet, an architecture designed to capture temporal, regional, and synchronous features of EEG signals. EEG-TransNet introduces three key modules: 1) a preprocessing and feature extraction module leveraging ResNet and wavelet-based denoising, 2) a Local Self-Attention Block for regional feature learning, and 3) a Fuzzy-Attention Synchronous Transformer (FAST) to model spatiotemporal dependencies. Through extensive experiments on three EEG datasets (BETA, SEED, and DepEEG), the proposed model consistently outperforms other methods in terms of classification accuracy and robustness across varying signal lengths. Ablation studies confirm the contribution of the Local Self-Attention Block in improving performance, and the inclusion of depthwise separable convolutions in the decoder reduces computational complexity while maintaining high accuracy. EEG-TransNet's ability to generalize across subjects with minimal performance variation highlights its potential as a robust tool for EEG-based brain activity classification and emotion recognition tasks.
TrioPose: Native Triple-Stream Diffusion Transformers for Pose-Guided Text-to-Image Generation
Jun 05, 2026Pose-guided text-to-image generation often suffers from limb distortions and feature crosstalk in complex multi-person scenarios. While existing UNet-based adapters struggle with long-range spatial dependencies, emerging Multimodal Diffusion Transformers (MM-DiTs) offer superior global modeling. However, naive signal concatenation in MM-DiTs severely disrupts pre-trained latent distributions. To address this, we propose TrioPose, a native pose-driven framework built upon the SD3.5M architecture. Specifically, we introduce a Triple-Stream Pose-Aware DiT (TSPA-DiT) that treats pose as an independent modality. It employs layer-wise activation and zero-initialized dual-residual injection to smoothly enforce geometric constraints while preserving pre-trained latent stability. To resolve severe multi-instance occlusions, we design a Learnable Relational Bias Mask that categorizes topological connectivity into fine-grained physical states, mapping them into continuous attention soft constraints to effectively decouple inter-instance interference. Furthermore, a Pose-Guided Spatial Loss Weighting strategy modulates the native diffusion objective using heatmap-derived error maps, focusing anatomical supervision strictly on distortion-prone regions. Extensive experiments demonstrate that TrioPose achieves state-of-the-art performance across challenging benchmarks, including Human-Art, CrowdPose, and OCHuman. Notably, it attains an AP of $64.33$ on Human-Art, representing a $30\%$ improvement over prior arts, while setting new standards for visual fidelity and text-image semantic alignment in complex multi-human generation.
Electronic Health Records-Based Data-Driven Diabetes Knowledge Unveiling and Risk Prognosis
Dec 05, 2024


In the healthcare sector, the application of deep learning technologies has revolutionized data analysis and disease forecasting. This is particularly evident in the field of diabetes, where the deep analysis of Electronic Health Records (EHR) has unlocked new opportunities for early detection and effective intervention strategies. Our research presents an innovative model that synergizes the capabilities of Bidirectional Long Short-Term Memory Networks-Conditional Random Field (BiLSTM-CRF) with a fusion of XGBoost and Logistic Regression. This model is designed to enhance the accuracy of diabetes risk prediction by conducting an in-depth analysis of electronic medical records data. The first phase of our approach involves employing BiLSTM-CRF to delve into the temporal characteristics and latent patterns present in EHR data. This method effectively uncovers the progression trends of diabetes, which are often hidden in the complex data structures of medical records. The second phase leverages the combined strength of XGBoost and Logistic Regression to classify these extracted features and evaluate associated risks. This dual approach facilitates a more nuanced and precise prediction of diabetes, outperforming traditional models, particularly in handling multifaceted and nonlinear medical datasets. Our research demonstrates a notable advancement in diabetes prediction over traditional methods, showcasing the effectiveness of our combined BiLSTM-CRF, XGBoost, and Logistic Regression model. This study highlights the value of data-driven strategies in clinical decision-making, equipping healthcare professionals with precise tools for early detection and intervention. By enabling personalized treatment and timely care, our approach signifies progress in incorporating advanced analytics in healthcare, potentially improving outcomes for diabetes and other chronic conditions.
Optimized CNNs for Rapid 3D Point Cloud Object Recognition
Dec 03, 2024



This study introduces a method for efficiently detecting objects within 3D point clouds using convolutional neural networks (CNNs). Our approach adopts a unique feature-centric voting mechanism to construct convolutional layers that capitalize on the typical sparsity observed in input data. We explore the trade-off between accuracy and speed across diverse network architectures and advocate for integrating an $\mathcal{L}_1$ penalty on filter activations to augment sparsity within intermediate layers. This research pioneers the proposal of sparse convolutional layers combined with $\mathcal{L}_1$ regularization to effectively handle large-scale 3D data processing. Our method's efficacy is demonstrated on the MVTec 3D-AD object detection benchmark. The Vote3Deep models, with just three layers, outperform the previous state-of-the-art in both laser-only approaches and combined laser-vision methods. Additionally, they maintain competitive processing speeds. This underscores our approach's capability to substantially enhance detection performance while ensuring computational efficiency suitable for real-time applications.
TRIZ Method for Urban Building Energy Optimization: GWO-SARIMA-LSTM Forecasting model
Oct 20, 2024



With the advancement of global climate change and sustainable development goals, urban building energy consumption optimization and carbon emission reduction have become the focus of research. Traditional energy consumption prediction methods often lack accuracy and adaptability due to their inability to fully consider complex energy consumption patterns, especially in dealing with seasonal fluctuations and dynamic changes. This study proposes a hybrid deep learning model that combines TRIZ innovation theory with GWO, SARIMA and LSTM to improve the accuracy of building energy consumption prediction. TRIZ plays a key role in model design, providing innovative solutions to achieve an effective balance between energy efficiency, cost and comfort by systematically analyzing the contradictions in energy consumption optimization. GWO is used to optimize the parameters of the model to ensure that the model maintains high accuracy under different conditions. The SARIMA model focuses on capturing seasonal trends in the data, while the LSTM model handles short-term and long-term dependencies in the data, further improving the accuracy of the prediction. The main contribution of this research is the development of a robust model that leverages the strengths of TRIZ and advanced deep learning techniques, improving the accuracy of energy consumption predictions. Our experiments demonstrate a significant 15% reduction in prediction error compared to existing models. This innovative approach not only enhances urban energy management but also provides a new framework for optimizing energy use and reducing carbon emissions, contributing to sustainable development.
Cross-Modal ASR Post-Processing System for Error Correction and Utterance Rejection
Jan 10, 2022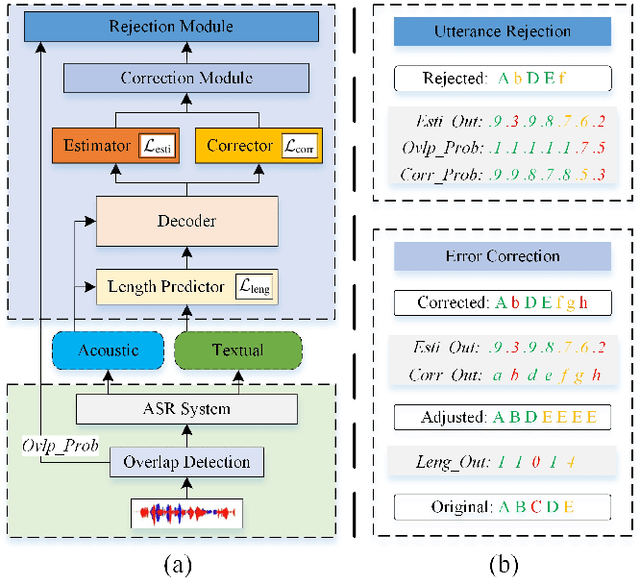

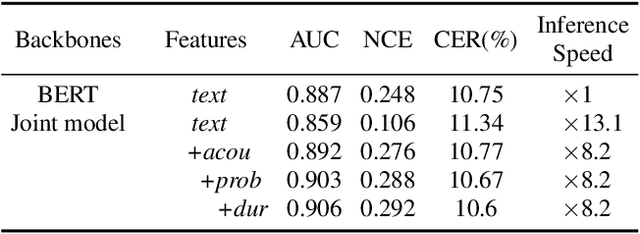
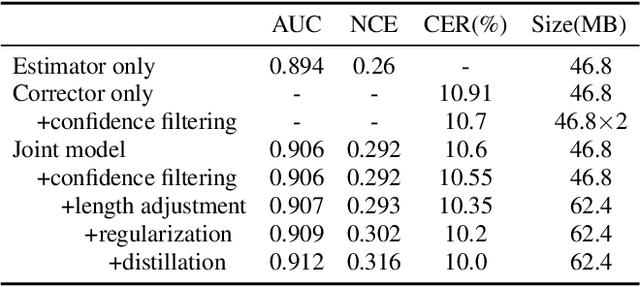
Although modern automatic speech recognition (ASR) systems can achieve high performance, they may produce errors that weaken readers' experience and do harm to downstream tasks. To improve the accuracy and reliability of ASR hypotheses, we propose a cross-modal post-processing system for speech recognizers, which 1) fuses acoustic features and textual features from different modalities, 2) joints a confidence estimator and an error corrector in multi-task learning fashion and 3) unifies error correction and utterance rejection modules. Compared with single-modal or single-task models, our proposed system is proved to be more effective and efficient. Experiment result shows that our post-processing system leads to more than 10% relative reduction of character error rate (CER) for both single-speaker and multi-speaker speech on our industrial ASR system, with about 1.7ms latency for each token, which ensures that extra latency introduced by post-processing is acceptable in streaming speech recognition.
FeCaffe: FPGA-enabled Caffe with OpenCL for Deep Learning Training and Inference on Intel Stratix 10
Nov 18, 2019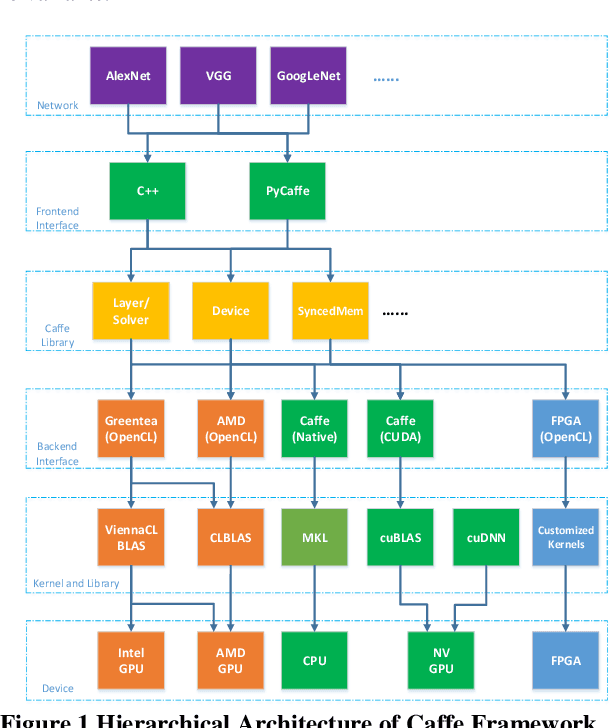
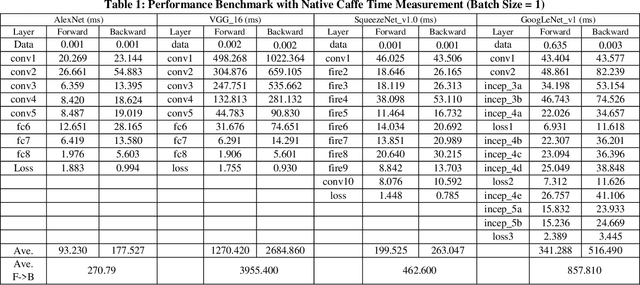
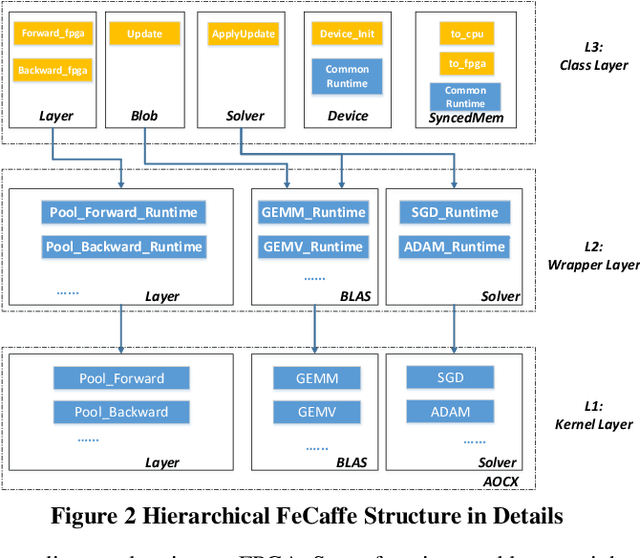
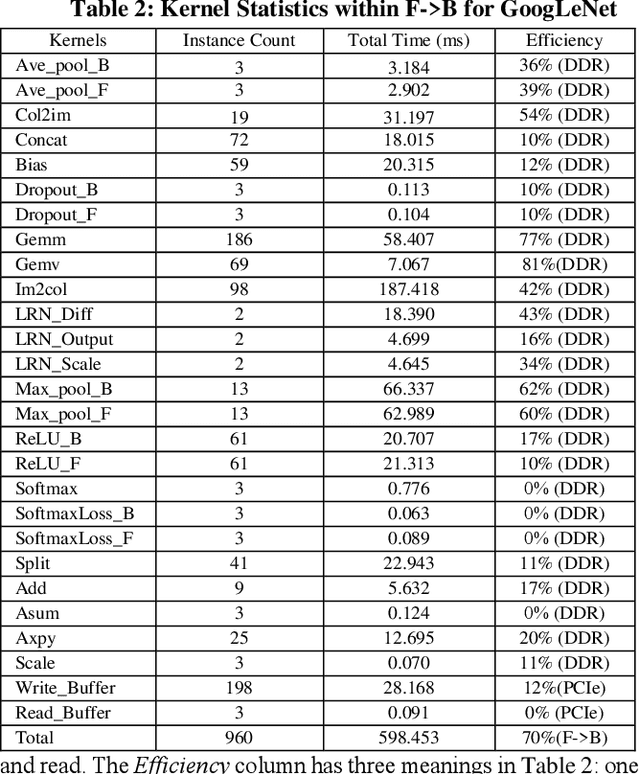
Deep learning and Convolutional Neural Network (CNN) have becoming increasingly more popular and important in both academic and industrial areas in recent years cause they are able to provide better accuracy and result in classification, detection and recognition areas, compared to traditional approaches. Currently, there are many popular frameworks in the market for deep learning development, such as Caffe, TensorFlow, Pytorch, and most of frameworks natively support CPU and consider GPU as the mainline accelerator by default. FPGA device, viewed as a potential heterogeneous platform, still cannot provide a comprehensive support for CNN development in popular frameworks, in particular to the training phase. In this paper, we firstly propose the FeCaffe, i.e. FPGA-enabled Caffe, a hierarchical software and hardware design methodology based on the Caffe to enable FPGA to support mainline deep learning development features, e.g. training and inference with Caffe. Furthermore, we provide some benchmarks with FeCaffe by taking some classical CNN networks as examples, and further analysis of kernel execution time in details accordingly. Finally, some optimization directions including FPGA kernel design, system pipeline, network architecture, user case application and heterogeneous platform levels, have been proposed gradually to improve FeCaffe performance and efficiency. The result demonstrates the proposed FeCaffe is capable of supporting almost full features during CNN network training and inference respectively with high degree of design flexibility, expansibility and reusability for deep learning development. Compared to prior studies, our architecture can support more network and training settings, and current configuration can achieve 6.4x and 8.4x average execution time improvement for forward and backward respectively for LeNet.