 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
VCSE: Time-Domain Visual-Contextual Speaker Extraction Network
Oct 09, 2022
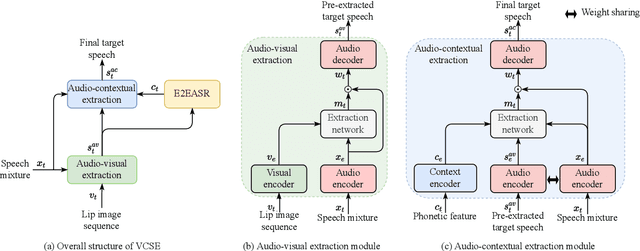
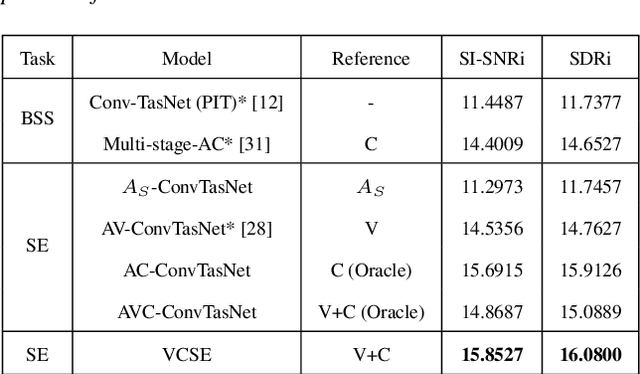
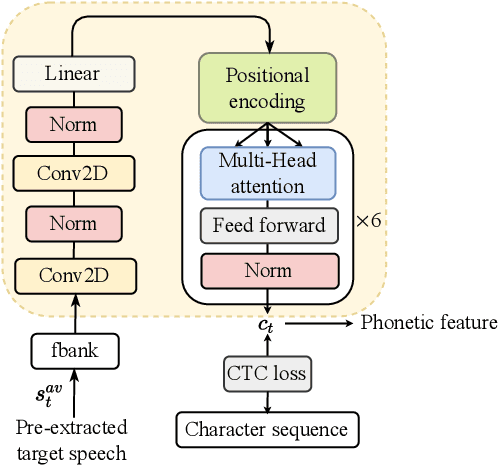
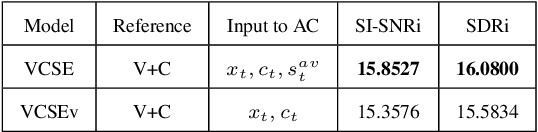
Speaker extraction seeks to extract the target speech in a multi-talker scenario given an auxiliary reference. Such reference can be auditory, i.e., a pre-recorded speech, visual, i.e., lip movements, or contextual, i.e., phonetic sequence. References in different modalities provide distinct and complementary information that could be fused to form top-down attention on the target speaker. Previous studies have introduced visual and contextual modalities in a single model. In this paper, we propose a two-stage time-domain visual-contextual speaker extraction network named VCSE, which incorporates visual and self-enrolled contextual cues stage by stage to take full advantage of every modality. In the first stage, we pre-extract a target speech with visual cues and estimate the underlying phonetic sequence. In the second stage, we refine the pre-extracted target speech with the self-enrolled contextual cues. Experimental results on the real-world Lip Reading Sentences 3 (LRS3) database demonstrate that our proposed VCSE network consistently outperforms other state-of-the-art baselines.
VoiceFixer: Toward General Speech Restoration With Neural Vocoder
Sep 28, 2021
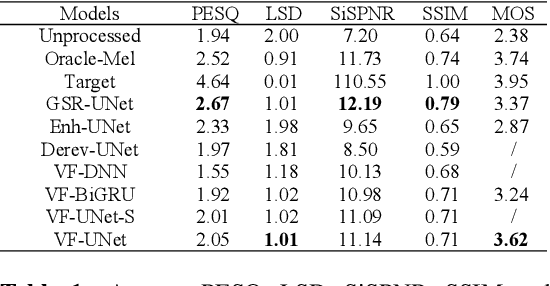
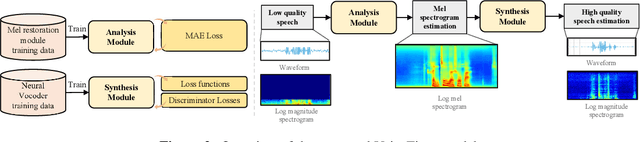
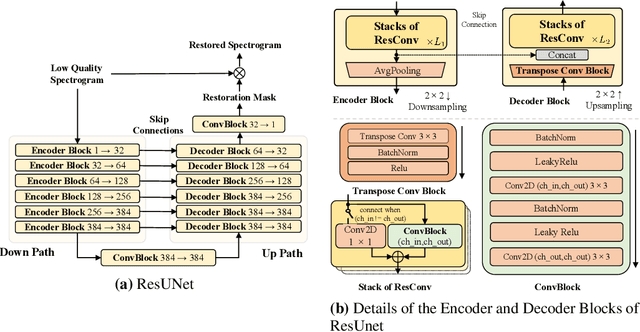
Speech restoration aims to remove distortions in speech signals. Prior methods mainly focus on single-task speech restoration(SSR), such as speech enhancement or speech declipping. However, SSR systems only focus on one task and do not address the general speech restoration problem. Previous SSR systems also have limited performance in speech restoration tasks such as speech super-resolution. To overcome those limitations, we propose a general speech restoration(GSR) task that attempts to remove multiple distortions simultaneously. Furthermore, we propose VoiceFixer, a generative framework to address the GSR tasks. VoiceFixer consists of an analysis stage and a synthesis stage to mimic the speech analysis and comprehension of the human auditory system. We employ a ResUNet to model the analysis module and a neural vocoder to model the synthesis module. We evaluate VoiceFixer with additive noise, room reverberation, low-resolution, and clipping distortions. Our baseline GSR model achieves a 0.499 higher mean opinion score(MOS) than the speech enhancement SSR model. VoiceFixer further surpasses the GSR baseline model on the MOS score by 0.256. In addition, we observe that VoiceFixer generalizes well to severely degraded real speech recordings, indicating its potential in restoring old movies and historical speeches. The source code is available at https://github.com/haoheliu/voicefixer_main.
A Comparison of Temporal Encoders for Neuromorphic Keyword Spotting with Few Neurons
Jan 24, 2023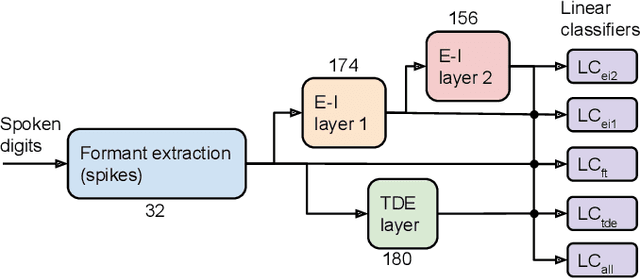
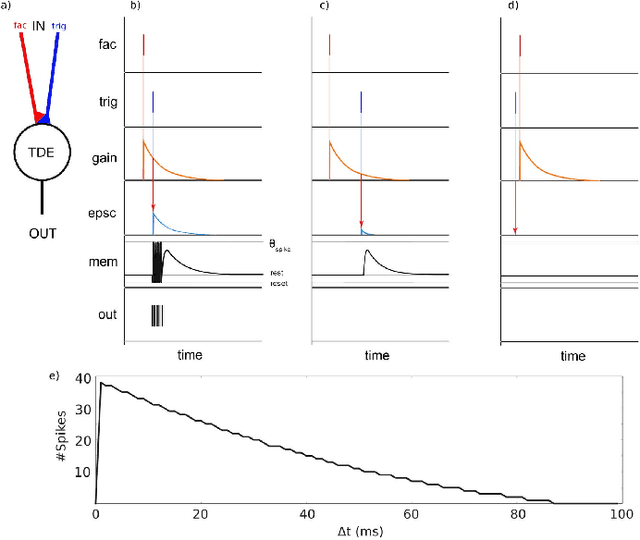
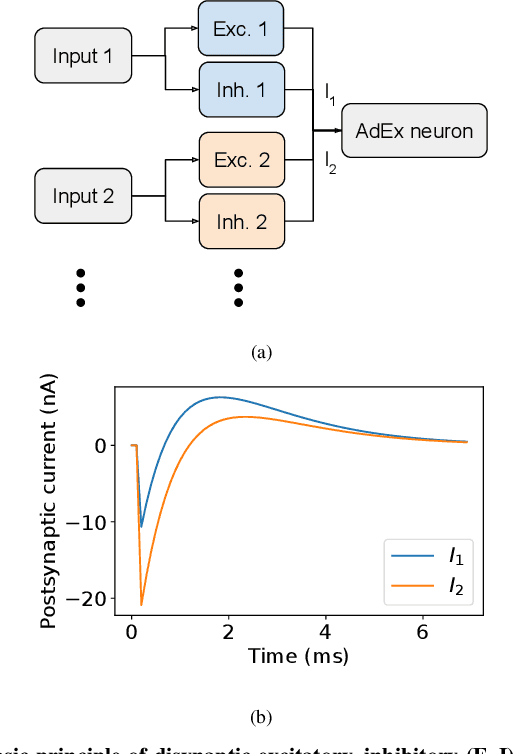
With the expansion of AI-powered virtual assistants, there is a need for low-power keyword spotting systems providing a "wake-up" mechanism for subsequent computationally expensive speech recognition. One promising approach is the use of neuromorphic sensors and spiking neural networks (SNNs) implemented in neuromorphic processors for sparse event-driven sensing. However, this requires resource-efficient SNN mechanisms for temporal encoding, which need to consider that these systems process information in a streaming manner, with physical time being an intrinsic property of their operation. In this work, two candidate neurocomputational elements for temporal encoding and feature extraction in SNNs described in recent literature - the spiking time-difference encoder (TDE) and disynaptic excitatory-inhibitory (E-I) elements - are comparatively investigated in a keyword-spotting task on formants computed from spoken digits in the TIDIGITS dataset. While both encoders improve performance over direct classification of the formant features in the training data, enabling a complete binary classification with a logistic regression model, they show no clear improvements on the test set. Resource-efficient keyword spotting applications may benefit from the use of these encoders, but further work on methods for learning the time constants and weights is required to investigate their full potential.
Summary on the ISCSLP 2022 Chinese-English Code-Switching ASR Challenge
Oct 13, 2022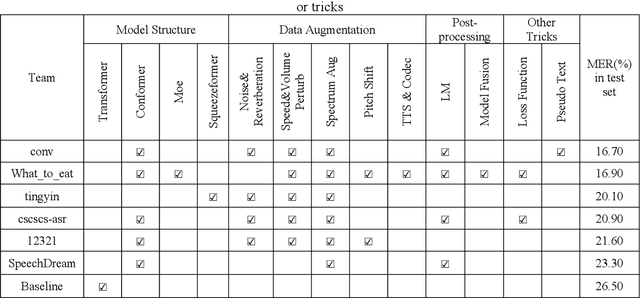
Code-switching automatic speech recognition becomes one of the most challenging and the most valuable scenarios of automatic speech recognition, due to the code-switching phenomenon between multilingual language and the frequent occurrence of code-switching phenomenon in daily life. The ISCSLP 2022 Chinese-English Code-Switching Automatic Speech Recognition (CSASR) Challenge aims to promote the development of code-switching automatic speech recognition. The ISCSLP 2022 CSASR challenge provided two training sets, TAL_CSASR corpus and MagicData-RAMC corpus, a development and a test set for participants, which are used for CSASR model training and evaluation. Along with the challenge, we also provide the baseline system performance for reference. As a result, more than 40 teams participated in this challenge, and the winner team achieved 16.70% Mixture Error Rate (MER) performance on the test set and has achieved 9.8% MER absolute improvement compared with the baseline system. In this paper, we will describe the datasets, the associated baselines system and the requirements, and summarize the CSASR challenge results and major techniques and tricks used in the submitted systems.
Speaker Adaption with Intuitive Prosodic Features for Statistical Parametric Speech Synthesis
Mar 02, 2022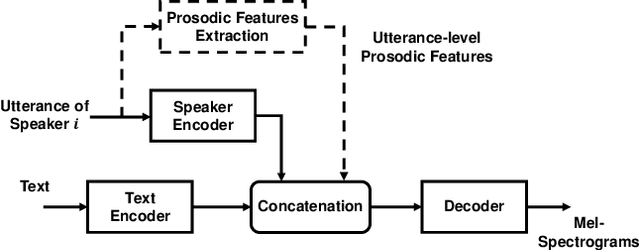
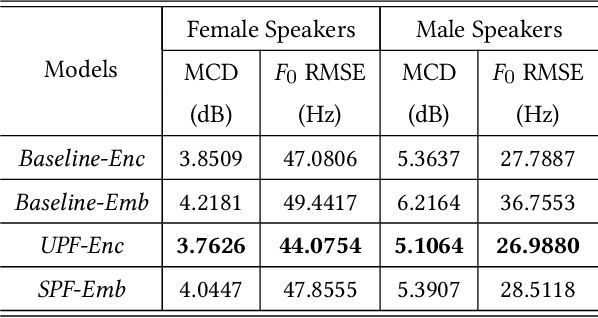
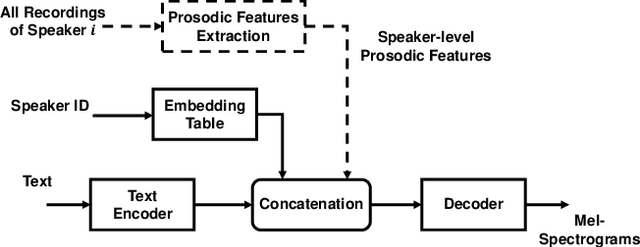
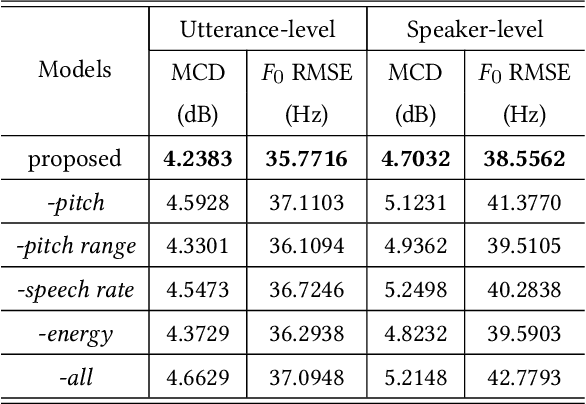
In this paper, we propose a method of speaker adaption with intuitive prosodic features for statistical parametric speech synthesis. The intuitive prosodic features employed in this method include pitch, pitch range, speech rate and energy considering that they are directly related with the overall prosodic characteristics of different speakers. The intuitive prosodic features are extracted at utterance-level or speaker-level, and are further integrated into the existing speaker-encoding-based and speaker-embedding-based adaptation frameworks respectively. The acoustic models are sequence-to-sequence ones based on Tacotron2. Intuitive prosodic features are concatenated with text encoder outputs and speaker vectors for decoding acoustic features.Experimental results have demonstrated that our proposed methods can achieve better objective and subjective performance than the baseline methods without intuitive prosodic features. Besides, the proposed speaker adaption method with utterance-level prosodic features has achieved the best similarity of synthetic speech among all compared methods.
Beyond Statistical Similarity: Rethinking Metrics for Deep Generative Models in Engineering Design
Feb 06, 2023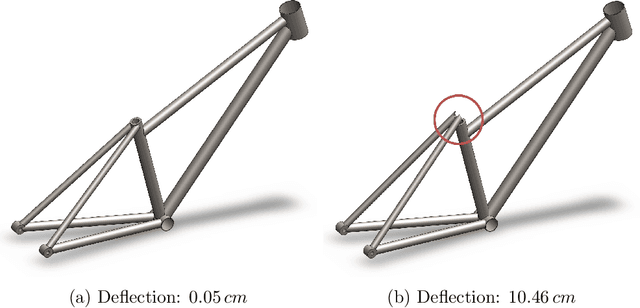
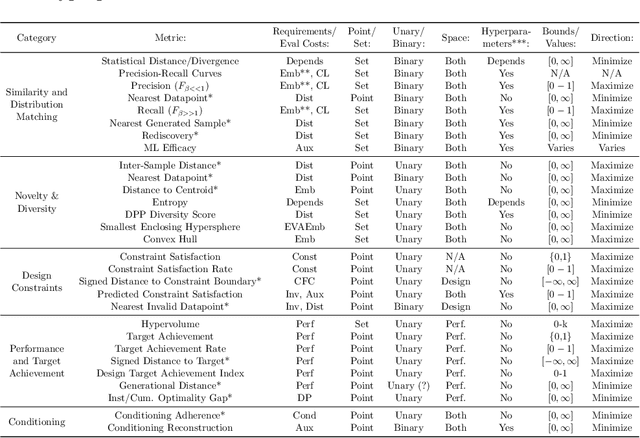
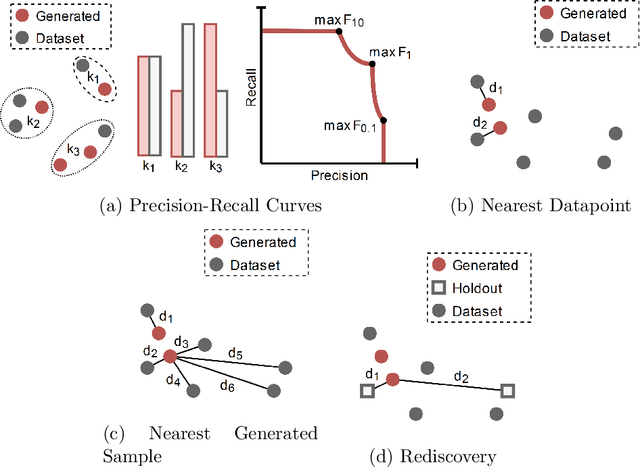
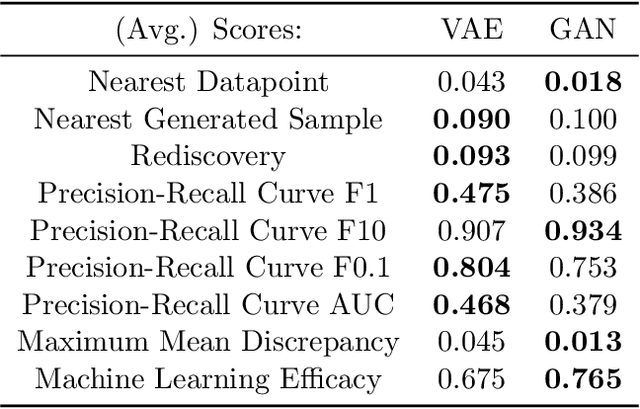
Deep generative models, such as Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), Diffusion Models, and Transformers, have shown great promise in a variety of applications, including image and speech synthesis, natural language processing, and drug discovery. However, when applied to engineering design problems, evaluating the performance of these models can be challenging, as traditional statistical metrics based on likelihood may not fully capture the requirements of engineering applications. This paper doubles as a review and a practical guide to evaluation metrics for deep generative models (DGMs) in engineering design. We first summarize well-accepted `classic' evaluation metrics for deep generative models grounded in machine learning theory and typical computer science applications. Using case studies, we then highlight why these metrics seldom translate well to design problems but see frequent use due to the lack of established alternatives. Next, we curate a set of design-specific metrics which have been proposed across different research communities and can be used for evaluating deep generative models. These metrics focus on unique requirements in design and engineering, such as constraint satisfaction, functional performance, novelty, and conditioning. We structure our review and discussion as a set of practical selection criteria and usage guidelines. Throughout our discussion, we apply the metrics to models trained on simple 2-dimensional example problems. Finally, to illustrate the selection process and classic usage of the presented metrics, we evaluate three deep generative models on a multifaceted bicycle frame design problem considering performance target achievement, design novelty, and geometric constraints. We publicly release the code for the datasets, models, and metrics used throughout the paper at decode.mit.edu/projects/metrics/.
A Bayesian Permutation training deep representation learning method for speech enhancement with variational autoencoder
Jan 24, 2022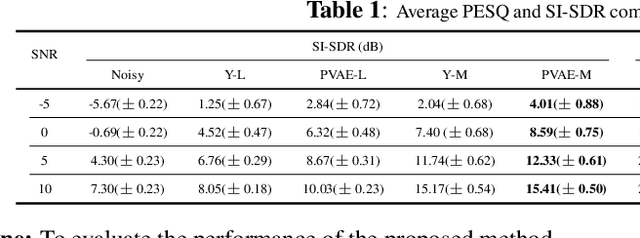
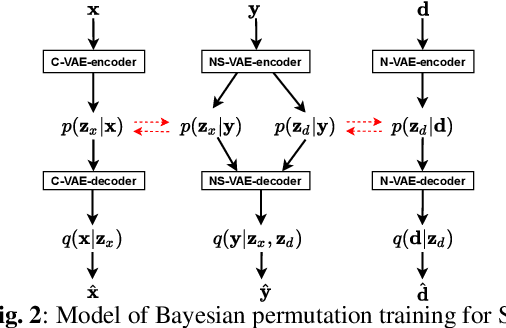
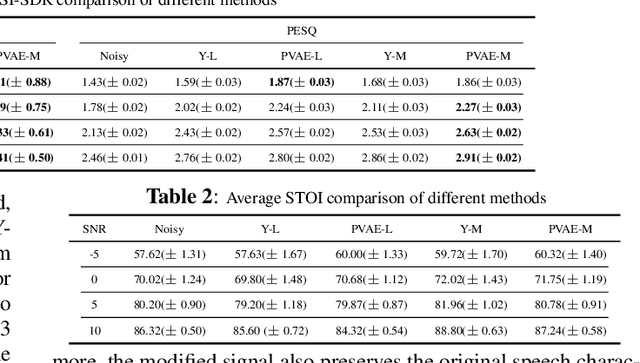
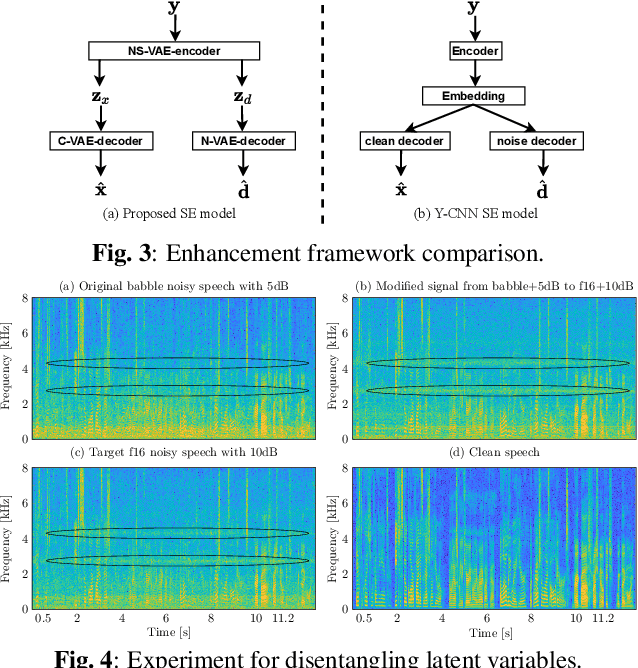
Recently, variational autoencoder (VAE), a deep representation learning (DRL) model, has been used to perform speech enhancement (SE). However, to the best of our knowledge, current VAE-based SE methods only apply VAE to the model speech signal, while noise is modeled using the traditional non-negative matrix factorization (NMF) model. One of the most important reasons for using NMF is that these VAE-based methods cannot disentangle the speech and noise latent variables from the observed signal. Based on Bayesian theory, this paper derives a novel variational lower bound for VAE, which ensures that VAE can be trained in supervision, and can disentangle speech and noise latent variables from the observed signal. This means that the proposed method can apply the VAE to model both speech and noise signals, which is totally different from the previous VAE-based SE works. More specifically, the proposed DRL method can learn to impose speech and noise signal priors to different sets of latent variables for SE. The experimental results show that the proposed method can not only disentangle speech and noise latent variables from the observed signal but also obtain a higher scale-invariant signal-to-distortion ratio and speech quality score than the similar deep neural network-based (DNN) SE method.
Quotations, Coreference Resolution, and Sentiment Annotations in Croatian News Articles: An Exploratory Study
Dec 14, 2022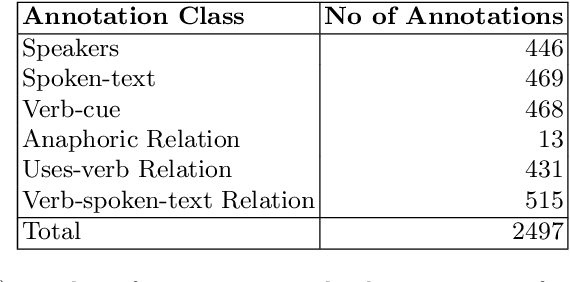
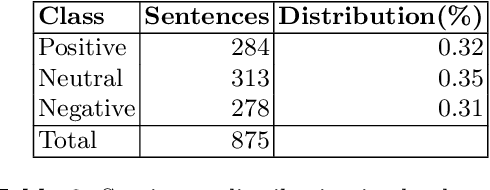
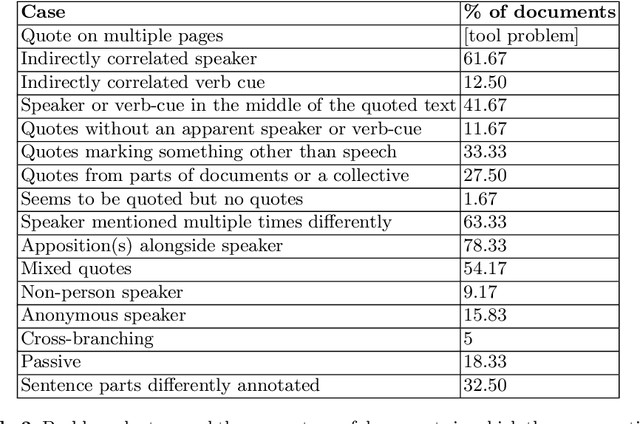
This paper presents a corpus annotated for the task of direct-speech extraction in Croatian. The paper focuses on the annotation of the quotation, co-reference resolution, and sentiment annotation in SETimes news corpus in Croatian and on the analysis of its language-specific differences compared to English. From this, a list of the phenomena that require special attention when performing these annotations is derived. The generated corpus with quotation features annotations can be used for multiple tasks in the field of Natural Language Processing.
Speaker Normalization for Self-supervised Speech Emotion Recognition
Feb 02, 2022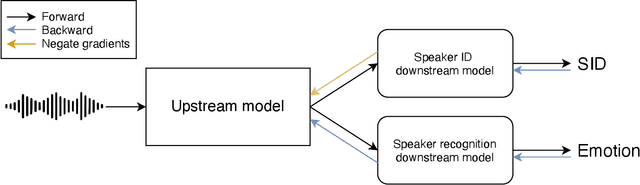
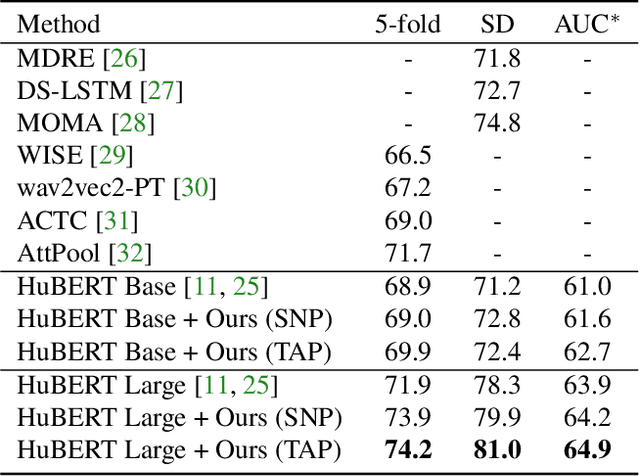
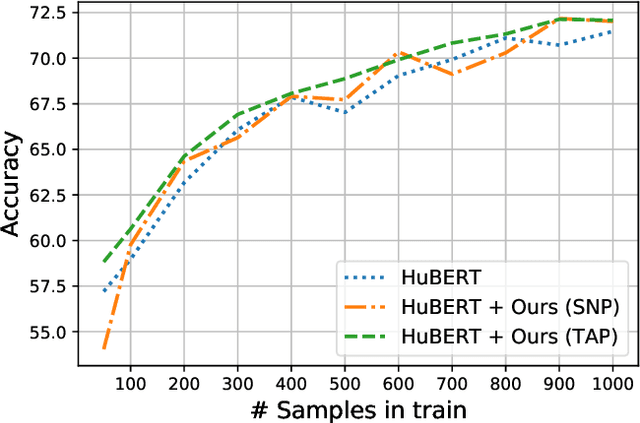
Large speech emotion recognition datasets are hard to obtain, and small datasets may contain biases. Deep-net-based classifiers, in turn, are prone to exploit those biases and find shortcuts such as speaker characteristics. These shortcuts usually harm a model's ability to generalize. To address this challenge, we propose a gradient-based adversary learning framework that learns a speech emotion recognition task while normalizing speaker characteristics from the feature representation. We demonstrate the efficacy of our method on both speaker-independent and speaker-dependent settings and obtain new state-of-the-art results on the challenging IEMOCAP dataset.