 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Regressive vs Flow-Matching: a Comparative Study of Modeling Paradigms for Text-to-Music Generation
Jun 11, 2025Recent progress in text-to-music generation has enabled models to synthesize high-quality musical segments, full compositions, and even respond to fine-grained control signals, e.g. chord progressions. State-of-the-art (SOTA) systems differ significantly across many dimensions, such as training datasets, modeling paradigms, and architectural choices. This diversity complicates efforts to evaluate models fairly and pinpoint which design choices most influence performance. While factors like data and architecture are important, in this study we focus exclusively on the modeling paradigm. We conduct a systematic empirical analysis to isolate its effects, offering insights into associated trade-offs and emergent behaviors that can guide future text-to-music generation systems. Specifically, we compare the two arguably most common modeling paradigms: Auto-Regressive decoding and Conditional Flow-Matching. We conduct a controlled comparison by training all models from scratch using identical datasets, training configurations, and similar backbone architectures. Performance is evaluated across multiple axes, including generation quality, robustness to inference configurations, scalability, adherence to both textual and temporally aligned conditioning, and editing capabilities in the form of audio inpainting. This comparative study sheds light on distinct strengths and limitations of each paradigm, providing actionable insights that can inform future architectural and training decisions in the evolving landscape of text-to-music generation. Audio sampled examples are available at: https://huggingface.co/spaces/ortal1602/ARvsFM
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Discrete Flow Matching
Jul 22, 2024Despite Flow Matching and diffusion models having emerged as powerful generative paradigms for continuous variables such as images and videos, their application to high-dimensional discrete data, such as language, is still limited. In this work, we present Discrete Flow Matching, a novel discrete flow paradigm designed specifically for generating discrete data. Discrete Flow Matching offers several key contributions: (i) it works with a general family of probability paths interpolating between source and target distributions; (ii) it allows for a generic formula for sampling from these probability paths using learned posteriors such as the probability denoiser ($x$-prediction) and noise-prediction ($\epsilon$-prediction); (iii) practically, focusing on specific probability paths defined with different schedulers considerably improves generative perplexity compared to previous discrete diffusion and flow models; and (iv) by scaling Discrete Flow Matching models up to 1.7B parameters, we reach 6.7% Pass@1 and 13.4% Pass@10 on HumanEval and 6.7% Pass@1 and 20.6% Pass@10 on 1-shot MBPP coding benchmarks. Our approach is capable of generating high-quality discrete data in a non-autoregressive fashion, significantly closing the gap between autoregressive models and discrete flow models.
Joint Audio and Symbolic Conditioning for Temporally Controlled Text-to-Music Generation
Jun 16, 2024We present JASCO, a temporally controlled text-to-music generation model utilizing both symbolic and audio-based conditions. JASCO can generate high-quality music samples conditioned on global text descriptions along with fine-grained local controls. JASCO is based on the Flow Matching modeling paradigm together with a novel conditioning method. This allows music generation controlled both locally (e.g., chords) and globally (text description). Specifically, we apply information bottleneck layers in conjunction with temporal blurring to extract relevant information with respect to specific controls. This allows the incorporation of both symbolic and audio-based conditions in the same text-to-music model. We experiment with various symbolic control signals (e.g., chords, melody), as well as with audio representations (e.g., separated drum tracks, full-mix). We evaluate JASCO considering both generation quality and condition adherence, using both objective metrics and human studies. Results suggest that JASCO is comparable to the evaluated baselines considering generation quality while allowing significantly better and more versatile controls over the generated music. Samples are available on our demo page https://pages.cs.huji.ac.il/adiyoss-lab/JASCO.
Masked Audio Generation using a Single Non-Autoregressive Transformer
Jan 09, 2024
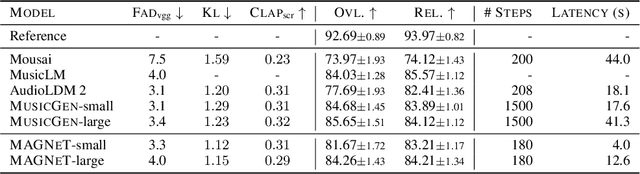


We introduce MAGNeT, a masked generative sequence modeling method that operates directly over several streams of audio tokens. Unlike prior work, MAGNeT is comprised of a single-stage, non-autoregressive transformer. During training, we predict spans of masked tokens obtained from a masking scheduler, while during inference we gradually construct the output sequence using several decoding steps. To further enhance the quality of the generated audio, we introduce a novel rescoring method in which, we leverage an external pre-trained model to rescore and rank predictions from MAGNeT, which will be then used for later decoding steps. Lastly, we explore a hybrid version of MAGNeT, in which we fuse between autoregressive and non-autoregressive models to generate the first few seconds in an autoregressive manner while the rest of the sequence is being decoded in parallel. We demonstrate the efficiency of MAGNeT for the task of text-to-music and text-to-audio generation and conduct an extensive empirical evaluation, considering both objective metrics and human studies. The proposed approach is comparable to the evaluated baselines, while being significantly faster (x7 faster than the autoregressive baseline). Through ablation studies and analysis, we shed light on the importance of each of the components comprising MAGNeT, together with pointing to the trade-offs between autoregressive and non-autoregressive modeling, considering latency, throughput, and generation quality. Samples are available on our demo page https://pages.cs.huji.ac.il/adiyoss-lab/MAGNeT.
EXPRESSO: A Benchmark and Analysis of Discrete Expressive Speech Resynthesis
Aug 10, 2023



Recent work has shown that it is possible to resynthesize high-quality speech based, not on text, but on low bitrate discrete units that have been learned in a self-supervised fashion and can therefore capture expressive aspects of speech that are hard to transcribe (prosody, voice styles, non-verbal vocalization). The adoption of these methods is still limited by the fact that most speech synthesis datasets are read, severely limiting spontaneity and expressivity. Here, we introduce Expresso, a high-quality expressive speech dataset for textless speech synthesis that includes both read speech and improvised dialogues rendered in 26 spontaneous expressive styles. We illustrate the challenges and potentials of this dataset with an expressive resynthesis benchmark where the task is to encode the input in low-bitrate units and resynthesize it in a target voice while preserving content and style. We evaluate resynthesis quality with automatic metrics for different self-supervised discrete encoders, and explore tradeoffs between quality, bitrate and invariance to speaker and style. All the dataset, evaluation metrics and baseline models are open source
Simple and Controllable Music Generation
Jun 08, 2023We tackle the task of conditional music generation. We introduce MusicGen, a single Language Model (LM) that operates over several streams of compressed discrete music representation, i.e., tokens. Unlike prior work, MusicGen is comprised of a single-stage transformer LM together with efficient token interleaving patterns, which eliminates the need for cascading several models, e.g., hierarchically or upsampling. Following this approach, we demonstrate how MusicGen can generate high-quality samples, while being conditioned on textual description or melodic features, allowing better controls over the generated output. We conduct extensive empirical evaluation, considering both automatic and human studies, showing the proposed approach is superior to the evaluated baselines on a standard text-to-music benchmark. Through ablation studies, we shed light over the importance of each of the components comprising MusicGen. Music samples, code, and models are available at https://github.com/facebookresearch/audiocraft.
Textually Pretrained Speech Language Models
May 22, 2023



Speech language models (SpeechLMs) process and generate acoustic data only, without textual supervision. In this work, we propose TWIST, a method for training SpeechLMs using a warm-start from a pretrained textual language models. We show using both automatic and human evaluations that TWIST outperforms a cold-start SpeechLM across the board. We empirically analyze the effect of different model design choices such as the speech tokenizer, the pretrained textual model, and the dataset size. We find that model and dataset scale both play an important role in constructing better-performing SpeechLMs. Based on our observations, we present the largest (to the best of our knowledge) SpeechLM both in terms of number of parameters and training data. We additionally introduce two spoken versions of the StoryCloze textual benchmark to further improve model evaluation and advance future research in the field. Speech samples can be found on our website: https://pages.cs.huji.ac.il/adiyoss-lab/twist/ .
Audio Language Modeling using Perceptually-Guided Discrete Representations
Nov 04, 2022In this work, we study the task of Audio Language Modeling, in which we aim at learning probabilistic models for audio that can be used for generation and completion. We use a state-of-the-art perceptually-guided audio compression model, to encode audio to discrete representations. Next, we train a transformer-based causal language model using these representations. At inference time, we perform audio auto-completion by encoding an audio prompt as a discrete sequence, feeding it to the audio language model, sampling from the model, and synthesizing the corresponding time-domain signal. We evaluate the quality of samples generated by our method on Audioset, the largest dataset for general audio to date, and show that it is superior to the evaluated baseline audio encoders. We additionally provide an extensive analysis to better understand the trade-off between audio-quality and language-modeling capabilities. Samples:link.
On The Robustness of Self-Supervised Representations for Spoken Language Modeling
Sep 30, 2022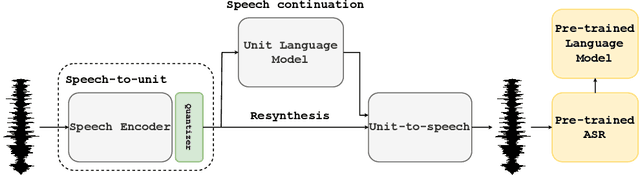
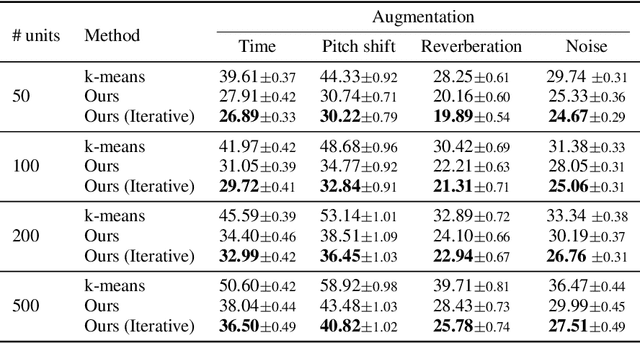
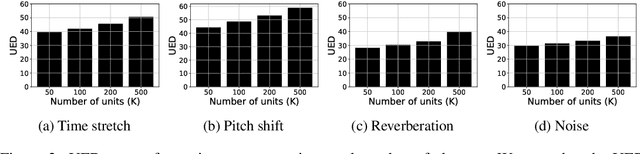
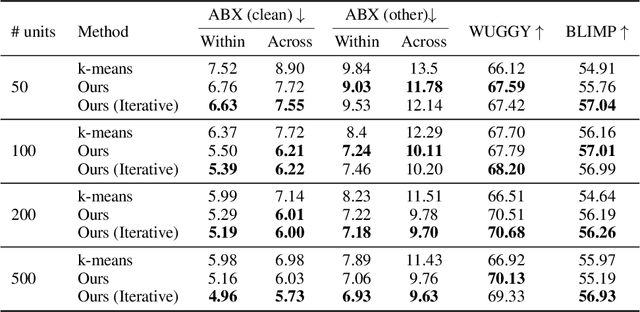
Self-supervised representations have been extensively studied for discriminative and generative tasks. However, their robustness capabilities have not been extensively investigated. This work focuses on self-supervised representations for spoken generative language models. First, we empirically demonstrate how current state-of-the-art speech representation models lack robustness to basic signal variations that do not alter the spoken information. To overcome this, we propose an effective and efficient method to learn robust self-supervised speech representation for generative spoken language modeling. The proposed approach is based on applying a set of signal transformations to the speech signal and optimizing the model using an iterative pseudo-labeling scheme. Our method significantly improves over the evaluated baselines when considering encoding metrics. We additionally evaluate our method on the speech-to-speech translation task. We consider Spanish-English and French-English conversions and empirically demonstrate the benefits of following the proposed approach.