 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Single-Channel Audio-Based Sound Speed Estimation for Robust Multi-Channel Audio Control
Feb 18, 2026Robust spatial audio control relies on accurate acoustic propagation models, yet environmental variations, especially changes in the speed of sound, cause systematic mismatches that degrade performance. Existing methods either assume known sound speed, require multiple microphones, or rely on separate calibration, making them impractical for systems with minimal sensing. We propose an online sound speed estimator that operates during general multichannel audio playback and requires only a single observation microphone. The method exploits the structured effect of sound speed on the reproduced signal and estimates it by minimizing the mismatch between the measured audio and a parametric acoustic model. Simulations show accurate tracking of sound speed for diverse input signals and improved spatial control performance when the estimates are used to compensate propagation errors in a sound zone control framework.
A Study of the Scale Invariant Signal to Distortion Ratio in Speech Separation with Noisy References
Aug 20, 2025This paper examines the implications of using the Scale-Invariant Signal-to-Distortion Ratio (SI-SDR) as both evaluation and training objective in supervised speech separation, when the training references contain noise, as is the case with the de facto benchmark WSJ0-2Mix. A derivation of the SI-SDR with noisy references reveals that noise limits the achievable SI-SDR, or leads to undesired noise in the separated outputs. To address this, a method is proposed to enhance references and augment the mixtures with WHAM!, aiming to train models that avoid learning noisy references. Two models trained on these enhanced datasets are evaluated with the non-intrusive NISQA.v2 metric. Results show reduced noise in separated speech but suggest that processing references may introduce artefacts, limiting overall quality gains. Negative correlation is found between SI-SDR and perceived noisiness across models on the WSJ0-2Mix and Libri2Mix test sets, underlining the conclusion from the derivation.
Learning-based A Posteriori Speech Presence Probability Estimation and Applications
Jan 23, 2025



The a posteriori speech presence probability (SPP) is the fundamental component of noise power spectral density (PSD) estimation, which can contribute to speech enhancement and speech recognition systems. Most existing SPP estimators can estimate SPP accurately from the background noise. Nevertheless, numerous challenges persist, including the difficulty of accurately estimating SPP from non-stationary noise with statistics-based methods and the high latency associated with deep learning-based approaches. This paper presents an improved SPP estimation approach based on deep learning to achieve higher SPP estimation accuracy, especially in non-stationary noise conditions. To promote the information extraction performance of the DNN, the global information of the observed signal and the local information of the decoupled frequency bins from the observed signal are connected as hybrid global-local information. The global information is extracted by one encoder. Then, one decoder and two fully connected layers are used to estimate SPP from the information of residual connection. To evaluate the performance of our proposed SPP estimator, the noise PSD estimation and speech enhancement tasks are performed. In contrast to existing minimum mean-square error (MMSE)-based noise PSD estimation approaches, the noise PSD is estimated by the sub-optimal MMSE based on the current frame SPP estimate without smoothing. Directed by the noise PSD estimate, a standard speech enhancement framework, the log spectral amplitude estimator, is employed to extract clean speech from the observed signal. From the experimental results, we can confirm that our proposed SPP estimator can achieve high noise PSD estimation accuracy and speech enhancement performance while requiring low model complexity.
Sound Zone Control Robust To Sound Speed Change
Oct 10, 2024



Sound zone control (SZC) implemented using static optimal filters is significantly affected by various perturbations in the acoustic environment, an important one being the fluctuation in the speed of sound, which is in turn influenced by changes in temperature and humidity (TH). This issue arises because control algorithms typically use pre-recorded, static impulse responses (IRs) to design the optimal control filters. The IRs, however, may change with time due to TH changes, which renders the derived control filters to become non-optimal. To address this challenge, we propose a straightforward model called sinc interpolation-compression/expansion-resampling (SICER), which adjusts the IRs to account for both sound speed reduction and increase. Using the proposed technique, IRs measured at a certain TH can be corrected for any TH change and control filters can be re-derived without the need of re-measuring the new IRs (which is impractical when SZC is deployed). We integrate the proposed SICER IR correction method with the recently introduced variable span trade-off (VAST) framework for SZC, and propose a SICER-corrected VAST method that is resilient to sound speed variations. Simulation studies show that the proposed SICER-corrected VAST approach significantly improves acoustic contrast and reduces signal distortion in the presence of sound speed changes.
Robust Fixed-Filter Sound Zone Control with Audio-Based Position Tracking
Oct 10, 2024



Performance of sound zone control (SZC) systems deployed in practical scenarios are highly sensitive to the location of the listener(s) and can degrade significantly when listener(s) are moving. This paper presents a robust SZC system that adapts to dynamic changes such as moving listeners and varying zone locations using a dictionary-based approach. The proposed system continuously monitors the environment and updates the fixed control filters by tracking the listener position using audio signals only. To test the effectiveness of the proposed SZC method, simulation studies are carried out using practically measured impulse responses. These studies show that SZC, when incorporated with the proposed audio-only position tracking scheme, achieves optimal performance when all listener positions are available in the dictionary. Moreover, even when not all listener positions are included in the dictionary, the method still provides good performance improvement compared to a traditional fixed filter SZC scheme.
Provable Privacy Advantages of Decentralized Federated Learning via Distributed Optimization
Jul 12, 2024



Federated learning (FL) emerged as a paradigm designed to improve data privacy by enabling data to reside at its source, thus embedding privacy as a core consideration in FL architectures, whether centralized or decentralized. Contrasting with recent findings by Pasquini et al., which suggest that decentralized FL does not empirically offer any additional privacy or security benefits over centralized models, our study provides compelling evidence to the contrary. We demonstrate that decentralized FL, when deploying distributed optimization, provides enhanced privacy protection - both theoretically and empirically - compared to centralized approaches. The challenge of quantifying privacy loss through iterative processes has traditionally constrained the theoretical exploration of FL protocols. We overcome this by conducting a pioneering in-depth information-theoretical privacy analysis for both frameworks. Our analysis, considering both eavesdropping and passive adversary models, successfully establishes bounds on privacy leakage. We show information theoretically that the privacy loss in decentralized FL is upper bounded by the loss in centralized FL. Compared to the centralized case where local gradients of individual participants are directly revealed, a key distinction of optimization-based decentralized FL is that the relevant information includes differences of local gradients over successive iterations and the aggregated sum of different nodes' gradients over the network. This information complicates the adversary's attempt to infer private data. To bridge our theoretical insights with practical applications, we present detailed case studies involving logistic regression and deep neural networks. These examples demonstrate that while privacy leakage remains comparable in simpler models, complex models like deep neural networks exhibit lower privacy risks under decentralized FL.
Frequency bin-wise single channel speech presence probability estimation using multiple DNNs
Feb 23, 2023In this work, we propose a frequency bin-wise method to estimate the single-channel speech presence probability (SPP) with multiple deep neural networks (DNNs) in the short-time Fourier transform domain. Since all frequency bins are typically considered simultaneously as input features for conventional DNN-based SPP estimators, high model complexity is inevitable. To reduce the model complexity and the requirements on the training data, we take a single frequency bin and some of its neighboring frequency bins into account to train separate gate recurrent units. In addition, the noisy speech and the a posteriori probability SPP representation are used to train our model. The experiments were performed on the Deep Noise Suppression challenge dataset. The experimental results show that the speech detection accuracy can be improved when we employ the frequency bin-wise model. Finally, we also demonstrate that our proposed method outperforms most of the state-of-the-art SPP estimation methods in terms of speech detection accuracy and model complexity.
A Two-Stage Deep Representation Learning-Based Speech Enhancement Method Using Variational Autoencoder and Adversarial Training
Nov 16, 2022This paper focuses on leveraging deep representation learning (DRL) for speech enhancement (SE). In general, the performance of the deep neural network (DNN) is heavily dependent on the learning of data representation. However, the DRL's importance is often ignored in many DNN-based SE algorithms. To obtain a higher quality enhanced speech, we propose a two-stage DRL-based SE method through adversarial training. In the first stage, we disentangle different latent variables because disentangled representations can help DNN generate a better enhanced speech. Specifically, we use the $\beta$-variational autoencoder (VAE) algorithm to obtain the speech and noise posterior estimations and related representations from the observed signal. However, since the posteriors and representations are intractable and we can only apply a conditional assumption to estimate them, it is difficult to ensure that these estimations are always pretty accurate, which may potentially degrade the final accuracy of the signal estimation. To further improve the quality of enhanced speech, in the second stage, we introduce adversarial training to reduce the effect of the inaccurate posterior towards signal reconstruction and improve the signal estimation accuracy, making our algorithm more robust for the potentially inaccurate posterior estimations. As a result, better SE performance can be achieved. The experimental results indicate that the proposed strategy can help similar DNN-based SE algorithms achieve higher short-time objective intelligibility (STOI), perceptual evaluation of speech quality (PESQ), and scale-invariant signal-to-distortion ratio (SI-SDR) scores. Moreover, the proposed algorithm can also outperform recent competitive SE algorithms.
Privacy-Preserving Distributed Expectation Maximization for Gaussian Mixture Model using Subspace Perturbation
Sep 16, 2022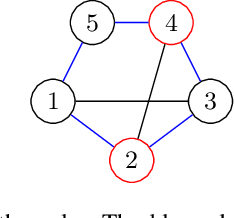
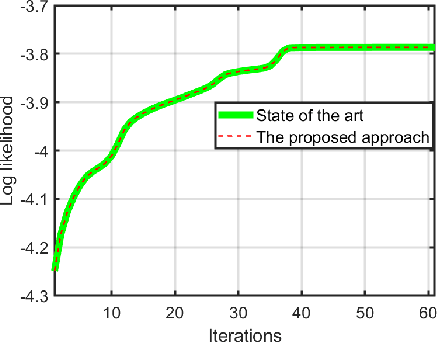
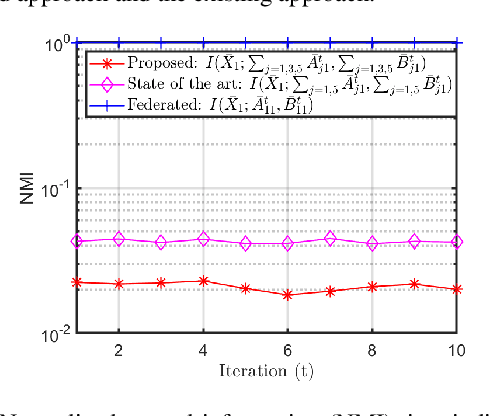
Privacy has become a major concern in machine learning. In fact, the federated learning is motivated by the privacy concern as it does not allow to transmit the private data but only intermediate updates. However, federated learning does not always guarantee privacy-preservation as the intermediate updates may also reveal sensitive information. In this paper, we give an explicit information-theoretical analysis of a federated expectation maximization algorithm for Gaussian mixture model and prove that the intermediate updates can cause severe privacy leakage. To address the privacy issue, we propose a fully decentralized privacy-preserving solution, which is able to securely compute the updates in each maximization step. Additionally, we consider two different types of security attacks: the honest-but-curious and eavesdropping adversary models. Numerical validation shows that the proposed approach has superior performance compared to the existing approach in terms of both the accuracy and privacy level.
A deep representation learning speech enhancement method using $β$-VAE
May 11, 2022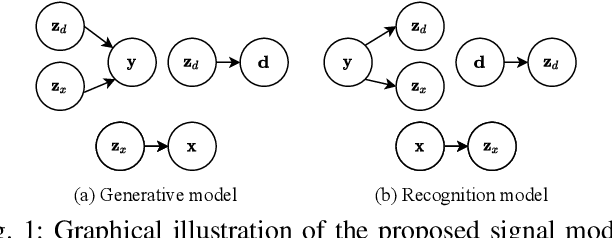
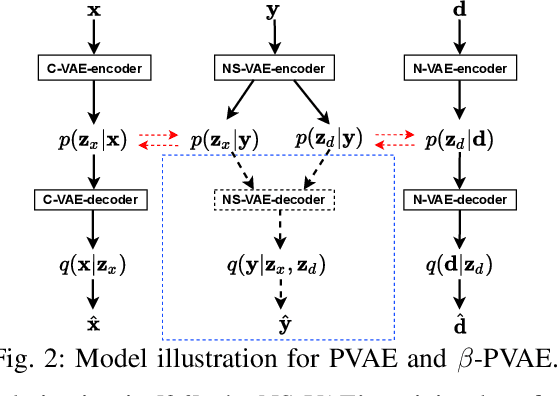
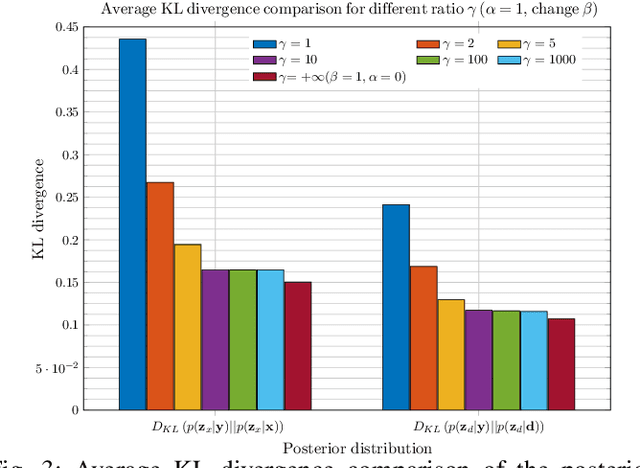
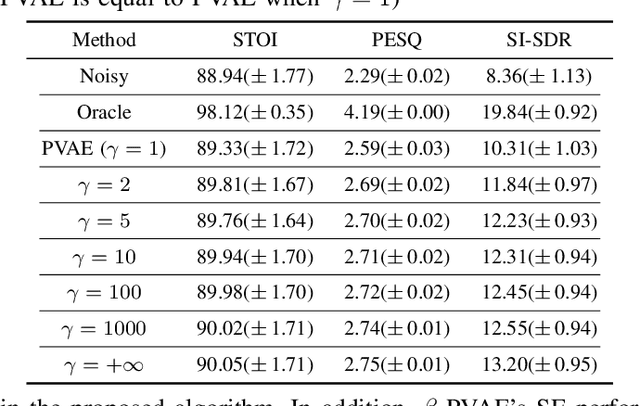
In previous work, we proposed a variational autoencoder-based (VAE) Bayesian permutation training speech enhancement (SE) method (PVAE) which indicated that the SE performance of the traditional deep neural network-based (DNN) method could be improved by deep representation learning (DRL). Based on our previous work, we in this paper propose to use $\beta$-VAE to further improve PVAE's ability of representation learning. More specifically, our $\beta$-VAE can improve PVAE's capacity of disentangling different latent variables from the observed signal without the trade-off problem between disentanglement and signal reconstruction. This trade-off problem widely exists in previous $\beta$-VAE algorithms. Unlike the previous $\beta$-VAE algorithms, the proposed $\beta$-VAE strategy can also be used to optimize the DNN's structure. This means that the proposed method can not only improve PVAE's SE performance but also reduce the number of PVAE training parameters. The experimental results show that the proposed method can acquire better speech and noise latent representation than PVAE. Meanwhile, it also obtains a higher scale-invariant signal-to-distortion ratio, speech quality, and speech intelligibility.