 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
KinSPEAK: Improving speech recognition for Kinyarwanda via semi-supervised learning methods
Aug 23, 2023
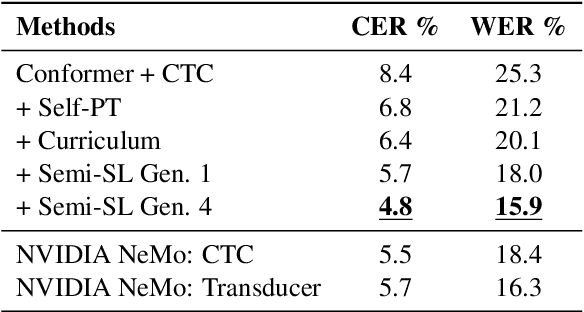
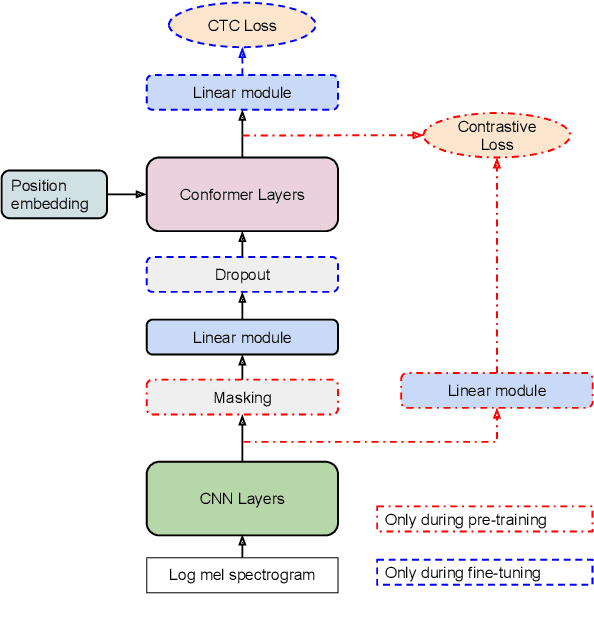

Despite recent availability of large transcribed Kinyarwanda speech data, achieving robust speech recognition for Kinyarwanda is still challenging. In this work, we show that using self-supervised pre-training, following a simple curriculum schedule during fine-tuning and using semi-supervised learning to leverage large unlabelled speech data significantly improve speech recognition performance for Kinyarwanda. Our approach focuses on using public domain data only. A new studio-quality speech dataset is collected from a public website, then used to train a clean baseline model. The clean baseline model is then used to rank examples from a more diverse and noisy public dataset, defining a simple curriculum training schedule. Finally, we apply semi-supervised learning to label and learn from large unlabelled data in four successive generations. Our final model achieves 3.2% word error rate (WER) on the new dataset and 15.9% WER on Mozilla Common Voice benchmark, which is state-of-the-art to the best of our knowledge. Our experiments also indicate that using syllabic rather than character-based tokenization results in better speech recognition performance for Kinyarwanda.
Generative Speech Recognition Error Correction with Large Language Models and Task-Activating Prompting
Oct 10, 2023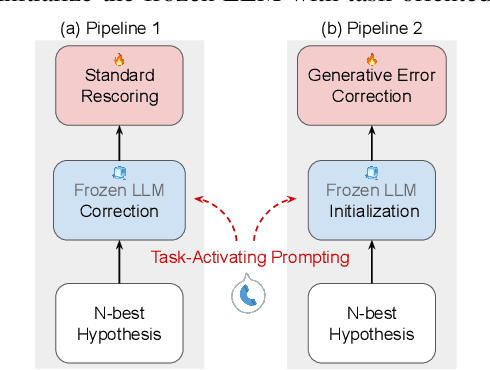
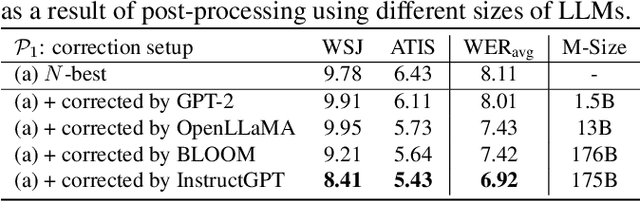
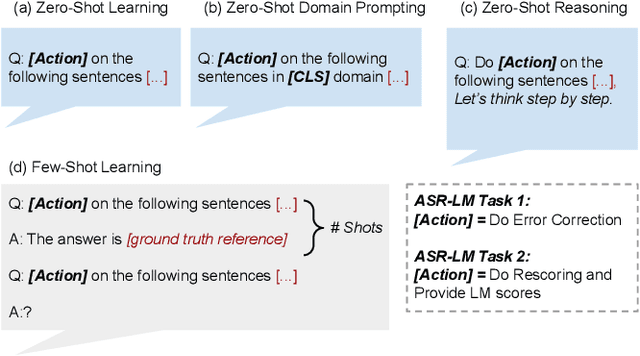
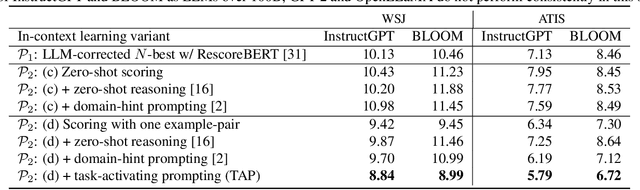
We explore the ability of large language models (LLMs) to act as speech recognition post-processors that perform rescoring and error correction. Our first focus is on instruction prompting to let LLMs perform these task without fine-tuning, for which we evaluate different prompting schemes, both zero- and few-shot in-context learning, and a novel task activation prompting method that combines causal instructions and demonstration to increase its context windows. Next, we show that rescoring only by in-context learning with frozen LLMs achieves results that are competitive with rescoring by domain-tuned LMs, using a pretrained first-pass recognition system and rescoring output on two out-of-domain tasks (ATIS and WSJ). By combining prompting techniques with fine-tuning we achieve error rates below the N-best oracle level, showcasing the generalization power of the LLMs.
Unimodal Aggregation for CTC-based Speech Recognition
Sep 15, 2023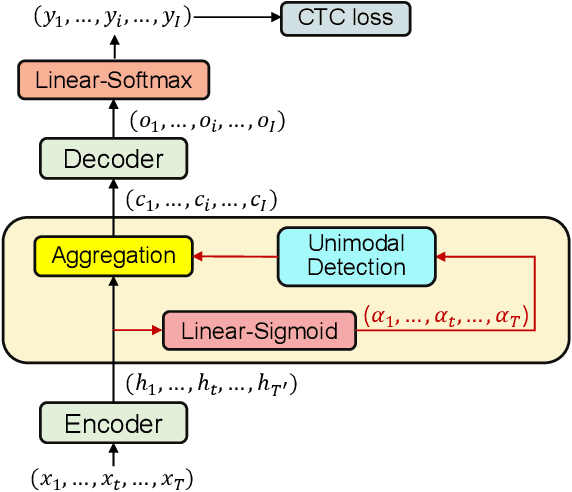
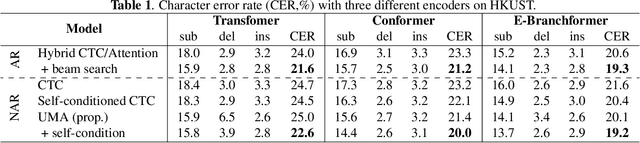
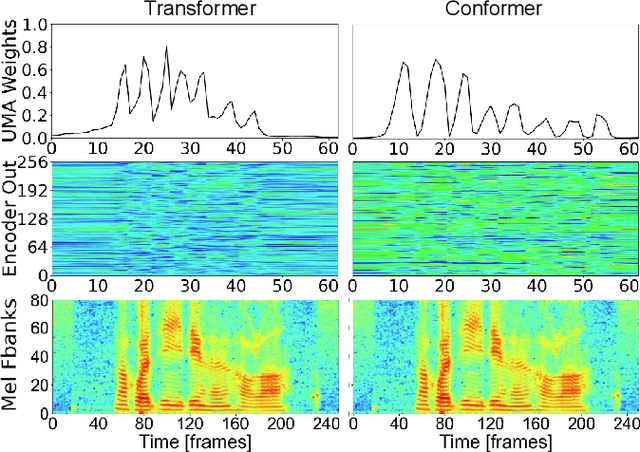
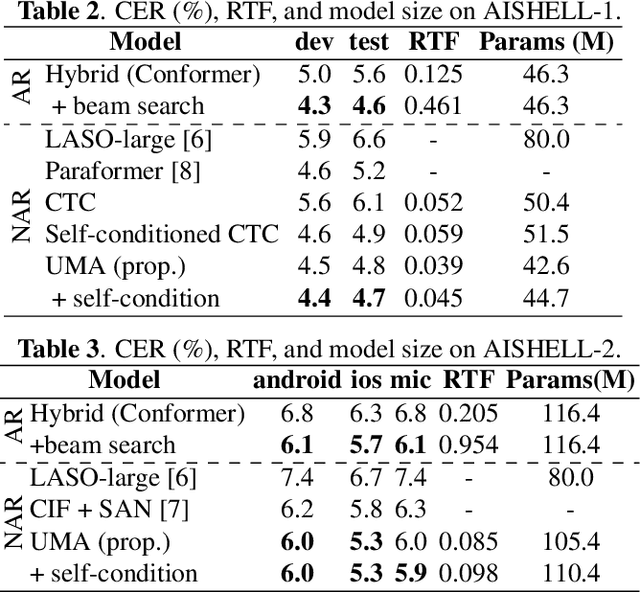
This paper works on non-autoregressive automatic speech recognition. A unimodal aggregation (UMA) is proposed to segment and integrate the feature frames that belong to the same text token, and thus to learn better feature representations for text tokens. The frame-wise features and weights are both derived from an encoder. Then, the feature frames with unimodal weights are integrated and further processed by a decoder. Connectionist temporal classification (CTC) loss is applied for training. Compared to the regular CTC, the proposed method learns better feature representations and shortens the sequence length, resulting in lower recognition error and computational complexity. Experiments on three Mandarin datasets show that UMA demonstrates superior or comparable performance to other advanced non-autoregressive methods, such as self-conditioned CTC. Moreover, by integrating self-conditioned CTC into the proposed framework, the performance can be further noticeably improved.
Extending Whisper with prompt tuning to target-speaker ASR
Dec 13, 2023Target-speaker automatic speech recognition (ASR) aims to transcribe the desired speech of a target speaker from multi-talker overlapped utterances. Most of the existing target-speaker ASR (TS-ASR) methods involve either training from scratch or fully fine-tuning a pre-trained model, leading to significant training costs and becoming inapplicable to large foundation models. This work leverages prompt tuning, a parameter-efficient fine-tuning approach, to extend Whisper, a large-scale single-talker ASR model, to TS-ASR. Experimental results show that prompt tuning can achieve performance comparable to state-of-the-art full fine-tuning approaches while only requiring about 1% of task-specific model parameters. Notably, the original Whisper's features, such as inverse text normalization and timestamp prediction, are retained in target-speaker ASR, keeping the generated transcriptions natural and informative.
Improved Long-Form Speech Recognition by Jointly Modeling the Primary and Non-primary Speakers
Dec 18, 2023ASR models often suffer from a long-form deletion problem where the model predicts sequential blanks instead of words when transcribing a lengthy audio (in the order of minutes or hours). From the perspective of a user or downstream system consuming the ASR results, this behavior can be perceived as the model "being stuck", and potentially make the product hard to use. One of the culprits for long-form deletion is training-test data mismatch, which can happen even when the model is trained on diverse and large-scale data collected from multiple application domains. In this work, we introduce a novel technique to simultaneously model different groups of speakers in the audio along with the standard transcript tokens. Speakers are grouped as primary and non-primary, which connects the application domains and significantly alleviates the long-form deletion problem. This improved model neither needs any additional training data nor incurs additional training or inference cost.
Generative linguistic representation for spoken language identification
Dec 18, 2023Effective extraction and application of linguistic features are central to the enhancement of spoken Language IDentification (LID) performance. With the success of recent large models, such as GPT and Whisper, the potential to leverage such pre-trained models for extracting linguistic features for LID tasks has become a promising area of research. In this paper, we explore the utilization of the decoder-based network from the Whisper model to extract linguistic features through its generative mechanism for improving the classification accuracy in LID tasks. We devised two strategies - one based on the language embedding method and the other focusing on direct optimization of LID outputs while simultaneously enhancing the speech recognition tasks. We conducted experiments on the large-scale multilingual datasets MLS, VoxLingua107, and CommonVoice to test our approach. The experimental results demonstrated the effectiveness of the proposed method on both in-domain and out-of-domain datasets for LID tasks.
Exploring Speech Recognition, Translation, and Understanding with Discrete Speech Units: A Comparative Study
Sep 27, 2023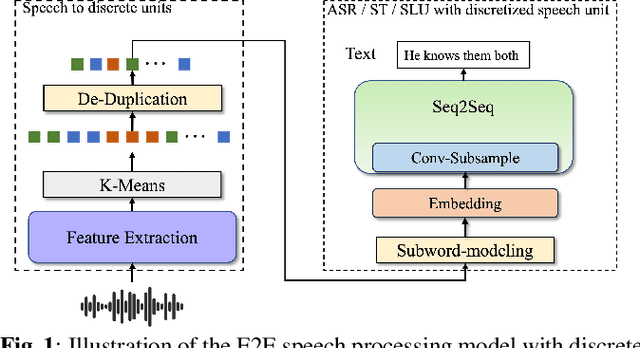
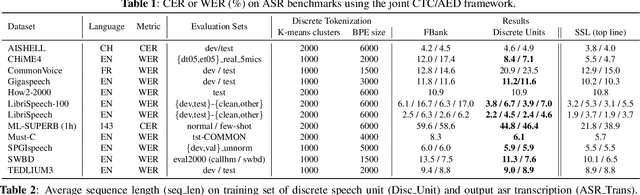
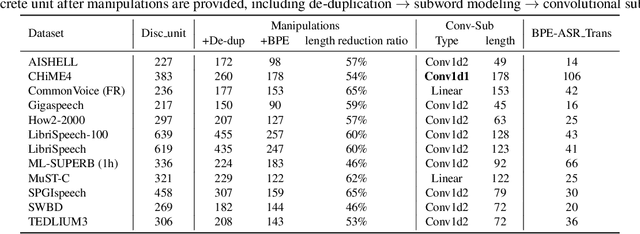
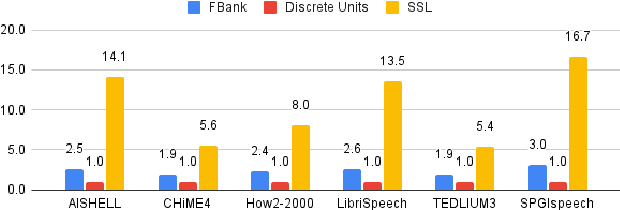
Speech signals, typically sampled at rates in the tens of thousands per second, contain redundancies, evoking inefficiencies in sequence modeling. High-dimensional speech features such as spectrograms are often used as the input for the subsequent model. However, they can still be redundant. Recent investigations proposed the use of discrete speech units derived from self-supervised learning representations, which significantly compresses the size of speech data. Applying various methods, such as de-duplication and subword modeling, can further compress the speech sequence length. Hence, training time is significantly reduced while retaining notable performance. In this study, we undertake a comprehensive and systematic exploration into the application of discrete units within end-to-end speech processing models. Experiments on 12 automatic speech recognition, 3 speech translation, and 1 spoken language understanding corpora demonstrate that discrete units achieve reasonably good results in almost all the settings. We intend to release our configurations and trained models to foster future research efforts.
Towards Probing Contact Center Large Language Models
Dec 26, 2023Fine-tuning large language models (LLMs) with domain-specific instructions has emerged as an effective method to enhance their domain-specific understanding. Yet, there is limited work that examines the core characteristics acquired during this process. In this study, we benchmark the fundamental characteristics learned by contact-center (CC) specific instruction fine-tuned LLMs with out-of-the-box (OOB) LLMs via probing tasks encompassing conversational, channel, and automatic speech recognition (ASR) properties. We explore different LLM architectures (Flan-T5 and Llama), sizes (3B, 7B, 11B, 13B), and fine-tuning paradigms (full fine-tuning vs PEFT). Our findings reveal remarkable effectiveness of CC-LLMs on the in-domain downstream tasks, with improvement in response acceptability by over 48% compared to OOB-LLMs. Additionally, we compare the performance of OOB-LLMs and CC-LLMs on the widely used SentEval dataset, and assess their capabilities in terms of surface, syntactic, and semantic information through probing tasks. Intriguingly, we note a relatively consistent performance of probing classifiers on the set of probing tasks. Our observations indicate that CC-LLMs, while outperforming their out-of-the-box counterparts, exhibit a tendency to rely less on encoding surface, syntactic, and semantic properties, highlighting the intricate interplay between domain-specific adaptation and probing task performance opening up opportunities to explore behavior of fine-tuned language models in specialized contexts.
Generative error correction for code-switching speech recognition using large language models
Oct 17, 2023
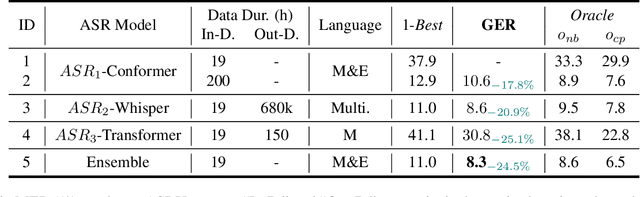
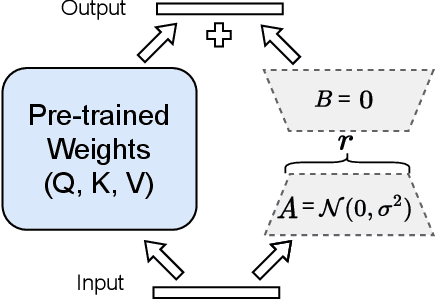
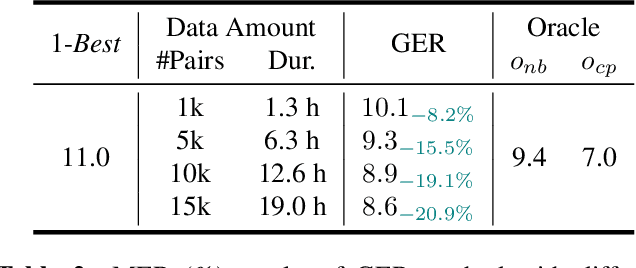
Code-switching (CS) speech refers to the phenomenon of mixing two or more languages within the same sentence. Despite the recent advances in automatic speech recognition (ASR), CS-ASR is still a challenging task ought to the grammatical structure complexity of the phenomenon and the data scarcity of specific training corpus. In this work, we propose to leverage large language models (LLMs) and lists of hypotheses generated by an ASR to address the CS problem. Specifically, we first employ multiple well-trained ASR models for N-best hypotheses generation, with the aim of increasing the diverse and informative elements in the set of hypotheses. Next, we utilize the LLMs to learn the hypotheses-to-transcription (H2T) mapping by adding a trainable low-rank adapter. Such a generative error correction (GER) method directly predicts the accurate transcription according to its expert linguistic knowledge and N-best hypotheses, resulting in a paradigm shift from the traditional language model rescoring or error correction techniques. Experimental evidence demonstrates that GER significantly enhances CS-ASR accuracy, in terms of reduced mixed error rate (MER). Furthermore, LLMs show remarkable data efficiency for H2T learning, providing a potential solution to the data scarcity problem of CS-ASR in low-resource languages.
Kid-Whisper: Towards Bridging the Performance Gap in Automatic Speech Recognition for Children VS. Adults
Sep 18, 2023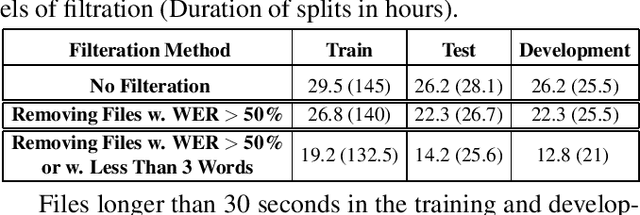
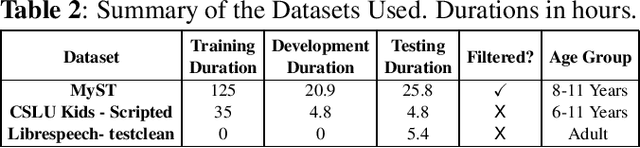
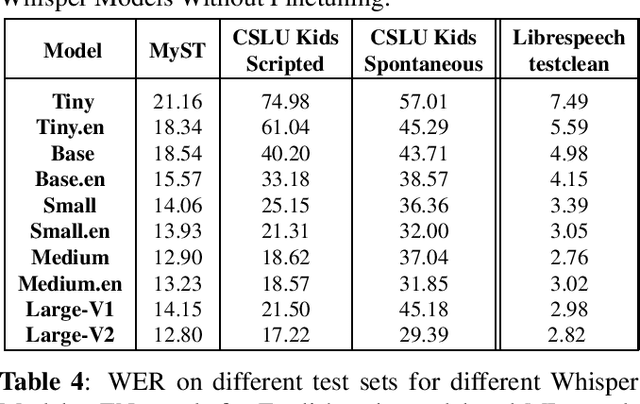
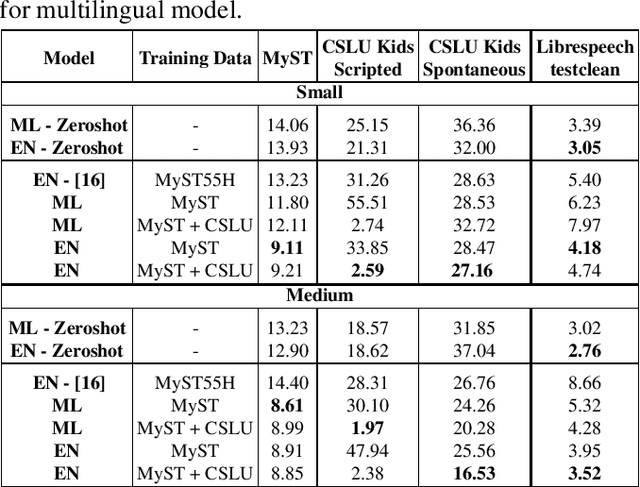
Recent advancements in Automatic Speech Recognition (ASR) systems, exemplified by Whisper, have demonstrated the potential of these systems to approach human-level performance given sufficient data. However, this progress doesn't readily extend to ASR for children due to the limited availability of suitable child-specific databases and the distinct characteristics of children's speech. A recent study investigated leveraging the My Science Tutor (MyST) children's speech corpus to enhance Whisper's performance in recognizing children's speech. They were able to demonstrate some improvement on a limited testset. This paper builds on these findings by enhancing the utility of the MyST dataset through more efficient data preprocessing. We reduce the Word Error Rate (WER) on the MyST testset 13.93% to 9.11% with Whisper-Small and from 13.23% to 8.61% with Whisper-Medium and show that this improvement can be generalized to unseen datasets. We also highlight important challenges towards improving children's ASR performance. The results showcase the viable and efficient integration of Whisper for effective children's speech recognition.