 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynParaSpeech: Automated Synthesis of Paralinguistic Datasets for Speech Generation and Understanding
Sep 18, 2025



Paralinguistic sounds, like laughter and sighs, are crucial for synthesizing more realistic and engaging speech. However, existing methods typically depend on proprietary datasets, while publicly available resources often suffer from incomplete speech, inaccurate or missing timestamps, and limited real-world relevance. To address these problems, we propose an automated framework for generating large-scale paralinguistic data and apply it to construct the SynParaSpeech dataset. The dataset comprises 6 paralinguistic categories with 118.75 hours of data and precise timestamps, all derived from natural conversational speech. Our contributions lie in introducing the first automated method for constructing large-scale paralinguistic datasets and releasing the SynParaSpeech corpus, which advances speech generation through more natural paralinguistic synthesis and enhances speech understanding by improving paralinguistic event detection. The dataset and audio samples are available at https://github.com/ShawnPi233/SynParaSpeech.
Residual Convolutional CTC Networks for Automatic Speech Recognition
Feb 24, 2017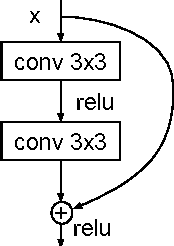

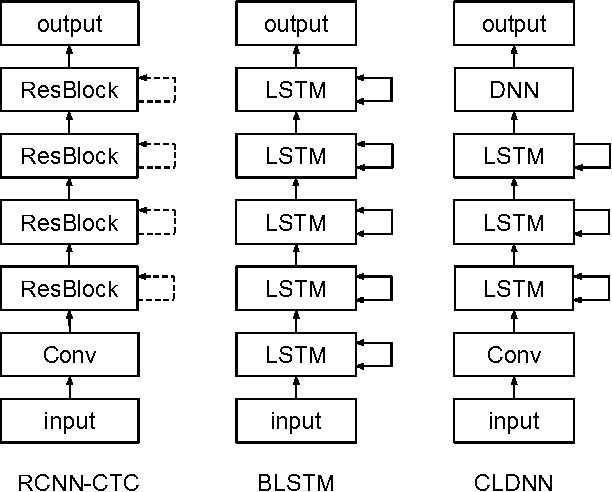
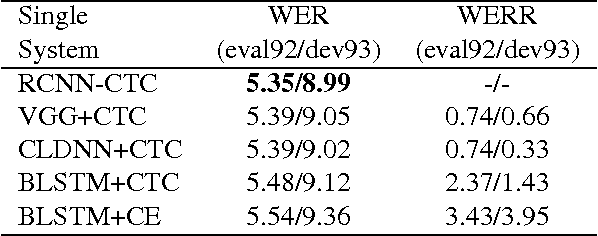
Deep learning approaches have been widely used in Automatic Speech Recognition (ASR) and they have achieved a significant accuracy improvement. Especially, Convolutional Neural Networks (CNNs) have been revisited in ASR recently. However, most CNNs used in existing work have less than 10 layers which may not be deep enough to capture all human speech signal information. In this paper, we propose a novel deep and wide CNN architecture denoted as RCNN-CTC, which has residual connections and Connectionist Temporal Classification (CTC) loss function. RCNN-CTC is an end-to-end system which can exploit temporal and spectral structures of speech signals simultaneously. Furthermore, we introduce a CTC-based system combination, which is different from the conventional frame-wise senone-based one. The basic subsystems adopted in the combination are different types and thus mutually complementary to each other. Experimental results show that our proposed single system RCNN-CTC can achieve the lowest word error rate (WER) on WSJ and Tencent Chat data sets, compared to several widely used neural network systems in ASR. In addition, the proposed system combination can offer a further error reduction on these two data sets, resulting in relative WER reductions of $14.91\%$ and $6.52\%$ on WSJ dev93 and Tencent Chat data sets respectively.