 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
CTC Variations Through New WFST Topologies
Oct 06, 2021
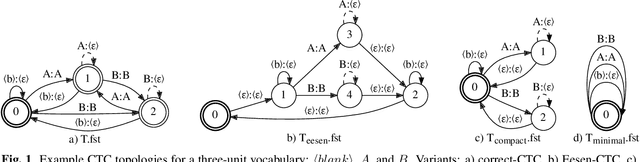
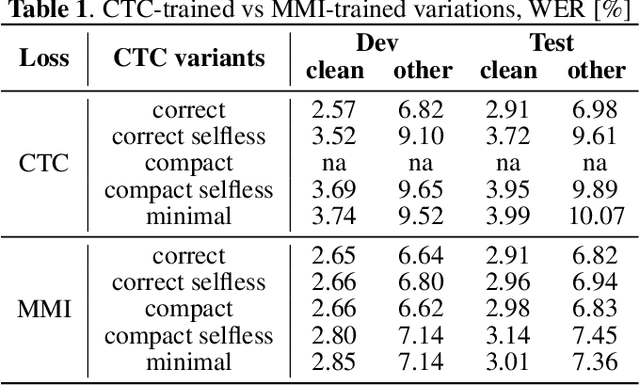
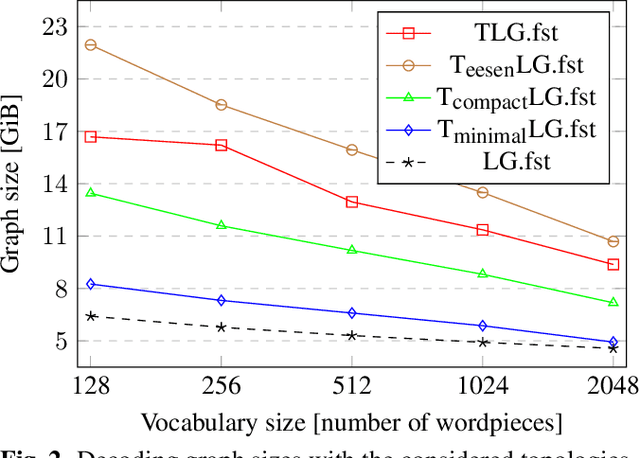
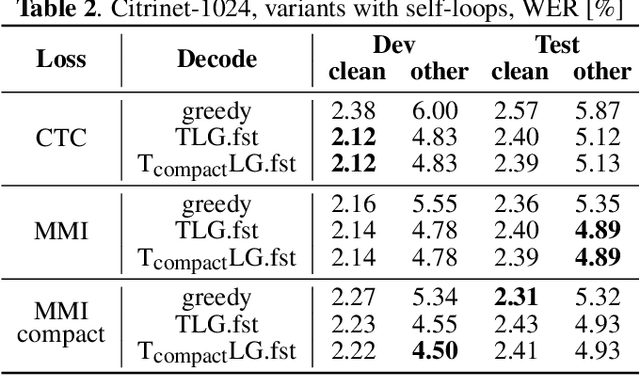
This paper presents novel Weighted Finite-State Transducer (WFST) topologies to implement Connectionist Temporal Classification (CTC)-like algorithms for automatic speech recognition. Three new CTC variants are proposed: (1) the "compact-CTC", in which direct transitions between units are replaced with <epsilon> back-off transitions; (2) the "minimal-CTC", that only adds <blank> self-loops when used in WFST-composition; and (3) "selfless-CTC", that disallows self-loop for non-blank units. The new CTC variants have several benefits, such as reducing decoding graph size and GPU memory required for training while keeping model accuracy.
Structured Language Modeling for Speech Recognition
Jan 25, 2000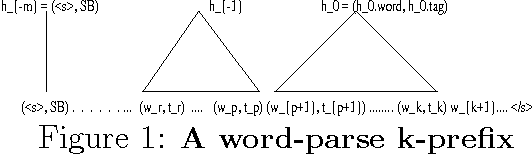

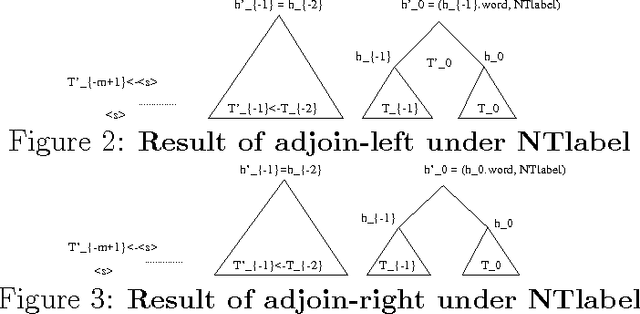
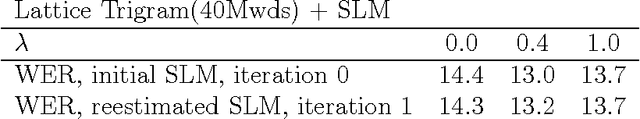
A new language model for speech recognition is presented. The model develops hidden hierarchical syntactic-like structure incrementally and uses it to extract meaningful information from the word history, thus complementing the locality of currently used trigram models. The structured language model (SLM) and its performance in a two-pass speech recognizer --- lattice decoding --- are presented. Experiments on the WSJ corpus show an improvement in both perplexity (PPL) and word error rate (WER) over conventional trigram models.
* 4 pages + 2 pages of ERRATA
Exploiting Pre-Trained ASR Models for Alzheimer's Disease Recognition Through Spontaneous Speech
Oct 04, 2021
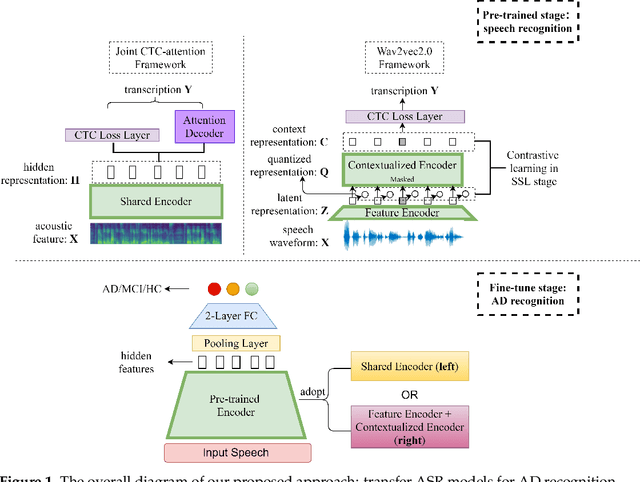
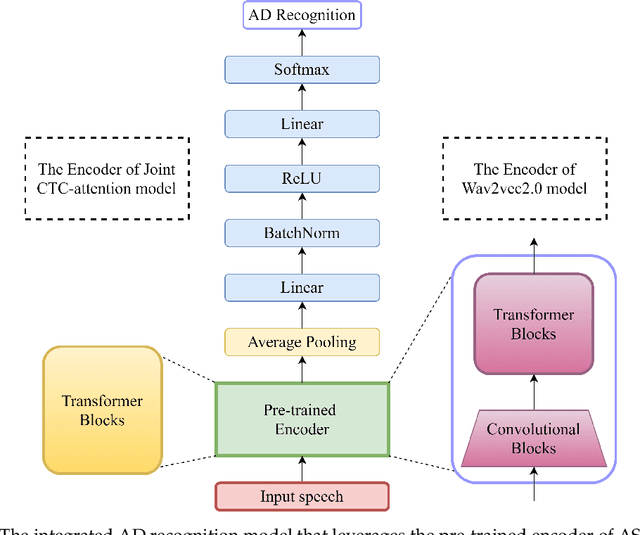
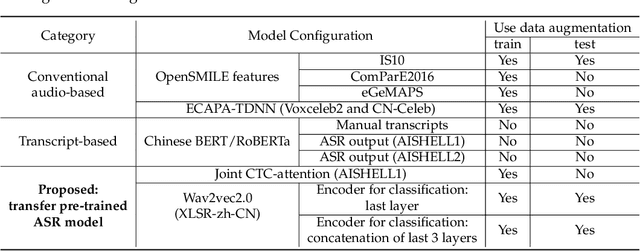
Alzheimer's disease (AD) is a progressive neurodegenerative disease and recently attracts extensive attention worldwide. Speech technology is considered a promising solution for the early diagnosis of AD and has been enthusiastically studied. Most recent works concentrate on the use of advanced BERT-like classifiers for AD detection. Input to these classifiers are speech transcripts produced by automatic speech recognition (ASR) models. The major challenge is that the quality of transcription could degrade significantly under complex acoustic conditions in the real world. The detection performance, in consequence, is largely limited. This paper tackles the problem via tailoring and adapting pre-trained neural-network based ASR model for the downstream AD recognition task. Only bottom layers of the ASR model are retained. A simple fully-connected neural network is added on top of the tailored ASR model for classification. The heavy BERT classifier is discarded. The resulting model is light-weight and can be fine-tuned in an end-to-end manner for AD recognition. Our proposed approach takes only raw speech as input, and no extra transcription process is required. The linguistic information of speech is implicitly encoded in the tailored ASR model and contributes to boosting the performance. Experiments show that our proposed approach outperforms the best manual transcript-based RoBERTa by an absolute margin of 4.6% in terms of accuracy. Our best-performing models achieve the accuracy of 83.2% and 78.0% in the long-audio and short-audio competition tracks of the 2021 NCMMSC Alzheimer's Disease Recognition Challenge, respectively.
End-to-end Speech Recognition with Word-based RNN Language Models
Aug 08, 2018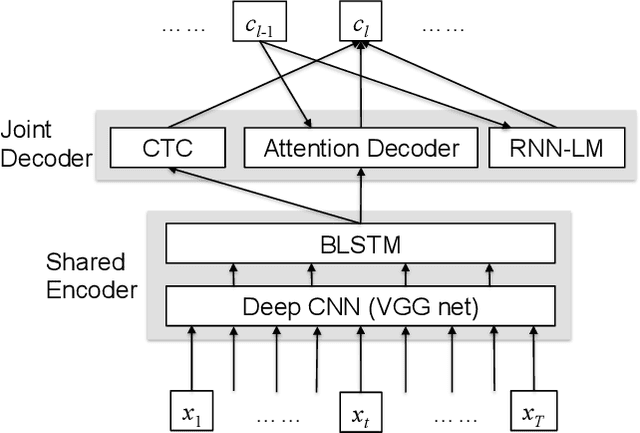

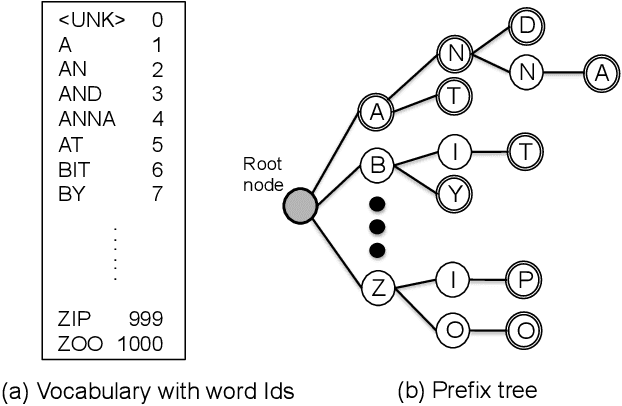
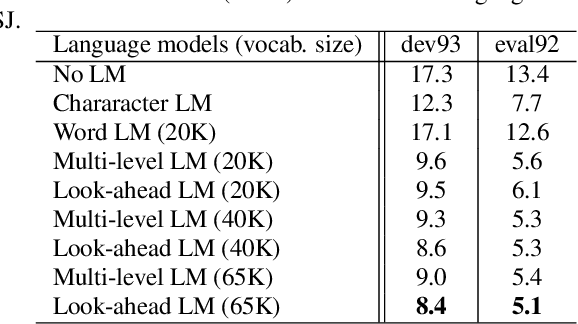
This paper investigates the impact of word-based RNN language models (RNN-LMs) on the performance of end-to-end automatic speech recognition (ASR). In our prior work, we have proposed a multi-level LM, in which character-based and word-based RNN-LMs are combined in hybrid CTC/attention-based ASR. Although this multi-level approach achieves significant error reduction in the Wall Street Journal (WSJ) task, two different LMs need to be trained and used for decoding, which increase the computational cost and memory usage. In this paper, we further propose a novel word-based RNN-LM, which allows us to decode with only the word-based LM, where it provides look-ahead word probabilities to predict next characters instead of the character-based LM, leading competitive accuracy with less computation compared to the multi-level LM. We demonstrate the efficacy of the word-based RNN-LMs using a larger corpus, LibriSpeech, in addition to WSJ we used in the prior work. Furthermore, we show that the proposed model achieves 5.1 %WER for WSJ Eval'92 test set when the vocabulary size is increased, which is the best WER reported for end-to-end ASR systems on this benchmark.
The Norwegian Parliamentary Speech Corpus
Jan 26, 2022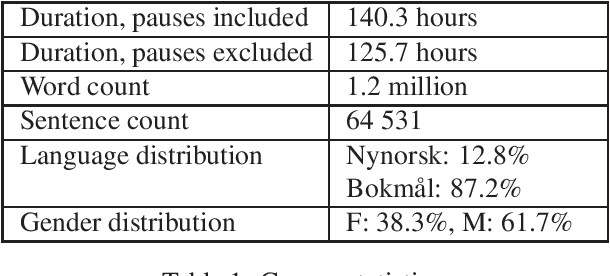
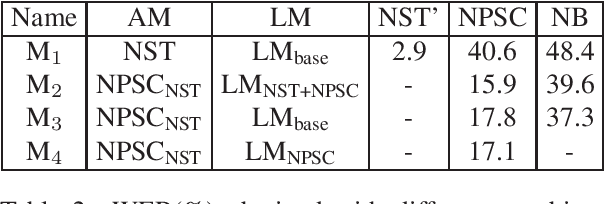
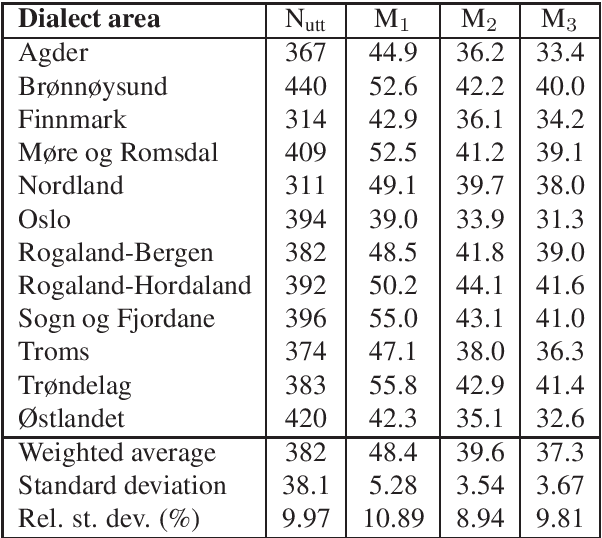
The Norwegian Parliamentary Speech Corpus (NPSC) is a speech dataset with recordings of meetings from Stortinget, the Norwegian parliament. It is the first, publicly available dataset containing unscripted, Norwegian speech designed for training of automatic speech recognition (ASR) systems. The recordings are manually transcribed and annotated with language codes and speakers, and there are detailed metadata about the speakers. The transcriptions exist in both normalized and non-normalized form, and non-standardized words are explicitly marked and annotated with standardized equivalents. To test the usefulness of this dataset, we have compared an ASR system trained on the NPSC with a baseline system trained on only manuscript-read speech. These systems were tested on an independent dataset containing spontaneous, dialectal speech. The NPSC-trained system performed significantly better, with a 22.9% relative improvement in word error rate (WER). Moreover, training on the NPSC is shown to have a "democratizing" effect in terms of dialects, as improvements are generally larger for dialects with higher WER from the baseline system.
HASP: A High-Performance Adaptive Mobile Security Enhancement Against Malicious Speech Recognition
Sep 04, 2018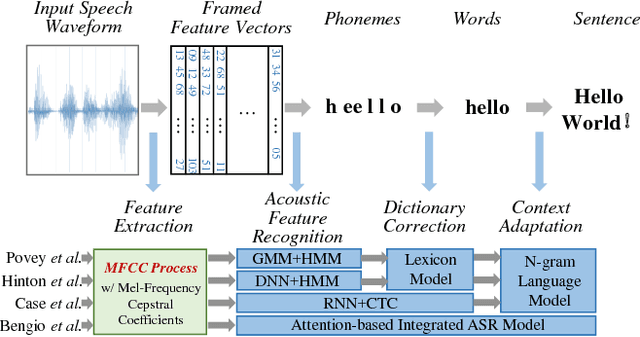
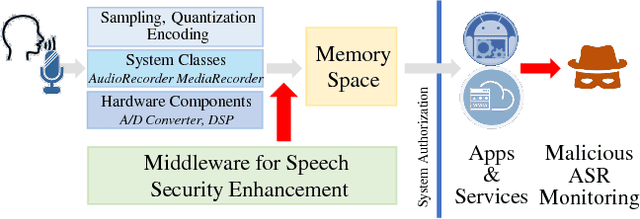
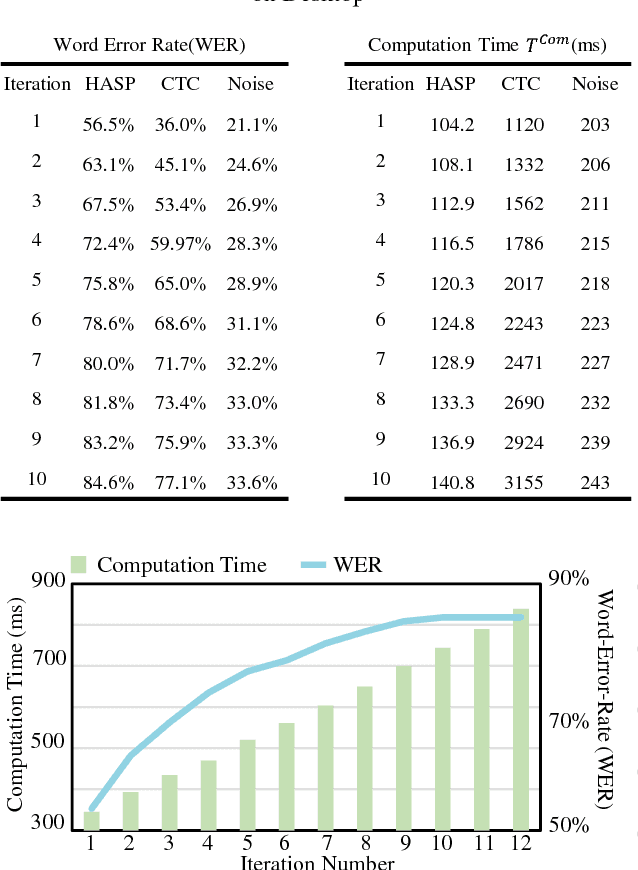
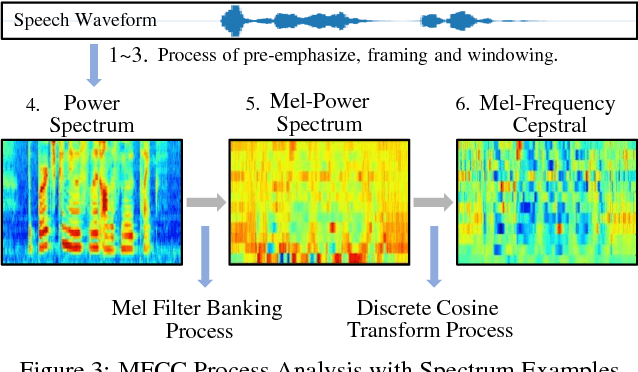
Nowadays, machine learning based Automatic Speech Recognition (ASR) technique has widely spread in smartphones, home devices, and public facilities. As convenient as this technology can be, a considerable security issue also raises -- the users' speech content might be exposed to malicious ASR monitoring and cause severe privacy leakage. In this work, we propose HASP -- a high-performance security enhancement approach to solve this security issue on mobile devices. Leveraging ASR systems' vulnerability to the adversarial examples, HASP is designed to cast human imperceptible adversarial noises to real-time speech and effectively perturb malicious ASR monitoring by increasing the Word Error Rate (WER). To enhance the practical performance on mobile devices, HASP is also optimized for effective adaptation to the human speech characteristics, environmental noises, and mobile computation scenarios. The experiments show that HASP can achieve optimal real-time security enhancement: it can lead an average WER of 84.55% for perturbing the malicious ASR monitoring, and the data processing speed is 15x to 40x faster compared to the state-of-the-art methods. Moreover, HASP can effectively perturb various ASR systems, demonstrating a strong transferability.
Improving the fusion of acoustic and text representations in RNN-T
Jan 25, 2022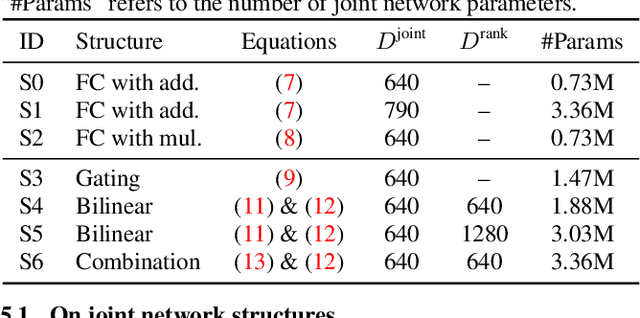

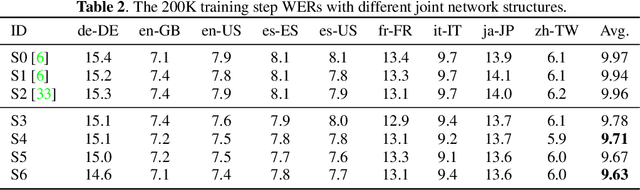
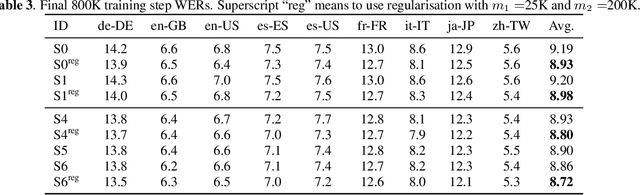
The recurrent neural network transducer (RNN-T) has recently become the mainstream end-to-end approach for streaming automatic speech recognition (ASR). To estimate the output distributions over subword units, RNN-T uses a fully connected layer as the joint network to fuse the acoustic representations extracted using the acoustic encoder with the text representations obtained using the prediction network based on the previous subword units. In this paper, we propose to use gating, bilinear pooling, and a combination of them in the joint network to produce more expressive representations to feed into the output layer. A regularisation method is also proposed to enable better acoustic encoder training by reducing the gradients back-propagated into the prediction network at the beginning of RNN-T training. Experimental results on a multilingual ASR setting for voice search over nine languages show that the joint use of the proposed methods can result in 4%--5% relative word error rate reductions with only a few million extra parameters.
A Text-to-Speech Pipeline, Evaluation Methodology, and Initial Fine-Tuning Results for Child Speech Synthesis
Apr 04, 2022
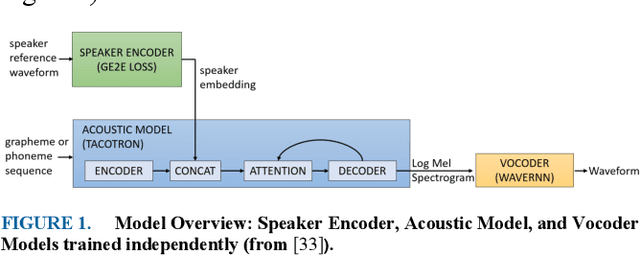
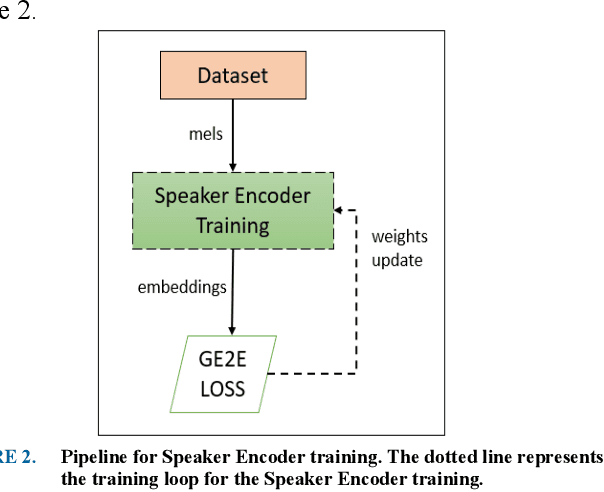
Speech synthesis has come a long way as current text-to-speech (TTS) models can now generate natural human-sounding speech. However, most of the TTS research focuses on using adult speech data and there has been very limited work done on child speech synthesis. This study developed and validated a training pipeline for fine-tuning state-of-the-art (SOTA) neural TTS models using child speech datasets. This approach adopts a multi-speaker TTS retuning workflow to provide a transfer-learning pipeline. A publicly available child speech dataset was cleaned to provide a smaller subset of approximately 19 hours, which formed the basis of our fine-tuning experiments. Both subjective and objective evaluations were performed using a pretrained MOSNet for objective evaluation and a novel subjective framework for mean opinion score (MOS) evaluations. Subjective evaluations achieved the MOS of 3.95 for speech intelligibility, 3.89 for voice naturalness, and 3.96 for voice consistency. Objective evaluation using a pretrained MOSNet showed a strong correlation between real and synthetic child voices. Speaker similarity was also verified by calculating the cosine similarity between the embeddings of utterances. An automatic speech recognition (ASR) model is also used to provide a word error rate (WER) comparison between the real and synthetic child voices. The final trained TTS model was able to synthesize child-like speech from reference audio samples as short as 5 seconds.
Hybrid Data Augmentation and Deep Attention-based Dilated Convolutional-Recurrent Neural Networks for Speech Emotion Recognition
Sep 18, 2021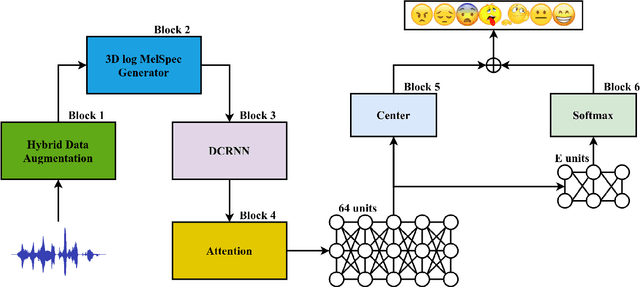
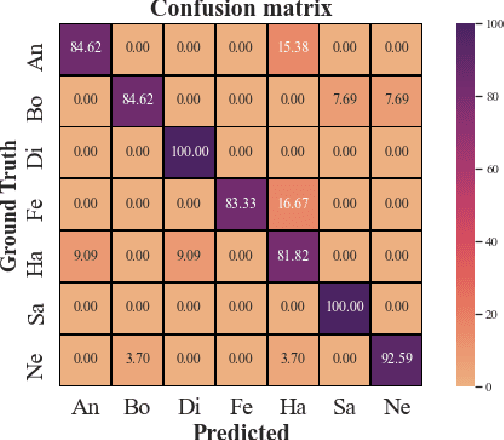
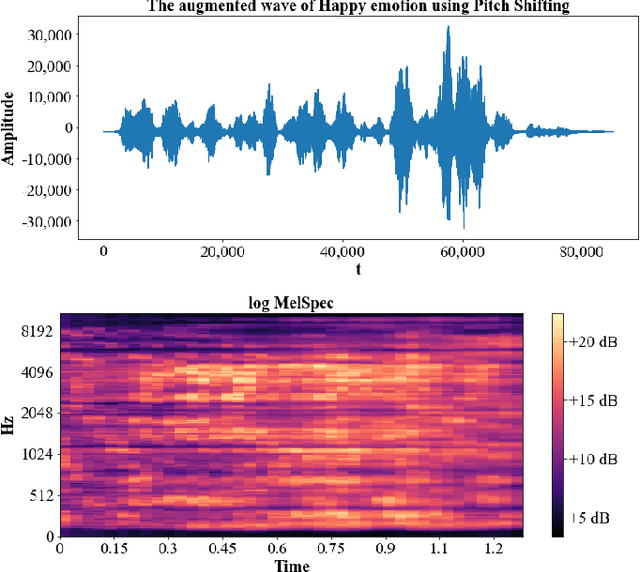
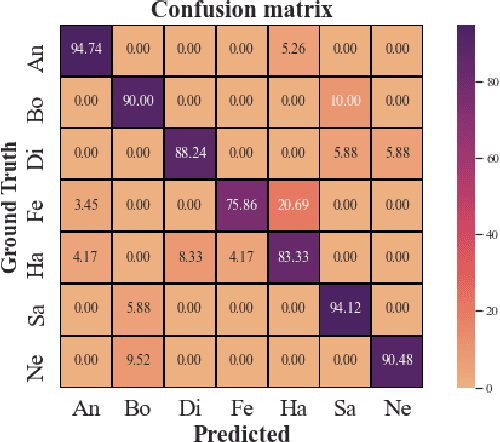
Speech emotion recognition (SER) has been one of the significant tasks in Human-Computer Interaction (HCI) applications. However, it is hard to choose the optimal features and deal with imbalance labeled data. In this article, we investigate hybrid data augmentation (HDA) methods to generate and balance data based on traditional and generative adversarial networks (GAN) methods. To evaluate the effectiveness of HDA methods, a deep learning framework namely (ADCRNN) is designed by integrating deep dilated convolutional-recurrent neural networks with an attention mechanism. Besides, we choose 3D log Mel-spectrogram (MelSpec) features as the inputs for the deep learning framework. Furthermore, we reconfigure a loss function by combining a softmax loss and a center loss to classify the emotions. For validating our proposed methods, we use the EmoDB dataset that consists of several emotions with imbalanced samples. Experimental results prove that the proposed methods achieve better accuracy than the state-of-the-art methods on the EmoDB with 87.12% and 88.47% for the traditional and GAN-based methods, respectively.
Residual Convolutional CTC Networks for Automatic Speech Recognition
Feb 24, 2017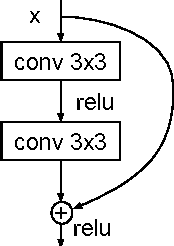

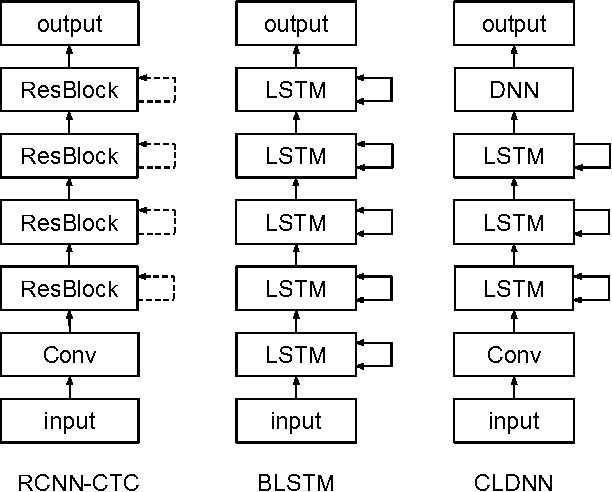
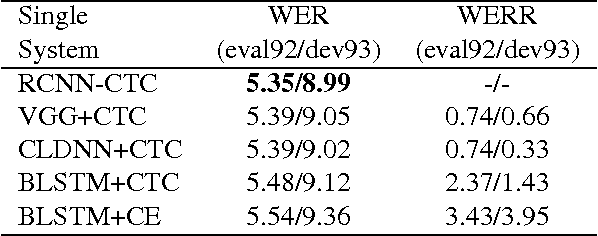
Deep learning approaches have been widely used in Automatic Speech Recognition (ASR) and they have achieved a significant accuracy improvement. Especially, Convolutional Neural Networks (CNNs) have been revisited in ASR recently. However, most CNNs used in existing work have less than 10 layers which may not be deep enough to capture all human speech signal information. In this paper, we propose a novel deep and wide CNN architecture denoted as RCNN-CTC, which has residual connections and Connectionist Temporal Classification (CTC) loss function. RCNN-CTC is an end-to-end system which can exploit temporal and spectral structures of speech signals simultaneously. Furthermore, we introduce a CTC-based system combination, which is different from the conventional frame-wise senone-based one. The basic subsystems adopted in the combination are different types and thus mutually complementary to each other. Experimental results show that our proposed single system RCNN-CTC can achieve the lowest word error rate (WER) on WSJ and Tencent Chat data sets, compared to several widely used neural network systems in ASR. In addition, the proposed system combination can offer a further error reduction on these two data sets, resulting in relative WER reductions of $14.91\%$ and $6.52\%$ on WSJ dev93 and Tencent Chat data sets respectively.