 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlternating Weak Triphone/BPE Alignment Supervision from Hybrid Model Improves End-to-End ASR
Feb 23, 2024



In this paper, alternating weak triphone/BPE alignment supervision is proposed to improve end-to-end model training. Towards this end, triphone and BPE alignments are extracted using a pre-existing hybrid ASR system. Then, regularization effect is obtained by cross-entropy based intermediate auxiliary losses computed on such alignments at a mid-layer representation of the encoder for triphone alignments and at the encoder for BPE alignments. Weak supervision is achieved through strong label smoothing with parameter of 0.5. Experimental results on TED-LIUM 2 indicate that either triphone or BPE alignment based weak supervision improves ASR performance over standard CTC auxiliary loss. Moreover, their combination lowers the word error rate further. We also investigate the alternation of the two auxiliary tasks during model training, and additional performance gain is observed. Overall, the proposed techniques result in over 10% relative error rate reduction over a CTC-regularized baseline system.
Weak Alignment Supervision from Hybrid Model Improves End-to-end ASR
Nov 30, 2023



In this paper, we aim to create weak alignment supervision from an existing hybrid system to aid the end-to-end modeling of automatic speech recognition. Towards this end, we use the existing hybrid ASR system to produce triphone alignments of the training audios. We then create a cross-entropy loss at a certain layer of the encoder using the derived alignments. In contrast to the general one-hot cross-entropy losses, here we use a cross-entropy loss with a label smoothing parameter to regularize the supervision. As a comparison, we also conduct the experiments with one-hot cross-entropy losses and CTC losses with loss weighting. The results show that placing the weak alignment supervision with the label smoothing parameter of 0.5 at the third encoder layer outperforms the other two approaches and leads to about 5\% relative WER reduction on the TED-LIUM 2 dataset over the baseline. We see similar improvements when applying the method out-of-the-box on a Tagalog end-to-end ASR system.
Improving End-to-End Models for Set Prediction in Spoken Language Understanding
Jan 28, 2022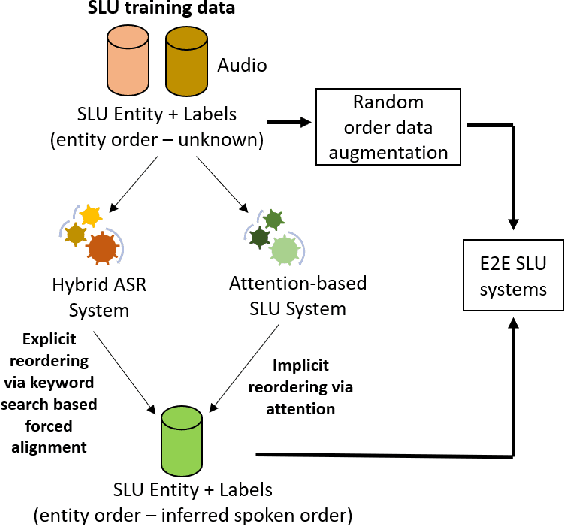

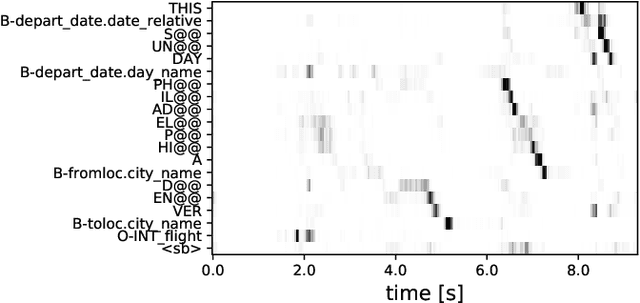
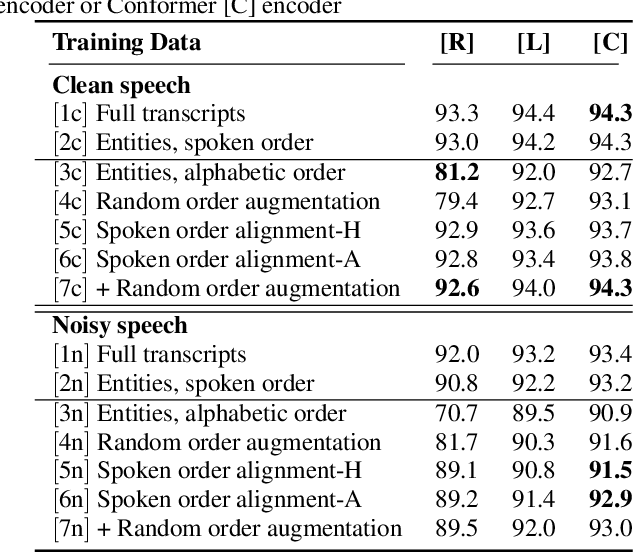
The goal of spoken language understanding (SLU) systems is to determine the meaning of the input speech signal, unlike speech recognition which aims to produce verbatim transcripts. Advances in end-to-end (E2E) speech modeling have made it possible to train solely on semantic entities, which are far cheaper to collect than verbatim transcripts. We focus on this set prediction problem, where entity order is unspecified. Using two classes of E2E models, RNN transducers and attention based encoder-decoders, we show that these models work best when the training entity sequence is arranged in spoken order. To improve E2E SLU models when entity spoken order is unknown, we propose a novel data augmentation technique along with an implicit attention based alignment method to infer the spoken order. F1 scores significantly increased by more than 11% for RNN-T and about 2% for attention based encoder-decoder SLU models, outperforming previously reported results.
Reducing Exposure Bias in Training Recurrent Neural Network Transducers
Aug 24, 2021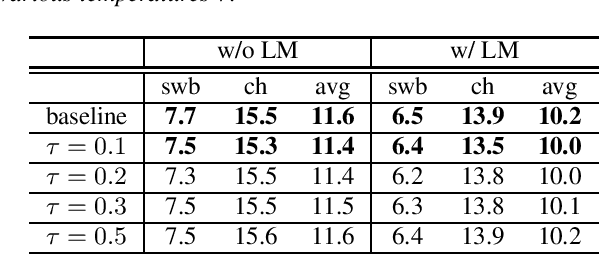
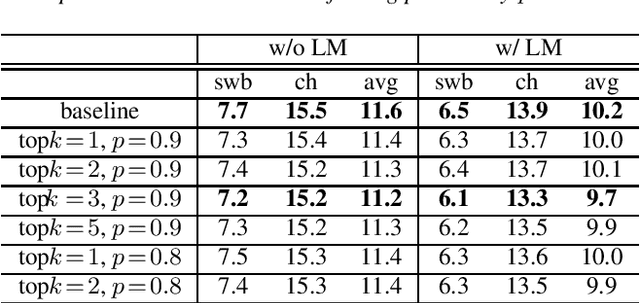
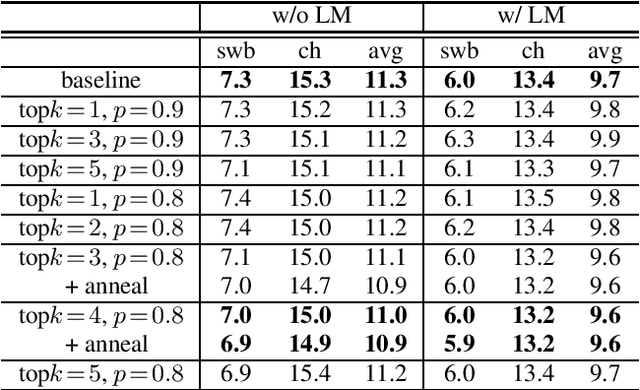
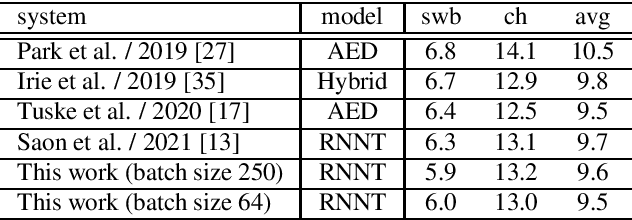
When recurrent neural network transducers (RNNTs) are trained using the typical maximum likelihood criterion, the prediction network is trained only on ground truth label sequences. This leads to a mismatch during inference, known as exposure bias, when the model must deal with label sequences containing errors. In this paper we investigate approaches to reducing exposure bias in training to improve the generalization of RNNT models for automatic speech recognition (ASR). A label-preserving input perturbation to the prediction network is introduced. The input token sequences are perturbed using SwitchOut and scheduled sampling based on an additional token language model. Experiments conducted on the 300-hour Switchboard dataset demonstrate their effectiveness. By reducing the exposure bias, we show that we can further improve the accuracy of a high-performance RNNT ASR model and obtain state-of-the-art results on the 300-hour Switchboard dataset.
End-to-end spoken language understanding using transformer networks and self-supervised pre-trained features
Nov 16, 2020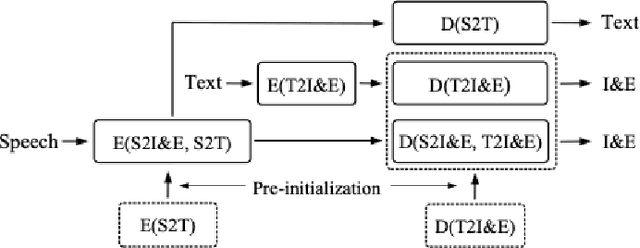
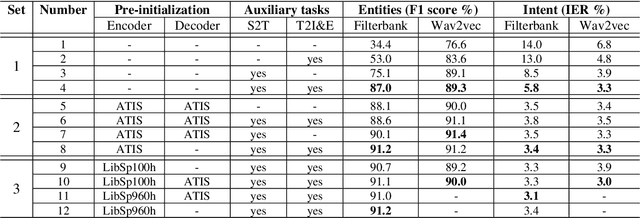


Transformer networks and self-supervised pre-training have consistently delivered state-of-art results in the field of natural language processing (NLP); however, their merits in the field of spoken language understanding (SLU) still need further investigation. In this paper we introduce a modular End-to-End (E2E) SLU transformer network based architecture which allows the use of self-supervised pre-trained acoustic features, pre-trained model initialization and multi-task training. Several SLU experiments for predicting intent and entity labels/values using the ATIS dataset are performed. These experiments investigate the interaction of pre-trained model initialization and multi-task training with either traditional filterbank or self-supervised pre-trained acoustic features. Results show not only that self-supervised pre-trained acoustic features outperform filterbank features in almost all the experiments, but also that when these features are used in combination with multi-task training, they almost eliminate the necessity of pre-trained model initialization.
English Broadcast News Speech Recognition by Humans and Machines
Apr 30, 2019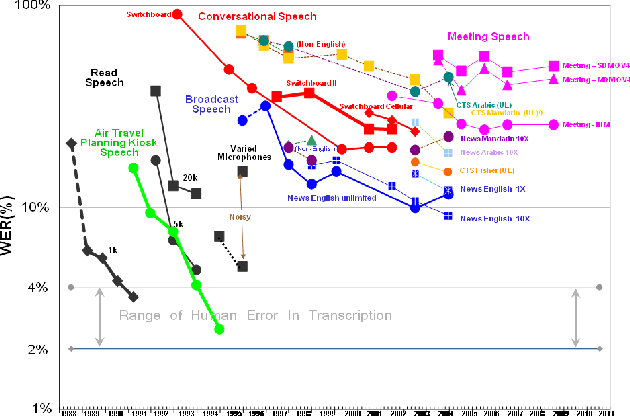
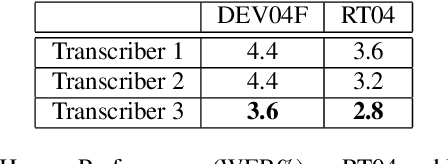


With recent advances in deep learning, considerable attention has been given to achieving automatic speech recognition performance close to human performance on tasks like conversational telephone speech (CTS) recognition. In this paper we evaluate the usefulness of these proposed techniques on broadcast news (BN), a similar challenging task. We also perform a set of recognition measurements to understand how close the achieved automatic speech recognition results are to human performance on this task. On two publicly available BN test sets, DEV04F and RT04, our speech recognition system using LSTM and residual network based acoustic models with a combination of n-gram and neural network language models performs at 6.5% and 5.9% word error rate. By achieving new performance milestones on these test sets, our experiments show that techniques developed on other related tasks, like CTS, can be transferred to achieve similar performance. In contrast, the best measured human recognition performance on these test sets is much lower, at 3.6% and 2.8% respectively, indicating that there is still room for new techniques and improvements in this space, to reach human performance levels.