 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Parmesan: mathematical concept extraction for education
Jul 17, 2023
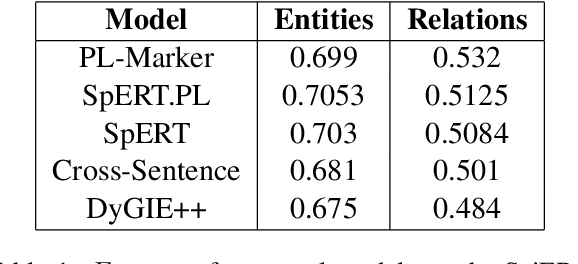
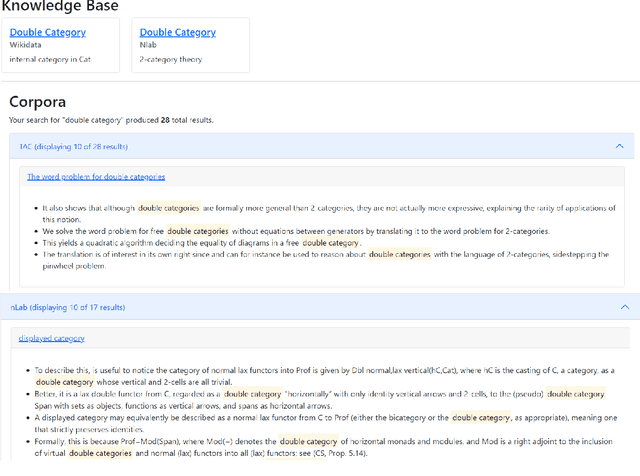
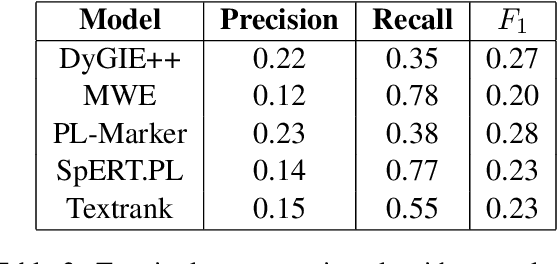
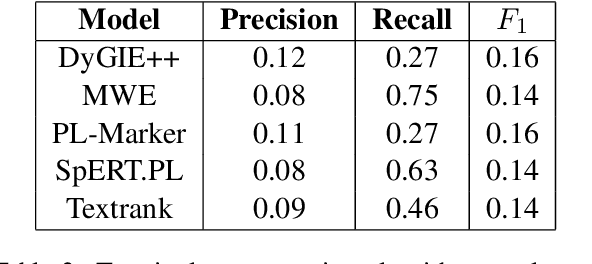
Mathematics is a highly specialized domain with its own unique set of challenges that has seen limited study in natural language processing. However, mathematics is used in a wide variety of fields and multidisciplinary research in many different domains often relies on an understanding of mathematical concepts. To aid researchers coming from other fields, we develop a prototype system for searching for and defining mathematical concepts in context, focusing on the field of category theory. This system, Parmesan, depends on natural language processing components including concept extraction, relation extraction, definition extraction, and entity linking. In developing this system, we show that existing techniques cannot be applied directly to the category theory domain, and suggest hybrid techniques that do perform well, though we expect the system to evolve over time. We also provide two cleaned mathematical corpora that power the prototype system, which are based on journal articles and wiki pages, respectively. The corpora have been annotated with dependency trees, lemmas, and part-of-speech tags.
Ed-Fed: A generic federated learning framework with resource-aware client selection for edge devices
Jul 14, 2023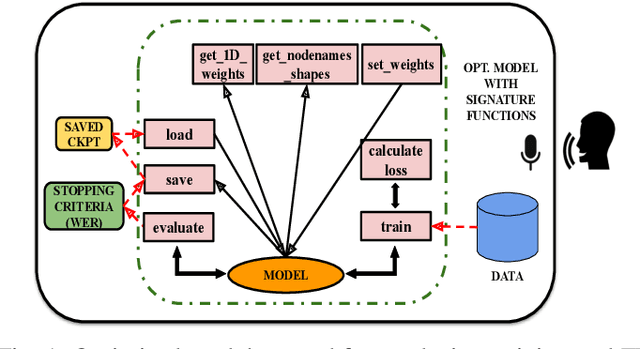
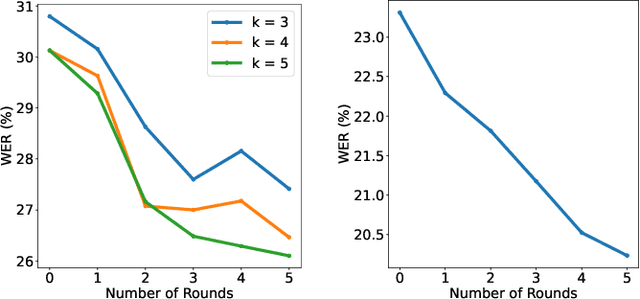
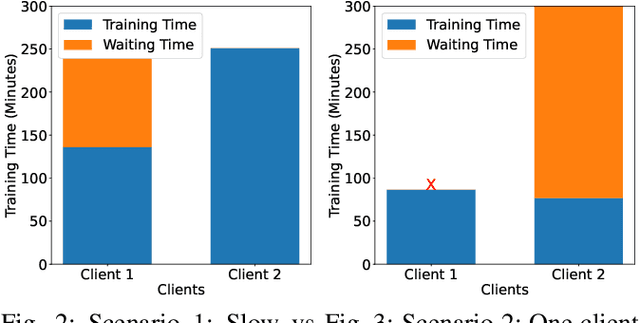
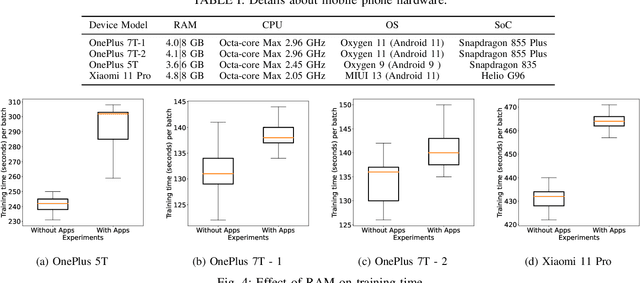
Federated learning (FL) has evolved as a prominent method for edge devices to cooperatively create a unified prediction model while securing their sensitive training data local to the device. Despite the existence of numerous research frameworks for simulating FL algorithms, they do not facilitate comprehensive deployment for automatic speech recognition tasks on heterogeneous edge devices. This is where Ed-Fed, a comprehensive and generic FL framework, comes in as a foundation for future practical FL system research. We also propose a novel resource-aware client selection algorithm to optimise the waiting time in the FL settings. We show that our approach can handle the straggler devices and dynamically set the training time for the selected devices in a round. Our evaluation has shown that the proposed approach significantly optimises waiting time in FL compared to conventional random client selection methods.
Improving RNN-Transducers with Acoustic LookAhead
Jul 11, 2023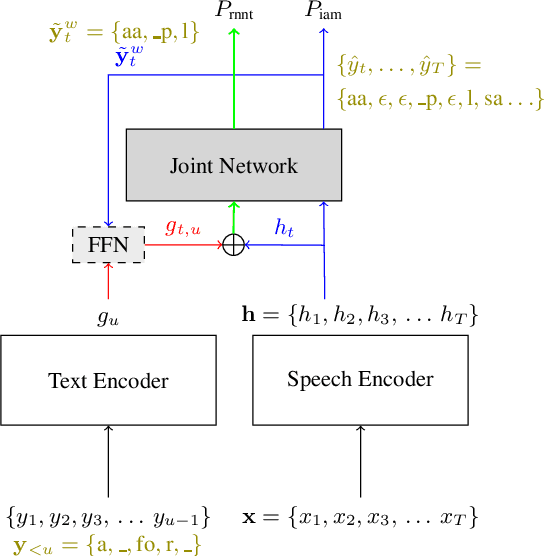
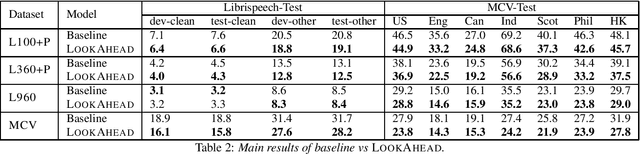
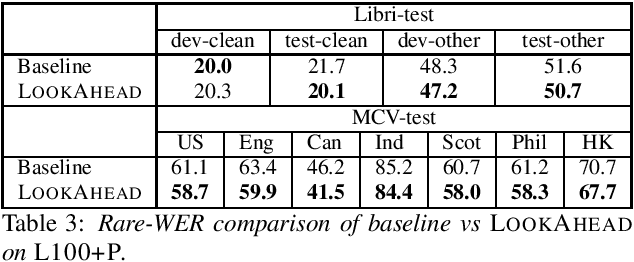

RNN-Transducers (RNN-Ts) have gained widespread acceptance as an end-to-end model for speech to text conversion because of their high accuracy and streaming capabilities. A typical RNN-T independently encodes the input audio and the text context, and combines the two encodings by a thin joint network. While this architecture provides SOTA streaming accuracy, it also makes the model vulnerable to strong LM biasing which manifests as multi-step hallucination of text without acoustic evidence. In this paper we propose LookAhead that makes text representations more acoustically grounded by looking ahead into the future within the audio input. This technique yields a significant 5%-20% relative reduction in word error rate on both in-domain and out-of-domain evaluation sets.
Conformers are All You Need for Visual Speech Recogntion
Feb 17, 2023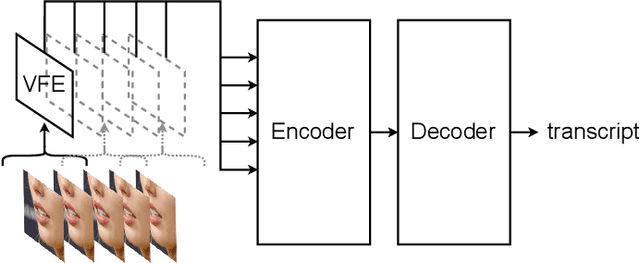

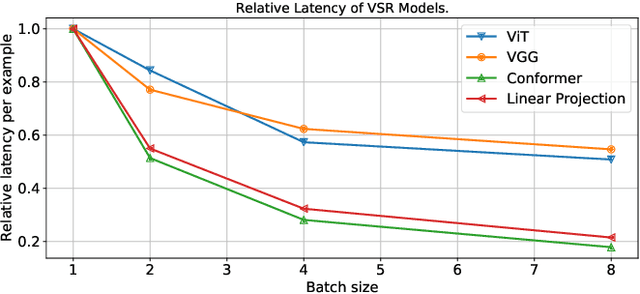
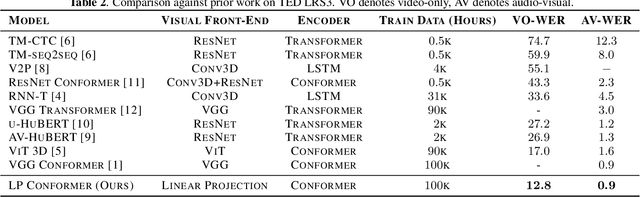
Visual speech recognition models extract visual features in a hierarchical manner. At the lower level, there is a visual front-end with a limited temporal receptive field that processes the raw pixels depicting the lips or faces. At the higher level, there is an encoder that attends to the embeddings produced by the front-end over a large temporal receptive field. Previous work has focused on improving the visual front-end of the model to extract more useful features for speech recognition. Surprisingly, our work shows that complex visual front-ends are not necessary. Instead of allocating resources to a sophisticated visual front-end, we find that a linear visual front-end paired with a larger Conformer encoder results in lower latency, more efficient memory usage, and improved WER performance. We achieve a new state-of-the-art of $12.8\%$ WER for visual speech recognition on the TED LRS3 dataset, which rivals the performance of audio-only models from just four years ago.
Speech-based Age and Gender Prediction with Transformers
Jun 29, 2023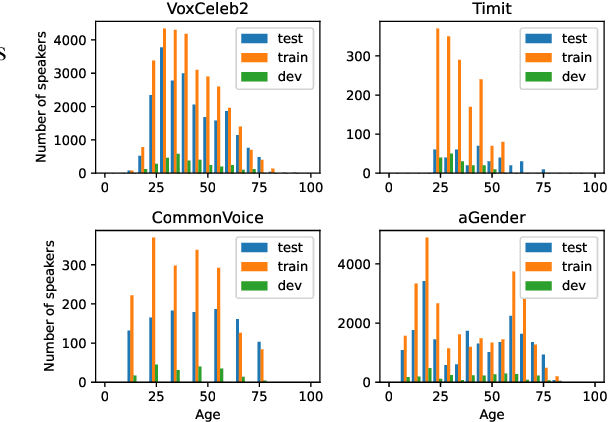
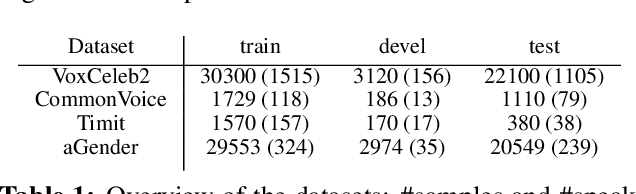
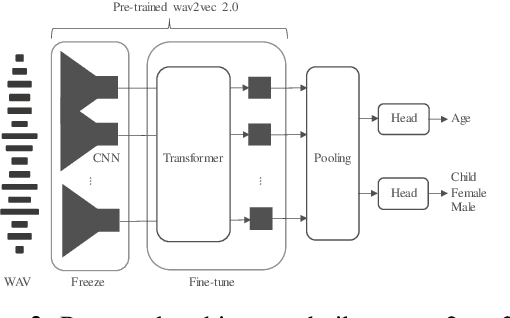

We report on the curation of several publicly available datasets for age and gender prediction. Furthermore, we present experiments to predict age and gender with models based on a pre-trained wav2vec 2.0. Depending on the dataset, we achieve an MAE between 7.1 years and 10.8 years for age, and at least 91.1% ACC for gender (female, male, child). Compared to a modelling approach built on handcrafted features, our proposed system shows an improvement of 9% UAR for age and 4% UAR for gender. To make our findings reproducible, we release the best performing model to the community as well as the sample lists of the data splits.
TranssionADD: A multi-frame reinforcement based sequence tagging model for audio deepfake detection
Jun 27, 2023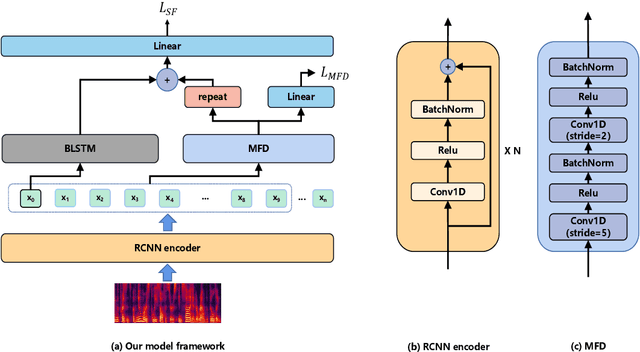

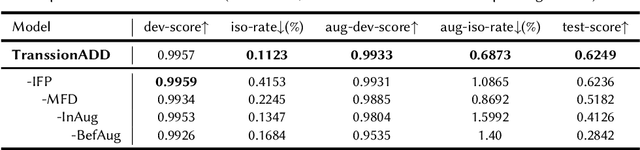
Thanks to recent advancements in end-to-end speech modeling technology, it has become increasingly feasible to imitate and clone a user`s voice. This leads to a significant challenge in differentiating between authentic and fabricated audio segments. To address the issue of user voice abuse and misuse, the second Audio Deepfake Detection Challenge (ADD 2023) aims to detect and analyze deepfake speech utterances. Specifically, Track 2, named the Manipulation Region Location (RL), aims to pinpoint the location of manipulated regions in audio, which can be present in both real and generated audio segments. We propose our novel TranssionADD system as a solution to the challenging problem of model robustness and audio segment outliers in the trace competition. Our system provides three unique contributions: 1) we adapt sequence tagging task for audio deepfake detection; 2) we improve model generalization by various data augmentation techniques; 3) we incorporate multi-frame detection (MFD) module to overcome limited representation provided by a single frame and use isolated-frame penalty (IFP) loss to handle outliers in segments. Our best submission achieved 2nd place in Track 2, demonstrating the effectiveness and robustness of our proposed system.
Deep Transfer Learning for Automatic Speech Recognition: Towards Better Generalization
Apr 27, 2023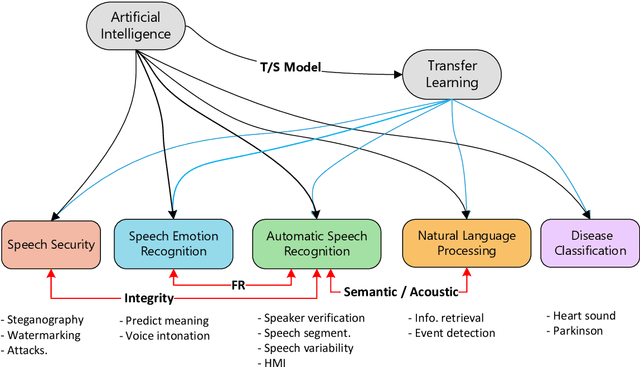
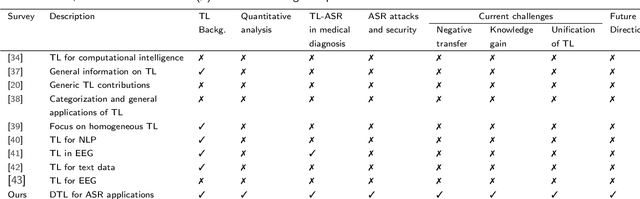
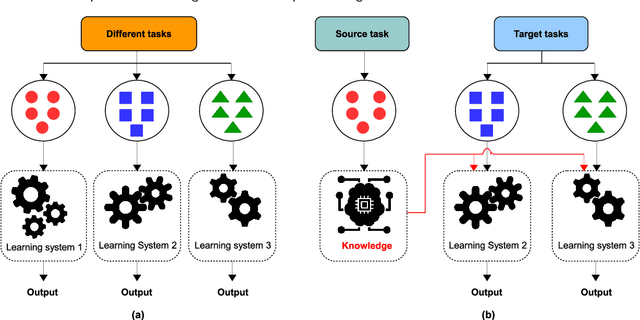

Automatic speech recognition (ASR) has recently become an important challenge when using deep learning (DL). It requires large-scale training datasets and high computational and storage resources. Moreover, DL techniques and machine learning (ML) approaches in general, hypothesize that training and testing data come from the same domain, with the same input feature space and data distribution characteristics. This assumption, however, is not applicable in some real-world artificial intelligence (AI) applications. Moreover, there are situations where gathering real data is challenging, expensive, or rarely occurring, which can not meet the data requirements of DL models. deep transfer learning (DTL) has been introduced to overcome these issues, which helps develop high-performing models using real datasets that are small or slightly different but related to the training data. This paper presents a comprehensive survey of DTL-based ASR frameworks to shed light on the latest developments and helps academics and professionals understand current challenges. Specifically, after presenting the DTL background, a well-designed taxonomy is adopted to inform the state-of-the-art. A critical analysis is then conducted to identify the limitations and advantages of each framework. Moving on, a comparative study is introduced to highlight the current challenges before deriving opportunities for future research.
Adapting Offline Speech Translation Models for Streaming with Future-Aware Distillation and Inference
Mar 14, 2023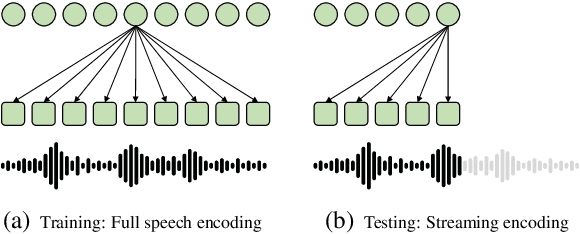
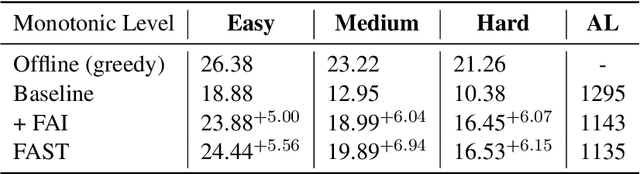
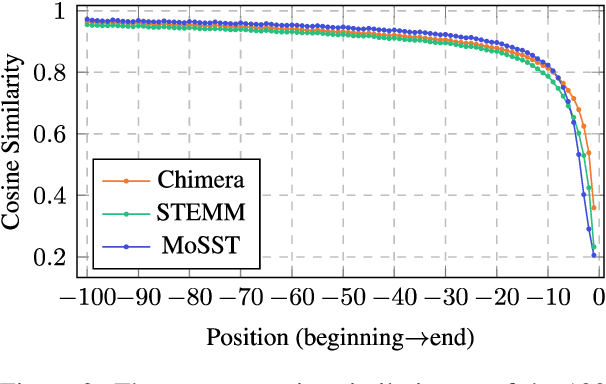
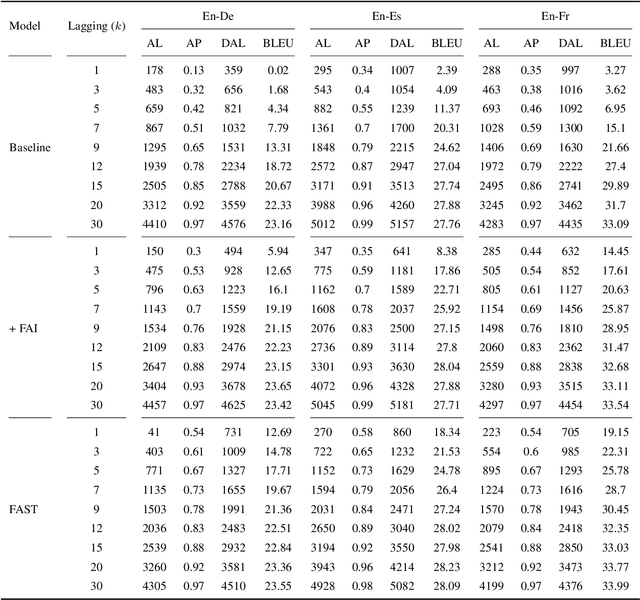
A popular approach to streaming speech translation is to employ a single offline model with a \textit{wait-$k$} policy to support different latency requirements, which is simpler than training multiple online models with different latency constraints. However, there is a mismatch problem in using a model trained with complete utterances for streaming inference with partial input. We demonstrate that speech representations extracted at the end of a streaming input are significantly different from those extracted from a complete utterance. To address this issue, we propose a new approach called Future-Aware Streaming Translation (FAST) that adapts an offline ST model for streaming input. FAST includes a Future-Aware Inference (FAI) strategy that incorporates future context through a trainable masked embedding, and a Future-Aware Distillation (FAD) framework that transfers future context from an approximation of full speech to streaming input. Our experiments on the MuST-C EnDe, EnEs, and EnFr benchmarks show that FAST achieves better trade-offs between translation quality and latency than strong baselines. Extensive analyses suggest that our methods effectively alleviate the aforementioned mismatch problem between offline training and online inference.
MERLIon CCS Challenge Evaluation Plan
May 31, 2023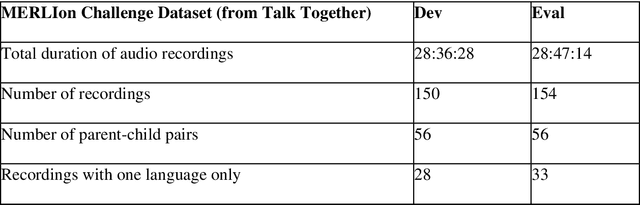
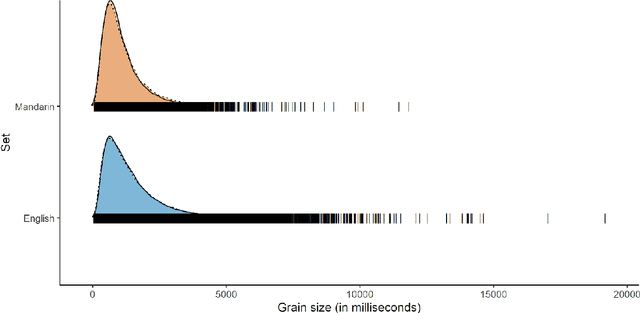
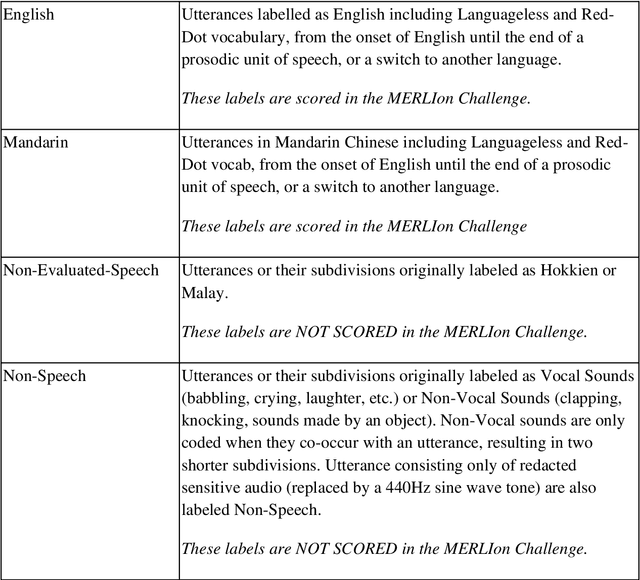
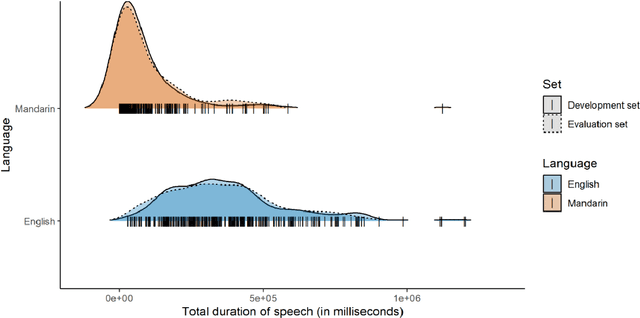
This paper introduces the inaugural Multilingual Everyday Recordings- Language Identification on Code-Switched Child-Directed Speech (MERLIon CCS) Challenge, focused on developing robust language identification and language diarization systems that are reliable for non-standard, accented, spontaneous code-switched, child-directed speech collected via Zoom. Aligning closely with Interspeech 2023 theme, the main objectives of this inaugural challenge are to present a unique first-of-its-kind Zoom videocall dataset featuring English-Mandarin spontaneous code-switched child-directed speech, benchmark the current and novel language identification and language diarization systems in a code-switching scenario including extremely short utterances, and test the robustness of such systems under accented speech. The MERLIon CCS challenge features two task: language identification (Task 1) and language diarization (Task 2). Two tracks, open and closed, are available for each task, differing by the volume of data systems can be trained on. This paper describes the dataset, dataset annotation protocol, challenge tasks, open and closed tracks, evaluation metrics, and evaluation protocol.
Multilingual Multi-Figurative Language Detection
May 31, 2023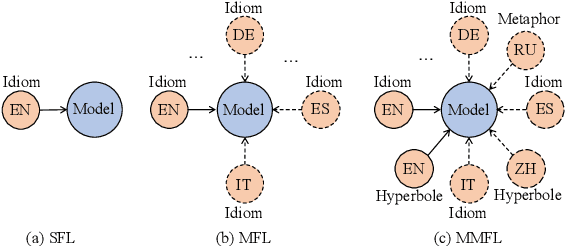

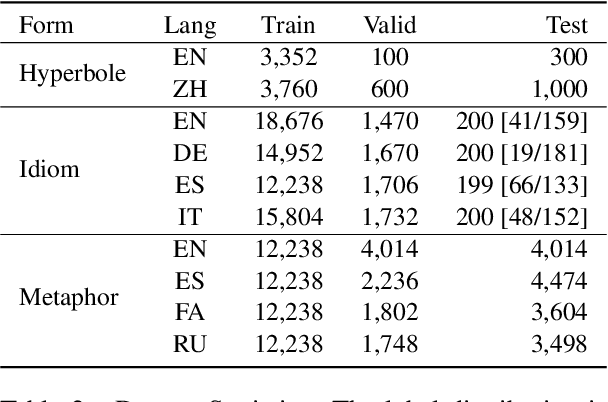
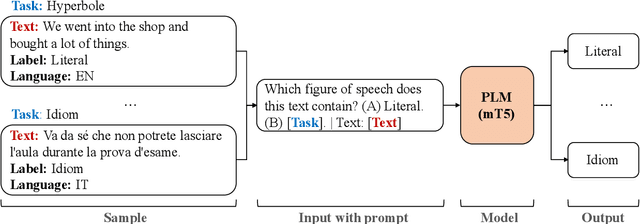
Figures of speech help people express abstract concepts and evoke stronger emotions than literal expressions, thereby making texts more creative and engaging. Due to its pervasive and fundamental character, figurative language understanding has been addressed in Natural Language Processing, but it's highly understudied in a multilingual setting and when considering more than one figure of speech at the same time. To bridge this gap, we introduce multilingual multi-figurative language modelling, and provide a benchmark for sentence-level figurative language detection, covering three common figures of speech and seven languages. Specifically, we develop a framework for figurative language detection based on template-based prompt learning. In so doing, we unify multiple detection tasks that are interrelated across multiple figures of speech and languages, without requiring task- or language-specific modules. Experimental results show that our framework outperforms several strong baselines and may serve as a blueprint for the joint modelling of other interrelated tasks.