 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRhythm-controllable Attention with High Robustness for Long Sentence Speech Synthesis
Jun 05, 2023



Regressive Text-to-Speech (TTS) system utilizes attention mechanism to generate alignment between text and acoustic feature sequence. Alignment determines synthesis robustness (e.g, the occurence of skipping, repeating, and collapse) and rhythm via duration control. However, current attention algorithms used in speech synthesis cannot control rhythm using external duration information to generate natural speech while ensuring robustness. In this study, we propose Rhythm-controllable Attention (RC-Attention) based on Tracotron2, which improves robustness and naturalness simultaneously. Proposed attention adopts a trainable scalar learned from four kinds of information to achieve rhythm control, which makes rhythm control more robust and natural, even when synthesized sentences are extremely longer than training corpus. We use word errors counting and AB preference test to measure robustness of proposed method and naturalness of synthesized speech, respectively. Results shows that RC-Attention has the lowest word error rate of nearly 0.6%, compared with 11.8% for baseline system. Moreover, nearly 60% subjects prefer to the speech synthesized with RC-Attention to that with Forward Attention, because the former has more natural rhythm.
M2-CTTS: End-to-End Multi-scale Multi-modal Conversational Text-to-Speech Synthesis
May 03, 2023


Conversational text-to-speech (TTS) aims to synthesize speech with proper prosody of reply based on the historical conversation. However, it is still a challenge to comprehensively model the conversation, and a majority of conversational TTS systems only focus on extracting global information and omit local prosody features, which contain important fine-grained information like keywords and emphasis. Moreover, it is insufficient to only consider the textual features, and acoustic features also contain various prosody information. Hence, we propose M2-CTTS, an end-to-end multi-scale multi-modal conversational text-to-speech system, aiming to comprehensively utilize historical conversation and enhance prosodic expression. More specifically, we design a textual context module and an acoustic context module with both coarse-grained and fine-grained modeling. Experimental results demonstrate that our model mixed with fine-grained context information and additionally considering acoustic features achieves better prosody performance and naturalness in CMOS tests.
ECAPA-TDNN for Multi-speaker Text-to-speech Synthesis
Mar 26, 2022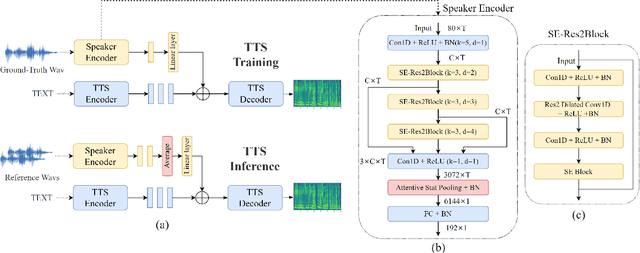
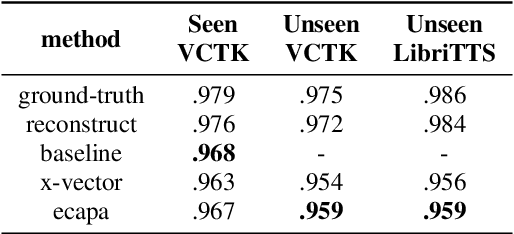
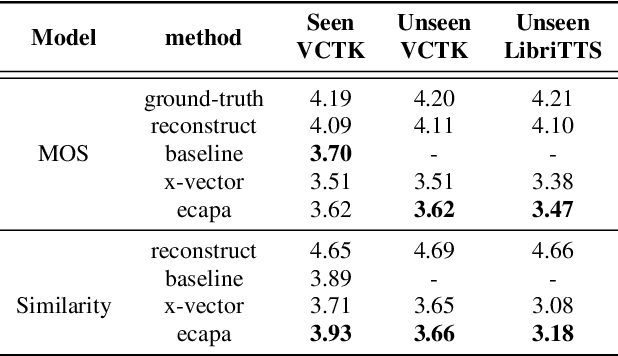
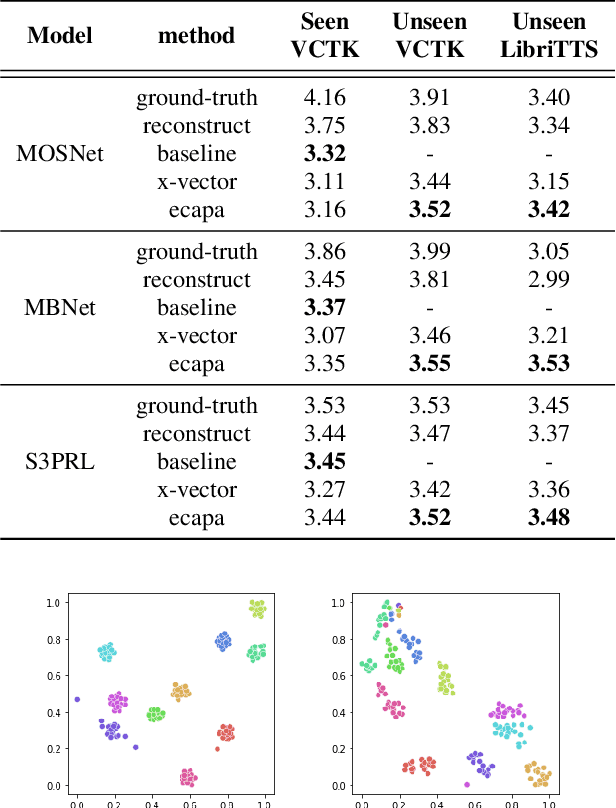
In recent years, neural network based methods for multi-speaker text-to-speech synthesis (TTS) have made significant progress. However, the current speaker encoder models used in these methods still cannot capture enough speaker information. In this paper, we focus on accurate speaker encoder modeling and propose an end-to-end method that can generate high-quality speech and better similarity for both seen and unseen speakers. The proposed architecture consists of three separately trained components: a speaker encoder based on the state-of-the-art ECAPA-TDNN model which is derived from speaker verification task, a FastSpeech2 based synthesizer, and a HiFi-GAN vocoder. The comparison among different speaker encoder models shows our proposed method can achieve better naturalness and similarity. To efficiently evaluate our synthesized speech, we are the first to adopt deep learning based automatic MOS evaluation methods to assess our results, and these methods show great potential in automatic speech quality assessment.