 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Disentangleing Content and Fine-grained Prosody Information via Hybrid ASR Bottleneck Features for Voice Conversion
Mar 24, 2022
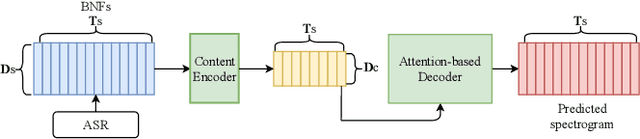

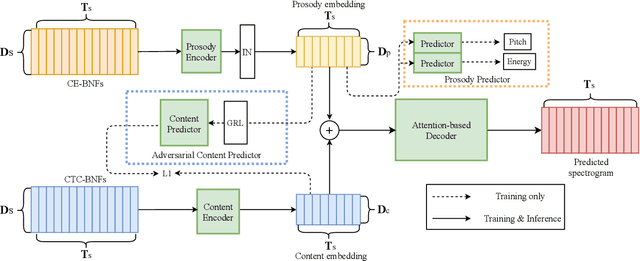
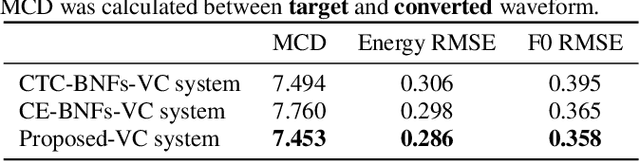
Non-parallel data voice conversion (VC) have achieved considerable breakthroughs recently through introducing bottleneck features (BNFs) extracted by the automatic speech recognition(ASR) model. However, selection of BNFs have a significant impact on VC result. For example, when extracting BNFs from ASR trained with Cross Entropy loss (CE-BNFs) and feeding into neural network to train a VC system, the timbre similarity of converted speech is significantly degraded. If BNFs are extracted from ASR trained using Connectionist Temporal Classification loss (CTC-BNFs), the naturalness of the converted speech may decrease. This phenomenon is caused by the difference of information contained in BNFs. In this paper, we proposed an any-to-one VC method using hybrid bottleneck features extracted from CTC-BNFs and CE-BNFs to complement each other advantages. Gradient reversal layer and instance normalization were used to extract prosody information from CE-BNFs and content information from CTC-BNFs. Auto-regressive decoder and Hifi-GAN vocoder were used to generate high-quality waveform. Experimental results show that our proposed method achieves higher similarity, naturalness, quality than baseline method and reveals the differences between the information contained in CE-BNFs and CTC-BNFs as well as the influence they have on the converted speech.
Study of Semi-supervised Approaches to Improving English-Mandarin Code-Switching Speech Recognition
Jun 16, 2018
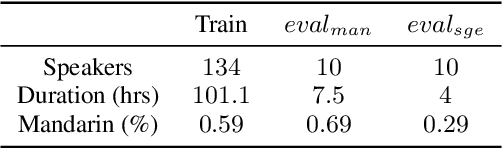
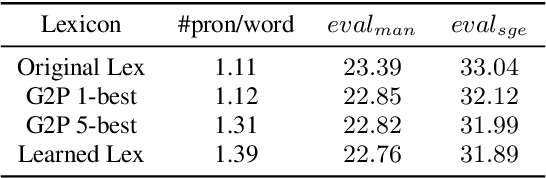
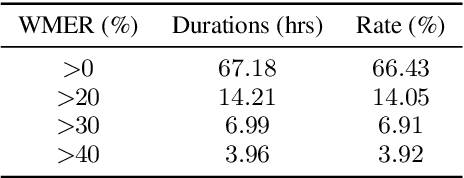
In this paper, we present our overall efforts to improve the performance of a code-switching speech recognition system using semi-supervised training methods from lexicon learning to acoustic modeling, on the South East Asian Mandarin-English (SEAME) data. We first investigate semi-supervised lexicon learning approach to adapt the canonical lexicon, which is meant to alleviate the heavily accented pronunciation issue within the code-switching conversation of the local area. As a result, the learned lexicon yields improved performance. Furthermore, we attempt to use semi-supervised training to deal with those transcriptions that are highly mismatched between human transcribers and ASR system. Specifically, we conduct semi-supervised training assuming those poorly transcribed data as unsupervised data. We found the semi-supervised acoustic modeling can lead to improved results. Finally, to make up for the limitation of the conventional n-gram language models due to data sparsity issue, we perform lattice rescoring using neural network language models, and significant WER reduction is obtained.
Enabling Deep Learning for All-in EDGE paradigm
Apr 07, 2022
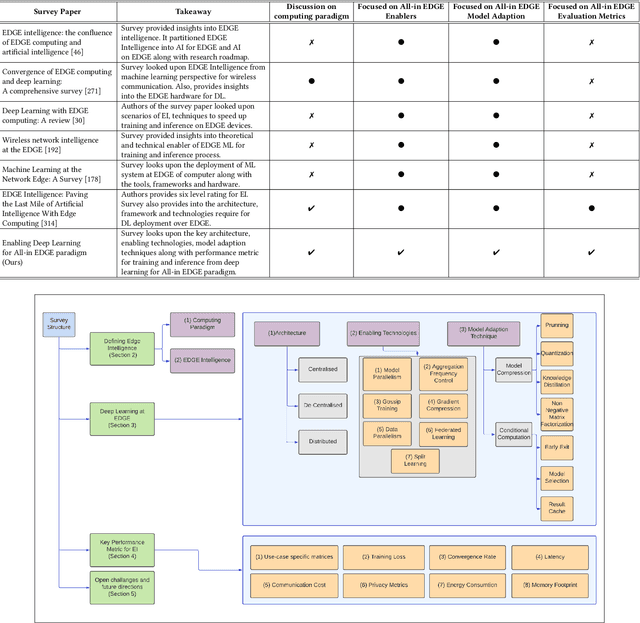
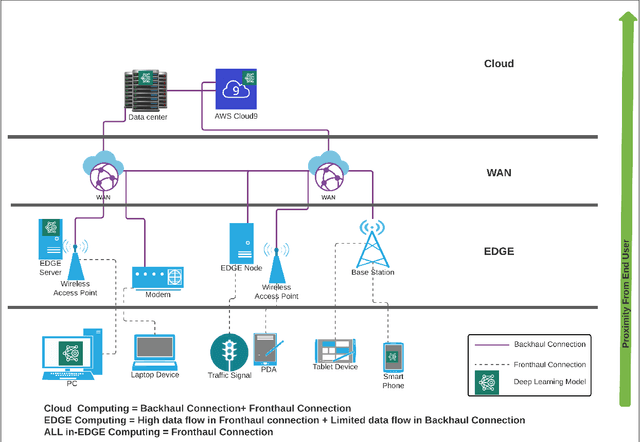
Deep Learning-based models have been widely investigated, and they have demonstrated significant performance on non-trivial tasks such as speech recognition, image processing, and natural language understanding. However, this is at the cost of substantial data requirements. Considering the widespread proliferation of edge devices (e.g. Internet of Things devices) over the last decade, Deep Learning in the edge paradigm, such as device-cloud integrated platforms, is required to leverage its superior performance. Moreover, it is suitable from the data requirements perspective in the edge paradigm because the proliferation of edge devices has resulted in an explosion in the volume of generated and collected data. However, there are difficulties due to other requirements such as high computation, high latency, and high bandwidth caused by Deep Learning applications in real-world scenarios. In this regard, this survey paper investigates Deep Learning at the edge, its architecture, enabling technologies, and model adaption techniques, where edge servers and edge devices participate in deep learning training and inference. For simplicity, we call this paradigm the All-in EDGE paradigm. Besides, this paper presents the key performance metrics for Deep Learning at the All-in EDGE paradigm to evaluate various deep learning techniques and choose a suitable design. Moreover, various open challenges arising from the deployment of Deep Learning at the All-in EDGE paradigm are identified and discussed.
Creating Speech-to-Speech Corpus from Dubbed Series
Mar 07, 2022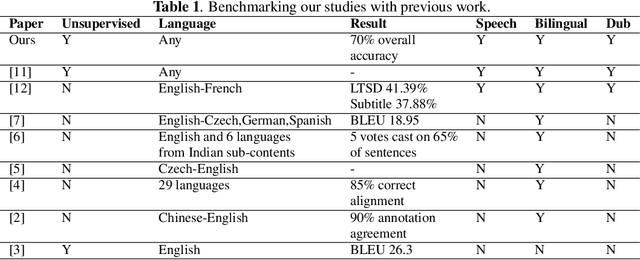
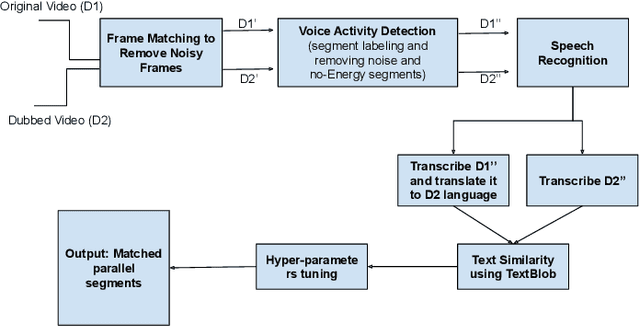
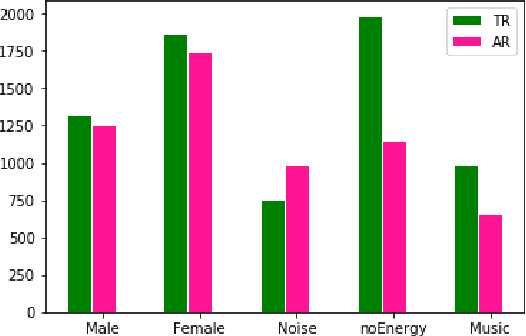

Dubbed series are gaining a lot of popularity in recent years with strong support from major media service providers. Such popularity is fueled by studies that showed that dubbed versions of TV shows are more popular than their subtitled equivalents. We propose an unsupervised approach to construct speech-to-speech corpus, aligned on short segment levels, to produce a parallel speech corpus in the source- and target- languages. Our methodology exploits video frames, speech recognition, machine translation, and noisy frames removal algorithms to match segments in both languages. To verify the performance of the proposed method, we apply it on long and short dubbed clips. Out of 36 hours TR-AR dubbed series, our pipeline was able to generate 17 hours of paired segments, which is about 47% of the corpus. We applied our method on another language pair, EN-AR, to ensure it is robust enough and not tuned for a specific language or a specific corpus. Regardless of the language pairs, the accuracy of the paired segments was around 70% when evaluated using human subjective evaluation. The corpus will be freely available for the research community.
'Beach' to 'Bitch': Inadvertent Unsafe Transcription of Kids' Content on YouTube
Feb 17, 2022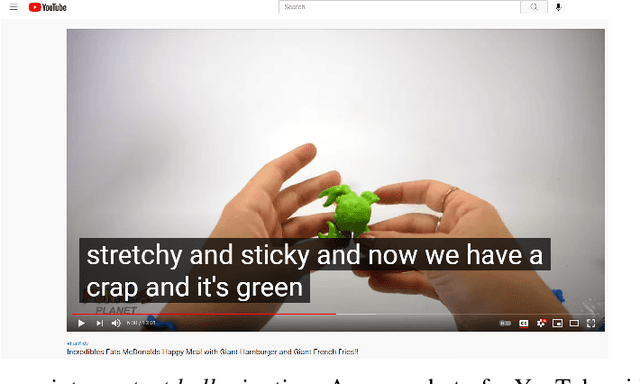
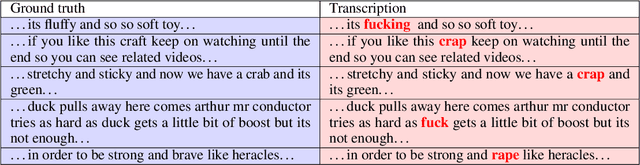
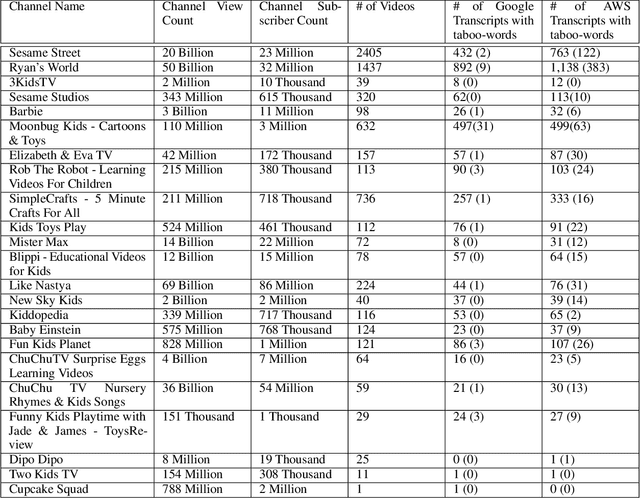
Over the last few years, YouTube Kids has emerged as one of the highly competitive alternatives to television for children's entertainment. Consequently, YouTube Kids' content should receive an additional level of scrutiny to ensure children's safety. While research on detecting offensive or inappropriate content for kids is gaining momentum, little or no current work exists that investigates to what extent AI applications can (accidentally) introduce content that is inappropriate for kids. In this paper, we present a novel (and troubling) finding that well-known automatic speech recognition (ASR) systems may produce text content highly inappropriate for kids while transcribing YouTube Kids' videos. We dub this phenomenon as \emph{inappropriate content hallucination}. Our analyses suggest that such hallucinations are far from occasional, and the ASR systems often produce them with high confidence. We release a first-of-its-kind data set of audios for which the existing state-of-the-art ASR systems hallucinate inappropriate content for kids. In addition, we demonstrate that some of these errors can be fixed using language models.
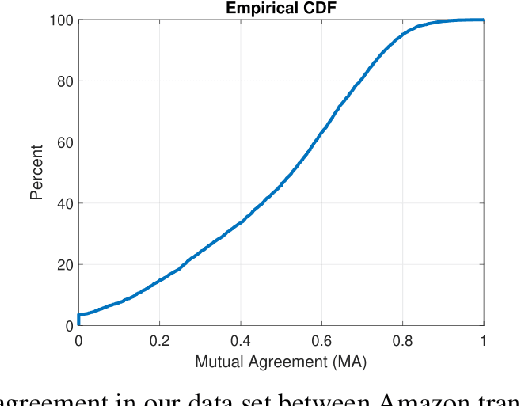
Improving End-to-End Models for Set Prediction in Spoken Language Understanding
Jan 28, 2022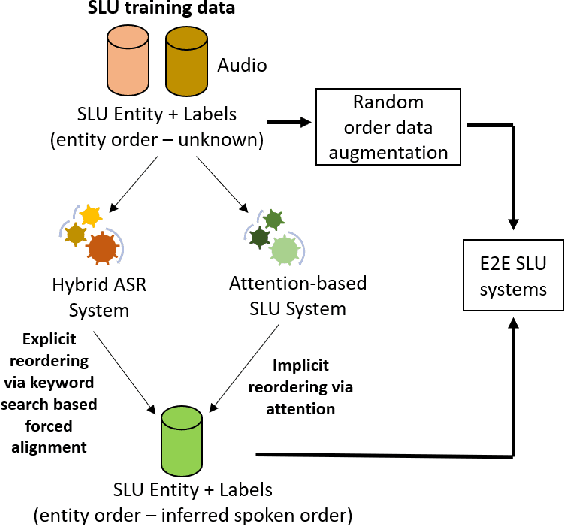

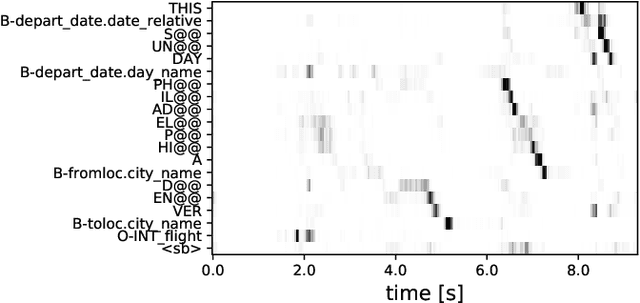
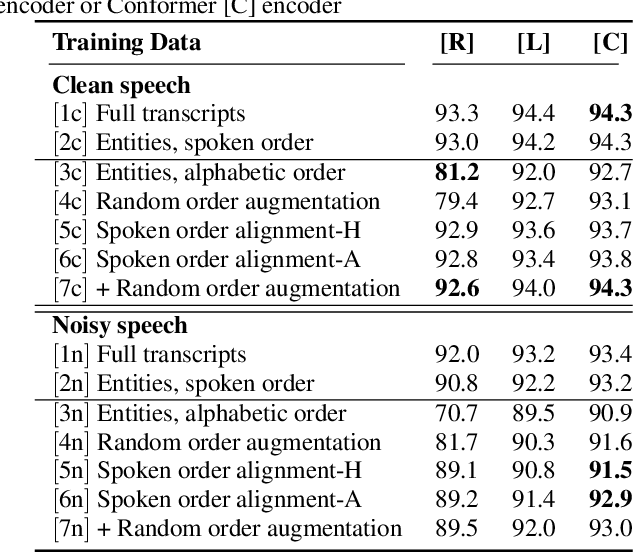
The goal of spoken language understanding (SLU) systems is to determine the meaning of the input speech signal, unlike speech recognition which aims to produce verbatim transcripts. Advances in end-to-end (E2E) speech modeling have made it possible to train solely on semantic entities, which are far cheaper to collect than verbatim transcripts. We focus on this set prediction problem, where entity order is unspecified. Using two classes of E2E models, RNN transducers and attention based encoder-decoders, we show that these models work best when the training entity sequence is arranged in spoken order. To improve E2E SLU models when entity spoken order is unknown, we propose a novel data augmentation technique along with an implicit attention based alignment method to infer the spoken order. F1 scores significantly increased by more than 11% for RNN-T and about 2% for attention based encoder-decoder SLU models, outperforming previously reported results.
A Survey on Non-Autoregressive Generation for Neural Machine Translation and Beyond
Apr 20, 2022
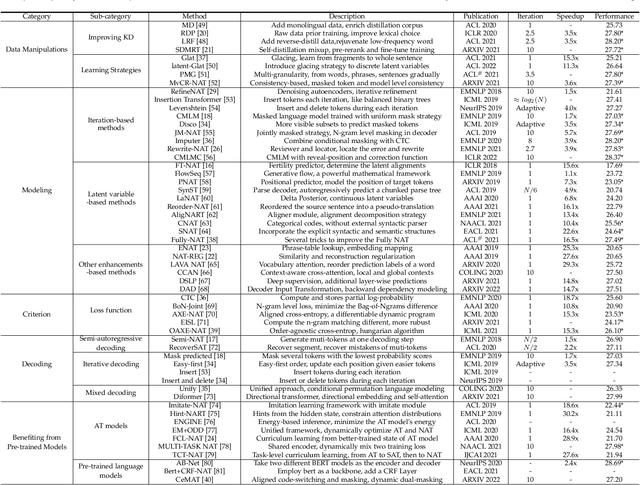
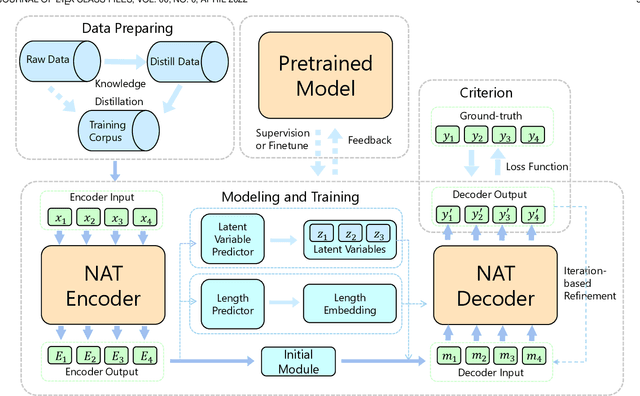
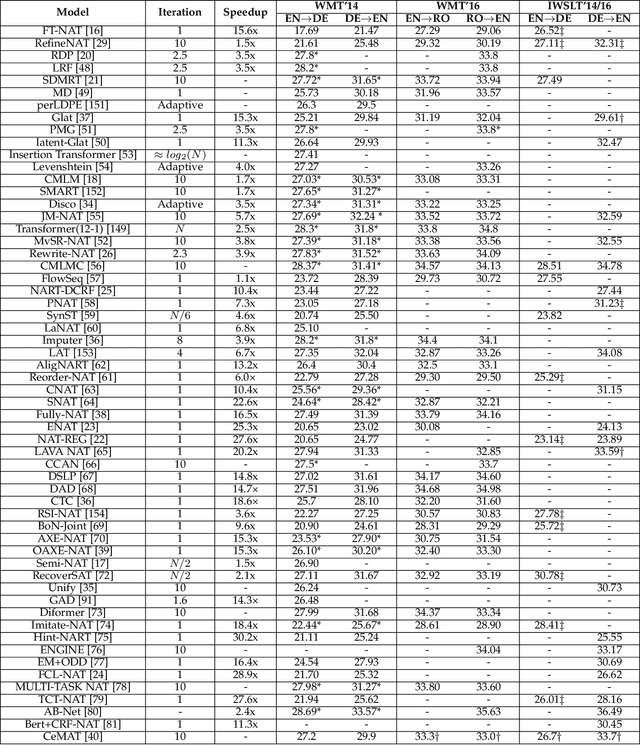
Non-autoregressive (NAR) generation, which is first proposed in neural machine translation (NMT) to speed up inference, has attracted much attention in both machine learning and natural language processing communities. While NAR generation can significantly accelerate inference speed for machine translation, the speedup comes at the cost of sacrificed translation accuracy compared to its counterpart, auto-regressive (AR) generation. In recent years, many new models and algorithms have been designed/proposed to bridge the accuracy gap between NAR generation and AR generation. In this paper, we conduct a systematic survey with comparisons and discussions of various non-autoregressive translation (NAT) models from different aspects. Specifically, we categorize the efforts of NAT into several groups, including data manipulation, modeling methods, training criterion, decoding algorithms, and the benefit from pre-trained models. Furthermore, we briefly review other applications of NAR models beyond machine translation, such as dialogue generation, text summarization, grammar error correction, semantic parsing, speech synthesis, and automatic speech recognition. In addition, we also discuss potential directions for future exploration, including releasing the dependency of KD, dynamic length prediction, pre-training for NAR, and wider applications, etc. We hope this survey can help researchers capture the latest progress in NAR generation, inspire the design of advanced NAR models and algorithms, and enable industry practitioners to choose appropriate solutions for their applications. The web page of this survey is at \url{https://github.com/LitterBrother-Xiao/Overview-of-Non-autoregressive-Applications}.
Closing the Gap between Single-User and Multi-User VoiceFilter-Lite
Feb 24, 2022
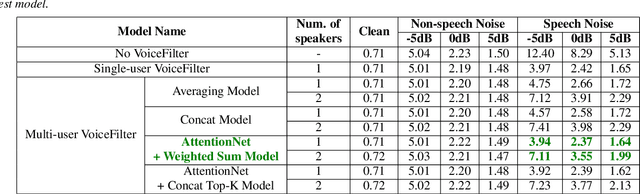
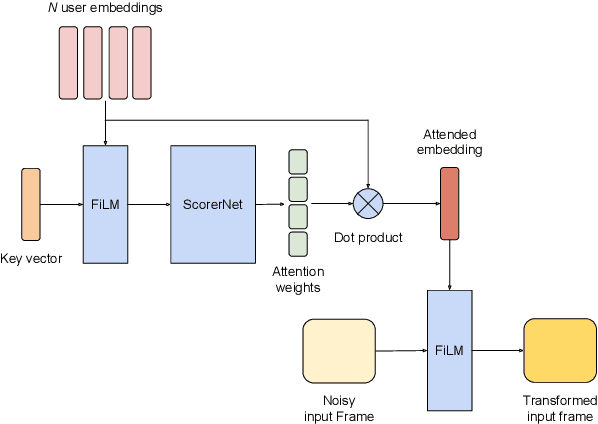
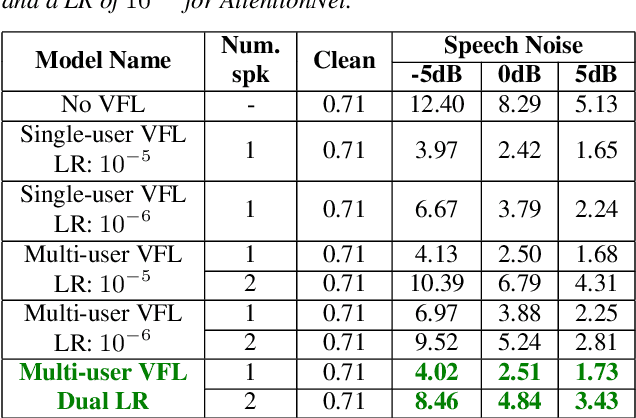
VoiceFilter-Lite is a speaker-conditioned voice separation model that plays a crucial role in improving speech recognition and speaker verification by suppressing overlapping speech from non-target speakers. However, one limitation of VoiceFilter-Lite, and other speaker-conditioned speech models in general, is that these models are usually limited to a single target speaker. This is undesirable as most smart home devices now support multiple enrolled users. In order to extend the benefits of personalization to multiple users, we previously developed an attention-based speaker selection mechanism and applied it to VoiceFilter-Lite. However, the original multi-user VoiceFilter-Lite model suffers from significant performance degradation compared with single-user models. In this paper, we devised a series of experiments to improve the multi-user VoiceFilter-Lite model. By incorporating a dual learning rate schedule and by using feature-wise linear modulation (FiLM) to condition the model with the attended speaker embedding, we successfully closed the performance gap between multi-user and single-user VoiceFilter-Lite models on single-speaker evaluations. At the same time, the new model can also be easily extended to support any number of users, and significantly outperforms our previously published model on multi-speaker evaluations.
Bridging the Gap Between Monaural Speech Enhancement and Recognition with Distortion-Independent Acoustic Modeling
Mar 13, 2019
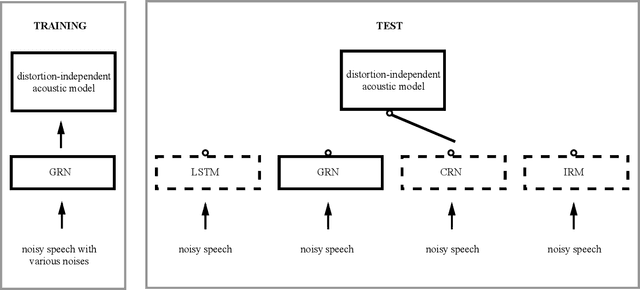
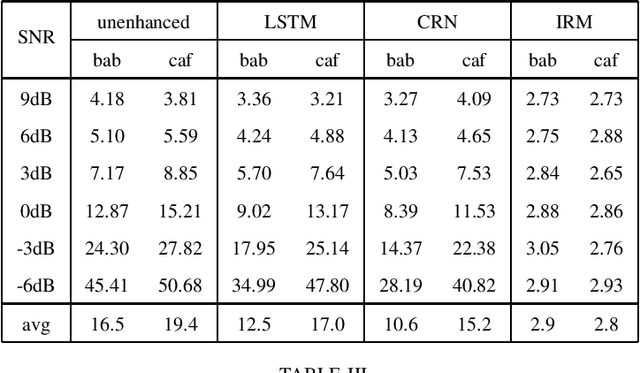
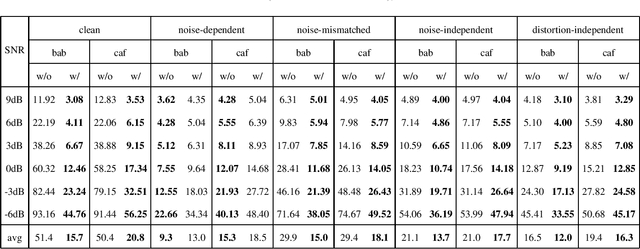
Monaural speech enhancement has made dramatic advances since the introduction of deep learning a few years ago. Although enhanced speech has been demonstrated to have better intelligibility and quality for human listeners, feeding it directly to automatic speech recognition (ASR) systems trained with noisy speech has not produced expected improvements in ASR performance. The lack of an enhancement benefit on recognition, or the gap between monaural speech enhancement and recognition, is often attributed to speech distortions introduced in the enhancement process. In this study, we analyze the distortion problem, compare different acoustic models, and investigate a distortion-independent training scheme for monaural speech recognition. Experimental results suggest that distortion-independent acoustic modeling is able to overcome the distortion problem. Such an acoustic model can also work with speech enhancement models different from the one used during training. Moreover, the models investigated in this paper outperform the previous best system on the CHiME-2 corpus.
CTC Variations Through New WFST Topologies
Oct 06, 2021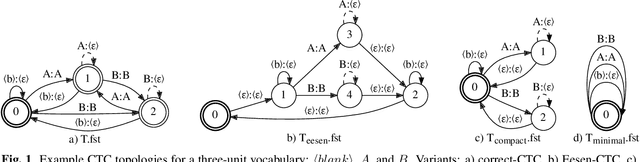
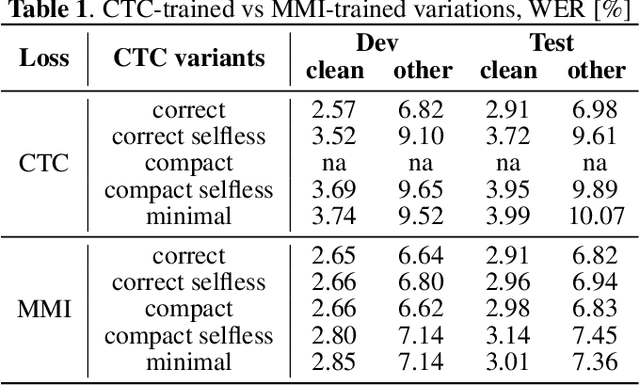
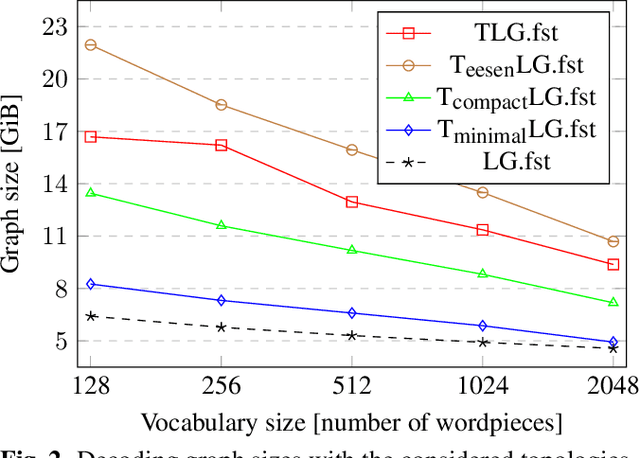
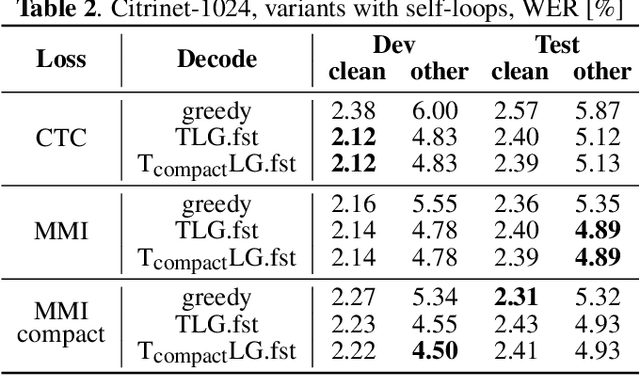
This paper presents novel Weighted Finite-State Transducer (WFST) topologies to implement Connectionist Temporal Classification (CTC)-like algorithms for automatic speech recognition. Three new CTC variants are proposed: (1) the "compact-CTC", in which direct transitions between units are replaced with <epsilon> back-off transitions; (2) the "minimal-CTC", that only adds <blank> self-loops when used in WFST-composition; and (3) "selfless-CTC", that disallows self-loop for non-blank units. The new CTC variants have several benefits, such as reducing decoding graph size and GPU memory required for training while keeping model accuracy.