 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Enhancing Cross-lingual Transfer via Phonemic Transcription Integration
Jul 10, 2023
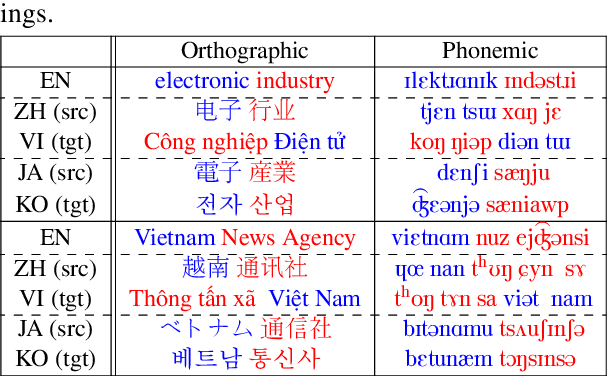
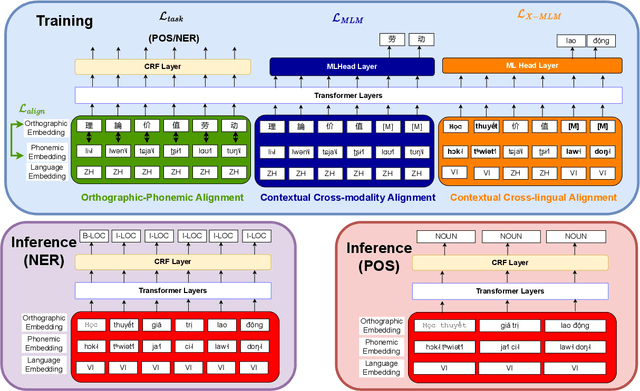
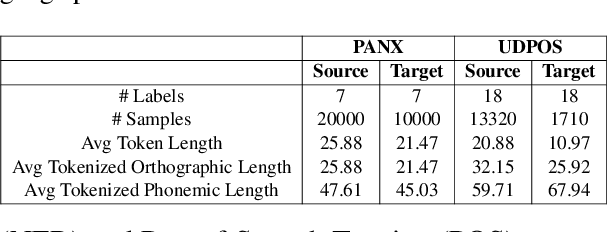
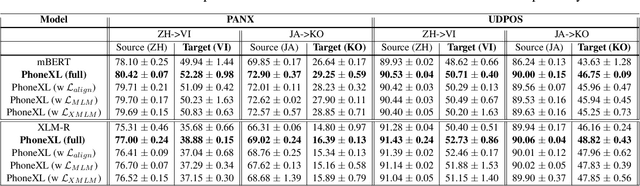
Previous cross-lingual transfer methods are restricted to orthographic representation learning via textual scripts. This limitation hampers cross-lingual transfer and is biased towards languages sharing similar well-known scripts. To alleviate the gap between languages from different writing scripts, we propose PhoneXL, a framework incorporating phonemic transcriptions as an additional linguistic modality beyond the traditional orthographic transcriptions for cross-lingual transfer. Particularly, we propose unsupervised alignment objectives to capture (1) local one-to-one alignment between the two different modalities, (2) alignment via multi-modality contexts to leverage information from additional modalities, and (3) alignment via multilingual contexts where additional bilingual dictionaries are incorporated. We also release the first phonemic-orthographic alignment dataset on two token-level tasks (Named Entity Recognition and Part-of-Speech Tagging) among the understudied but interconnected Chinese-Japanese-Korean-Vietnamese (CJKV) languages. Our pilot study reveals phonemic transcription provides essential information beyond the orthography to enhance cross-lingual transfer and bridge the gap among CJKV languages, leading to consistent improvements on cross-lingual token-level tasks over orthographic-based multilingual PLMs.
Beyond Universal Transformer: block reusing with adaptor in Transformer for automatic speech recognit
Mar 23, 2023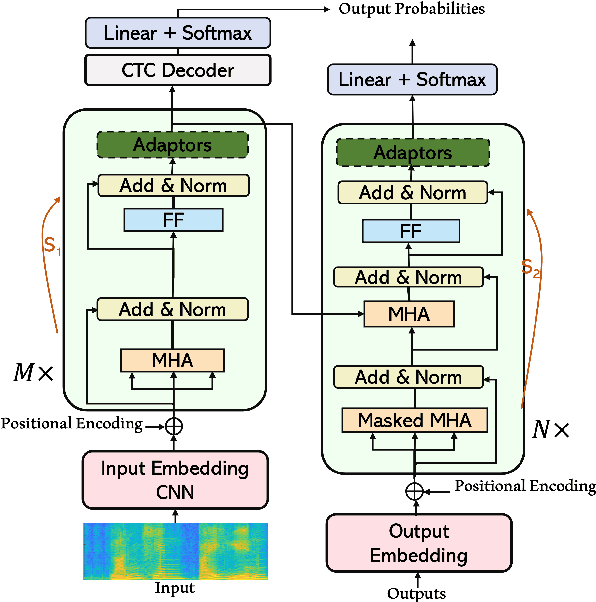
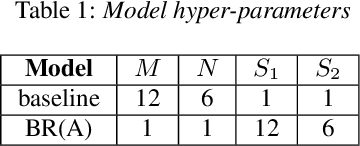
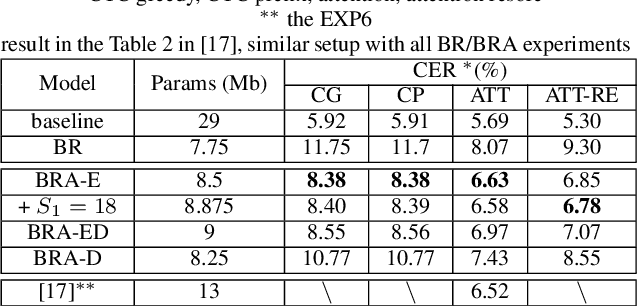
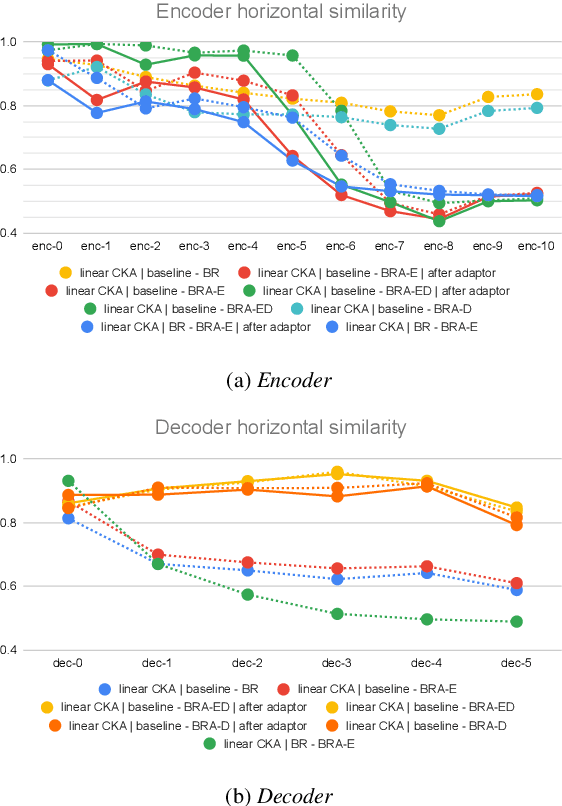
Transformer-based models have recently made significant achievements in the application of end-to-end (E2E) automatic speech recognition (ASR). It is possible to deploy the E2E ASR system on smart devices with the help of Transformer-based models. While these models still have the disadvantage of requiring a large number of model parameters. To overcome the drawback of universal Transformer models for the application of ASR on edge devices, we propose a solution that can reuse the block in Transformer models for the occasion of the small footprint ASR system, which meets the objective of accommodating resource limitations without compromising recognition accuracy. Specifically, we design a novel block-reusing strategy for speech Transformer (BRST) to enhance the effectiveness of parameters and propose an adapter module (ADM) that can produce a compact and adaptable model with only a few additional trainable parameters accompanying each reusing block. We conducted an experiment with the proposed method on the public AISHELL-1 corpus, and the results show that the proposed approach achieves the character error rate (CER) of 9.3%/6.63% with only 7.6M/8.3M parameters without and with the ADM, respectively. In addition, we also make a deeper analysis to show the effect of ADM in the general block-reusing method.
Language of Bargaining
Jun 12, 2023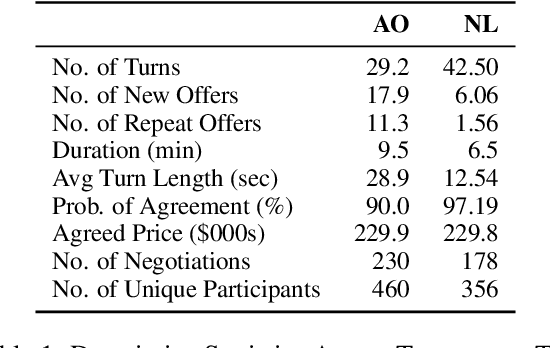
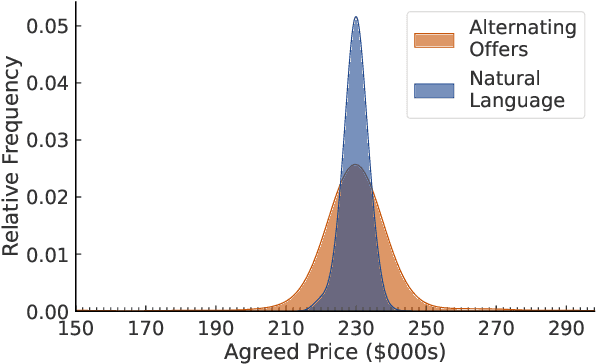
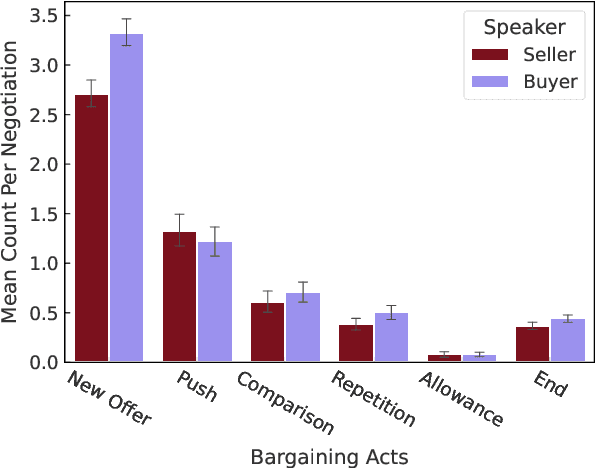
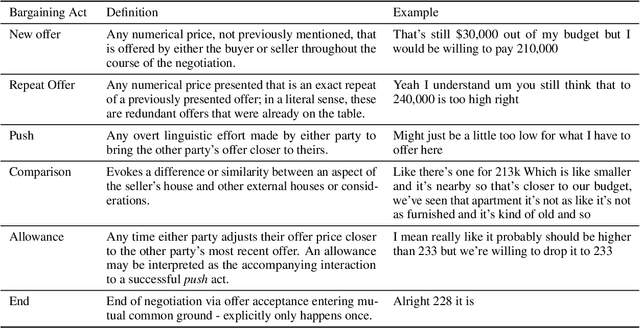
Leveraging an established exercise in negotiation education, we build a novel dataset for studying how the use of language shapes bilateral bargaining. Our dataset extends existing work in two ways: 1) we recruit participants via behavioral labs instead of crowdsourcing platforms and allow participants to negotiate through audio, enabling more naturalistic interactions; 2) we add a control setting where participants negotiate only through alternating, written numeric offers.Despite the two contrasting forms of communication, we find that the average agreed prices of the two treatments are identical. But when subjects can talk, fewer offers are exchanged, negotiations finish faster, the likelihood of reaching agreement rises, and the variance of prices at which subjects agree drops substantially. We further propose a taxonomy of speech acts in negotiation and enrich the dataset with annotated speech acts. We set up prediction tasks to predict negotiation success and find that being reactive to the arguments of the other party is advantageous over driving the negotiation.
VSMask: Defending Against Voice Synthesis Attack via Real-Time Predictive Perturbation
May 09, 2023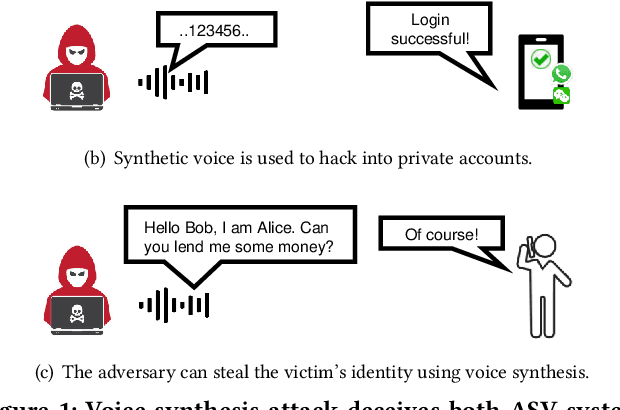
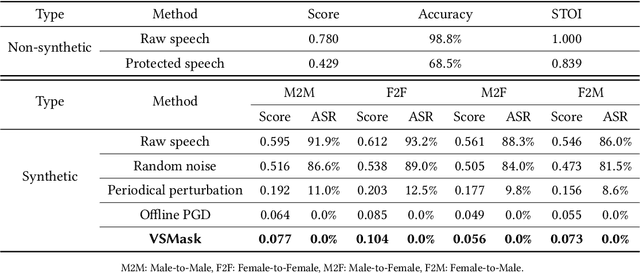
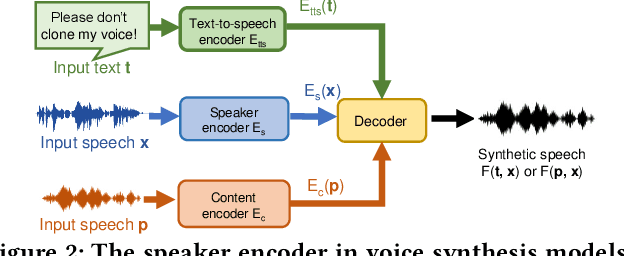
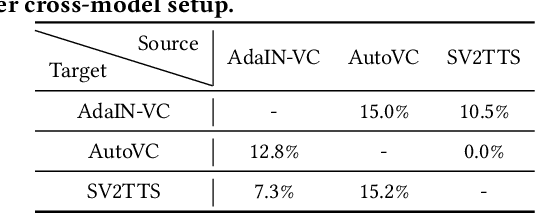
Deep learning based voice synthesis technology generates artificial human-like speeches, which has been used in deepfakes or identity theft attacks. Existing defense mechanisms inject subtle adversarial perturbations into the raw speech audios to mislead the voice synthesis models. However, optimizing the adversarial perturbation not only consumes substantial computation time, but it also requires the availability of entire speech. Therefore, they are not suitable for protecting live speech streams, such as voice messages or online meetings. In this paper, we propose VSMask, a real-time protection mechanism against voice synthesis attacks. Different from offline protection schemes, VSMask leverages a predictive neural network to forecast the most effective perturbation for the upcoming streaming speech. VSMask introduces a universal perturbation tailored for arbitrary speech input to shield a real-time speech in its entirety. To minimize the audio distortion within the protected speech, we implement a weight-based perturbation constraint to reduce the perceptibility of the added perturbation. We comprehensively evaluate VSMask protection performance under different scenarios. The experimental results indicate that VSMask can effectively defend against 3 popular voice synthesis models. None of the synthetic voice could deceive the speaker verification models or human ears with VSMask protection. In a physical world experiment, we demonstrate that VSMask successfully safeguards the real-time speech by injecting the perturbation over the air.
DAE-Talker: High Fidelity Speech-Driven Talking Face Generation with Diffusion Autoencoder
Mar 30, 2023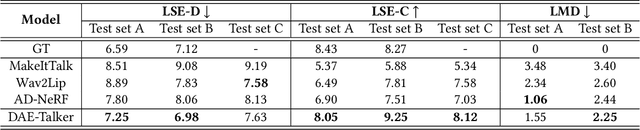
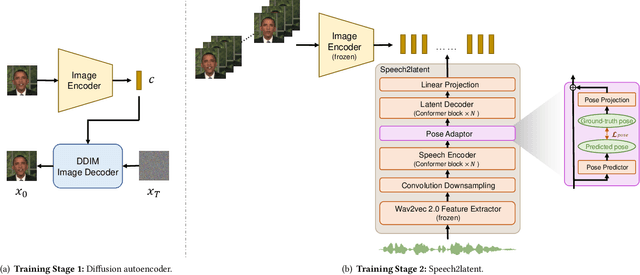

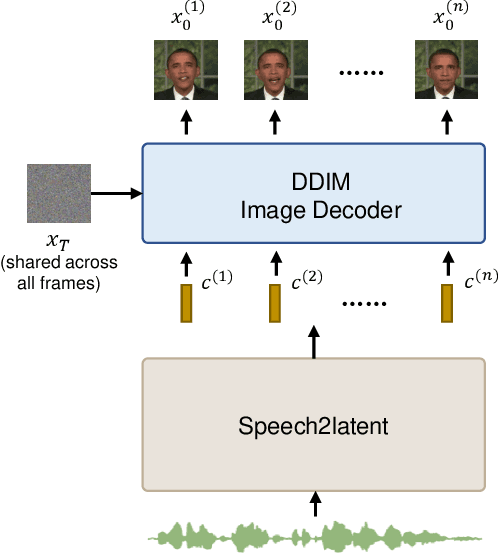
While recent research has made significant progress in speech-driven talking face generation, the quality of the generated video still lags behind that of real recordings. One reason for this is the use of handcrafted intermediate representations like facial landmarks and 3DMM coefficients, which are designed based on human knowledge and are insufficient to precisely describe facial movements. Additionally, these methods require an external pretrained model for extracting these representations, whose performance sets an upper bound on talking face generation. To address these limitations, we propose a novel method called DAE-Talker that leverages data-driven latent representations obtained from a diffusion autoencoder (DAE). DAE contains an image encoder that encodes an image into a latent vector and a DDIM image decoder that reconstructs the image from it. We train our DAE on talking face video frames and then extract their latent representations as the training target for a Conformer-based speech2latent model. This allows DAE-Talker to synthesize full video frames and produce natural head movements that align with the content of speech, rather than relying on a predetermined head pose from a template video. We also introduce pose modelling in speech2latent for pose controllability. Additionally, we propose a novel method for generating continuous video frames with the DDIM image decoder trained on individual frames, eliminating the need for modelling the joint distribution of consecutive frames directly. Our experiments show that DAE-Talker outperforms existing popular methods in lip-sync, video fidelity, and pose naturalness. We also conduct ablation studies to analyze the effectiveness of the proposed techniques and demonstrate the pose controllability of DAE-Talker.
Model Adaptation for ASR in low-resource Indian Languages
Jul 16, 2023
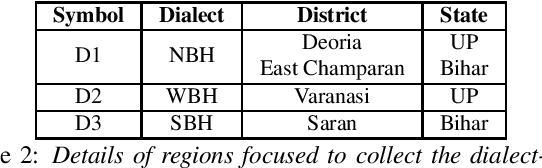
Automatic speech recognition (ASR) performance has improved drastically in recent years, mainly enabled by self-supervised learning (SSL) based acoustic models such as wav2vec2 and large-scale multi-lingual training like Whisper. A huge challenge still exists for low-resource languages where the availability of both audio and text is limited. This is further complicated by the presence of multiple dialects like in Indian languages. However, many Indian languages can be grouped into the same families and share the same script and grammatical structure. This is where a lot of adaptation and fine-tuning techniques can be applied to overcome the low-resource nature of the data by utilising well-resourced similar languages. In such scenarios, it is important to understand the extent to which each modality, like acoustics and text, is important in building a reliable ASR. It could be the case that an abundance of acoustic data in a language reduces the need for large text-only corpora. Or, due to the availability of various pretrained acoustic models, the vice-versa could also be true. In this proposed special session, we encourage the community to explore these ideas with the data in two low-resource Indian languages of Bengali and Bhojpuri. These approaches are not limited to Indian languages, the solutions are potentially applicable to various languages spoken around the world.
EM-Network: Oracle Guided Self-distillation for Sequence Learning
Jun 14, 2023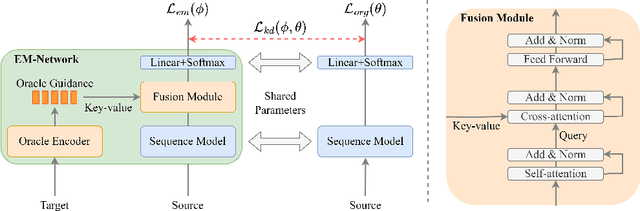
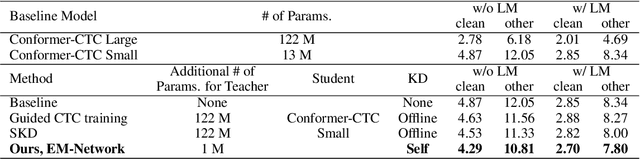
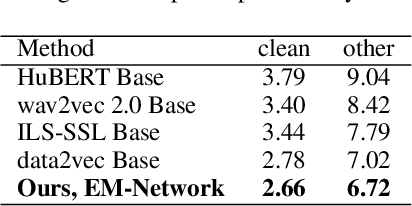
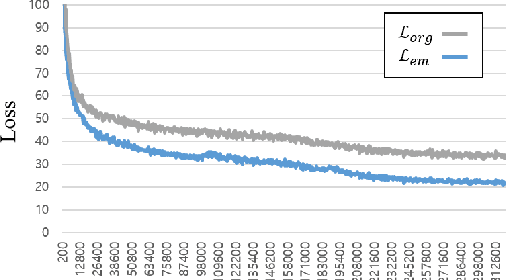
We introduce EM-Network, a novel self-distillation approach that effectively leverages target information for supervised sequence-to-sequence (seq2seq) learning. In contrast to conventional methods, it is trained with oracle guidance, which is derived from the target sequence. Since the oracle guidance compactly represents the target-side context that can assist the sequence model in solving the task, the EM-Network achieves a better prediction compared to using only the source input. To allow the sequence model to inherit the promising capability of the EM-Network, we propose a new self-distillation strategy, where the original sequence model can benefit from the knowledge of the EM-Network in a one-stage manner. We conduct comprehensive experiments on two types of seq2seq models: connectionist temporal classification (CTC) for speech recognition and attention-based encoder-decoder (AED) for machine translation. Experimental results demonstrate that the EM-Network significantly advances the current state-of-the-art approaches, improving over the best prior work on speech recognition and establishing state-of-the-art performance on WMT'14 and IWSLT'14.
Self-supervised speech representation learning for keyword-spotting with light-weight transformers
Mar 07, 2023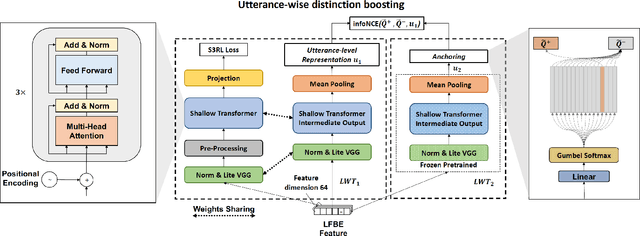
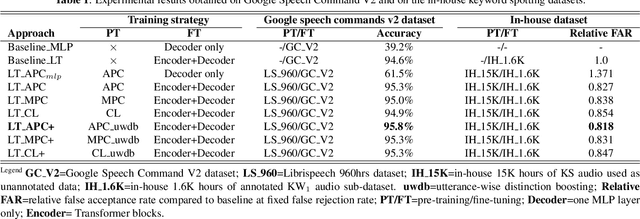
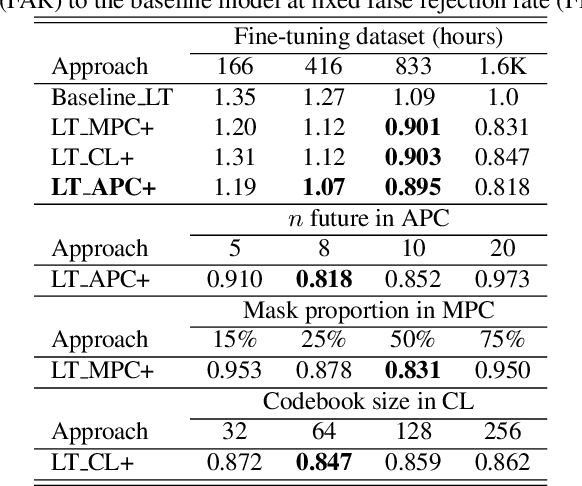
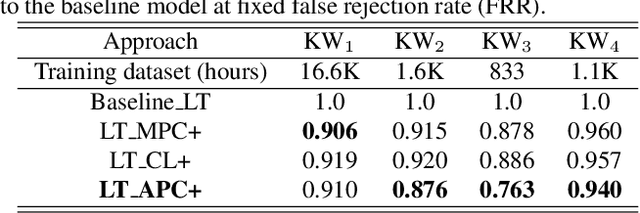
Self-supervised speech representation learning (S3RL) is revolutionizing the way we leverage the ever-growing availability of data. While S3RL related studies typically use large models, we employ light-weight networks to comply with tight memory of compute-constrained devices. We demonstrate the effectiveness of S3RL on a keyword-spotting (KS) problem by using transformers with 330k parameters and propose a mechanism to enhance utterance-wise distinction, which proves crucial for improving performance on classification tasks. On the Google speech commands v2 dataset, the proposed method applied to the Auto-Regressive Predictive Coding S3RL led to a 1.2% accuracy improvement compared to training from scratch. On an in-house KS dataset with four different keywords, it provided 6% to 23.7% relative false accept improvement at fixed false reject rate. We argue this demonstrates the applicability of S3RL approaches to light-weight models for KS and confirms S3RL is a powerful alternative to traditional supervised learning for resource-constrained applications.
High-Fidelity Audio Compression with Improved RVQGAN
Jun 11, 2023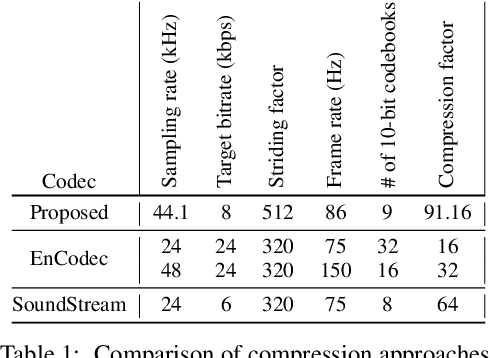
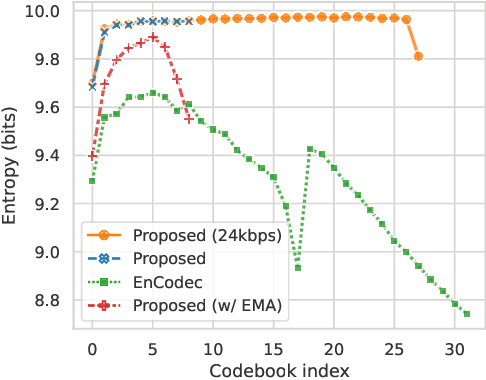
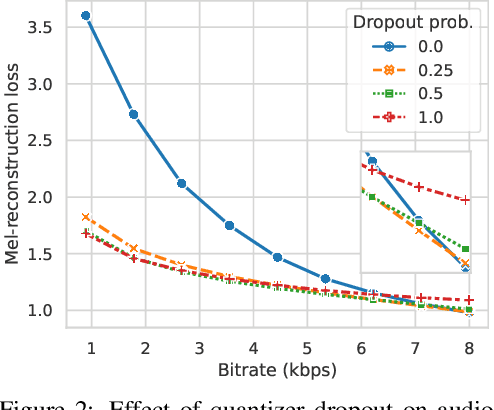
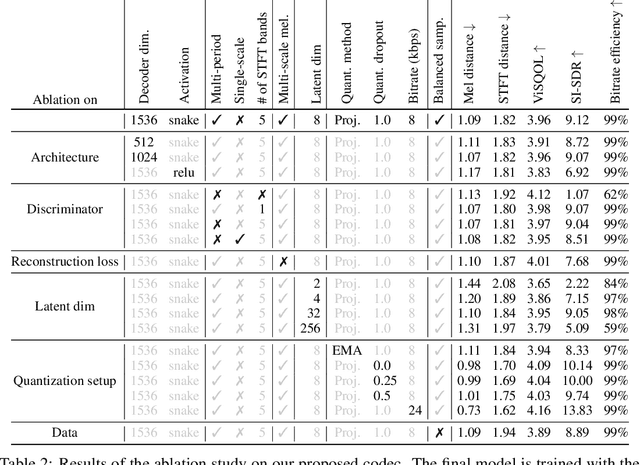
Language models have been successfully used to model natural signals, such as images, speech, and music. A key component of these models is a high quality neural compression model that can compress high-dimensional natural signals into lower dimensional discrete tokens. To that end, we introduce a high-fidelity universal neural audio compression algorithm that achieves ~90x compression of 44.1 KHz audio into tokens at just 8kbps bandwidth. We achieve this by combining advances in high-fidelity audio generation with better vector quantization techniques from the image domain, along with improved adversarial and reconstruction losses. We compress all domains (speech, environment, music, etc.) with a single universal model, making it widely applicable to generative modeling of all audio. We compare with competing audio compression algorithms, and find our method outperforms them significantly. We provide thorough ablations for every design choice, as well as open-source code and trained model weights. We hope our work can lay the foundation for the next generation of high-fidelity audio modeling.
Using Deepfake Technologies for Word Emphasis Detection
May 12, 2023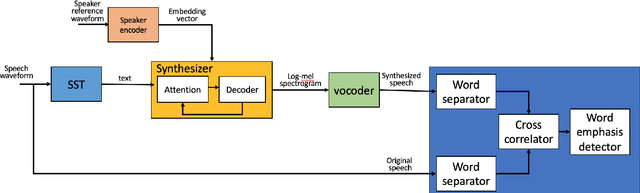
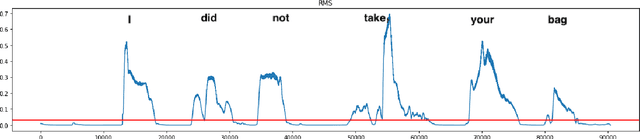
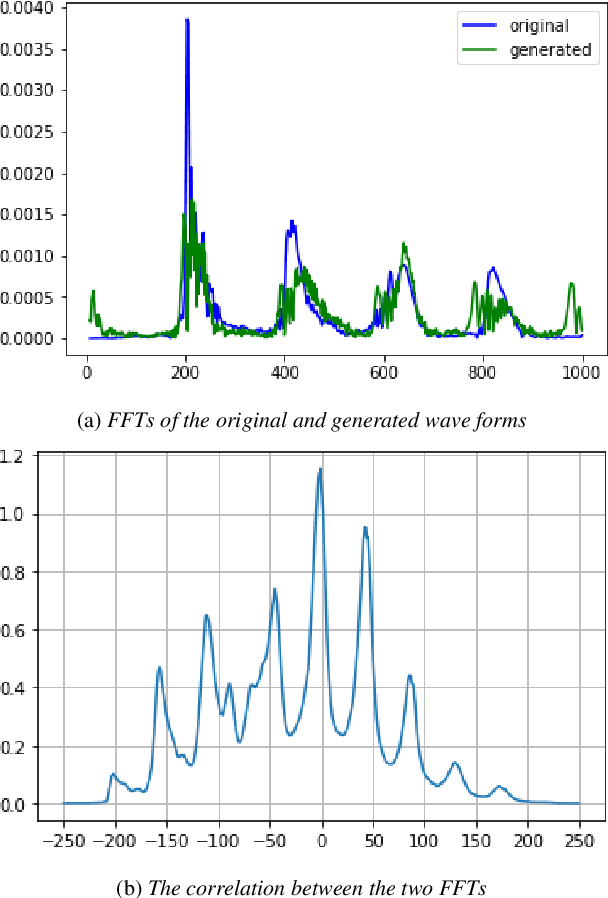
In this work, we consider the task of automated emphasis detection for spoken language. This problem is challenging in that emphasis is affected by the particularities of speech of the subject, for example the subject accent, dialect or voice. To address this task, we propose to utilize deep fake technology to produce an emphasis devoid speech for this speaker. This requires extracting the text of the spoken voice, and then using a voice sample from the same speaker to produce emphasis devoid speech for this task. By comparing the generated speech with the spoken voice, we are able to isolate patterns of emphasis which are relatively easy to detect.