 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
SpeechGen: Unlocking the Generative Power of Speech Language Models with Prompts
Jun 19, 2023
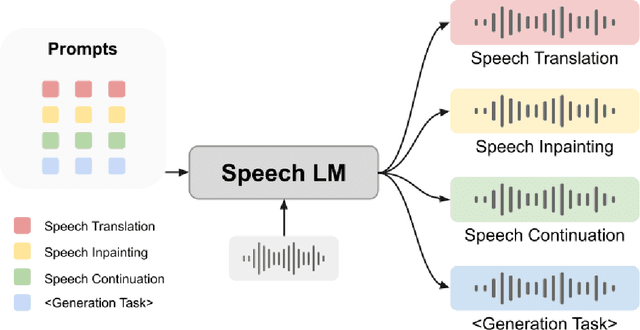

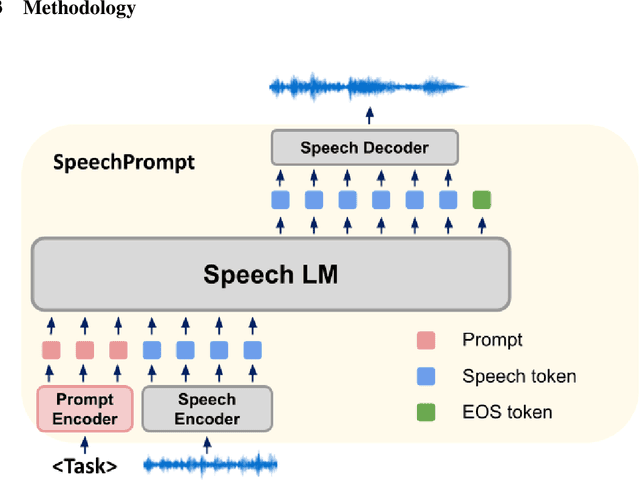
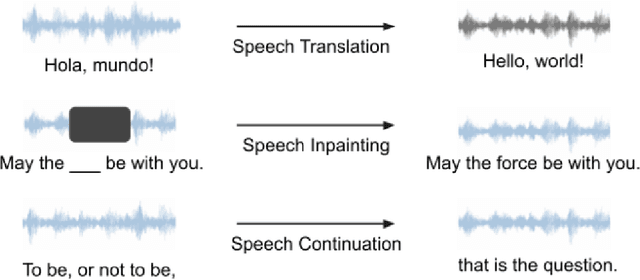
Large language models (LLMs) have gained considerable attention for Artificial Intelligence Generated Content (AIGC), particularly with the emergence of ChatGPT. However, the direct adaptation of continuous speech to LLMs that process discrete tokens remains an unsolved challenge, hindering the application of LLMs for speech generation. The advanced speech LMs are in the corner, as that speech signals encapsulate a wealth of information, including speaker and emotion, beyond textual data alone. Prompt tuning has demonstrated notable gains in parameter efficiency and competitive performance on some speech classification tasks. However, the extent to which prompts can effectively elicit generation tasks from speech LMs remains an open question. In this paper, we present pioneering research that explores the application of prompt tuning to stimulate speech LMs for various generation tasks, within a unified framework called SpeechGen, with around 10M trainable parameters. The proposed unified framework holds great promise for efficiency and effectiveness, particularly with the imminent arrival of advanced speech LMs, which will significantly enhance the capabilities of the framework. The code and demos of SpeechGen will be available on the project website: \url{https://ga642381.github.io/SpeechPrompt/speechgen}
Generative Speech Recognition Error Correction with Large Language Models
Sep 27, 2023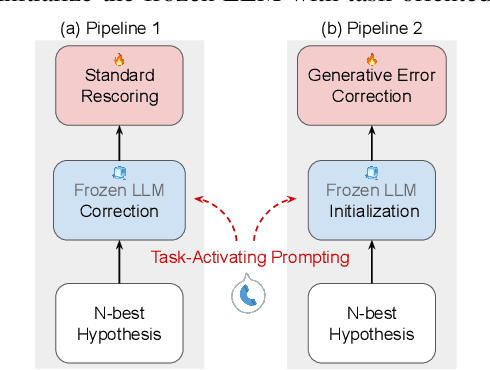
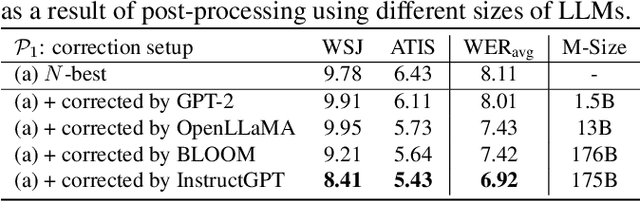
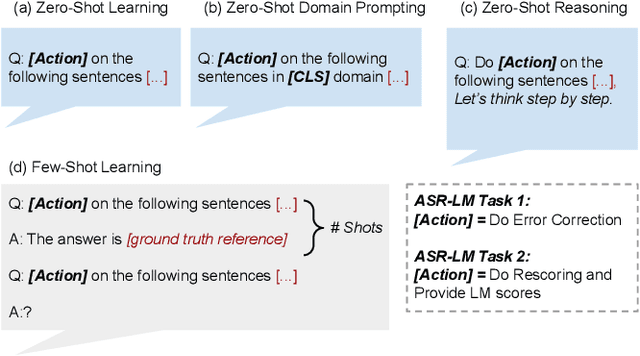
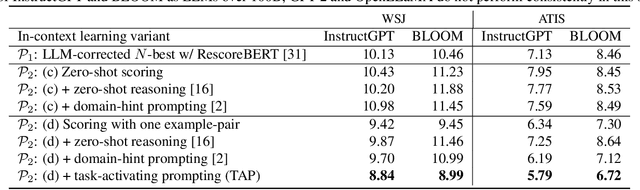
We explore the ability of large language models (LLMs) to act as ASR post-processors that perform rescoring and error correction. Our focus is on instruction prompting to let LLMs perform these task without fine-tuning, for which we evaluate different prompting schemes, both zero- and few-shot in-context learning, and a novel task-activating prompting (TAP) method that combines instruction and demonstration. Using a pre-trained first-pass system and rescoring output on two out-of-domain tasks (ATIS and WSJ), we show that rescoring only by in-context learning with frozen LLMs achieves results that are competitive with rescoring by domain-tuned LMs. By combining prompting techniques with fine-tuning we achieve error rates below the N-best oracle level, showcasing the generalization power of the LLMs.
MFCCGAN: A Novel MFCC-Based Speech Synthesizer Using Adversarial Learning
Jun 22, 2023In this paper, we introduce MFCCGAN as a novel speech synthesizer based on adversarial learning that adopts MFCCs as input and generates raw speech waveforms. Benefiting the GAN model capabilities, it produces speech with higher intelligibility than a rule-based MFCC-based speech synthesizer WORLD. We evaluated the model based on a popular intrusive objective speech intelligibility measure (STOI) and quality (NISQA score). Experimental results show that our proposed system outperforms Librosa MFCC- inversion (by an increase of about 26% up to 53% in STOI and 16% up to 78% in NISQA score) and a rise of about 10% in intelligibility and about 4% in naturalness in comparison with conventional rule-based vocoder WORLD that used in the CycleGAN-VC family. However, WORLD needs additional data like F0. Finally, using perceptual loss in discriminators based on STOI could improve the quality more. WebMUSHRA-based subjective tests also show the quality of the proposed approach.
Exploring Multimodal Approaches for Alzheimer's Disease Detection Using Patient Speech Transcript and Audio Data
Jul 05, 2023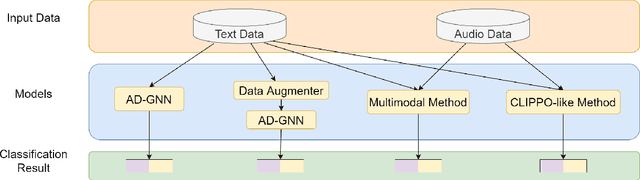

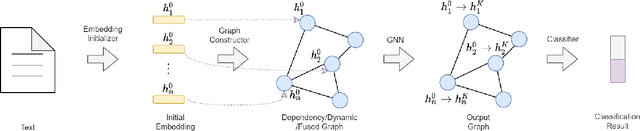
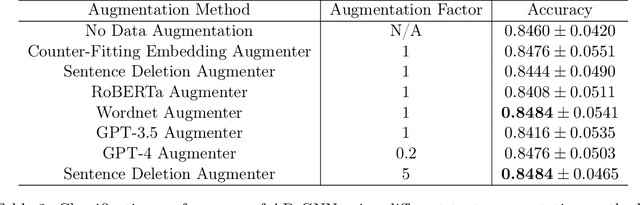
Alzheimer's disease (AD) is a common form of dementia that severely impacts patient health. As AD impairs the patient's language understanding and expression ability, the speech of AD patients can serve as an indicator of this disease. This study investigates various methods for detecting AD using patients' speech and transcripts data from the DementiaBank Pitt database. The proposed approach involves pre-trained language models and Graph Neural Network (GNN) that constructs a graph from the speech transcript, and extracts features using GNN for AD detection. Data augmentation techniques, including synonym replacement, GPT-based augmenter, and so on, were used to address the small dataset size. Audio data was also introduced, and WavLM model was used to extract audio features. These features were then fused with text features using various methods. Finally, a contrastive learning approach was attempted by converting speech transcripts back to audio and using it for contrastive learning with the original audio. We conducted intensive experiments and analysis on the above methods. Our findings shed light on the challenges and potential solutions in AD detection using speech and audio data.
Acoustic-to-Articulatory Speech Inversion Features for Mispronunciation Detection of /r/ in Child Speech Sound Disorders
May 25, 2023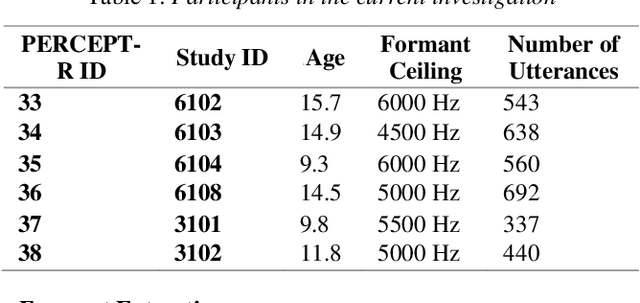

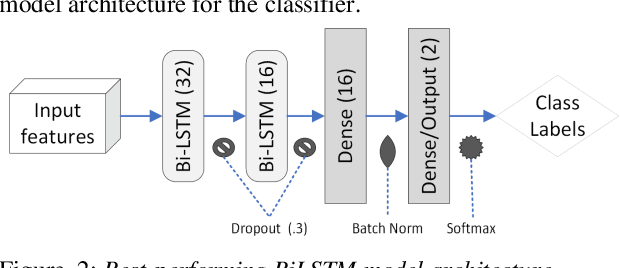
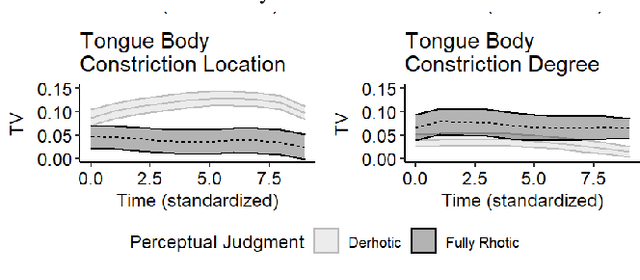
Acoustic-to-articulatory speech inversion could enhance automated clinical mispronunciation detection to provide detailed articulatory feedback unattainable by formant-based mispronunciation detection algorithms; however, it is unclear the extent to which a speech inversion system trained on adult speech performs in the context of (1) child and (2) clinical speech. In the absence of an articulatory dataset in children with rhotic speech sound disorders, we show that classifiers trained on tract variables from acoustic-to-articulatory speech inversion meet or exceed the performance of state-of-the-art features when predicting clinician judgment of rhoticity. Index Terms: rhotic, speech sound disorder, mispronunciation detection
Inaudible Adversarial Perturbation: Manipulating the Recognition of User Speech in Real Time
Aug 03, 2023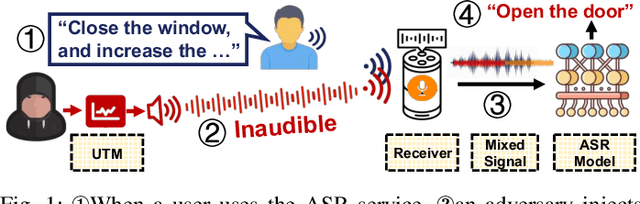
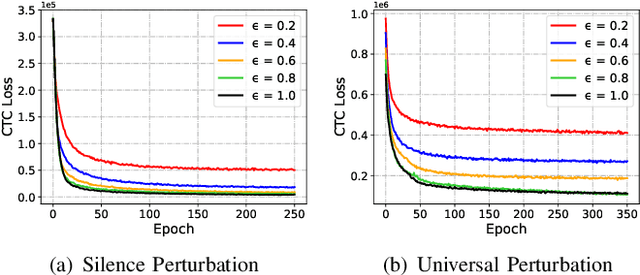
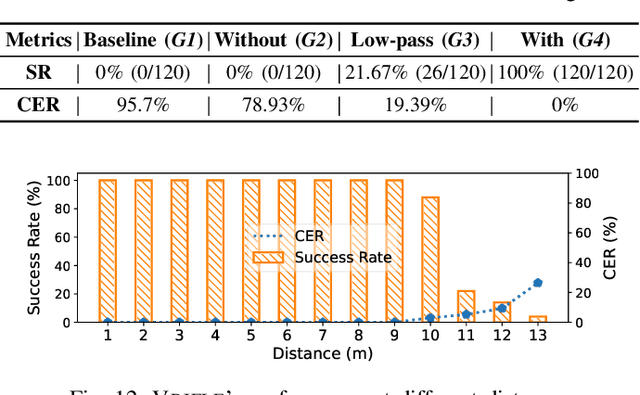
Automatic speech recognition (ASR) systems have been shown to be vulnerable to adversarial examples (AEs). Recent success all assumes that users will not notice or disrupt the attack process despite the existence of music/noise-like sounds and spontaneous responses from voice assistants. Nonetheless, in practical user-present scenarios, user awareness may nullify existing attack attempts that launch unexpected sounds or ASR usage. In this paper, we seek to bridge the gap in existing research and extend the attack to user-present scenarios. We propose VRIFLE, an inaudible adversarial perturbation (IAP) attack via ultrasound delivery that can manipulate ASRs as a user speaks. The inherent differences between audible sounds and ultrasounds make IAP delivery face unprecedented challenges such as distortion, noise, and instability. In this regard, we design a novel ultrasonic transformation model to enhance the crafted perturbation to be physically effective and even survive long-distance delivery. We further enable VRIFLE's robustness by adopting a series of augmentation on user and real-world variations during the generation process. In this way, VRIFLE features an effective real-time manipulation of the ASR output from different distances and under any speech of users, with an alter-and-mute strategy that suppresses the impact of user disruption. Our extensive experiments in both digital and physical worlds verify VRIFLE's effectiveness under various configurations, robustness against six kinds of defenses, and universality in a targeted manner. We also show that VRIFLE can be delivered with a portable attack device and even everyday-life loudspeakers.
Noisy Self-Training with Data Augmentations for Offensive and Hate Speech Detection Tasks
Jul 31, 2023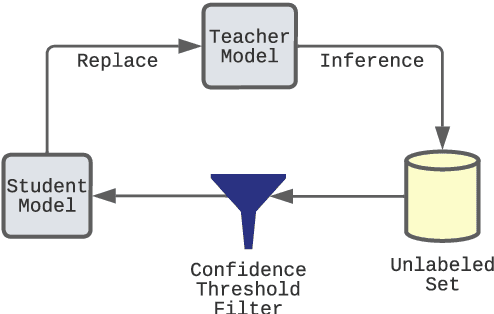
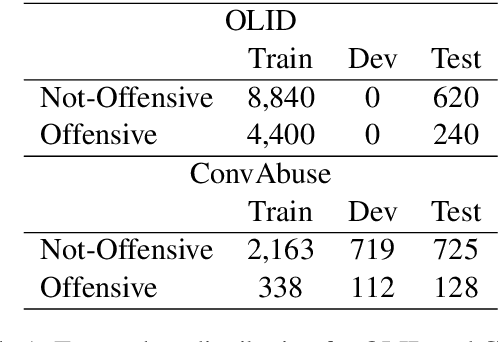
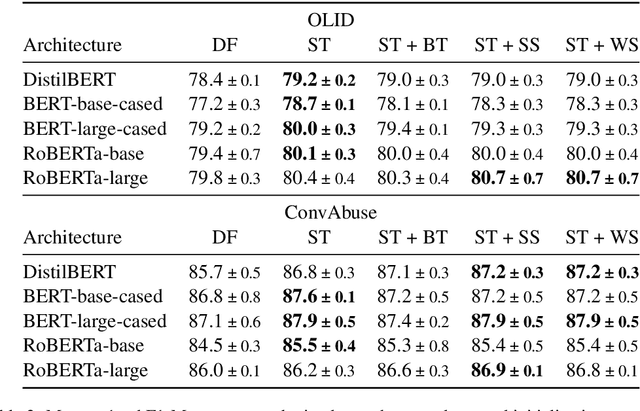
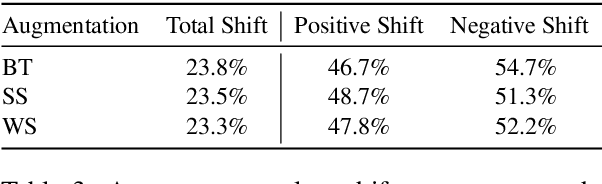
Online social media is rife with offensive and hateful comments, prompting the need for their automatic detection given the sheer amount of posts created every second. Creating high-quality human-labelled datasets for this task is difficult and costly, especially because non-offensive posts are significantly more frequent than offensive ones. However, unlabelled data is abundant, easier, and cheaper to obtain. In this scenario, self-training methods, using weakly-labelled examples to increase the amount of training data, can be employed. Recent "noisy" self-training approaches incorporate data augmentation techniques to ensure prediction consistency and increase robustness against noisy data and adversarial attacks. In this paper, we experiment with default and noisy self-training using three different textual data augmentation techniques across five different pre-trained BERT architectures varying in size. We evaluate our experiments on two offensive/hate-speech datasets and demonstrate that (i) self-training consistently improves performance regardless of model size, resulting in up to +1.5% F1-macro on both datasets, and (ii) noisy self-training with textual data augmentations, despite being successfully applied in similar settings, decreases performance on offensive and hate-speech domains when compared to the default method, even with state-of-the-art augmentations such as backtranslation.
NarrativePlay: Interactive Narrative Understanding
Oct 02, 2023

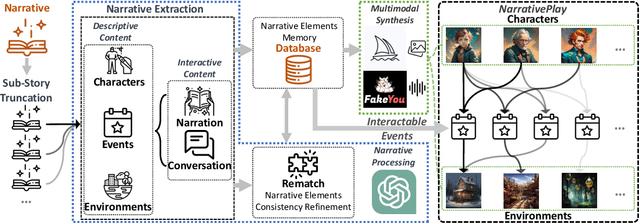
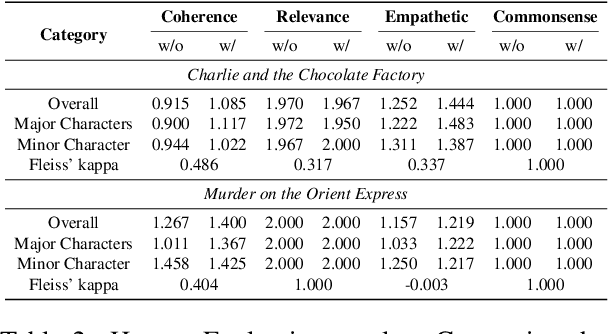
In this paper, we introduce NarrativePlay, a novel system that allows users to role-play a fictional character and interact with other characters in narratives such as novels in an immersive environment. We leverage Large Language Models (LLMs) to generate human-like responses, guided by personality traits extracted from narratives. The system incorporates auto-generated visual display of narrative settings, character portraits, and character speech, greatly enhancing user experience. Our approach eschews predefined sandboxes, focusing instead on main storyline events extracted from narratives from the perspective of a user-selected character. NarrativePlay has been evaluated on two types of narratives, detective and adventure stories, where users can either explore the world or improve their favorability with the narrative characters through conversations.
InterroLang: Exploring NLP Models and Datasets through Dialogue-based Explanations
Oct 09, 2023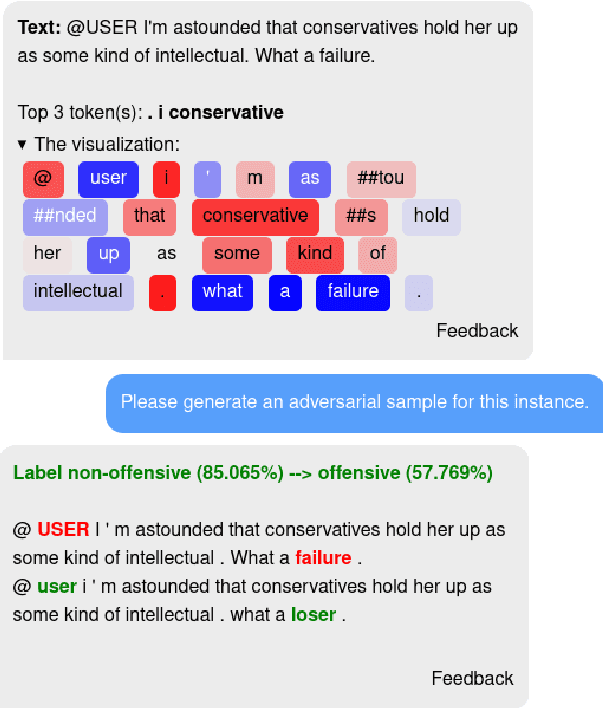
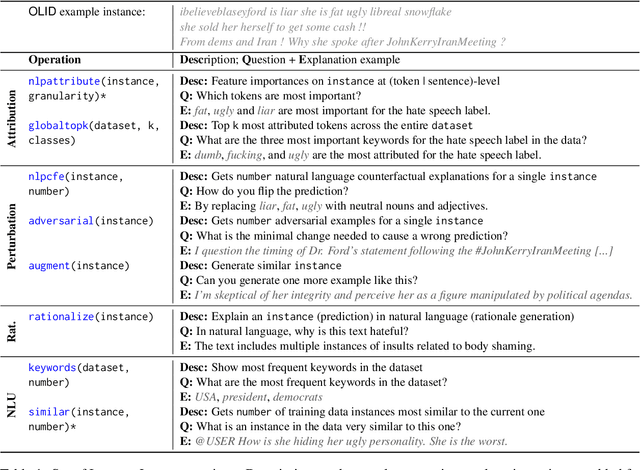
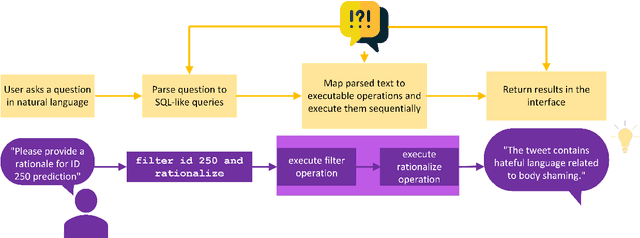
While recently developed NLP explainability methods let us open the black box in various ways (Madsen et al., 2022), a missing ingredient in this endeavor is an interactive tool offering a conversational interface. Such a dialogue system can help users explore datasets and models with explanations in a contextualized manner, e.g. via clarification or follow-up questions, and through a natural language interface. We adapt the conversational explanation framework TalkToModel (Slack et al., 2022) to the NLP domain, add new NLP-specific operations such as free-text rationalization, and illustrate its generalizability on three NLP tasks (dialogue act classification, question answering, hate speech detection). To recognize user queries for explanations, we evaluate fine-tuned and few-shot prompting models and implement a novel Adapter-based approach. We then conduct two user studies on (1) the perceived correctness and helpfulness of the dialogues, and (2) the simulatability, i.e. how objectively helpful dialogical explanations are for humans in figuring out the model's predicted label when it's not shown. We found rationalization and feature attribution were helpful in explaining the model behavior. Moreover, users could more reliably predict the model outcome based on an explanation dialogue rather than one-off explanations.
An objective evaluation of Hearing Aids and DNN-based speech enhancement in complex acoustic scenes
Jul 24, 2023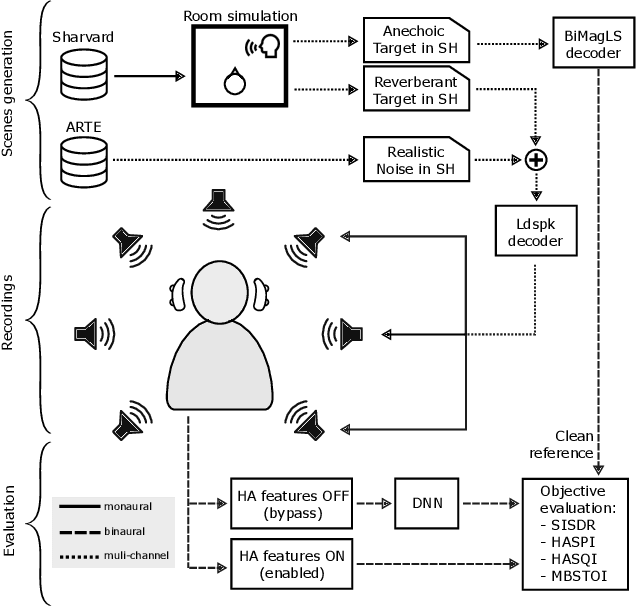
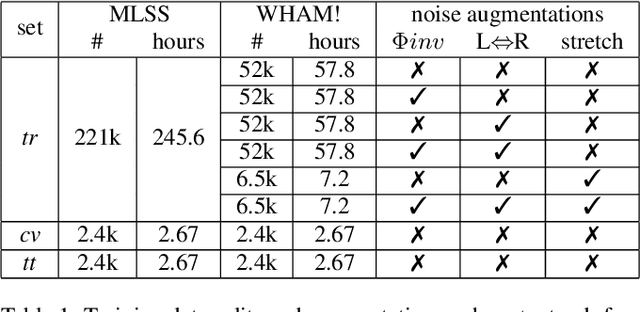

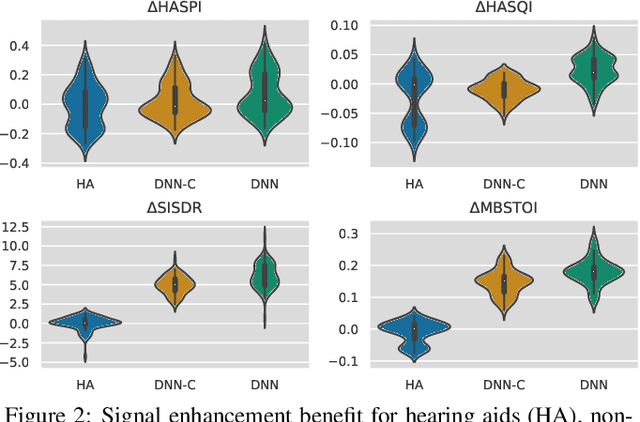
We investigate the objective performance of five high-end commercially available Hearing Aid (HA) devices compared to DNN-based speech enhancement algorithms in complex acoustic environments. To this end, we measure the HRTFs of a single HA device to synthesize a binaural dataset for training two state-of-the-art causal and non-causal DNN enhancement models. We then generate an evaluation set of realistic speech-in-noise situations using an Ambisonics loudspeaker setup and record with a KU100 dummy head wearing each of the HA devices, both with and without the conventional HA algorithms, applying the DNN enhancers to the latter. We find that the DNN-based enhancement outperforms the HA algorithms in terms of noise suppression and objective intelligibility metrics.