 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Compressing 1D Time-Channel Separable Convolutions using Sparse Random Ternary Matrices
Apr 01, 2021
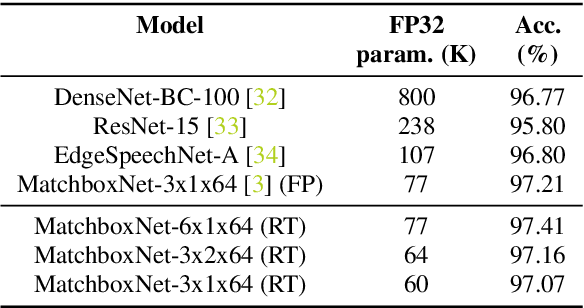
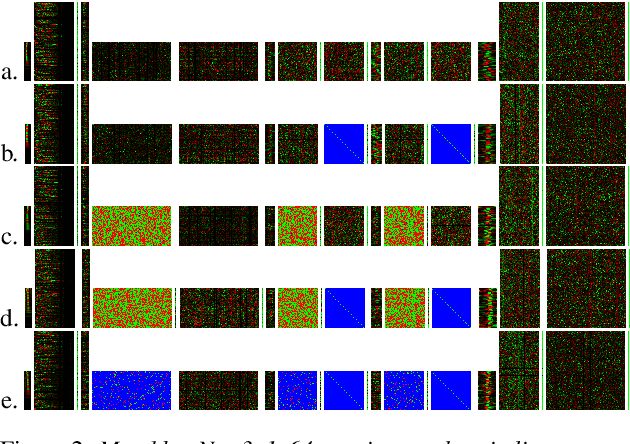

We demonstrate that 1x1-convolutions in 1D time-channel separable convolutions may be replaced by constant, sparse random ternary matrices with weights in $\{-1,0,+1\}$. Such layers do not perform any multiplications and do not require training. Moreover, the matrices may be generated on the chip during computation and therefore do not require any memory access. With the same parameter budget, we can afford deeper and more expressive models, improving the Pareto frontiers of existing models on several tasks. For command recognition on Google Speech Commands v1, we improve the state-of-the-art accuracy from $97.21\%$ to $97.41\%$ at the same network size. Alternatively, we can lower the cost of existing models. For speech recognition on Librispeech, we half the number of weights to be trained while only sacrificing about $1\%$ of the floating-point baseline's word error rate.
Knowledge Distillation for Neural Transducers from Large Self-Supervised Pre-trained Models
Oct 07, 2021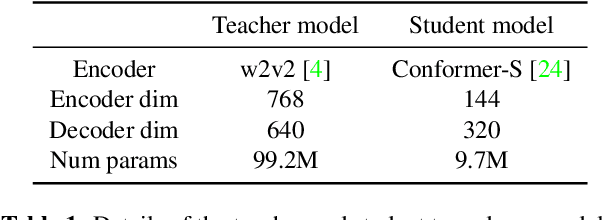
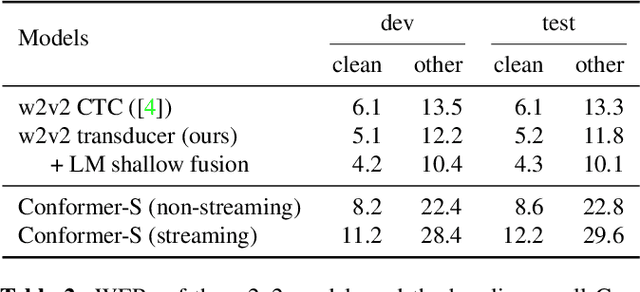
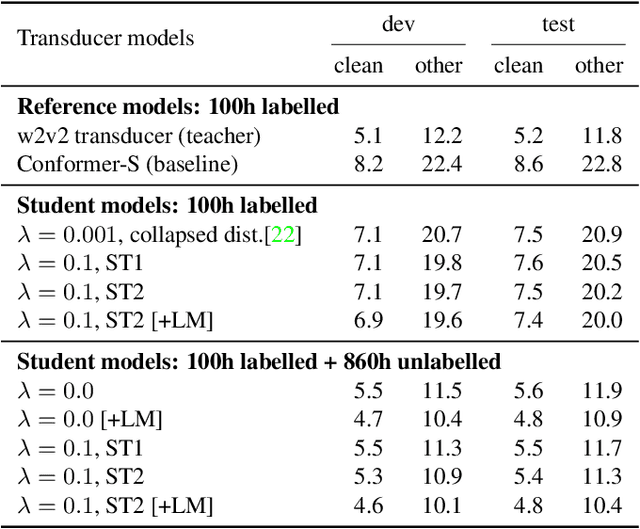
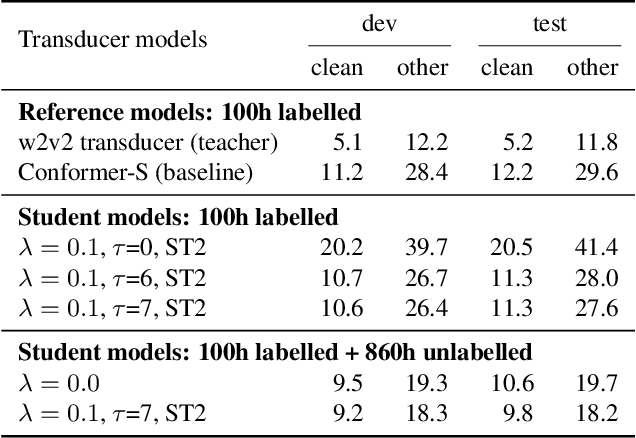
Self-supervised pre-training is an effective approach to leveraging a large amount of unlabelled data to boost the performance of automatic speech recognition (ASR) systems. However, it is impractical to serve large pre-trained models for real-world ASR applications. Therefore, it is desirable to have a much smaller model while retaining the performance of the pre-trained model. In this paper, we propose a simple knowledge distillation (KD) loss function for neural transducers that focuses on the one-best path in the output probability lattice under both the streaming and non-streaming setups, which allows the small student model to approach the performance of the large pre-trained teacher model. Experiments on the LibriSpeech dataset show that despite being more than 10 times smaller than the teacher model, the proposed loss results in relative word error rate reductions (WERRs) of 11.4% and 6.8% on test-other set for non-streaming and streaming student models compared to the baseline transducers trained without KD using the labelled 100-hour clean data. With additional 860-hour unlabelled data for KD, the WERRs increase to 50.4% and 38.5% for non-streaming and streaming students. If language model shallow fusion is used for producing distillation targets, further improvement on the student model is observed.
End-to-End Spoken Language Understanding using RNN-Transducer ASR
Jul 08, 2021
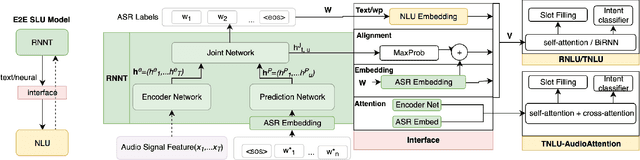
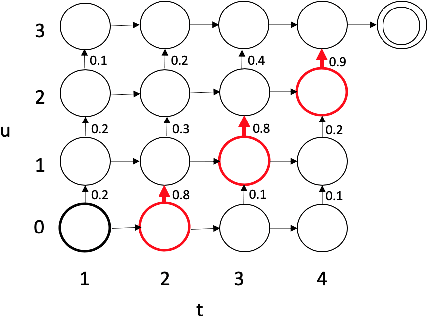

We propose an end-to-end trained spoken language understanding (SLU) system that extracts transcripts, intents and slots from an input speech utterance. It consists of a streaming recurrent neural network transducer (RNNT) based automatic speech recognition (ASR) model connected to a neural natural language understanding (NLU) model through a neural interface. This interface allows for end-to-end training using multi-task RNNT and NLU losses. Additionally, we introduce semantic sequence loss training for the joint RNNT-NLU system that allows direct optimization of non-differentiable SLU metrics. This end-to-end SLU model paradigm can leverage state-of-the-art advancements and pretrained models in both ASR and NLU research communities, outperforming recently proposed direct speech-to-semantics models, and conventional pipelined ASR and NLU systems. We show that this method improves both ASR and NLU metrics on both public SLU datasets and large proprietary datasets.
SpeechFormer: A Hierarchical Efficient Framework Incorporating the Characteristics of Speech
Mar 10, 2022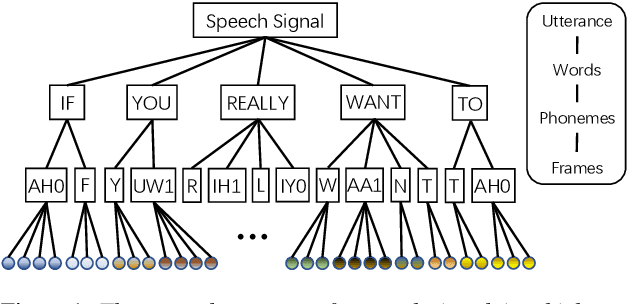

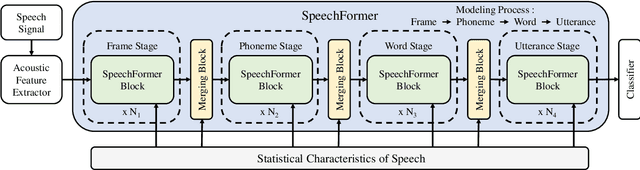
Transformer has obtained promising results on cognitive speech signal processing field, which is of interest in various applications ranging from emotion to neurocognitive disorder analysis. However, most works treat speech signal as a whole, leading to the neglect of the pronunciation structure that is unique to speech and reflects the cognitive process. Meanwhile, Transformer has heavy computational burden due to its full attention operation. In this paper, a hierarchical efficient framework, called SpeechFormer, which considers the structural characteristics of speech, is proposed and can be served as a general-purpose backbone for cognitive speech signal processing. The proposed SpeechFormer consists of frame, phoneme, word and utterance stages in succession, each performing a neighboring attention according to the structural pattern of speech with high computational efficiency. SpeechFormer is evaluated on speech emotion recognition (IEMOCAP & MELD) and neurocognitive disorder detection (Pitt & DAIC-WOZ) tasks, and the results show that SpeechFormer outperforms the standard Transformer-based framework while greatly reducing the computational cost. Furthermore, our SpeechFormer achieves comparable results to the state-of-the-art approaches.
Bridging the Gap between Spatial and Spectral Domains: A Theoretical Framework for Graph Neural Networks
Jul 21, 2021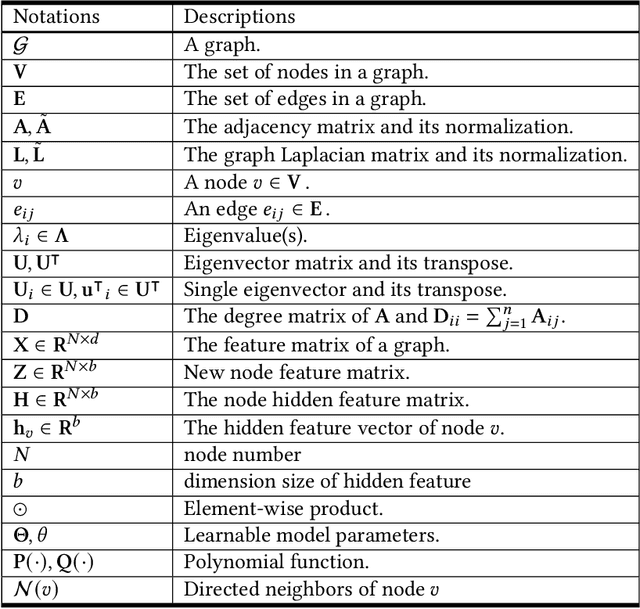

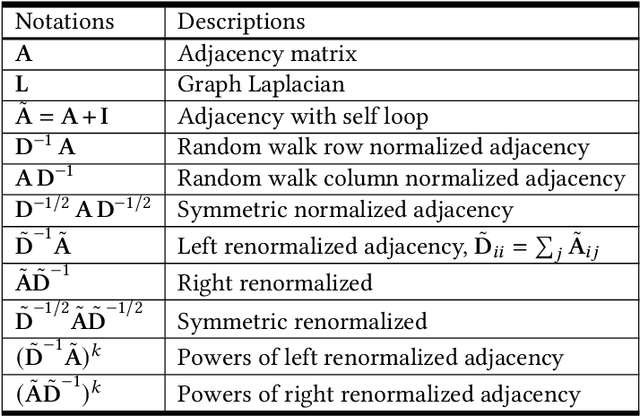
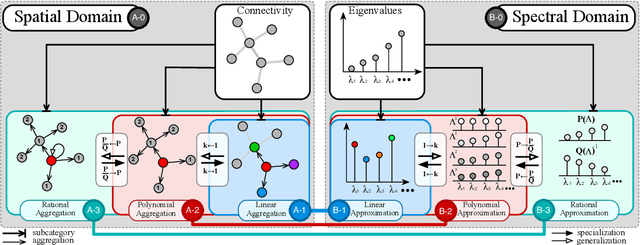
During the past decade, deep learning's performance has been widely recognized in a variety of machine learning tasks, ranging from image classification, speech recognition to natural language understanding. Graph neural networks (GNN) are a type of deep learning that is designed to handle non-Euclidean issues using graph-structured data that are difficult to solve with traditional deep learning techniques. The majority of GNNs were created using a variety of processes, including random walk, PageRank, graph convolution, and heat diffusion, making direct comparisons impossible. Previous studies have primarily focused on classifying current models into distinct categories, with little investigation of their internal relationships. This research proposes a unified theoretical framework and a novel perspective that can methodologically integrate existing GNN into our framework. We survey and categorize existing GNN models into spatial and spectral domains, as well as show linkages between subcategories within each domain. Further investigation reveals a strong relationship between the spatial, spectral, and subgroups of these domains.
Hybrid Fusion Based Interpretable Multimodal Emotion Recognition with Insufficient Labelled Data
Aug 24, 2022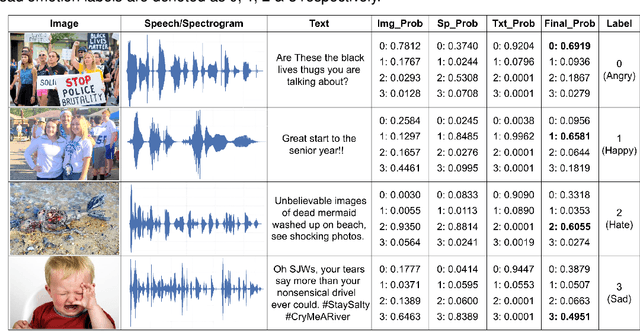
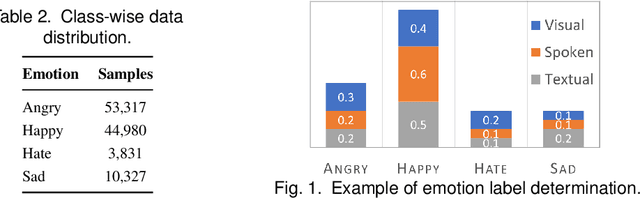
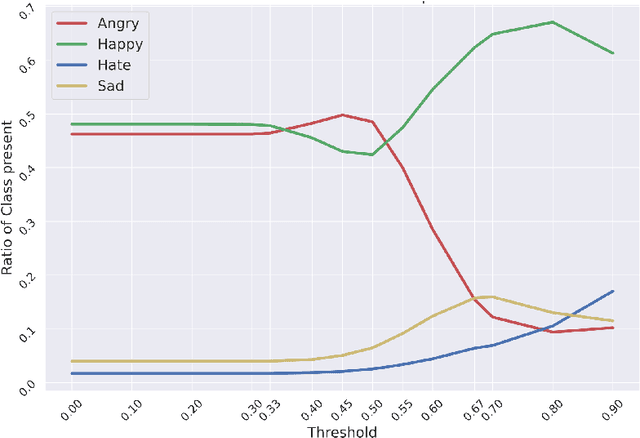
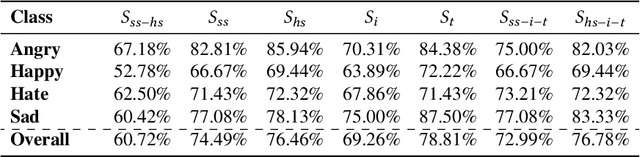
This paper proposes a multimodal emotion recognition system, VIsual Spoken Textual Additive Net (VISTA Net), to classify the emotions reflected by a multimodal input containing image, speech, and text into discrete classes. A new interpretability technique, K-Average Additive exPlanation (KAAP), has also been developed to identify the important visual, spoken, and textual features leading to predicting a particular emotion class. The VISTA Net fuses the information from image, speech & text modalities using a hybrid of early and late fusion. It automatically adjusts the weights of their intermediate outputs while computing the weighted average without human intervention. The KAAP technique computes the contribution of each modality and corresponding features toward predicting a particular emotion class. To mitigate the insufficiency of multimodal emotion datasets labeled with discrete emotion classes, we have constructed a large-scale IIT-R MMEmoRec dataset consisting of real-life images, corresponding speech & text, and emotion labels ('angry,' 'happy,' 'hate,' and 'sad.'). The VISTA Net has resulted in 95.99% emotion recognition accuracy on considering image, speech, and text modalities, which is better than the performance on considering the inputs of any one or two modalities.
ASR Rescoring and Confidence Estimation with ELECTRA
Oct 05, 2021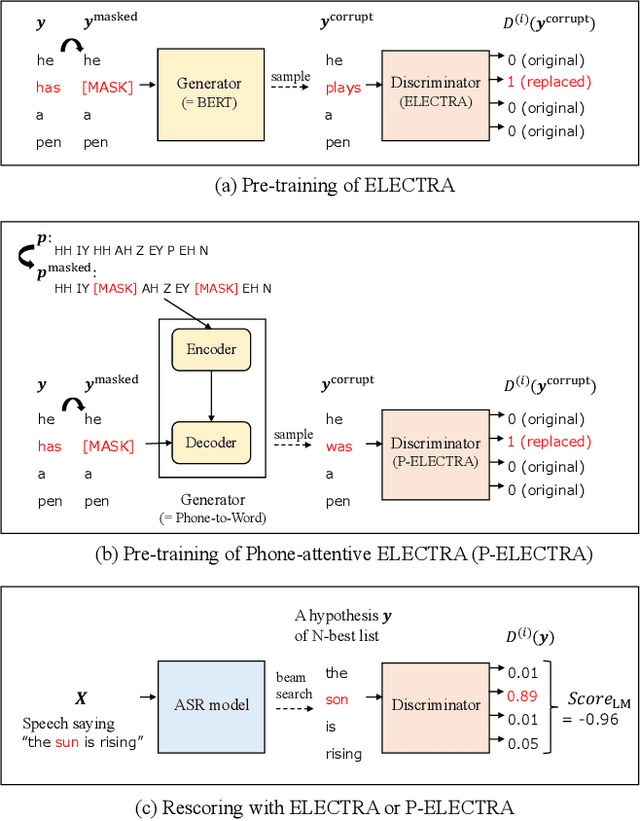

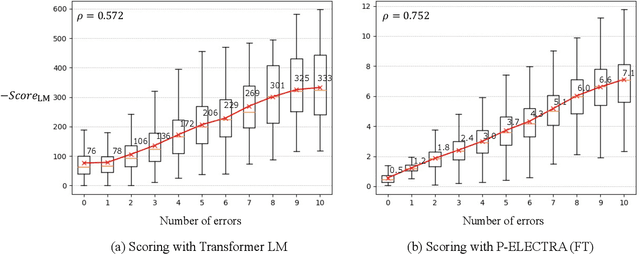
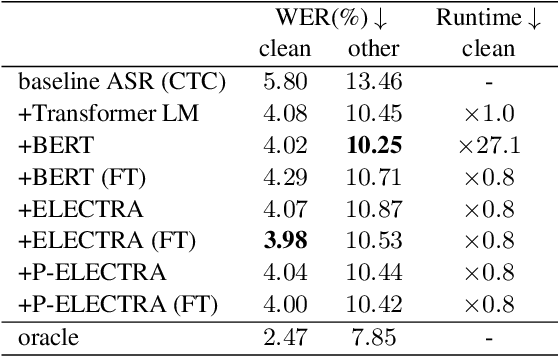
In automatic speech recognition (ASR) rescoring, the hypothesis with the fewest errors should be selected from the n-best list using a language model (LM). However, LMs are usually trained to maximize the likelihood of correct word sequences, not to detect ASR errors. We propose an ASR rescoring method for directly detecting errors with ELECTRA, which is originally a pre-training method for NLP tasks. ELECTRA is pre-trained to predict whether each word is replaced by BERT or not, which can simulate ASR error detection on large text corpora. To make this pre-training closer to ASR error detection, we further propose an extended version of ELECTRA called phone-attentive ELECTRA (P-ELECTRA). In the pre-training of P-ELECTRA, each word is replaced by a phone-to-word conversion model, which leverages phone information to generate acoustically similar words. Since our rescoring method is optimized for detecting errors, it can also be used for word-level confidence estimation. Experimental evaluations on the Librispeech and TED-LIUM2 corpora show that our rescoring method with ELECTRA is competitive with conventional rescoring methods with faster inference. ELECTRA also performs better in confidence estimation than BERT because it can learn to detect inappropriate words not only in fine-tuning but also in pre-training.
Investigation of Speaker-adaptation methods in Transformer based ASR
Aug 07, 2020
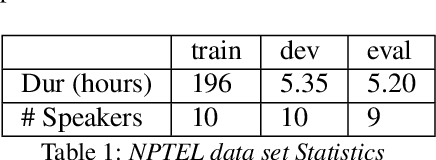
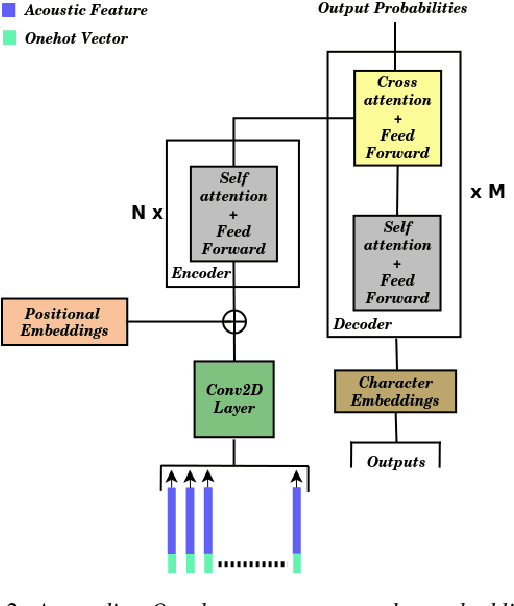
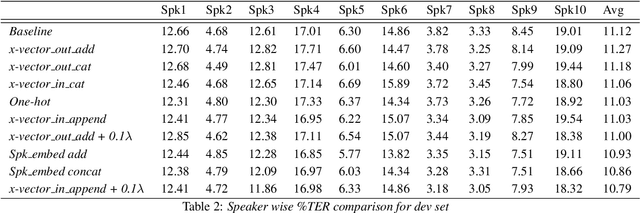
End-to-end models are fast replacing conventional hybrid models in automatic speech recognition. A transformer is a sequence-to-sequence framework solely based on attention, that was initially applied to machine translation task. This end-to-end framework has been shown to give promising results when used for automatic speech recognition as well. In this paper, we explore different ways of incorporating speaker information while training a transformer-based model to improve its performance. We present speaker information in the form of speaker embeddings for each of the speakers. Two broad categories of speaker embeddings are used: (i)fixed embeddings, and (ii)learned embeddings. We experiment using speaker embeddings learned along with the model training, as well as one-hot vectors and x-vectors. Using these different speaker embeddings, we obtain an average relative improvement of 1% to 3% in the token error rate. We report results on the NPTEL lecture database. NPTEL is an open-source e-learning portal providing content from top Indian universities.
LeBenchmark: A Reproducible Framework for Assessing Self-Supervised Representation Learning from Speech
Apr 23, 2021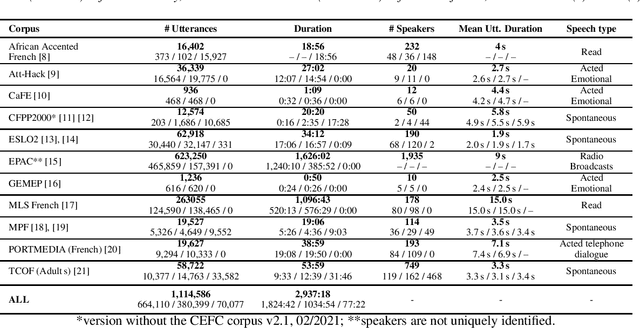
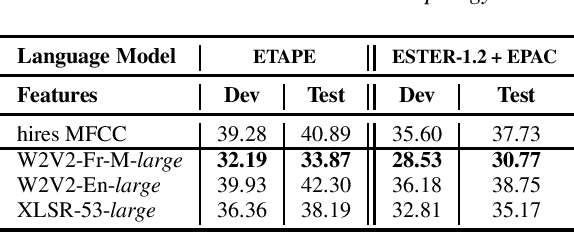
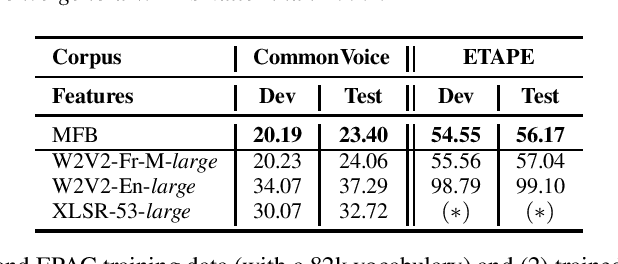
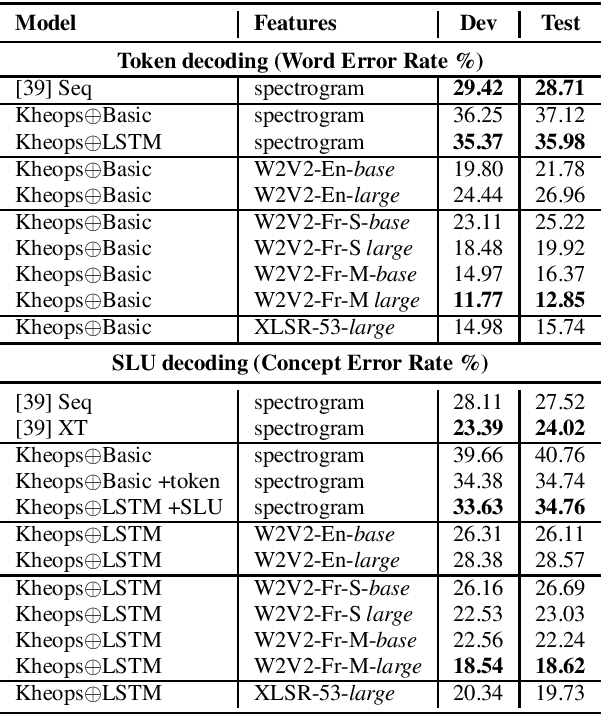
Self-Supervised Learning (SSL) using huge unlabeled data has been successfully explored for image and natural language processing. Recent works also investigated SSL from speech. They were notably successful to improve performance on downstream tasks such as automatic speech recognition (ASR). While these works suggest it is possible to reduce dependence on labeled data for building efficient speech systems, their evaluation was mostly made on ASR and using multiple and heterogeneous experimental settings (most of them for English). This renders difficult the objective comparison between SSL approaches and the evaluation of their impact on building speech systems. In this paper, we propose LeBenchmark: a reproducible framework for assessing SSL from speech. It not only includes ASR (high and low resource) tasks but also spoken language understanding, speech translation and emotion recognition. We also target speech technologies in a language different than English: French. SSL models of different sizes are trained from carefully sourced and documented datasets. Experiments show that SSL is beneficial for most but not all tasks which confirms the need for exhaustive and reliable benchmarks to evaluate its real impact. LeBenchmark is shared with the scientific community for reproducible research in SSL from speech.
Sequence Model with Self-Adaptive Sliding Window for Efficient Spoken Document Segmentation
Jul 20, 2021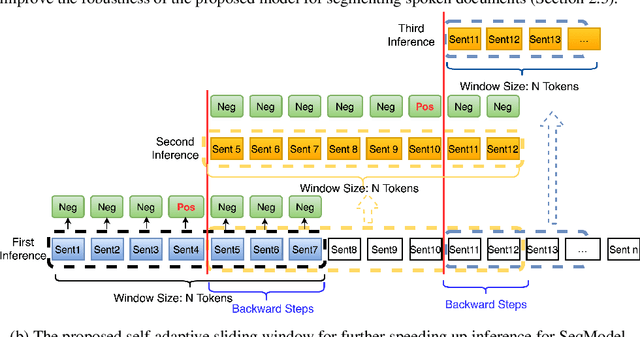
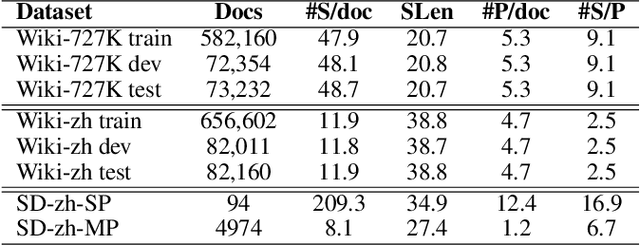
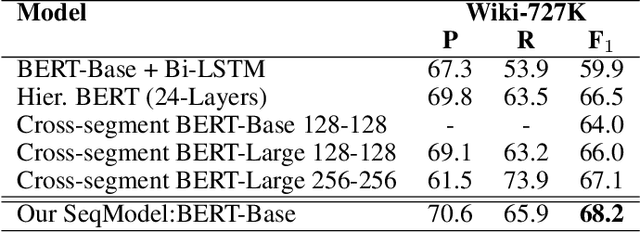
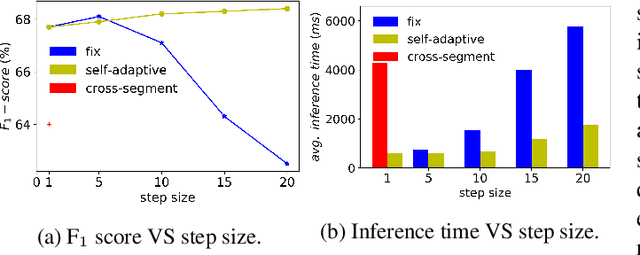
Transcripts generated by automatic speech recognition (ASR) systems for spoken documents lack structural annotations such as paragraphs, significantly reducing their readability. Automatically predicting paragraph segmentation for spoken documents may both improve readability and downstream NLP performance such as summarization and machine reading comprehension. We propose a sequence model with self-adaptive sliding window for accurate and efficient paragraph segmentation. We also propose an approach to exploit phonetic information, which significantly improves robustness of spoken document segmentation to ASR errors. Evaluations are conducted on the English Wiki-727K document segmentation benchmark, a Chinese Wikipedia-based document segmentation dataset we created, and an in-house Chinese spoken document dataset. Our proposed model outperforms the state-of-the-art (SOTA) model based on the same BERT-Base, increasing segmentation F1 on the English benchmark by 4.2 points and on Chinese datasets by 4.3-10.1 points, while reducing inference time to less than 1/6 of inference time of the current SOTA.