 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Personalization for BERT-based Discriminative Speech Recognition Rescoring
Jul 13, 2023
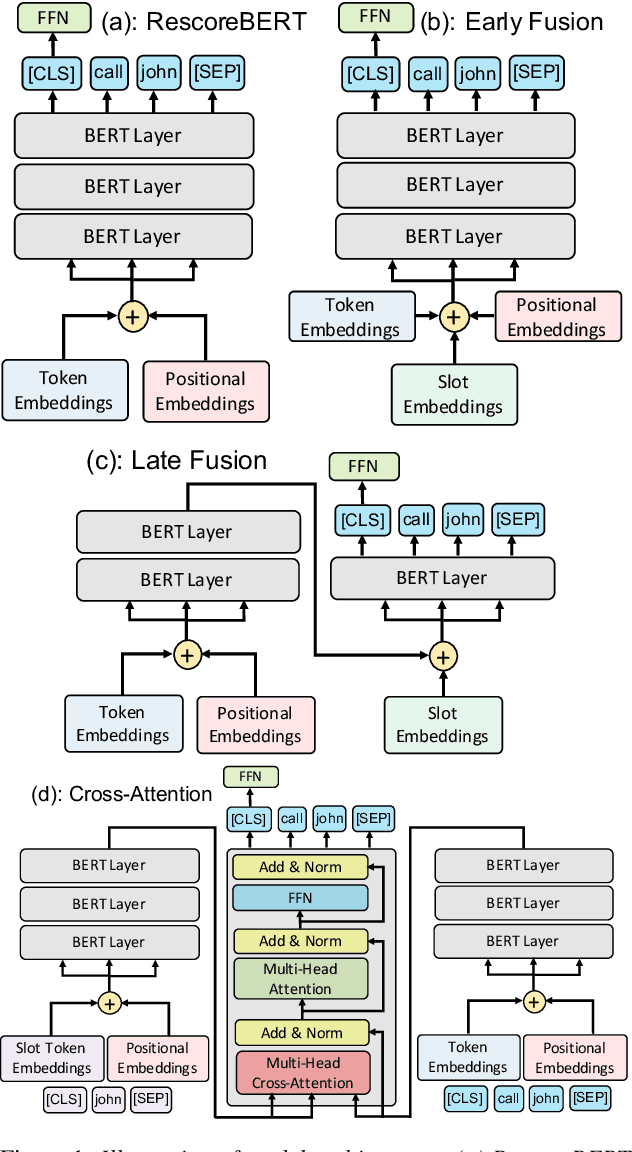

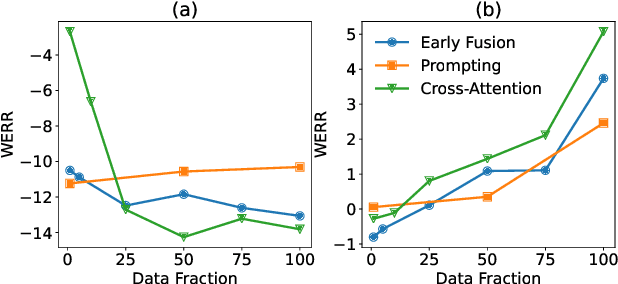
Recognition of personalized content remains a challenge in end-to-end speech recognition. We explore three novel approaches that use personalized content in a neural rescoring step to improve recognition: gazetteers, prompting, and a cross-attention based encoder-decoder model. We use internal de-identified en-US data from interactions with a virtual voice assistant supplemented with personalized named entities to compare these approaches. On a test set with personalized named entities, we show that each of these approaches improves word error rate by over 10%, against a neural rescoring baseline. We also show that on this test set, natural language prompts can improve word error rate by 7% without any training and with a marginal loss in generalization. Overall, gazetteers were found to perform the best with a 10% improvement in word error rate (WER), while also improving WER on a general test set by 1%.
Textually Pretrained Speech Language Models
May 22, 2023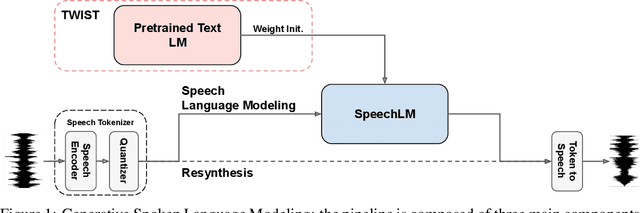

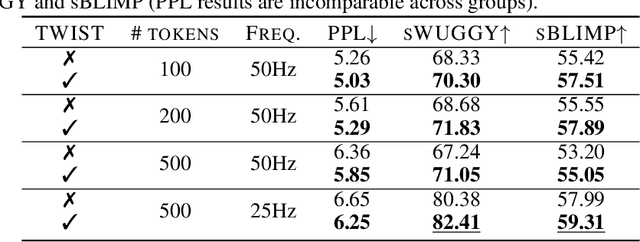
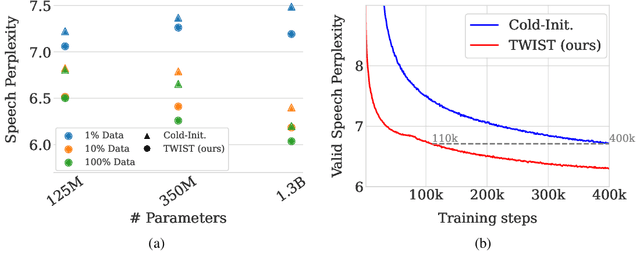
Speech language models (SpeechLMs) process and generate acoustic data only, without textual supervision. In this work, we propose TWIST, a method for training SpeechLMs using a warm-start from a pretrained textual language models. We show using both automatic and human evaluations that TWIST outperforms a cold-start SpeechLM across the board. We empirically analyze the effect of different model design choices such as the speech tokenizer, the pretrained textual model, and the dataset size. We find that model and dataset scale both play an important role in constructing better-performing SpeechLMs. Based on our observations, we present the largest (to the best of our knowledge) SpeechLM both in terms of number of parameters and training data. We additionally introduce two spoken versions of the StoryCloze textual benchmark to further improve model evaluation and advance future research in the field. Speech samples can be found on our website: https://pages.cs.huji.ac.il/adiyoss-lab/twist/ .
Simulating room transfer functions between transducers mounted on audio devices using a modified image source method
Sep 07, 2023The image source method (ISM) is often used to simulate room acoustics due to its ease of use and computational efficiency. The standard ISM is limited to simulations of room impulse responses between point sources and omnidirectional receivers. In this work, the ISM is extended using spherical harmonic directivity coefficients to include acoustic diffraction effects due to source and receiver transducers mounted on physical devices, which are typically encountered in practical situations. The proposed method is verified using finite element simulations of various loudspeaker and microphone configurations in a rectangular room. It is shown that the accuracy of the proposed method is related to the sizes, shapes, number, and positions of the devices inside a room. A simplified version of the proposed method, which can significantly reduce computational effort, is also presented. The proposed method and its simplified version can simulate room transfer functions more accurately than currently available image source methods and can aid the development and evaluation of speech and acoustic signal processing algorithms, including speech enhancement, acoustic scene analysis, and acoustic parameter estimation.
An Analysis of Personalized Speech Recognition System Development for the Deaf and Hard-of-Hearing
Jun 24, 2023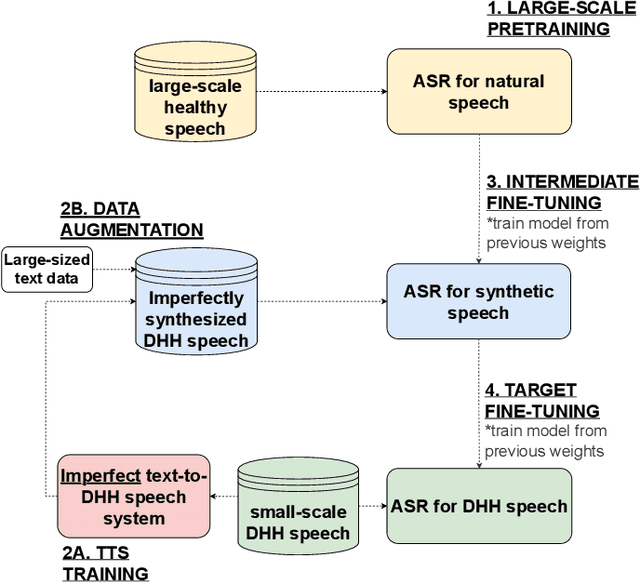
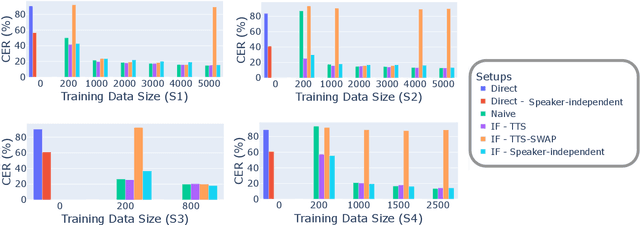
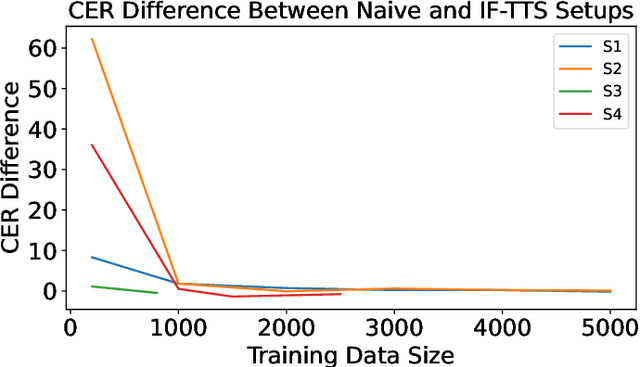
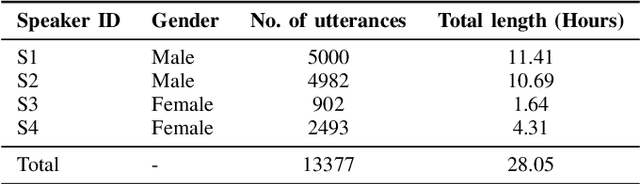
Deaf or hard-of-hearing (DHH) speakers typically have atypical speech caused by deafness. With the growing support of speech-based devices and software applications, more work needs to be done to make these devices inclusive to everyone. To do so, we analyze the use of openly-available automatic speech recognition (ASR) tools with a DHH Japanese speaker dataset. As these out-of-the-box ASR models typically do not perform well on DHH speech, we provide a thorough analysis of creating personalized ASR systems. We collected a large DHH speaker dataset of four speakers totaling around 28.05 hours and thoroughly analyzed the performance of different training frameworks by varying the training data sizes. Our findings show that 1000 utterances (or 1-2 hours) from a target speaker can already significantly improve the model performance with minimal amount of work needed, thus we recommend researchers to collect at least 1000 utterances to make an efficient personalized ASR system. In cases where 1000 utterances is difficult to collect, we also discover significant improvements in using previously proposed data augmentation techniques such as intermediate fine-tuning when only 200 utterances are available.
Sparks of Large Audio Models: A Survey and Outlook
Sep 03, 2023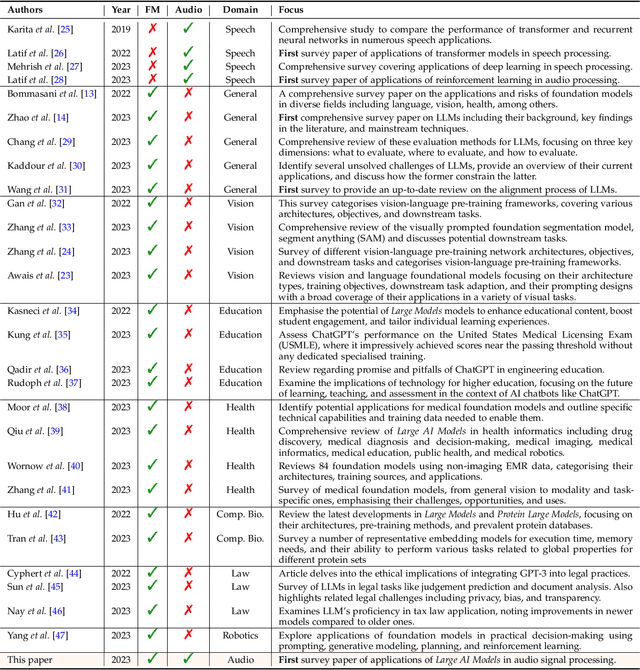

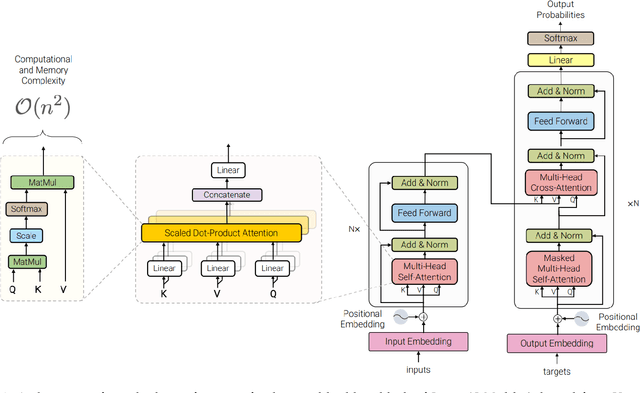
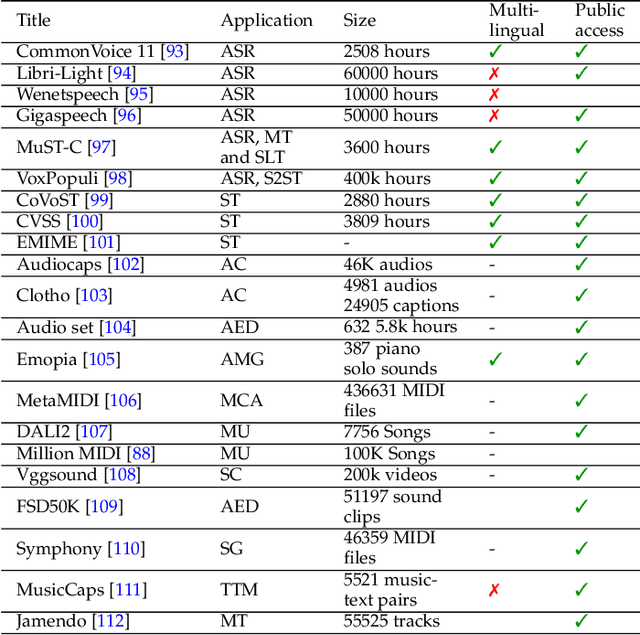
This survey paper provides a comprehensive overview of the recent advancements and challenges in applying large language models to the field of audio signal processing. Audio processing, with its diverse signal representations and a wide range of sources--from human voices to musical instruments and environmental sounds--poses challenges distinct from those found in traditional Natural Language Processing scenarios. Nevertheless, \textit{Large Audio Models}, epitomized by transformer-based architectures, have shown marked efficacy in this sphere. By leveraging massive amount of data, these models have demonstrated prowess in a variety of audio tasks, spanning from Automatic Speech Recognition and Text-To-Speech to Music Generation, among others. Notably, recently these Foundational Audio Models, like SeamlessM4T, have started showing abilities to act as universal translators, supporting multiple speech tasks for up to 100 languages without any reliance on separate task-specific systems. This paper presents an in-depth analysis of state-of-the-art methodologies regarding \textit{Foundational Large Audio Models}, their performance benchmarks, and their applicability to real-world scenarios. We also highlight current limitations and provide insights into potential future research directions in the realm of \textit{Large Audio Models} with the intent to spark further discussion, thereby fostering innovation in the next generation of audio-processing systems. Furthermore, to cope with the rapid development in this area, we will consistently update the relevant repository with relevant recent articles and their open-source implementations at https://github.com/EmulationAI/awesome-large-audio-models.
Towards training Bilingual and Code-Switched Speech Recognition models from Monolingual data sources
Jun 14, 2023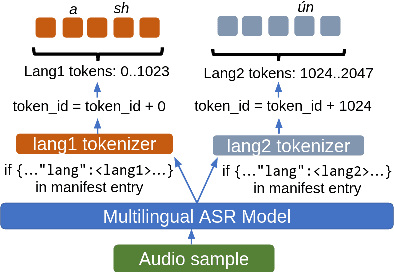
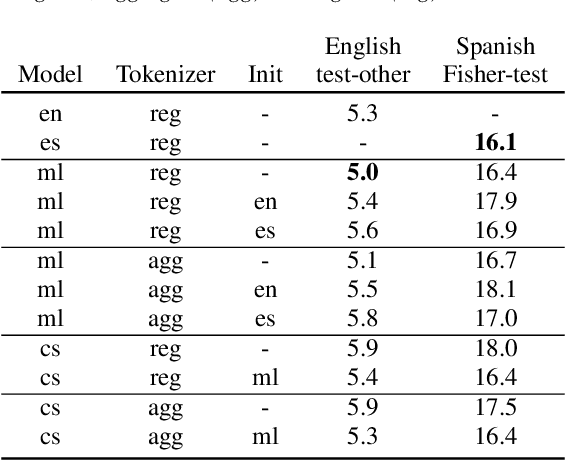
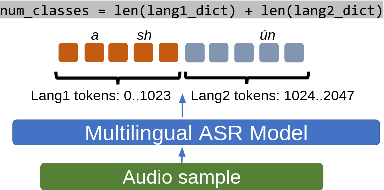
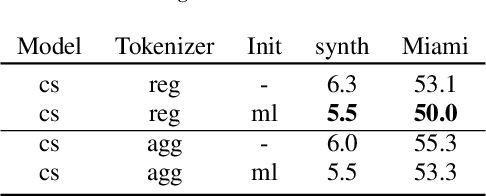
Multilingual Automatic Speech Recognition (ASR) models are capable of transcribing audios across multiple languages, eliminating the need for separate models. In addition, they can perform Language Identification (LID) and handle code-switched speech. However, training these models requires special code-switch and multilingual speech corpora which are sparsely available. In this paper, we evaluate different approaches towards training of bilingual as well as code-switched ASR models using purely monolingual data sources. We introduce the concept of aggregate tokenizers that differs from the current prevalent technique of generating LIDs at the boundaries of monolingual samples and produces LID for each emitted token instead. We compare bilingual and monolingual model performance, showcase the efficacy of aggregate tokenizers, present a synthetic code-switched ASR data generation technique and demonstrate the effectiveness of the proposed code-switched ASR models for the tasks of speech recognition and spoken language identification.
Rhythm-controllable Attention with High Robustness for Long Sentence Speech Synthesis
Jun 05, 2023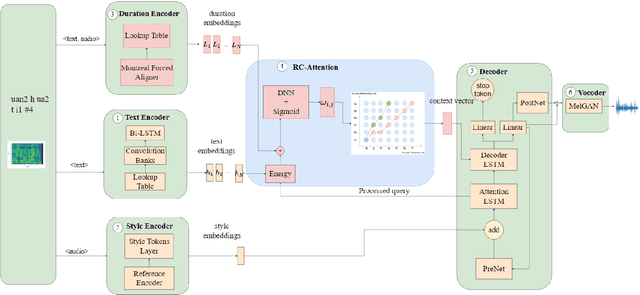
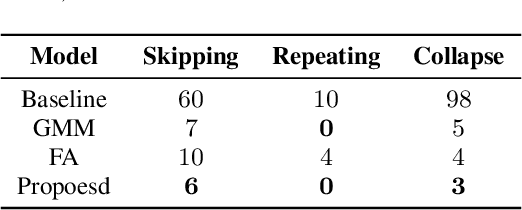
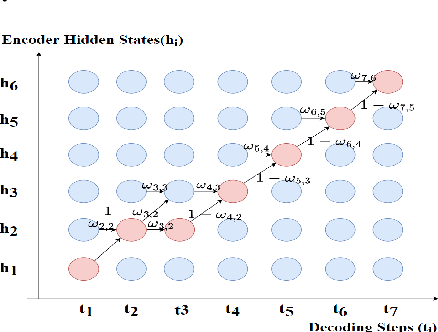
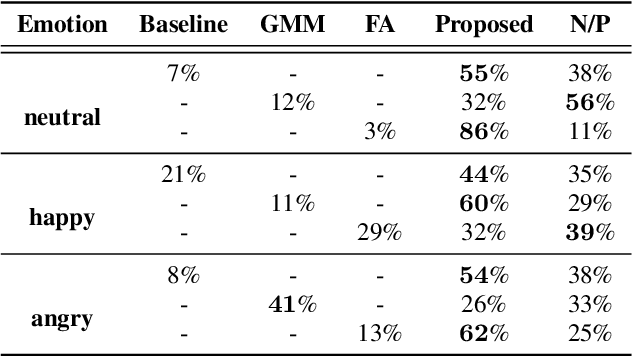
Regressive Text-to-Speech (TTS) system utilizes attention mechanism to generate alignment between text and acoustic feature sequence. Alignment determines synthesis robustness (e.g, the occurence of skipping, repeating, and collapse) and rhythm via duration control. However, current attention algorithms used in speech synthesis cannot control rhythm using external duration information to generate natural speech while ensuring robustness. In this study, we propose Rhythm-controllable Attention (RC-Attention) based on Tracotron2, which improves robustness and naturalness simultaneously. Proposed attention adopts a trainable scalar learned from four kinds of information to achieve rhythm control, which makes rhythm control more robust and natural, even when synthesized sentences are extremely longer than training corpus. We use word errors counting and AB preference test to measure robustness of proposed method and naturalness of synthesized speech, respectively. Results shows that RC-Attention has the lowest word error rate of nearly 0.6%, compared with 11.8% for baseline system. Moreover, nearly 60% subjects prefer to the speech synthesized with RC-Attention to that with Forward Attention, because the former has more natural rhythm.
Language-Universal Phonetic Representation in Multilingual Speech Pretraining for Low-Resource Speech Recognition
May 19, 2023

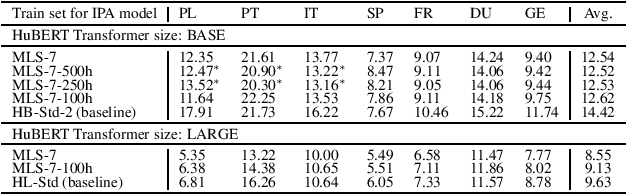
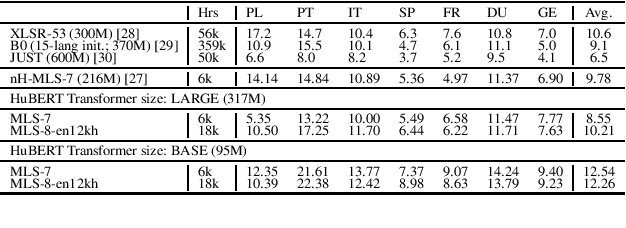
We improve low-resource ASR by integrating the ideas of multilingual training and self-supervised learning. Concretely, we leverage an International Phonetic Alphabet (IPA) multilingual model to create frame-level pseudo labels for unlabeled speech, and use these pseudo labels to guide hidden-unit BERT (HuBERT) based speech pretraining in a phonetically-informed manner. The experiments on the Multilingual Speech (MLS) Corpus show that the proposed approach consistently outperforms the standard HuBERT on all the target languages. Moreover, on 3 of the 4 languages, comparing to the standard HuBERT, the approach performs better, meanwhile is able to save supervised training data by 1.5k hours (75%) at most. Our approach outperforms most of the state of the arts, with much less pretraining data in terms of hours and language diversity. Compared to XLSR-53 and a retraining based multilingual method, our approach performs better with full and limited finetuning data scenarios.
Neural approaches to spoken content embedding
Aug 28, 2023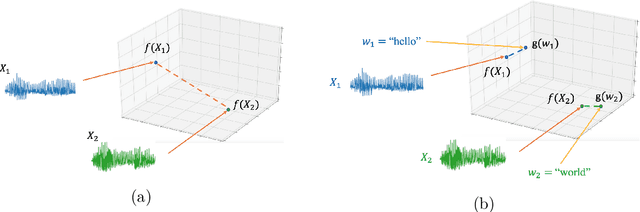
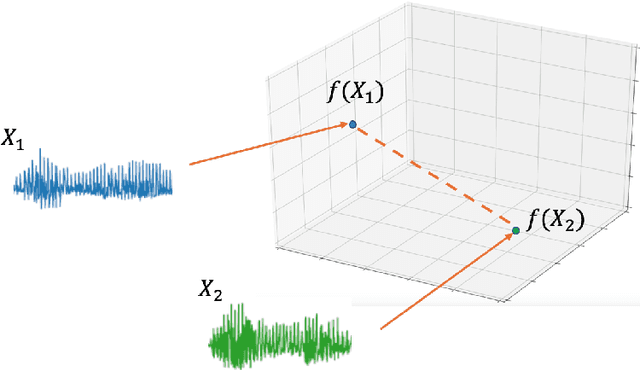
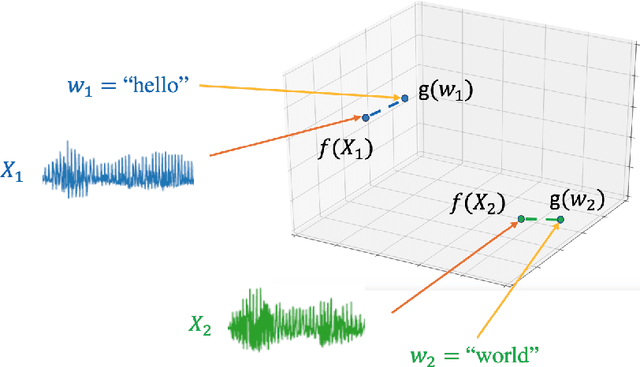
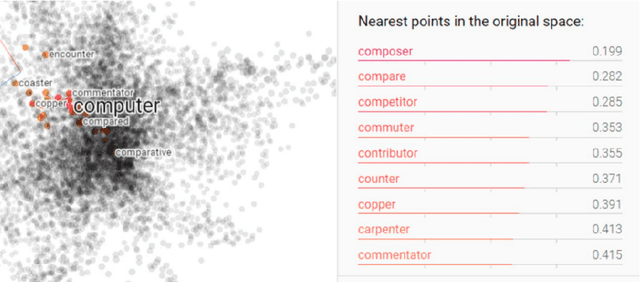
Comparing spoken segments is a central operation to speech processing. Traditional approaches in this area have favored frame-level dynamic programming algorithms, such as dynamic time warping, because they require no supervision, but they are limited in performance and efficiency. As an alternative, acoustic word embeddings -- fixed-dimensional vector representations of variable-length spoken word segments -- have begun to be considered for such tasks as well. However, the current space of such discriminative embedding models, training approaches, and their application to real-world downstream tasks is limited. We start by considering ``single-view" training losses where the goal is to learn an acoustic word embedding model that separates same-word and different-word spoken segment pairs. Then, we consider ``multi-view" contrastive losses. In this setting, acoustic word embeddings are learned jointly with embeddings of character sequences to generate acoustically grounded embeddings of written words, or acoustically grounded word embeddings. In this thesis, we contribute new discriminative acoustic word embedding (AWE) and acoustically grounded word embedding (AGWE) approaches based on recurrent neural networks (RNNs). We improve model training in terms of both efficiency and performance. We take these developments beyond English to several low-resource languages and show that multilingual training improves performance when labeled data is limited. We apply our embedding models, both monolingual and multilingual, to the downstream tasks of query-by-example speech search and automatic speech recognition. Finally, we show how our embedding approaches compare with and complement more recent self-supervised speech models.
VAKTA-SETU: A Speech-to-Speech Machine Translation Service in Select Indic Languages
May 21, 2023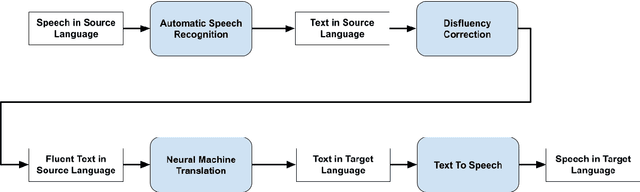
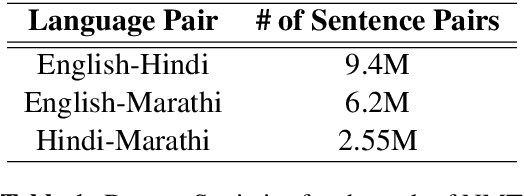
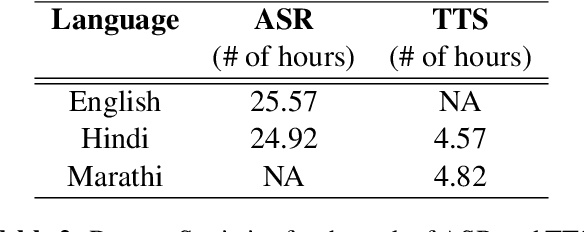

In this work, we present our deployment-ready Speech-to-Speech Machine Translation (SSMT) system for English-Hindi, English-Marathi, and Hindi-Marathi language pairs. We develop the SSMT system by cascading Automatic Speech Recognition (ASR), Disfluency Correction (DC), Machine Translation (MT), and Text-to-Speech Synthesis (TTS) models. We discuss the challenges faced during the research and development stage and the scalable deployment of the SSMT system as a publicly accessible web service. On the MT part of the pipeline too, we create a Text-to-Text Machine Translation (TTMT) service in all six translation directions involving English, Hindi, and Marathi. To mitigate data scarcity, we develop a LaBSE-based corpus filtering tool to select high-quality parallel sentences from a noisy pseudo-parallel corpus for training the TTMT system. All the data used for training the SSMT and TTMT systems and the best models are being made publicly available. Users of our system are (a) Govt. of India in the context of its new education policy (NEP), (b) tourists who criss-cross the multilingual landscape of India, (c) Indian Judiciary where a leading cause of the pendency of cases (to the order of 10 million as on date) is the translation of case papers, (d) farmers who need weather and price information and so on. We also share the feedback received from various stakeholders when our SSMT and TTMT systems were demonstrated in large public events.