 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Attributed Automatic Speech Recognition Using Speech Aware LLMS
Apr 13, 2026Speaker-Attributed Automatic Speech Recognition (SAA) enhances traditional ASR systems by incorporating relative speaker identity tags directly into the transcript (e.g., [Speaker 1]:, [Speaker 2]:). In this work, we extend the capabilities of Granite-speech, a state-of-the-art speech-aware Large Language Model (LLM) originally trained for transcription and translation. We demonstrate that it can be effectively adapted for SAA with only minimal architectural changes. Our core contribution is the introduction of speaker cluster identification tags (e.g., [Speaker 1 cluster 42]:) which are jointly trained with SAA to significantly improve accuracy. To address limitations in training data, we propose a data augmentation method that uses artificially concatenated multi-speaker conversations. Our approach is evaluated across multiple benchmarks and shows superior performance compared to conventional pipelines that sequentially perform speaker diarization followed by ASR.
Knowing What to Stress: A Discourse-Conditioned Text-to-Speech Benchmark
Apr 12, 2026Spoken meaning often depends not only on what is said, but also on which word is emphasized. The same sentence can convey correction, contrast, or clarification depending on where emphasis falls. Although modern text-to-speech (TTS) systems generate expressive speech, it remains unclear whether they infer contextually appropriate stress from discourse alone. To address this gap, we present Context-Aware Stress TTS (CAST), a benchmark for evaluating context-conditioned word-level stress in TTS. Items are defined as contrastive context pairs: identical sentences paired with distinct contexts requiring different stressed words. We evaluate state-of-the-art systems and find a consistent gap: text-only language models reliably recover the intended stress from context, yet TTS systems frequently fail to realize it in speech. We release the benchmark, evaluation framework, construction pipeline and a synthetic corpus to support future work on context-aware speech synthesis.
Spoken question answering for visual queries
May 29, 2025Question answering (QA) systems are designed to answer natural language questions. Visual QA (VQA) and Spoken QA (SQA) systems extend the textual QA system to accept visual and spoken input respectively. This work aims to create a system that enables user interaction through both speech and images. That is achieved through the fusion of text, speech, and image modalities to tackle the task of spoken VQA (SVQA). The resulting multi-modal model has textual, visual, and spoken inputs and can answer spoken questions on images. Training and evaluating SVQA models requires a dataset for all three modalities, but no such dataset currently exists. We address this problem by synthesizing VQA datasets using two zero-shot TTS models. Our initial findings indicate that a model trained only with synthesized speech nearly reaches the performance of the upper-bounding model trained on textual QAs. In addition, we show that the choice of the TTS model has a minor impact on accuracy.
Granite-speech: open-source speech-aware LLMs with strong English ASR capabilities
May 14, 2025Granite-speech LLMs are compact and efficient speech language models specifically designed for English ASR and automatic speech translation (AST). The models were trained by modality aligning the 2B and 8B parameter variants of granite-3.3-instruct to speech on publicly available open-source corpora containing audio inputs and text targets consisting of either human transcripts for ASR or automatically generated translations for AST. Comprehensive benchmarking shows that on English ASR, which was our primary focus, they outperform several competitors' models that were trained on orders of magnitude more proprietary data, and they keep pace on English-to-X AST for major European languages, Japanese, and Chinese. The speech-specific components are: a conformer acoustic encoder using block attention and self-conditioning trained with connectionist temporal classification, a windowed query-transformer speech modality adapter used to do temporal downsampling of the acoustic embeddings and map them to the LLM text embedding space, and LoRA adapters to further fine-tune the text LLM. Granite-speech-3.3 operates in two modes: in speech mode, it performs ASR and AST by activating the encoder, projector, and LoRA adapters; in text mode, it calls the underlying granite-3.3-instruct model directly (without LoRA), essentially preserving all the text LLM capabilities and safety. Both models are freely available on HuggingFace (https://huggingface.co/ibm-granite/granite-speech-3.3-2b and https://huggingface.co/ibm-granite/granite-speech-3.3-8b) and can be used for both research and commercial purposes under a permissive Apache 2.0 license.
Continuous Speech Synthesis using per-token Latent Diffusion
Oct 21, 2024



The success of autoregressive transformer models with discrete tokens has inspired quantization-based approaches for continuous modalities, though these often limit reconstruction quality. We therefore introduce SALAD, a per-token latent diffusion model for zero-shot text-to-speech, that operates on continuous representations. SALAD builds upon the recently proposed expressive diffusion head for image generation, and extends it to generate variable-length outputs. Our approach utilizes semantic tokens for providing contextual information and determining the stopping condition. We suggest three continuous variants for our method, extending popular discrete speech synthesis techniques. Additionally, we implement discrete baselines for each variant and conduct a comparative analysis of discrete versus continuous speech modeling techniques. Our results demonstrate that both continuous and discrete approaches are highly competent, and that SALAD achieves a superior intelligibility score while obtaining speech quality and speaker similarity on par with the ground-truth audio.
Extending RNN-T-based speech recognition systems with emotion and language classification
Jul 28, 2022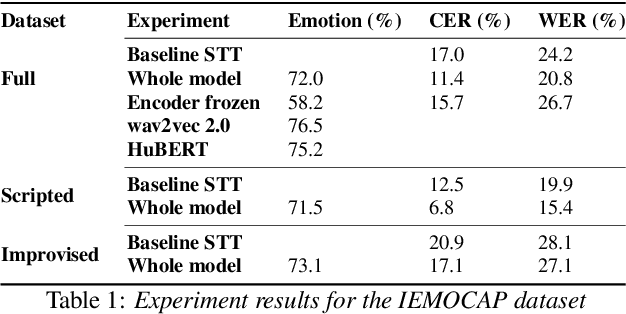
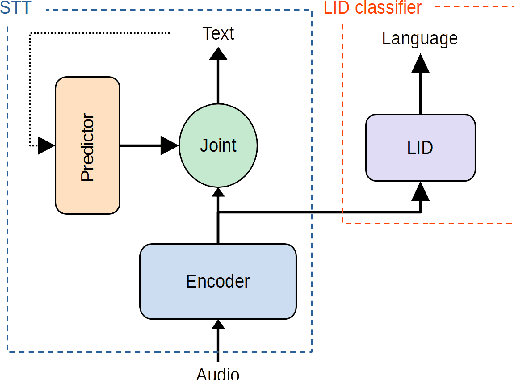
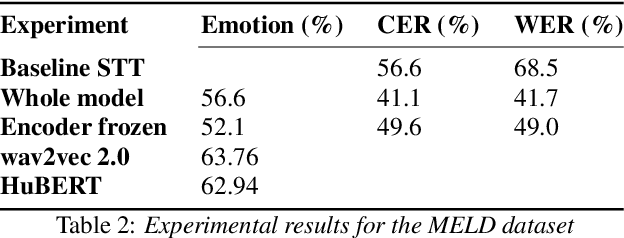
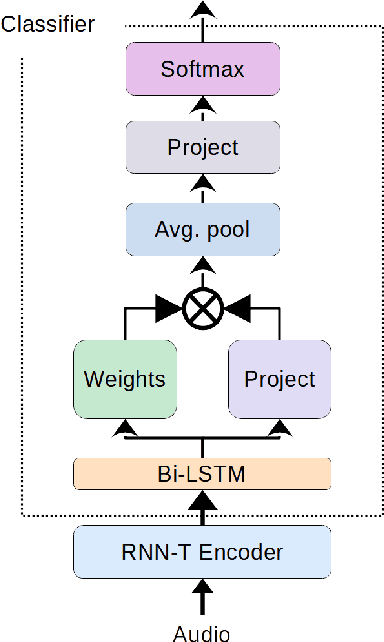
Speech transcription, emotion recognition, and language identification are usually considered to be three different tasks. Each one requires a different model with a different architecture and training process. We propose using a recurrent neural network transducer (RNN-T)-based speech-to-text (STT) system as a common component that can be used for emotion recognition and language identification as well as for speech recognition. Our work extends the STT system for emotion classification through minimal changes, and shows successful results on the IEMOCAP and MELD datasets. In addition, we demonstrate that by adding a lightweight component to the RNN-T module, it can also be used for language identification. In our evaluations, this new classifier demonstrates state-of-the-art accuracy for the NIST-LRE-07 dataset.
Towards a Common Speech Analysis Engine
Mar 01, 2022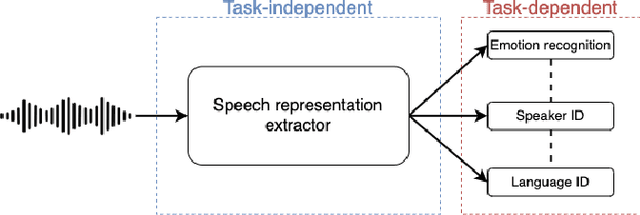
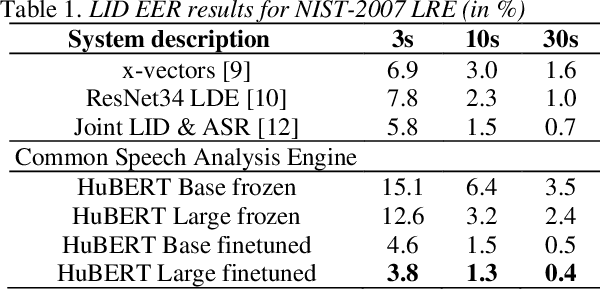

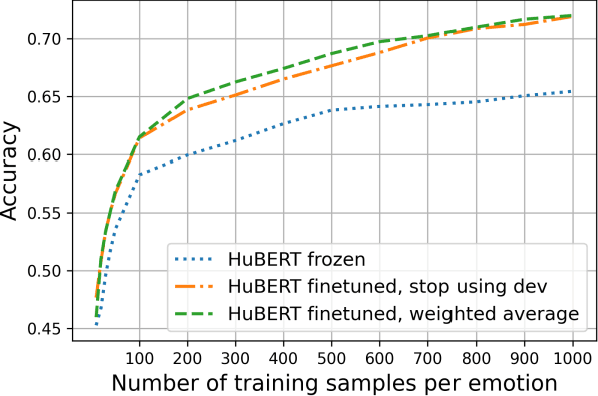
Recent innovations in self-supervised representation learning have led to remarkable advances in natural language processing. That said, in the speech processing domain, self-supervised representation learning-based systems are not yet considered state-of-the-art. We propose leveraging recent advances in self-supervised-based speech processing to create a common speech analysis engine. Such an engine should be able to handle multiple speech processing tasks, using a single architecture, to obtain state-of-the-art accuracy. The engine must also enable support for new tasks with small training datasets. Beyond that, a common engine should be capable of supporting distributed training with client in-house private data. We present the architecture for a common speech analysis engine based on the HuBERT self-supervised speech representation. Based on experiments, we report our results for language identification and emotion recognition on the standard evaluations NIST-LRE 07 and IEMOCAP. Our results surpass the state-of-the-art performance reported so far on these tasks. We also analyzed our engine on the emotion recognition task using reduced amounts of training data and show how to achieve improved results.
Speech Emotion Recognition using Self-Supervised Features
Feb 07, 2022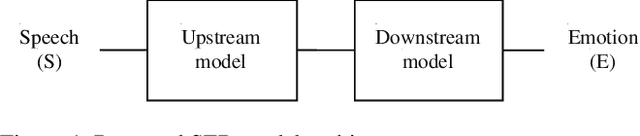
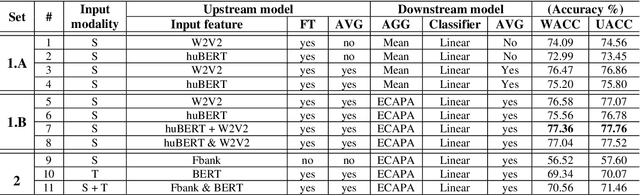
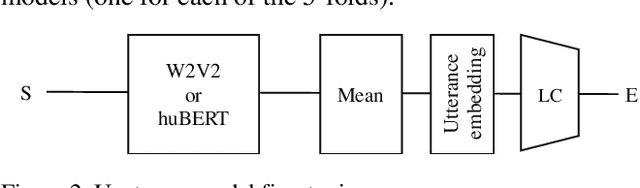
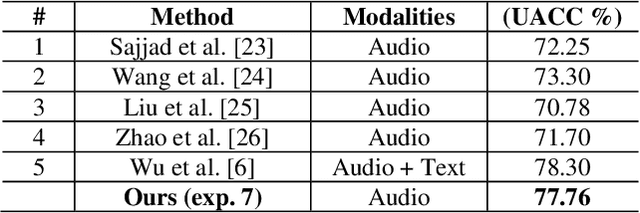
Self-supervised pre-trained features have consistently delivered state-of-art results in the field of natural language processing (NLP); however, their merits in the field of speech emotion recognition (SER) still need further investigation. In this paper we introduce a modular End-to- End (E2E) SER system based on an Upstream + Downstream architecture paradigm, which allows easy use/integration of a large variety of self-supervised features. Several SER experiments for predicting categorical emotion classes from the IEMOCAP dataset are performed. These experiments investigate interactions among fine-tuning of self-supervised feature models, aggregation of frame-level features into utterance-level features and back-end classification networks. The proposed monomodal speechonly based system not only achieves SOTA results, but also brings light to the possibility of powerful and well finetuned self-supervised acoustic features that reach results similar to the results achieved by SOTA multimodal systems using both Speech and Text modalities.
Speaker Normalization for Self-supervised Speech Emotion Recognition
Feb 02, 2022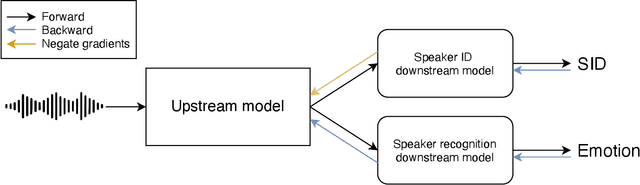
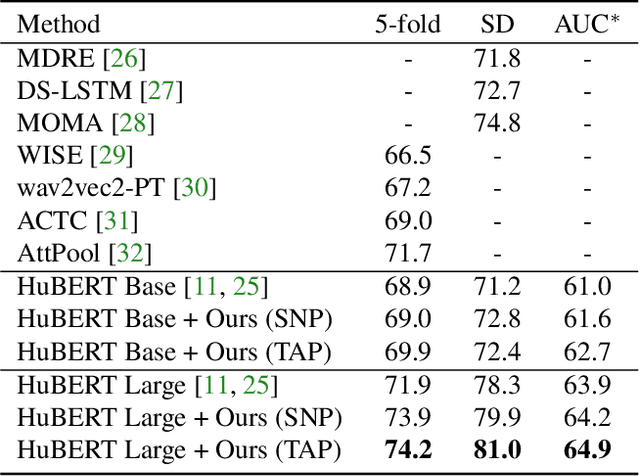
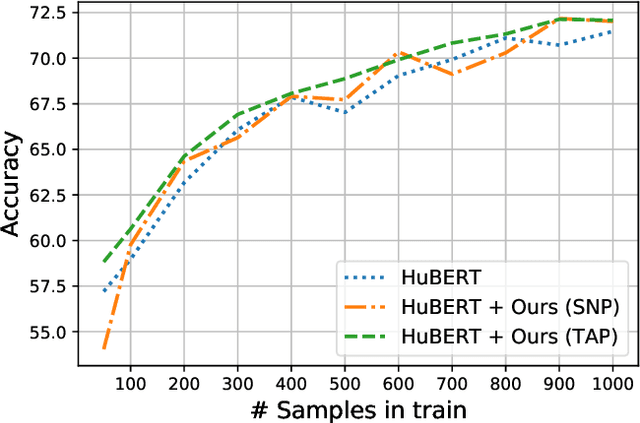
Large speech emotion recognition datasets are hard to obtain, and small datasets may contain biases. Deep-net-based classifiers, in turn, are prone to exploit those biases and find shortcuts such as speaker characteristics. These shortcuts usually harm a model's ability to generalize. To address this challenge, we propose a gradient-based adversary learning framework that learns a speech emotion recognition task while normalizing speaker characteristics from the feature representation. We demonstrate the efficacy of our method on both speaker-independent and speaker-dependent settings and obtain new state-of-the-art results on the challenging IEMOCAP dataset.
Siamese x-vector reconstruction for domain adapted speaker recognition
Jul 28, 2020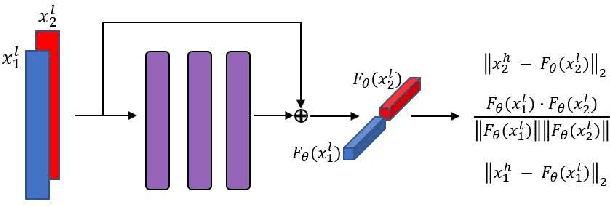

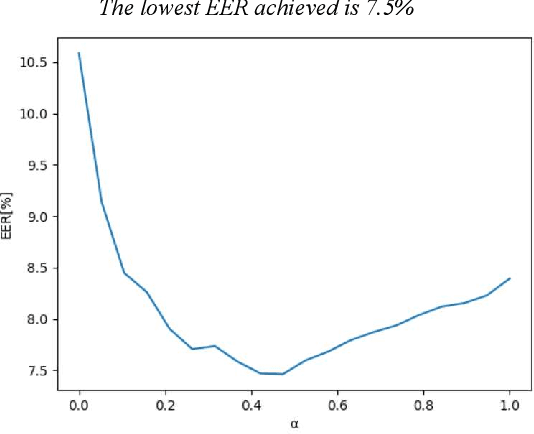
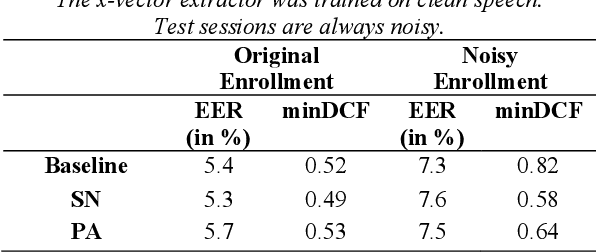
With the rise of voice-activated applications, the need for speaker recognition is rapidly increasing. The x-vector, an embedding approach based on a deep neural network (DNN), is considered the state-of-the-art when proper end-to-end training is not feasible. However, the accuracy significantly decreases when recording conditions (noise, sample rate, etc.) are mismatched, either between the x-vector training data and the target data or between enrollment and test data. We introduce the Siamese x-vector Reconstruction (SVR) for domain adaptation. We reconstruct the embedding of a higher quality signal from a lower quality counterpart using a lean auxiliary Siamese DNN. We evaluate our method on several mismatch scenarios and demonstrate significant improvement over the baseline.