 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
GNN-SL: Sequence Labeling Based on Nearest Examples via GNN
Dec 05, 2022

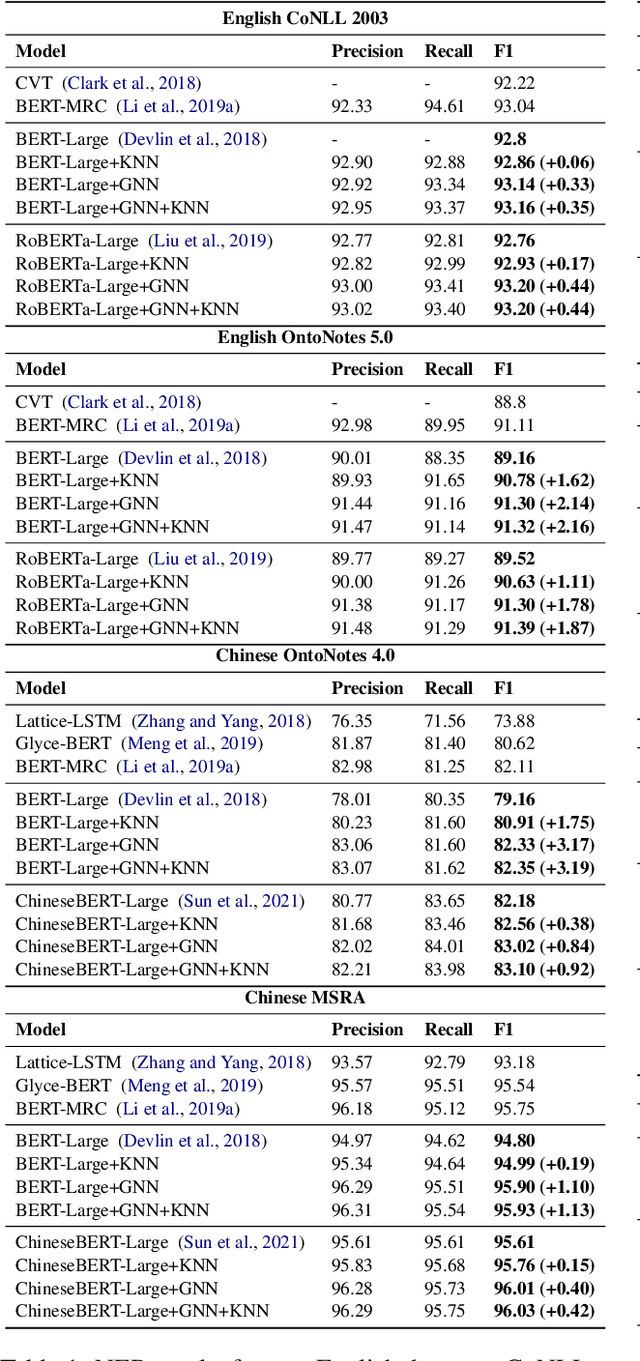
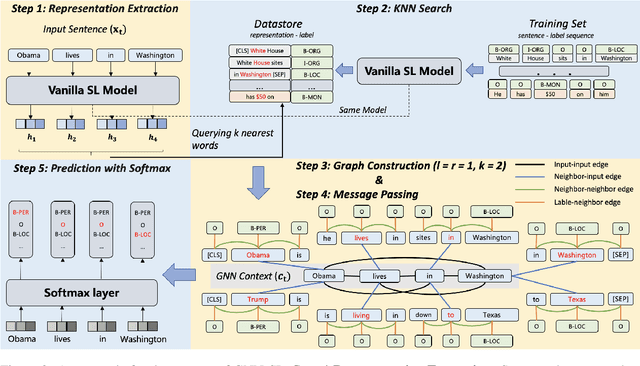
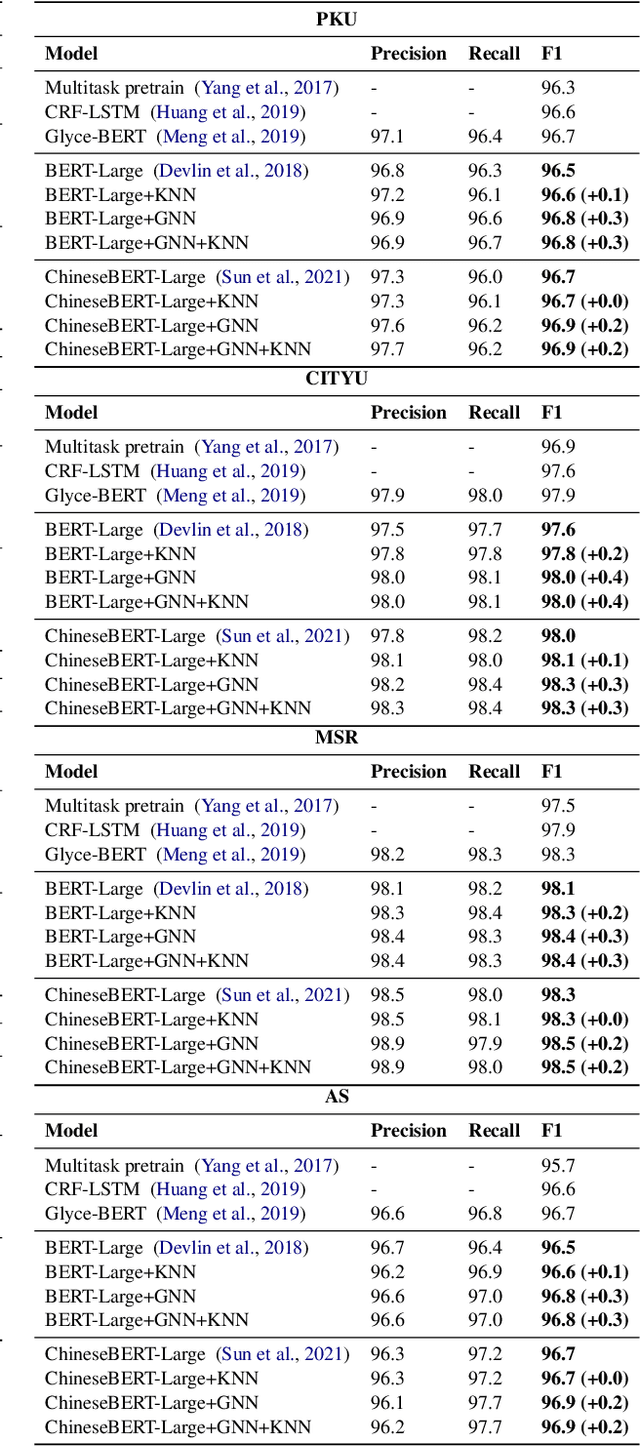
To better handle long-tail cases in the sequence labeling (SL) task, in this work, we introduce graph neural networks sequence labeling (GNN-SL), which augments the vanilla SL model output with similar tagging examples retrieved from the whole training set. Since not all the retrieved tagging examples benefit the model prediction, we construct a heterogeneous graph, and leverage graph neural networks (GNNs) to transfer information between the retrieved tagging examples and the input word sequence. The augmented node which aggregates information from neighbors is used to do prediction. This strategy enables the model to directly acquire similar tagging examples and improves the general quality of predictions. We conduct a variety of experiments on three typical sequence labeling tasks: Named Entity Recognition (NER), Part of Speech Tagging (POS), and Chinese Word Segmentation (CWS) to show the significant performance of our GNN-SL. Notably, GNN-SL achieves SOTA results of 96.9 (+0.2) on PKU, 98.3 (+0.4) on CITYU, 98.5 (+0.2) on MSR, and 96.9 (+0.2) on AS for the CWS task, and results comparable to SOTA performances on NER datasets, and POS datasets.
All-neural beamformer for continuous speech separation
Oct 13, 2021
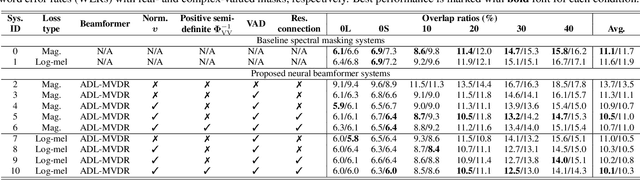

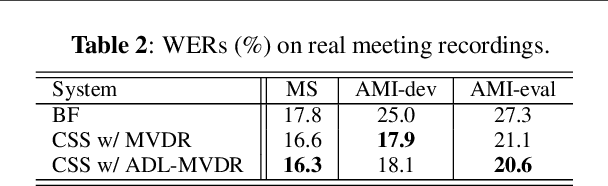
Continuous speech separation (CSS) aims to separate overlapping voices from a continuous influx of conversational audio containing an unknown number of utterances spoken by an unknown number of speakers. A common application scenario is transcribing a meeting conversation recorded by a microphone array. Prior studies explored various deep learning models for time-frequency mask estimation, followed by a minimum variance distortionless response (MVDR) filter to improve the automatic speech recognition (ASR) accuracy. The performance of these methods is fundamentally upper-bounded by MVDR's spatial selectivity. Recently, the all deep learning MVDR (ADL-MVDR) model was proposed for neural beamforming and demonstrated superior performance in a target speech extraction task using pre-segmented input. In this paper, we further adapt ADL-MVDR to the CSS task with several enhancements to enable end-to-end neural beamforming. The proposed system achieves significant word error rate reduction over a baseline spectral masking system on the LibriCSS dataset. Moreover, the proposed neural beamformer is shown to be comparable to a state-of-the-art MVDR-based system in real meeting transcription tasks, including AMI, while showing potentials to further simplify the runtime implementation and reduce the system latency with frame-wise processing.
Full Attention Bidirectional Deep Learning Structure for Single Channel Speech Enhancement
Aug 27, 2021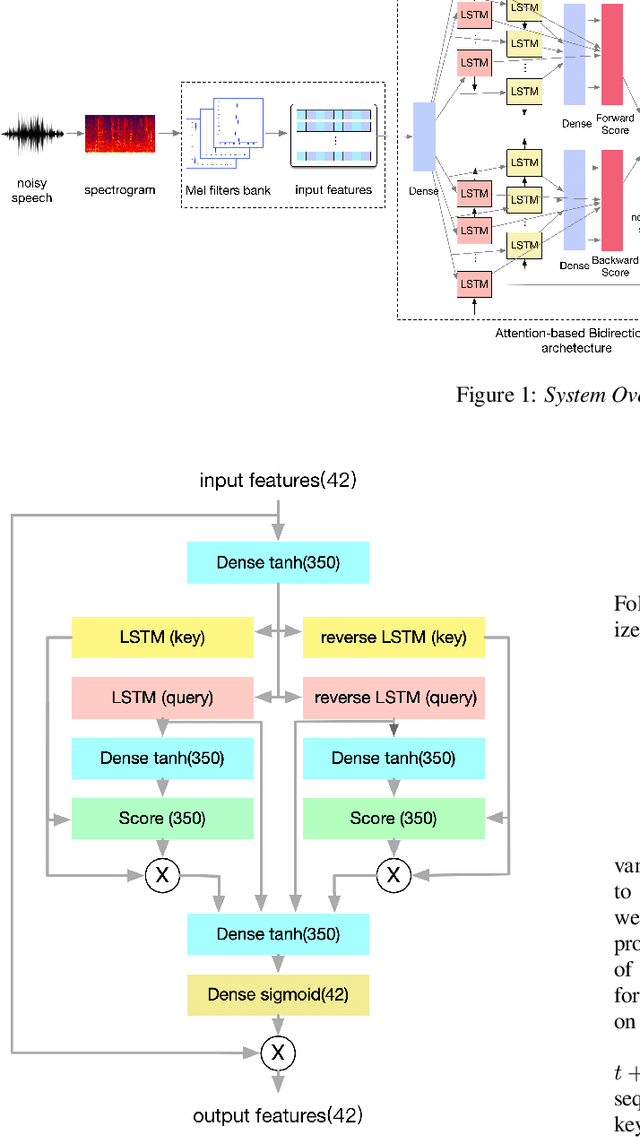

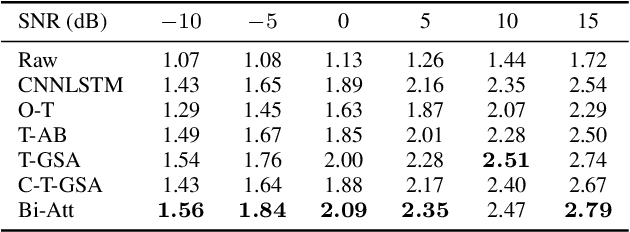

As the cornerstone of other important technologies, such as speech recognition and speech synthesis, speech enhancement is a critical area in audio signal processing. In this paper, a new deep learning structure for speech enhancement is demonstrated. The model introduces a "full" attention mechanism to a bidirectional sequence-to-sequence method to make use of latent information after each focal frame. This is an extension of the previous attention-based RNN method. The proposed bidirectional attention-based architecture achieves better performance in terms of speech quality (PESQ), compared with OM-LSA, CNN-LSTM, T-GSA and the unidirectional attention-based LSTM baseline.
Speech Analysis for Automatic Mania Assessment in Bipolar Disorder
Feb 05, 2022Bipolar disorder is a mental disorder that causes periods of manic and depressive episodes. In this work, we classify recordings from Bipolar Disorder corpus that contain 7 different tasks, into hypomania, mania, and remission classes using only speech features. We perform our experiments on splitted tasks from the interviews. Best results achieved on the model trained with 6th and 7th tasks together gives 0.53 UAR (unweighted average recall) result which is higher than the baseline results of the corpus.
Don't speak too fast: The impact of data bias on self-supervised speech models
Oct 15, 2021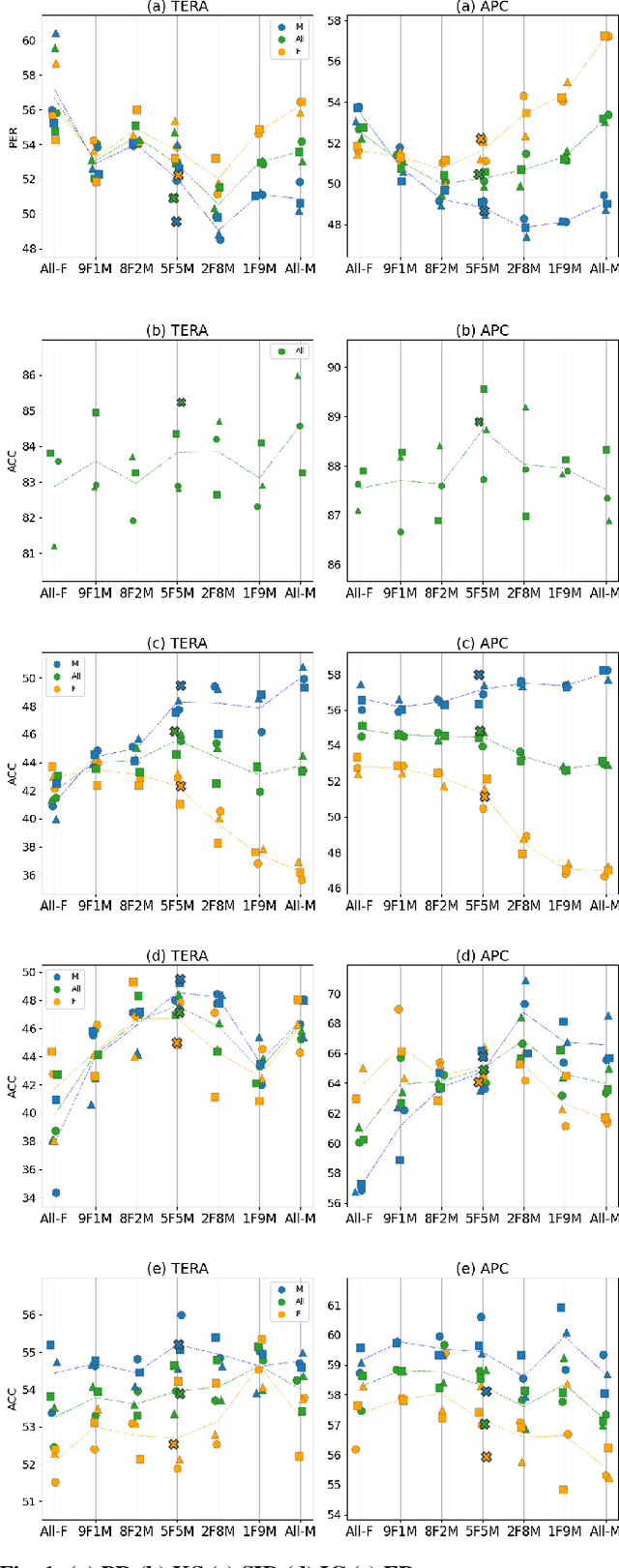
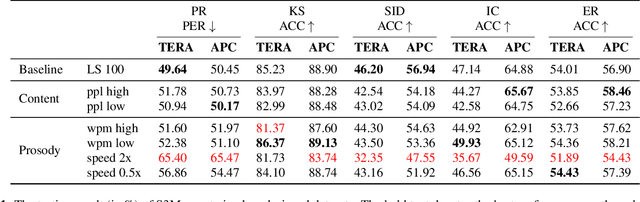
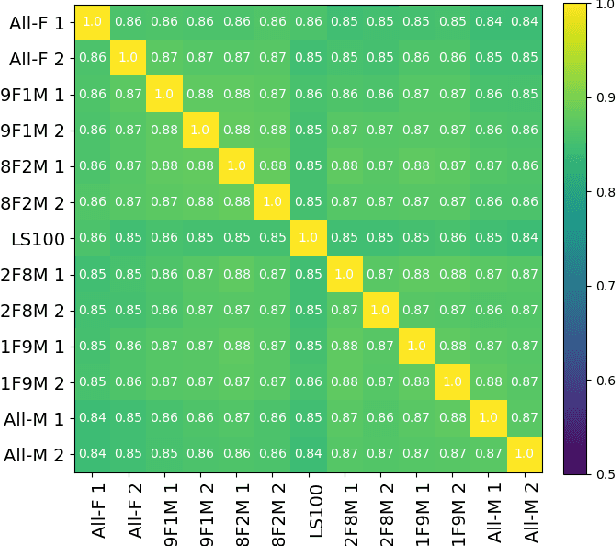
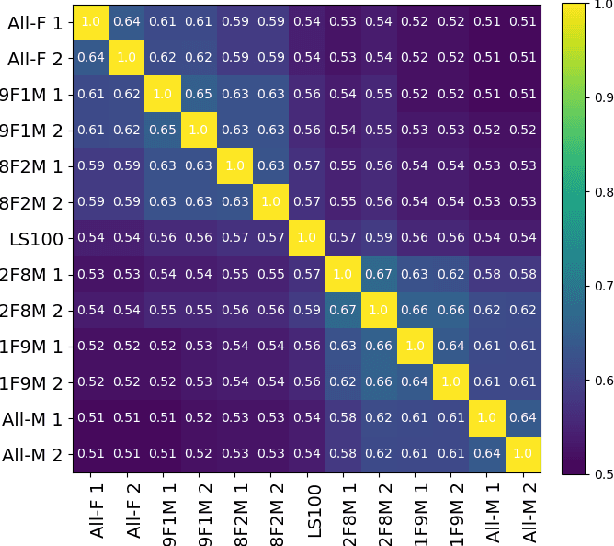
Self-supervised Speech Models (S3Ms) have been proven successful in many speech downstream tasks, like ASR. However, how pre-training data affects S3Ms' downstream behavior remains an unexplored issue. In this paper, we study how pre-training data affects S3Ms by pre-training models on biased datasets targeting different factors of speech, including gender, content, and prosody, and evaluate these pre-trained S3Ms on selected downstream tasks in SUPERB Benchmark. Our experiments show that S3Ms have tolerance toward gender bias. Moreover, we find that the content of speech has little impact on the performance of S3Ms across downstream tasks, but S3Ms do show a preference toward a slower speech rate.
Accidental Learners: Spoken Language Identification in Multilingual Self-Supervised Models
Nov 09, 2022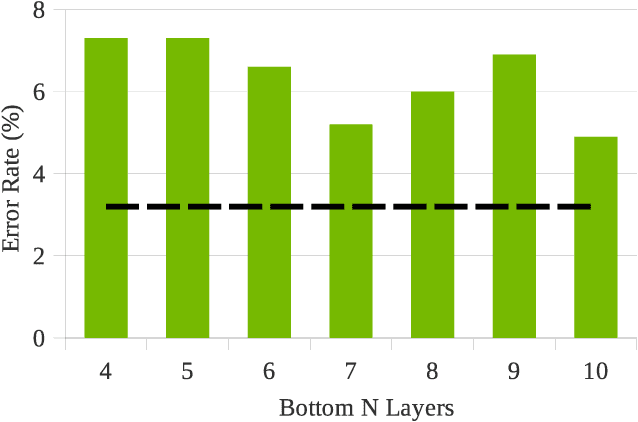
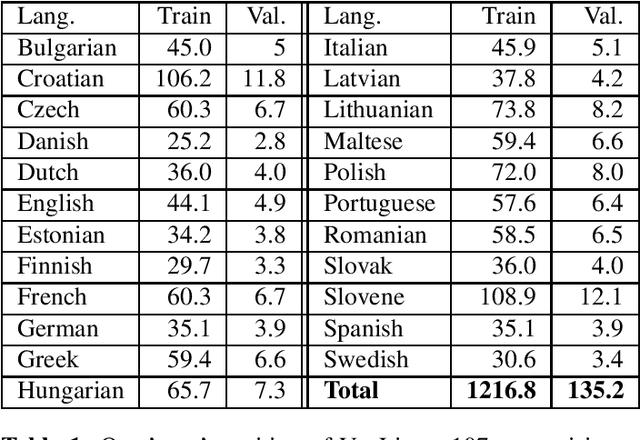
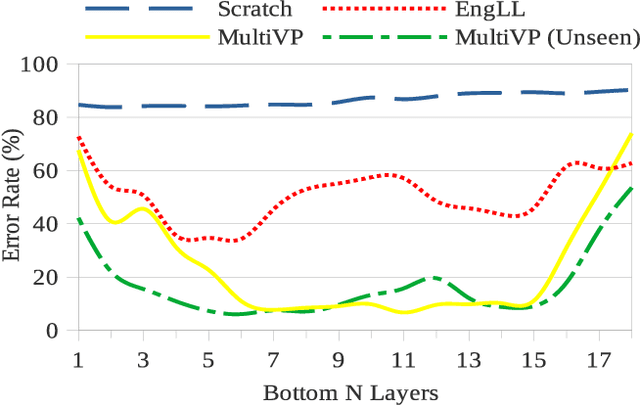
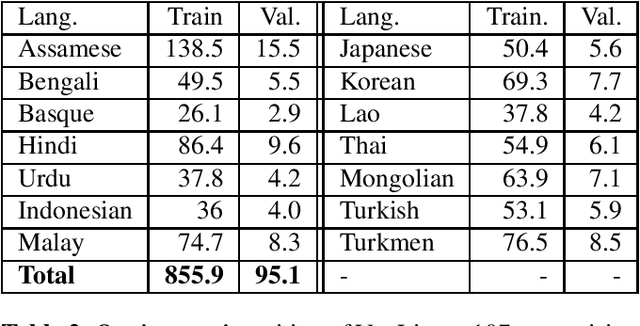
In this paper, we extend previous self-supervised approaches for language identification by experimenting with Conformer based architecture in a multilingual pre-training paradigm. We find that pre-trained speech models optimally encode language discriminatory information in lower layers. Further, we demonstrate that the embeddings obtained from these layers are significantly robust to classify unseen languages and different acoustic environments without additional training. After fine-tuning a pre-trained Conformer model on the VoxLingua107 dataset, we achieve results similar to current state-of-the-art systems for language identification. More, our model accomplishes this with 5x less parameters. We open-source the model through the NVIDIA NeMo toolkit.
A comparison of several AI techniques for authorship attribution on Romanian texts
Nov 09, 2022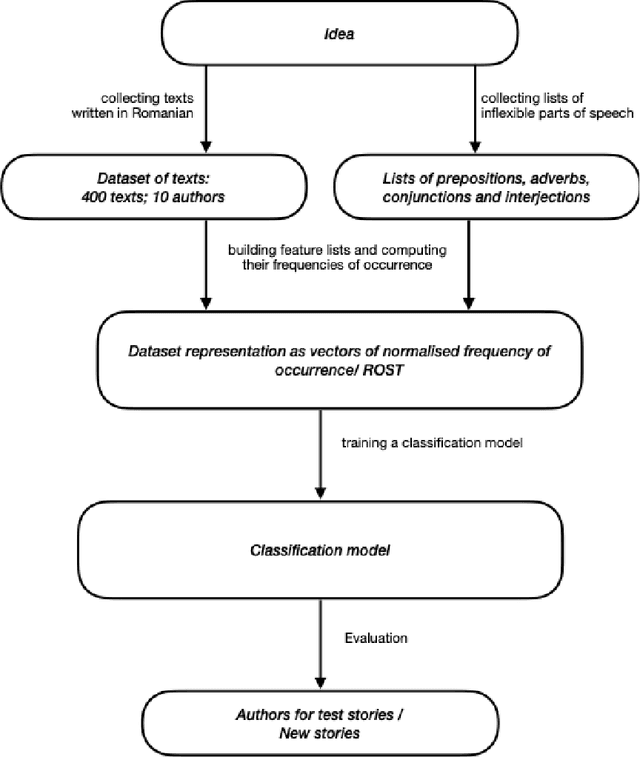
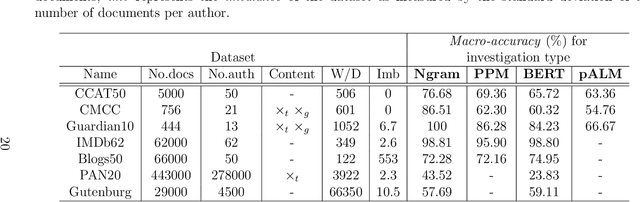
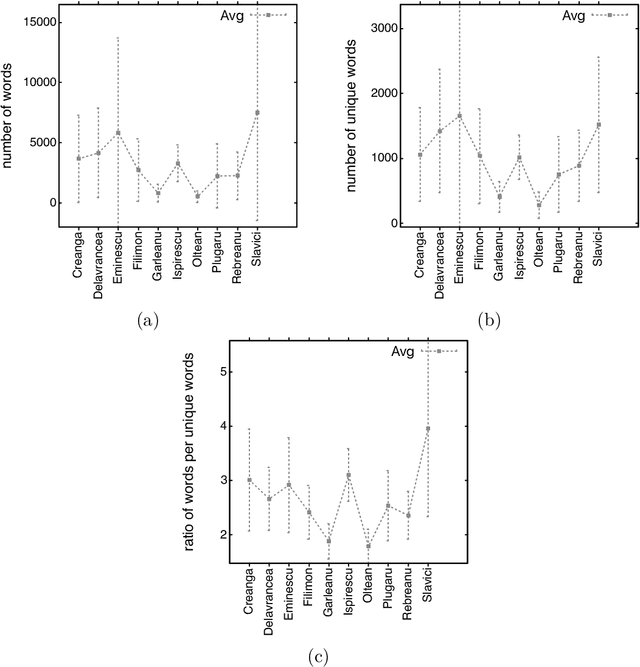
Determining the author of a text is a difficult task. Here we compare multiple AI techniques for classifying literary texts written by multiple authors by taking into account a limited number of speech parts (prepositions, adverbs, and conjunctions). We also introduce a new dataset composed of texts written in the Romanian language on which we have run the algorithms. The compared methods are Artificial Neural Networks, Support Vector Machines, Multi Expression Programming, Decision Trees with C5.0, and k-Nearest Neighbour. Numerical experiments show, first of all, that the problem is difficult, but some algorithms are able to generate decent errors on the test set.
PortaSpeech: Portable and High-Quality Generative Text-to-Speech
Sep 30, 2021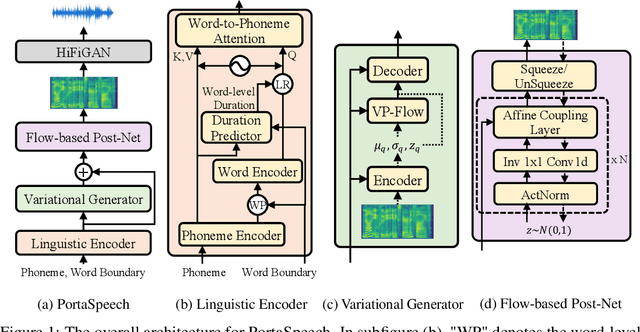
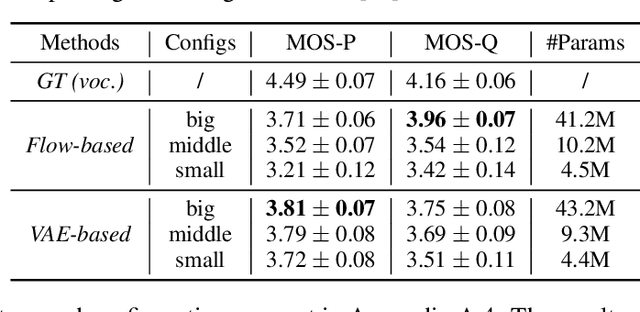
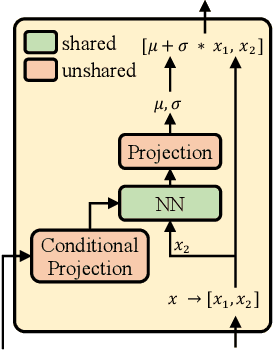
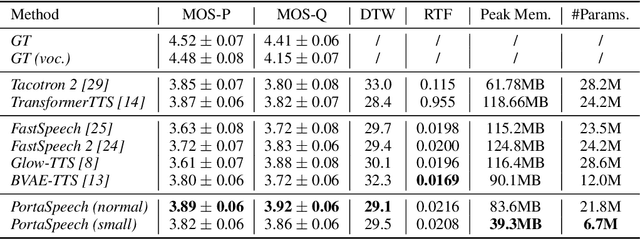
Non-autoregressive text-to-speech (NAR-TTS) models such as FastSpeech 2 and Glow-TTS can synthesize high-quality speech from the given text in parallel. After analyzing two kinds of generative NAR-TTS models (VAE and normalizing flow), we find that: VAE is good at capturing the long-range semantics features (e.g., prosody) even with small model size but suffers from blurry and unnatural results; and normalizing flow is good at reconstructing the frequency bin-wise details but performs poorly when the number of model parameters is limited. Inspired by these observations, to generate diverse speech with natural details and rich prosody using a lightweight architecture, we propose PortaSpeech, a portable and high-quality generative text-to-speech model. Specifically, 1) to model both the prosody and mel-spectrogram details accurately, we adopt a lightweight VAE with an enhanced prior followed by a flow-based post-net with strong conditional inputs as the main architecture. 2) To further compress the model size and memory footprint, we introduce the grouped parameter sharing mechanism to the affine coupling layers in the post-net. 3) To improve the expressiveness of synthesized speech and reduce the dependency on accurate fine-grained alignment between text and speech, we propose a linguistic encoder with mixture alignment combining hard inter-word alignment and soft intra-word alignment, which explicitly extracts word-level semantic information. Experimental results show that PortaSpeech outperforms other TTS models in both voice quality and prosody modeling in terms of subjective and objective evaluation metrics, and shows only a slight performance degradation when reducing the model parameters to 6.7M (about 4x model size and 3x runtime memory compression ratio compared with FastSpeech 2). Our extensive ablation studies demonstrate that each design in PortaSpeech is effective.
Transformer-Based Video Front-Ends for Audio-Visual Speech Recognition
Jan 25, 2022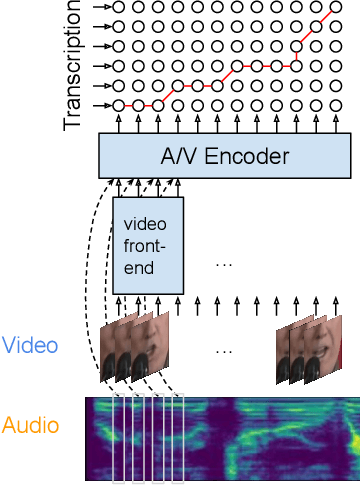
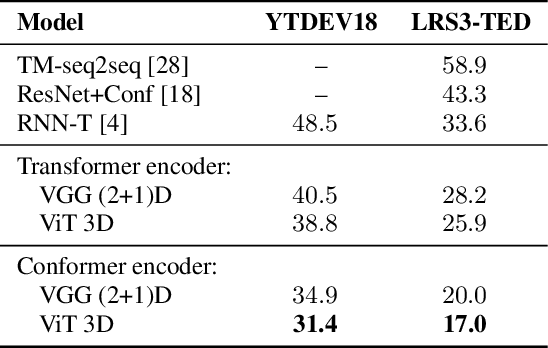
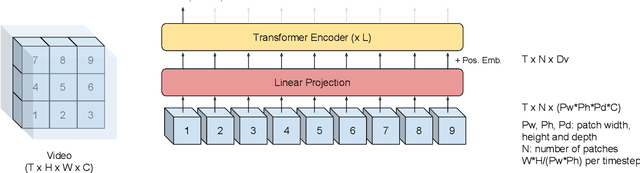
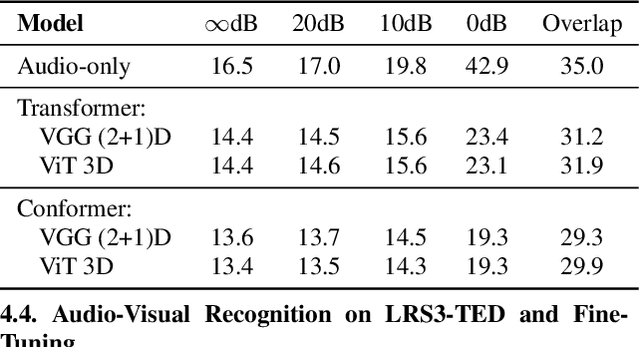
Audio-visual automatic speech recognition (AV-ASR) extends the speech recognition by introducing the video modality. In particular, the information contained in the motion of the speaker's mouth is used to augment the audio features. The video modality is traditionally processed with a 3D convolutional neural network (e.g. 3D version of VGG). Recently, image transformer networks arXiv:2010.11929 demonstrated the ability to extract rich visual features for the image classification task. In this work, we propose to replace the 3D convolution with a video transformer video feature extractor. We train our baselines and the proposed model on a large scale corpus of the YouTube videos. Then we evaluate the performance on a labeled subset of YouTube as well as on the public corpus LRS3-TED. Our best model video-only model achieves the performance of 34.9% WER on YTDEV18 and 19.3% on LRS3-TED which is a 10% and 9% relative improvements over the convolutional baseline. We achieve the state of the art performance of the audio-visual recognition on the LRS3-TED after fine-tuning our model (1.6% WER).
AdaSpeech 3: Adaptive Text to Speech for Spontaneous Style
Jul 06, 2021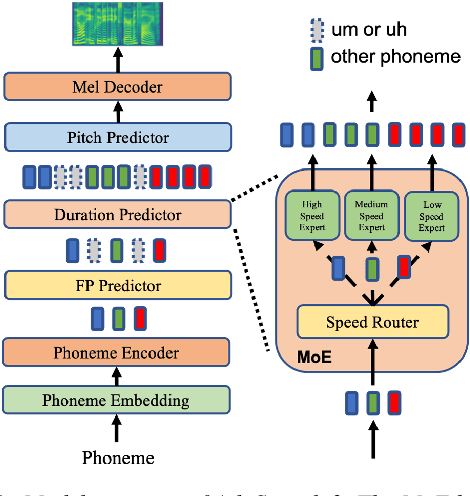
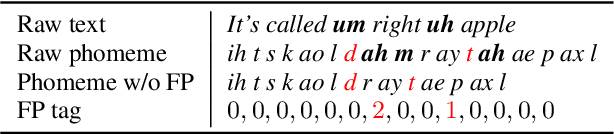

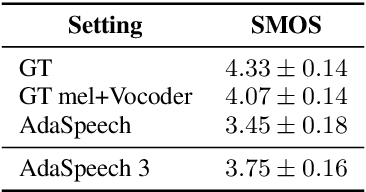
While recent text to speech (TTS) models perform very well in synthesizing reading-style (e.g., audiobook) speech, it is still challenging to synthesize spontaneous-style speech (e.g., podcast or conversation), mainly because of two reasons: 1) the lack of training data for spontaneous speech; 2) the difficulty in modeling the filled pauses (um and uh) and diverse rhythms in spontaneous speech. In this paper, we develop AdaSpeech 3, an adaptive TTS system that fine-tunes a well-trained reading-style TTS model for spontaneous-style speech. Specifically, 1) to insert filled pauses (FP) in the text sequence appropriately, we introduce an FP predictor to the TTS model; 2) to model the varying rhythms, we introduce a duration predictor based on mixture of experts (MoE), which contains three experts responsible for the generation of fast, medium and slow speech respectively, and fine-tune it as well as the pitch predictor for rhythm adaptation; 3) to adapt to other speaker timbre, we fine-tune some parameters in the decoder with few speech data. To address the challenge of lack of training data, we mine a spontaneous speech dataset to support our research this work and facilitate future research on spontaneous TTS. Experiments show that AdaSpeech 3 synthesizes speech with natural FP and rhythms in spontaneous styles, and achieves much better MOS and SMOS scores than previous adaptive TTS systems.