 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCONCSS: Contrastive-based Context Comprehension for Dialogue-appropriate Prosody in Conversational Speech Synthesis
Dec 16, 2023Conversational speech synthesis (CSS) incorporates historical dialogue as supplementary information with the aim of generating speech that has dialogue-appropriate prosody. While previous methods have already delved into enhancing context comprehension, context representation still lacks effective representation capabilities and context-sensitive discriminability. In this paper, we introduce a contrastive learning-based CSS framework, CONCSS. Within this framework, we define an innovative pretext task specific to CSS that enables the model to perform self-supervised learning on unlabeled conversational datasets to boost the model's context understanding. Additionally, we introduce a sampling strategy for negative sample augmentation to enhance context vectors' discriminability. This is the first attempt to integrate contrastive learning into CSS. We conduct ablation studies on different contrastive learning strategies and comprehensive experiments in comparison with prior CSS systems. Results demonstrate that the synthesized speech from our proposed method exhibits more contextually appropriate and sensitive prosody.
Rhythm-controllable Attention with High Robustness for Long Sentence Speech Synthesis
Jun 05, 2023



Regressive Text-to-Speech (TTS) system utilizes attention mechanism to generate alignment between text and acoustic feature sequence. Alignment determines synthesis robustness (e.g, the occurence of skipping, repeating, and collapse) and rhythm via duration control. However, current attention algorithms used in speech synthesis cannot control rhythm using external duration information to generate natural speech while ensuring robustness. In this study, we propose Rhythm-controllable Attention (RC-Attention) based on Tracotron2, which improves robustness and naturalness simultaneously. Proposed attention adopts a trainable scalar learned from four kinds of information to achieve rhythm control, which makes rhythm control more robust and natural, even when synthesized sentences are extremely longer than training corpus. We use word errors counting and AB preference test to measure robustness of proposed method and naturalness of synthesized speech, respectively. Results shows that RC-Attention has the lowest word error rate of nearly 0.6%, compared with 11.8% for baseline system. Moreover, nearly 60% subjects prefer to the speech synthesized with RC-Attention to that with Forward Attention, because the former has more natural rhythm.
Text-Aware End-to-end Mispronunciation Detection and Diagnosis
Jun 15, 2022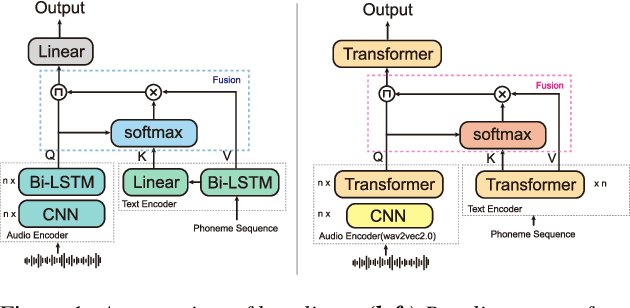
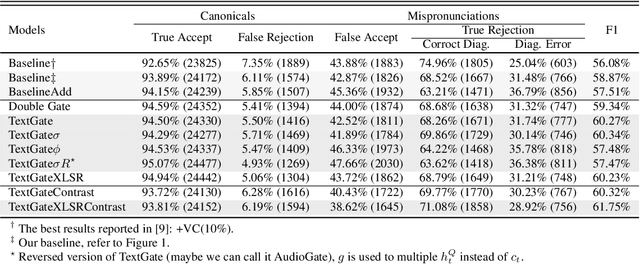
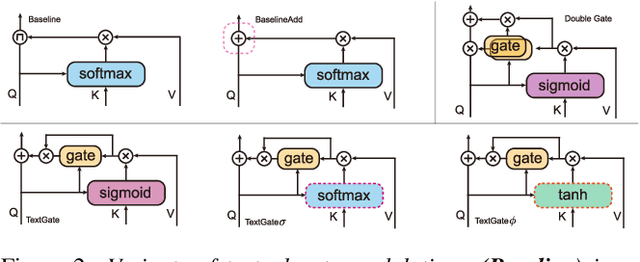
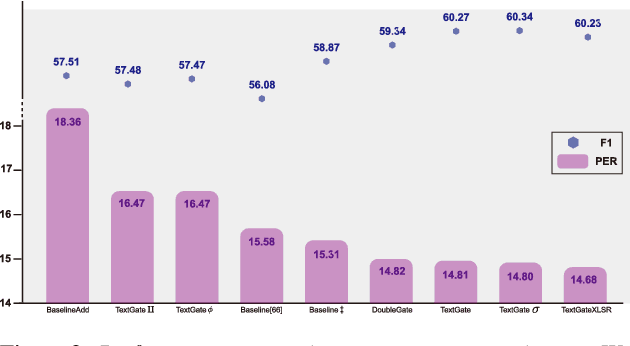
Mispronunciation detection and diagnosis (MDD) technology is a key component of computer-assisted pronunciation training system (CAPT). In the field of assessing the pronunciation quality of constrained speech, the given transcriptions can play the role of a teacher. Conventional methods have fully utilized the prior texts for the model construction or improving the system performance, e.g. forced-alignment and extended recognition networks. Recently, some end-to-end based methods attempt to incorporate the prior texts into model training and preliminarily show the effectiveness. However, previous studies mostly consider applying raw attention mechanism to fuse audio representations with text representations, without taking possible text-pronunciation mismatch into account. In this paper, we present a gating strategy that assigns more importance to the relevant audio features while suppressing irrelevant text information. Moreover, given the transcriptions, we design an extra contrastive loss to reduce the gap between the learning objective of phoneme recognition and MDD. We conducted experiments using two publicly available datasets (TIMIT and L2-Arctic) and our best model improved the F1 score from $57.51\%$ to $61.75\%$ compared to the baselines. Besides, we provide a detailed analysis to shed light on the effectiveness of gating mechanism and contrastive learning on MDD.
An Empirical Study on End-to-End Singing Voice Synthesis with Encoder-Decoder Architectures
Aug 06, 2021
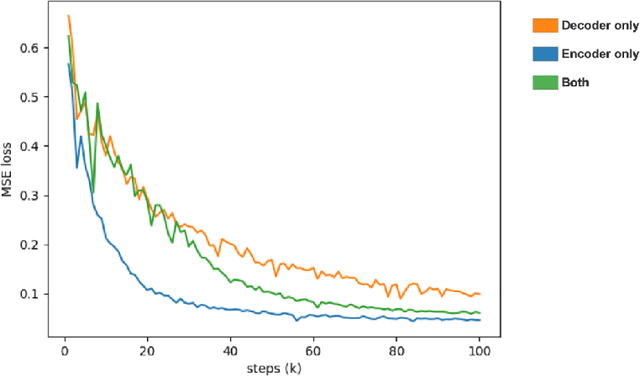
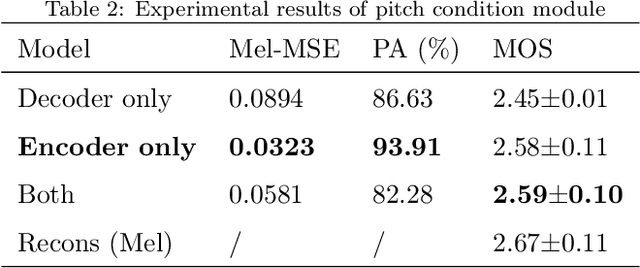
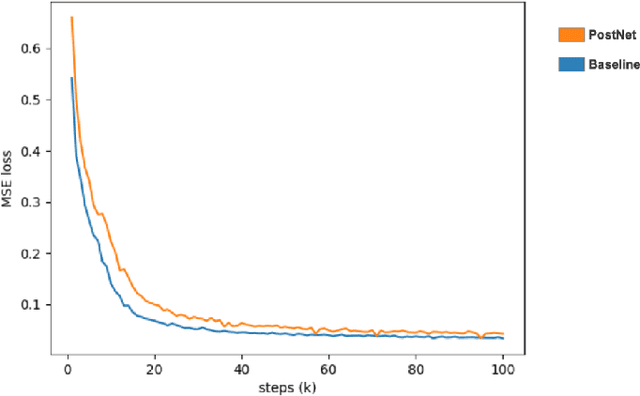
With the rapid development of neural network architectures and speech processing models, singing voice synthesis with neural networks is becoming the cutting-edge technique of digital music production. In this work, in order to explore how to improve the quality and efficiency of singing voice synthesis, in this work, we use encoder-decoder neural models and a number of vocoders to achieve singing voice synthesis. We conduct experiments to demonstrate that the models can be trained using voice data with pitch information, lyrics and beat information, and the trained models can produce smooth, clear and natural singing voice that is close to real human voice. As the models work in the end-to-end manner, they allow users who are not domain experts to directly produce singing voice by arranging pitches, lyrics and beats.
Speech Enhancement using Separable Polling Attention and Global Layer Normalization followed with PReLU
May 06, 2021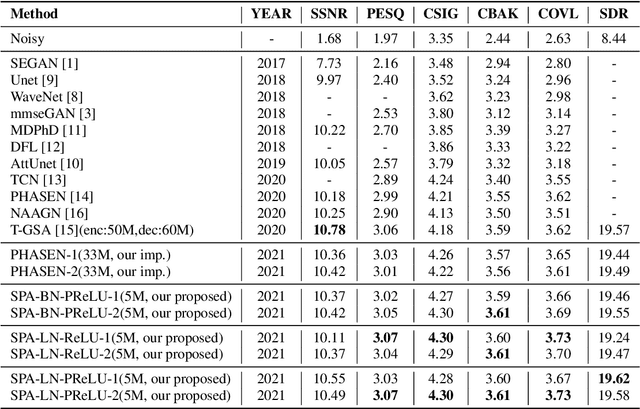
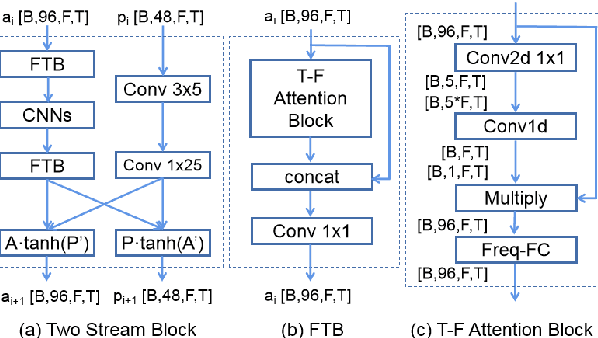
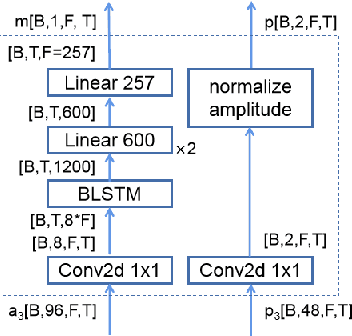

Single channel speech enhancement is a challenging task in speech community. Recently, various neural networks based methods have been applied to speech enhancement. Among these models, PHASEN and T-GSA achieve state-of-the-art performances on the publicly opened VoiceBank+DEMAND corpus. Both of the models reach the COVL score of 3.62. PHASEN achieves the highest CSIG score of 4.21 while T-GSA gets the highest PESQ score of 3.06. However, both of these two models are very large. The contradiction between the model performance and the model size is hard to reconcile. In this paper, we introduce three kinds of techniques to shrink the PHASEN model and improve the performance. Firstly, seperable polling attention is proposed to replace the frequency transformation blocks in PHASEN. Secondly, global layer normalization followed with PReLU is used to replace batch normalization followed with ReLU. Finally, BLSTM in PHASEN is replaced with Conv2d operation and the phase stream is simplified. With all these modifications, the size of the PHASEN model is shrunk from 33M parameters to 5M parameters, while the performance on VoiceBank+DEMAND is improved to the CSIG score of 4.30, the PESQ score of 3.07 and the COVL score of 3.73.
A Full Text-Dependent End to End Mispronunciation Detection and Diagnosis with Easy Data Augmentation Techniques
Apr 17, 2021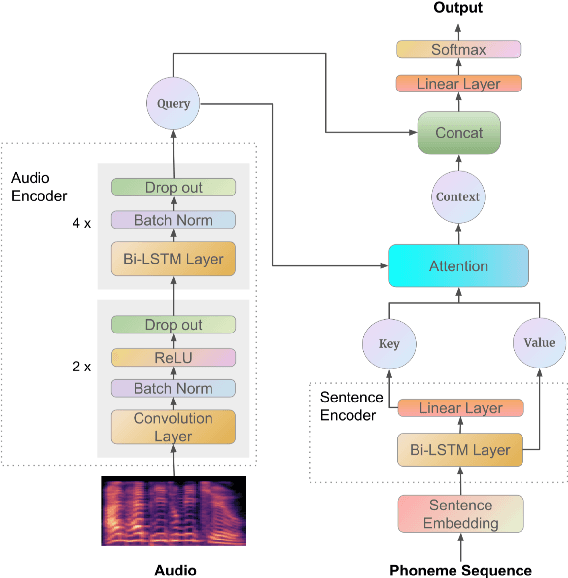
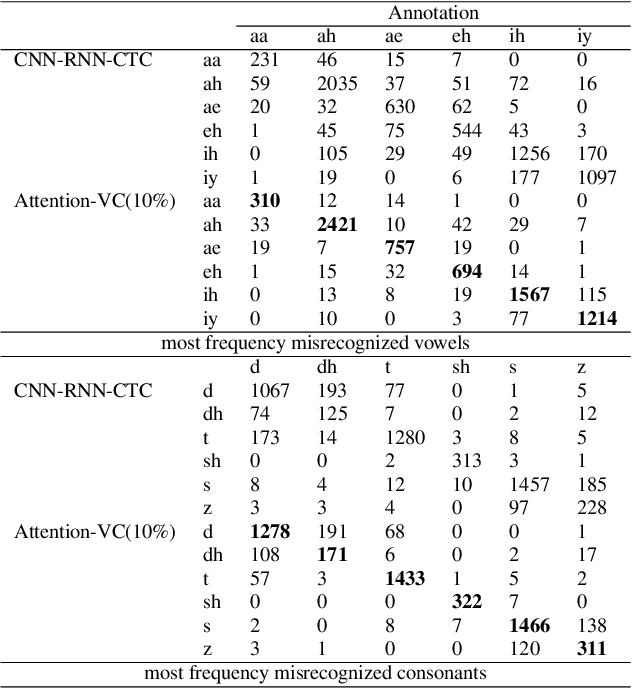
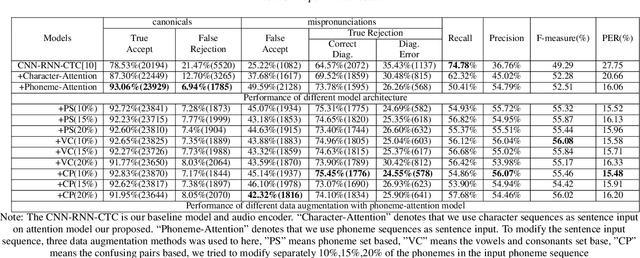
Recently, end-to-end mispronunciation detection and diagnosis (MD&D) systems has become a popular alternative to greatly simplify the model-building process of conventional hybrid DNN-HMM systems by representing complicated modules with a single deep network architecture. In this paper, in order to utilize the prior text in the end-to-end structure, we present a novel text-dependent model which is difference with sed-mdd, the model achieves a fully end-to-end system by aligning the audio with the phoneme sequences of the prior text inside the model through the attention mechanism. Moreover, the prior text as input will be a problem of imbalance between positive and negative samples in the phoneme sequence. To alleviate this problem, we propose three simple data augmentation methods, which effectively improve the ability of model to capture mispronounced phonemes. We conduct experiments on L2-ARCTIC, and our best performance improved from 49.29% to 56.08% in F-measure metric compared to the CNN-RNN-CTC model.
Dynamically Mitigating Data Discrepancy with Balanced Focal Loss for Replay Attack Detection
Jun 25, 2020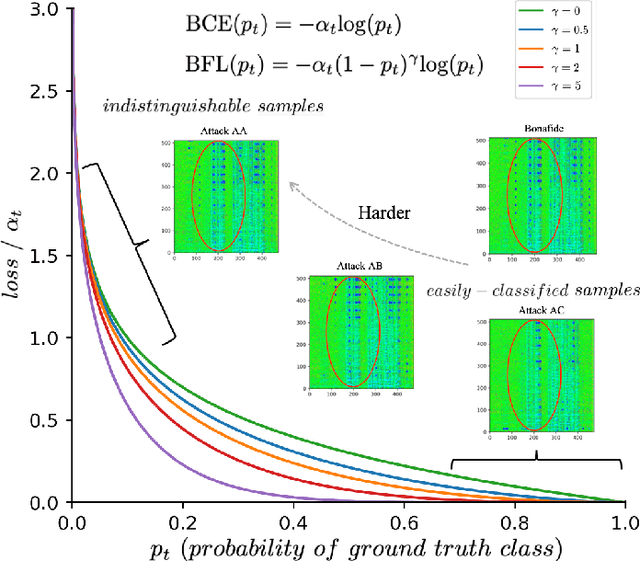
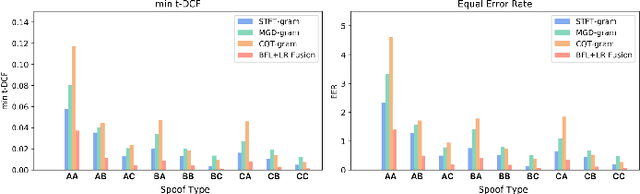
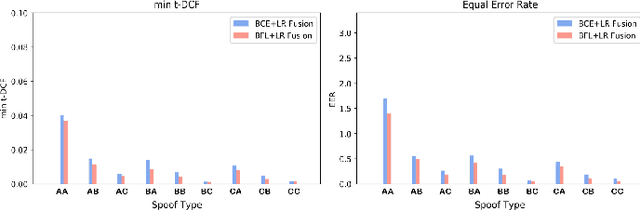
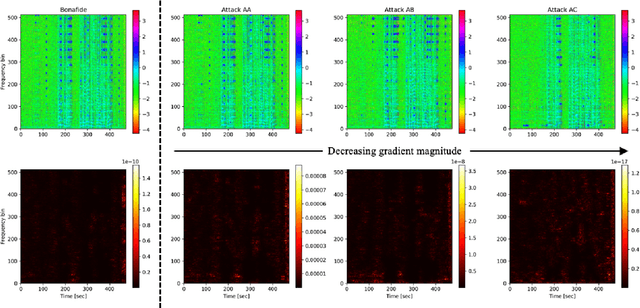
It becomes urgent to design effective anti-spoofing algorithms for vulnerable automatic speaker verification systems due to the advancement of high-quality playback devices. Current studies mainly treat anti-spoofing as a binary classification problem between bonafide and spoofed utterances, while lack of indistinguishable samples makes it difficult to train a robust spoofing detector. In this paper, we argue that for anti-spoofing, it needs more attention for indistinguishable samples over easily-classified ones in the modeling process, to make correct discrimination a top priority. Therefore, to mitigate the data discrepancy between training and inference, we propose to leverage a balanced focal loss function as the training objective to dynamically scale the loss based on the traits of the sample itself. Besides, in the experiments, we select three kinds of features that contain both magnitude-based and phase-based information to form complementary and informative features. Experimental results on the ASVspoof2019 dataset demonstrate the superiority of the proposed methods by comparison between our systems and top-performing ones. Systems trained with the balanced focal loss perform significantly better than conventional cross-entropy loss. With complementary features, our fusion system with only three kinds of features outperforms other systems containing five or more complex single models by 22.5% for min-tDCF and 7% for EER, achieving a min-tDCF and an EER of 0.0124 and 0.55% respectively. Furthermore, we present and discuss the evaluation results on real replay data apart from the simulated ASVspoof2019 data, indicating that research for anti-spoofing still has a long way to go.
Boosting Noise Robustness of Acoustic Model via Deep Adversarial Training
May 02, 2018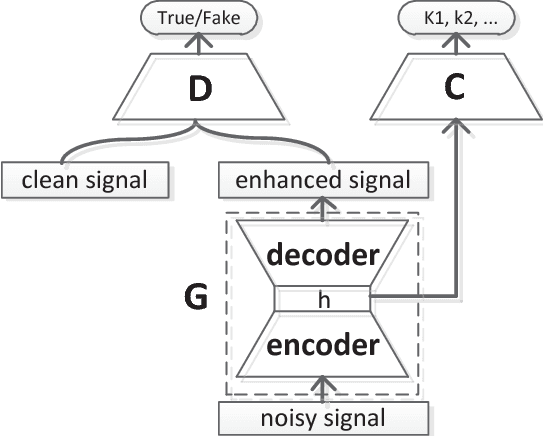


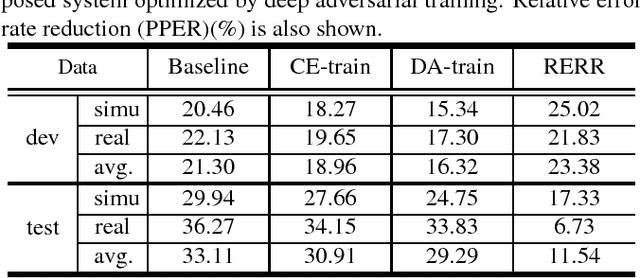
In realistic environments, speech is usually interfered by various noise and reverberation, which dramatically degrades the performance of automatic speech recognition (ASR) systems. To alleviate this issue, the commonest way is to use a well-designed speech enhancement approach as the front-end of ASR. However, more complex pipelines, more computations and even higher hardware costs (microphone array) are additionally consumed for this kind of methods. In addition, speech enhancement would result in speech distortions and mismatches to training. In this paper, we propose an adversarial training method to directly boost noise robustness of acoustic model. Specifically, a jointly compositional scheme of generative adversarial net (GAN) and neural network-based acoustic model (AM) is used in the training phase. GAN is used to generate clean feature representations from noisy features by the guidance of a discriminator that tries to distinguish between the true clean signals and generated signals. The joint optimization of generator, discriminator and AM concentrates the strengths of both GAN and AM for speech recognition. Systematic experiments on CHiME-4 show that the proposed method significantly improves the noise robustness of AM and achieves the average relative error rate reduction of 23.38% and 11.54% on the development and test set, respectively.
Trainable back-propagated functional transfer matrices
Oct 28, 2017
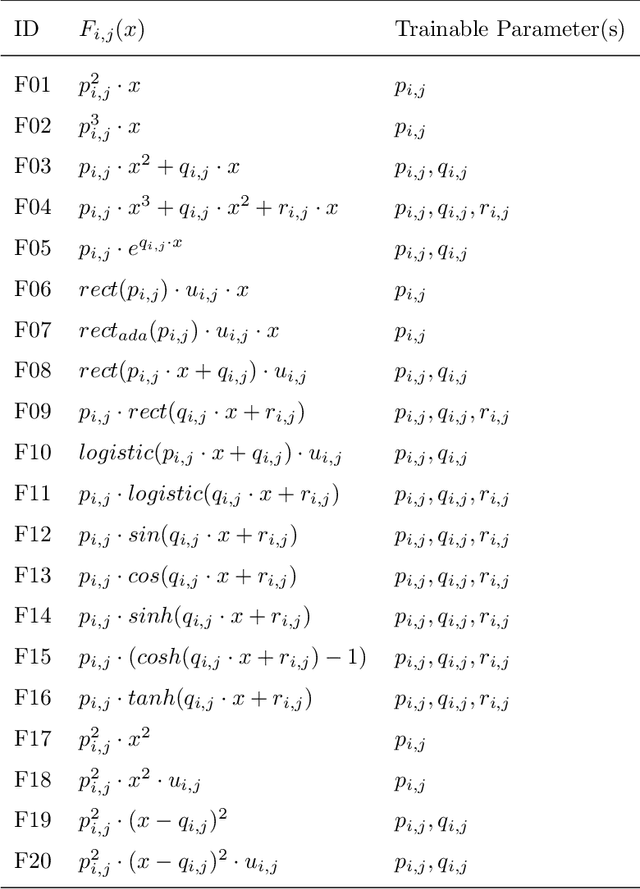
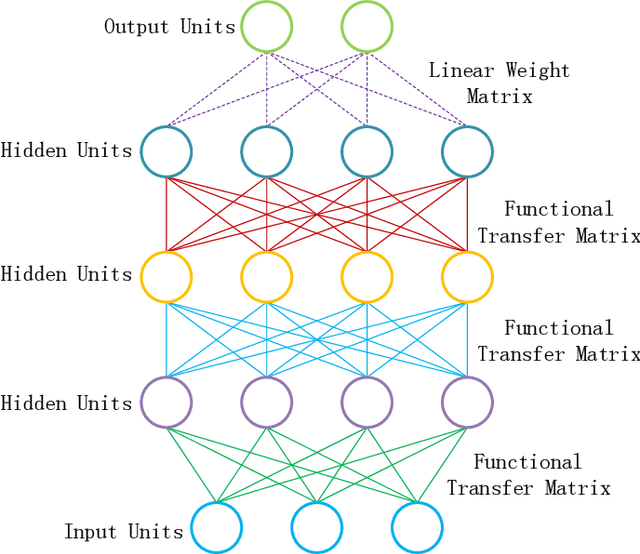

Connections between nodes of fully connected neural networks are usually represented by weight matrices. In this article, functional transfer matrices are introduced as alternatives to the weight matrices: Instead of using real weights, a functional transfer matrix uses real functions with trainable parameters to represent connections between nodes. Multiple functional transfer matrices are then stacked together with bias vectors and activations to form deep functional transfer neural networks. These neural networks can be trained within the framework of back-propagation, based on a revision of the delta rules and the error transmission rule for functional connections. In experiments, it is demonstrated that the revised rules can be used to train a range of functional connections: 20 different functions are applied to neural networks with up to 10 hidden layers, and most of them gain high test accuracies on the MNIST database. It is also demonstrated that a functional transfer matrix with a memory function can roughly memorise a non-cyclical sequence of 400 digits.
* 39 pages, 4 figures, submitted as a journal article
Learning of Human-like Algebraic Reasoning Using Deep Feedforward Neural Networks
Apr 25, 2017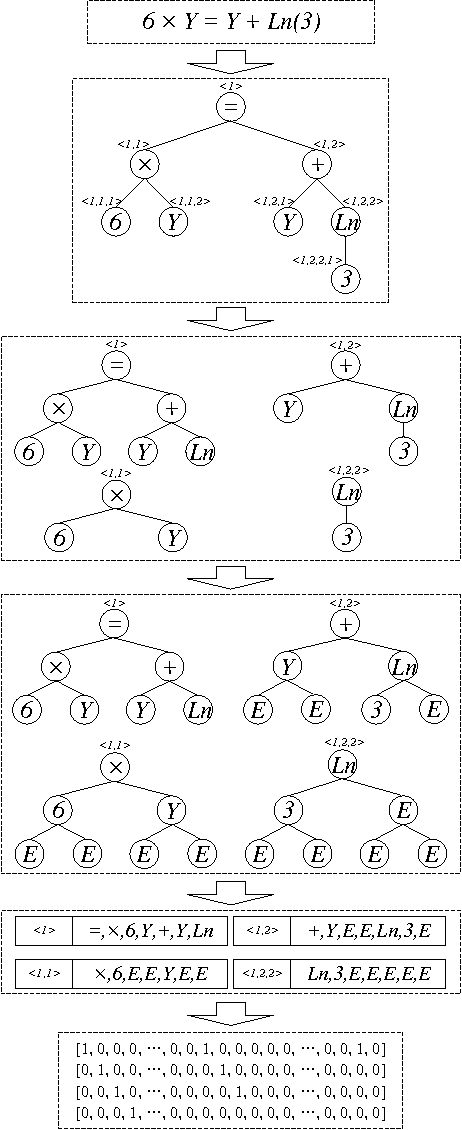
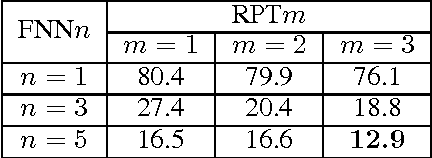
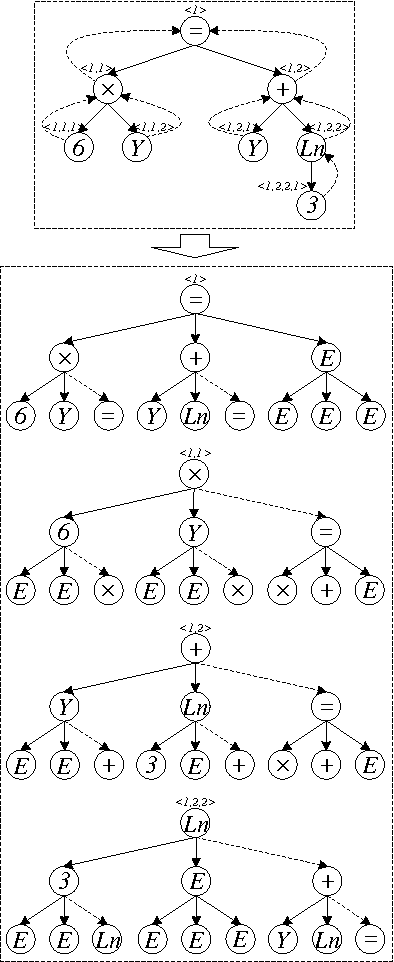
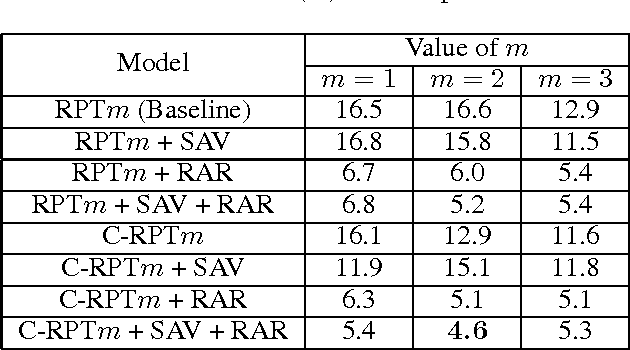
There is a wide gap between symbolic reasoning and deep learning. In this research, we explore the possibility of using deep learning to improve symbolic reasoning. Briefly, in a reasoning system, a deep feedforward neural network is used to guide rewriting processes after learning from algebraic reasoning examples produced by humans. To enable the neural network to recognise patterns of algebraic expressions with non-deterministic sizes, reduced partial trees are used to represent the expressions. Also, to represent both top-down and bottom-up information of the expressions, a centralisation technique is used to improve the reduced partial trees. Besides, symbolic association vectors and rule application records are used to improve the rewriting processes. Experimental results reveal that the algebraic reasoning examples can be accurately learnt only if the feedforward neural network has enough hidden layers. Also, the centralisation technique, the symbolic association vectors and the rule application records can reduce error rates of reasoning. In particular, the above approaches have led to 4.6% error rate of reasoning on a dataset of linear equations, differentials and integrals.