 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior-agnostic Multi-scale Contrastive Text-Audio Pre-training for Parallelized TTS Frontend Modeling
Apr 14, 2024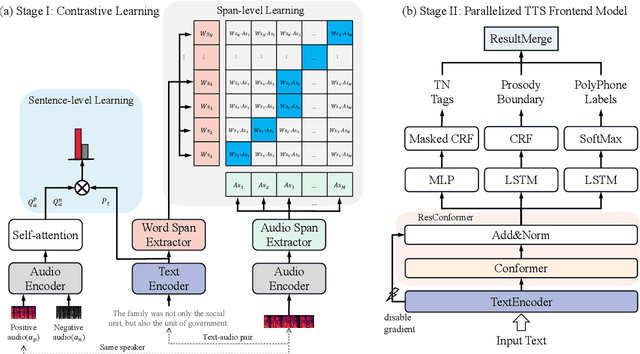
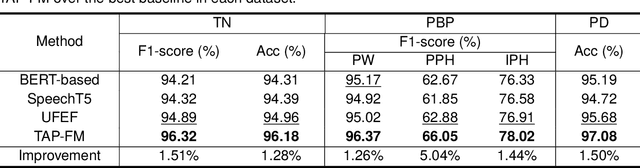

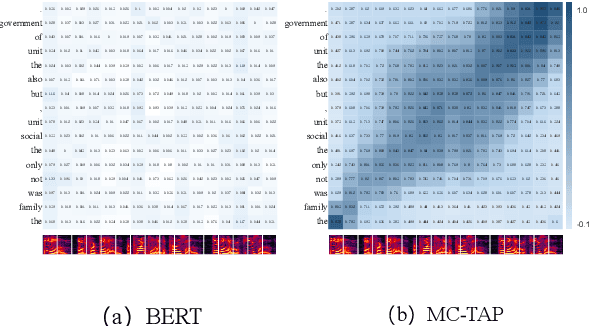
Over the past decade, a series of unflagging efforts have been dedicated to developing highly expressive and controllable text-to-speech (TTS) systems. In general, the holistic TTS comprises two interconnected components: the frontend module and the backend module. The frontend excels in capturing linguistic representations from the raw text input, while the backend module converts linguistic cues to speech. The research community has shown growing interest in the study of the frontend component, recognizing its pivotal role in text-to-speech systems, including Text Normalization (TN), Prosody Boundary Prediction (PBP), and Polyphone Disambiguation (PD). Nonetheless, the limitations posed by insufficient annotated textual data and the reliance on homogeneous text signals significantly undermine the effectiveness of its supervised learning. To evade this obstacle, a novel two-stage TTS frontend prediction pipeline, named TAP-FM, is proposed in this paper. Specifically, during the first learning phase, we present a Multi-scale Contrastive Text-audio Pre-training protocol (MC-TAP), which hammers at acquiring richer insights via multi-granularity contrastive pre-training in an unsupervised manner. Instead of mining homogeneous features in prior pre-training approaches, our framework demonstrates the ability to delve deep into both global and local text-audio semantic and acoustic representations. Furthermore, a parallelized TTS frontend model is delicately devised to execute TN, PD, and PBP prediction tasks, respectively in the second stage. Finally, extensive experiments illustrate the superiority of our proposed method, achieving state-of-the-art performance.
Knowledge-aware Collaborative Filtering with Pre-trained Language Model for Personalized Review-based Rating Prediction
Aug 02, 2023



Personalized review-based rating prediction aims at leveraging existing reviews to model user interests and item characteristics for rating prediction. Most of the existing studies mainly encounter two issues. First, the rich knowledge contained in the fine-grained aspects of each review and the knowledge graph is rarely considered to complement the pure text for better modeling user-item interactions. Second, the power of pre-trained language models is not carefully studied for personalized review-based rating prediction. To address these issues, we propose an approach named Knowledge-aware Collaborative Filtering with Pre-trained Language Model (KCF-PLM). For the first issue, to utilize rich knowledge, KCF-PLM develops a transformer network to model the interactions of the extracted aspects w.r.t. a user-item pair. For the second issue, to better represent users and items, KCF-PLM takes all the historical reviews of a user or an item as input to pre-trained language models. Moreover, KCF-PLM integrates the transformer network and the pre-trained language models through representation propagation on the knowledge graph and user-item guided attention of the aspect representations. Thus KCF-PLM combines review text, aspect, knowledge graph, and pre-trained language models together for review-based rating prediction. We conduct comprehensive experiments on several public datasets, demonstrating the effectiveness of KCF-PLM.
TranssionADD: A multi-frame reinforcement based sequence tagging model for audio deepfake detection
Jun 27, 2023


Thanks to recent advancements in end-to-end speech modeling technology, it has become increasingly feasible to imitate and clone a user`s voice. This leads to a significant challenge in differentiating between authentic and fabricated audio segments. To address the issue of user voice abuse and misuse, the second Audio Deepfake Detection Challenge (ADD 2023) aims to detect and analyze deepfake speech utterances. Specifically, Track 2, named the Manipulation Region Location (RL), aims to pinpoint the location of manipulated regions in audio, which can be present in both real and generated audio segments. We propose our novel TranssionADD system as a solution to the challenging problem of model robustness and audio segment outliers in the trace competition. Our system provides three unique contributions: 1) we adapt sequence tagging task for audio deepfake detection; 2) we improve model generalization by various data augmentation techniques; 3) we incorporate multi-frame detection (MFD) module to overcome limited representation provided by a single frame and use isolated-frame penalty (IFP) loss to handle outliers in segments. Our best submission achieved 2nd place in Track 2, demonstrating the effectiveness and robustness of our proposed system.
Capturing Event Argument Interaction via A Bi-Directional Entity-Level Recurrent Decoder
Jul 01, 2021
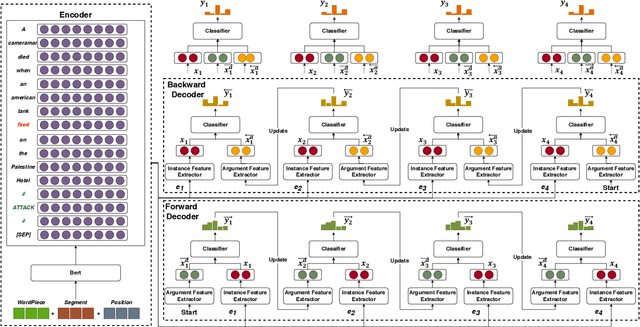
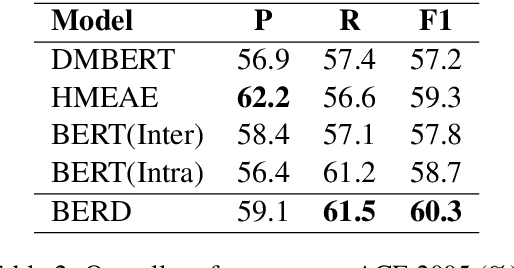
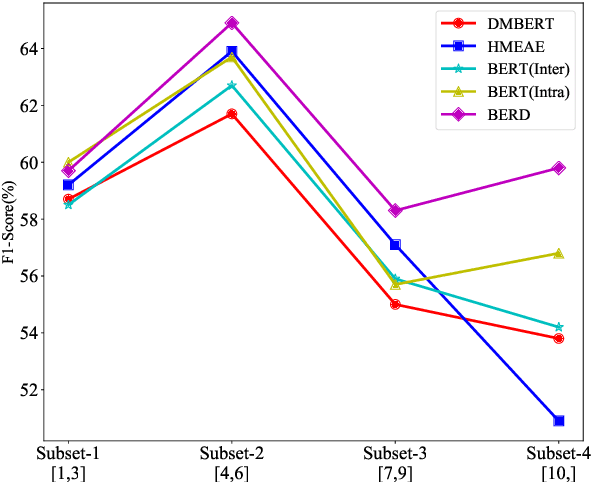
Capturing interactions among event arguments is an essential step towards robust event argument extraction (EAE). However, existing efforts in this direction suffer from two limitations: 1) The argument role type information of contextual entities is mainly utilized as training signals, ignoring the potential merits of directly adopting it as semantically rich input features; 2) The argument-level sequential semantics, which implies the overall distribution pattern of argument roles over an event mention, is not well characterized. To tackle the above two bottlenecks, we formalize EAE as a Seq2Seq-like learning problem for the first time, where a sentence with a specific event trigger is mapped to a sequence of event argument roles. A neural architecture with a novel Bi-directional Entity-level Recurrent Decoder (BERD) is proposed to generate argument roles by incorporating contextual entities' argument role predictions, like a word-by-word text generation process, thereby distinguishing implicit argument distribution patterns within an event more accurately.