 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Visualizing Deep Neural Networks for Speech Recognition with Learned Topographic Filter Maps
Dec 06, 2019
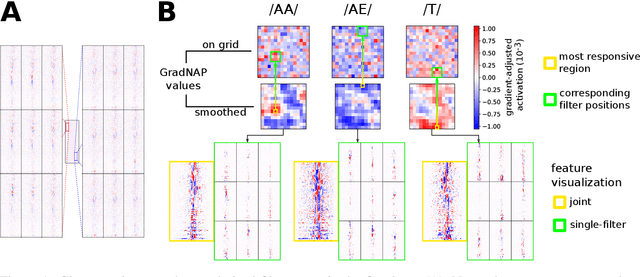
The uninformative ordering of artificial neurons in Deep Neural Networks complicates visualizing activations in deeper layers. This is one reason why the internal structure of such models is very unintuitive. In neuroscience, activity of real brains can be visualized by highlighting active regions. Inspired by those techniques, we train a convolutional speech recognition model, where filters are arranged in a 2D grid and neighboring filters are similar to each other. We show, how those topographic filter maps visualize artificial neuron activations more intuitively. Moreover, we investigate, whether this causes phoneme-responsive neurons to be grouped in certain regions of the topographic map.
End-to-end model for named entity recognition from speech without paired training data
Apr 02, 2022
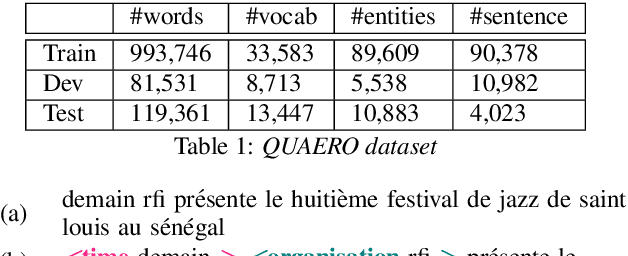


Recent works showed that end-to-end neural approaches tend to become very popular for spoken language understanding (SLU). Through the term end-to-end, one considers the use of a single model optimized to extract semantic information directly from the speech signal. A major issue for such models is the lack of paired audio and textual data with semantic annotation. In this paper, we propose an approach to build an end-to-end neural model to extract semantic information in a scenario in which zero paired audio data is available. Our approach is based on the use of an external model trained to generate a sequence of vectorial representations from text. These representations mimic the hidden representations that could be generated inside an end-to-end automatic speech recognition (ASR) model by processing a speech signal. An SLU neural module is then trained using these representations as input and the annotated text as output. Last, the SLU module replaces the top layers of the ASR model to achieve the construction of the end-to-end model. Our experiments on named entity recognition, carried out on the QUAERO corpus, show that this approach is very promising, getting better results than a comparable cascade approach or than the use of synthetic voices.
Memory Visualization for Gated Recurrent Neural Networks in Speech Recognition
Feb 27, 2017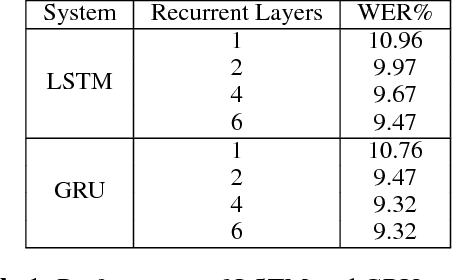
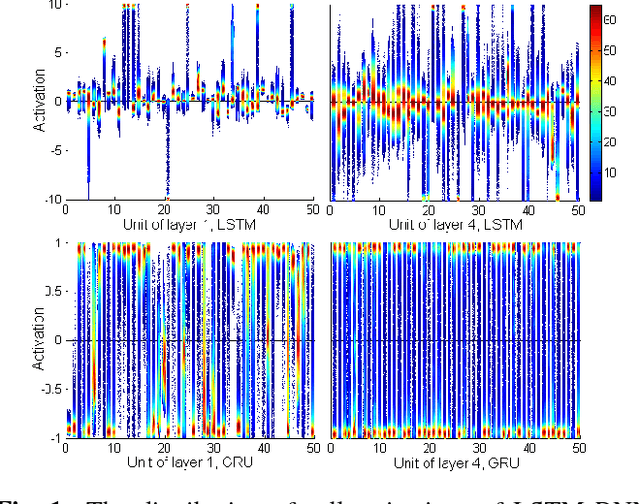
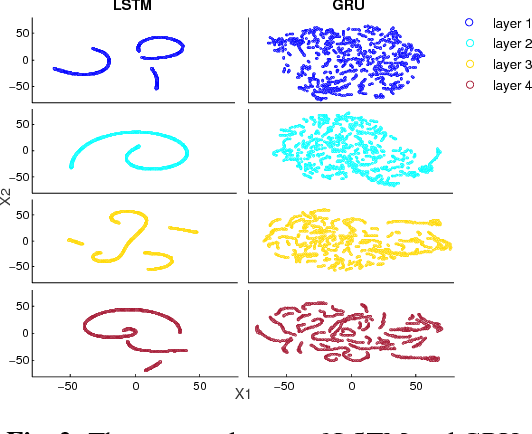
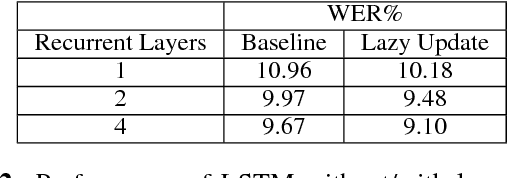
Recurrent neural networks (RNNs) have shown clear superiority in sequence modeling, particularly the ones with gated units, such as long short-term memory (LSTM) and gated recurrent unit (GRU). However, the dynamic properties behind the remarkable performance remain unclear in many applications, e.g., automatic speech recognition (ASR). This paper employs visualization techniques to study the behavior of LSTM and GRU when performing speech recognition tasks. Our experiments show some interesting patterns in the gated memory, and some of them have inspired simple yet effective modifications on the network structure. We report two of such modifications: (1) lazy cell update in LSTM, and (2) shortcut connections for residual learning. Both modifications lead to more comprehensible and powerful networks.
Synthetic Dataset Generation for Privacy-Preserving Machine Learning
Oct 10, 2022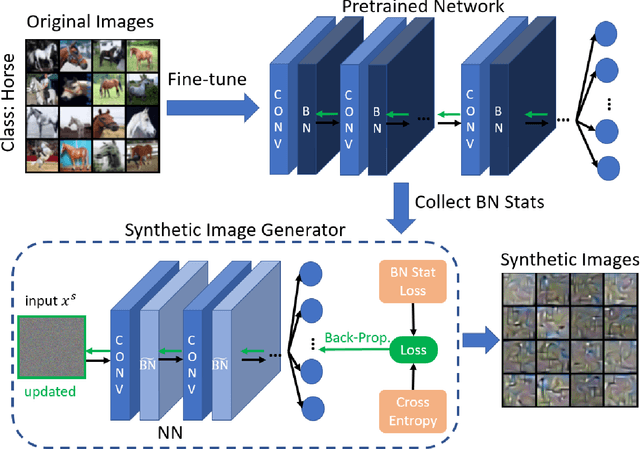



Machine Learning (ML) has achieved enormous success in solving a variety of problems in computer vision, speech recognition, object detection, to name a few. The principal reason for this success is the availability of huge datasets for training deep neural networks (DNNs). However, datasets cannot be publicly released if they contain sensitive information such as medical records, and data privacy becomes a major concern. Encryption methods could be a possible solution, however their deployment on ML applications seriously impacts classification accuracy and results in substantial computational overhead. Alternatively, obfuscation techniques could be used, but maintaining a good trade-off between visual privacy and accuracy is challenging. In this paper, we propose a method to generate secure synthetic datasets from the original private datasets. Given a network with Batch Normalization (BN) layers pretrained on the original dataset, we first record the class-wise BN layer statistics. Next, we generate the synthetic dataset by optimizing random noise such that the synthetic data match the layer-wise statistical distribution of original images. We evaluate our method on image classification datasets (CIFAR10, ImageNet) and show that synthetic data can be used in place of the original CIFAR10/ImageNet data for training networks from scratch, producing comparable classification performance. Further, to analyze visual privacy provided by our method, we use Image Quality Metrics and show high degree of visual dissimilarity between the original and synthetic images. Moreover, we show that our proposed method preserves data-privacy under various privacy-leakage attacks including Gradient Matching Attack, Model Memorization Attack, and GAN-based Attack.
An Investigation Into On-device Personalization of End-to-end Automatic Speech Recognition Models
Sep 14, 2019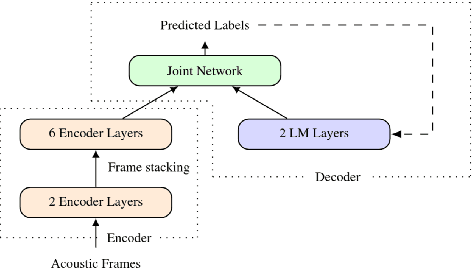
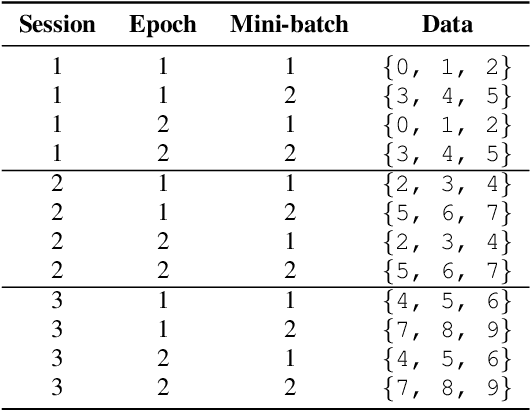
Speaker-independent speech recognition systems trained with data from many users are generally robust against speaker variability and work well for a large population of speakers. However, these systems do not always generalize well for users with very different speech characteristics. This issue can be addressed by building personalized systems that are designed to work well for each specific user. In this paper, we investigate the idea of securely training personalized end-to-end speech recognition models on mobile devices so that user data and models never leave the device and are never stored on a server. We study how the mobile training environment impacts performance by simulating on-device data consumption. We conduct experiments using data collected from speech impaired users for personalization. Our results show that personalization achieved 63.7\% relative word error rate reduction when trained in a server environment and 58.1% in a mobile environment. Moving to on-device personalization resulted in 18.7% performance degradation, in exchange for improved scalability and data privacy. To train the model on device, we split the gradient computation into two and achieved 45% memory reduction at the expense of 42% increase in training time.
Self-Supervised Attention Networks and Uncertainty Loss Weighting for Multi-Task Emotion Recognition on Vocal Bursts
Sep 27, 2022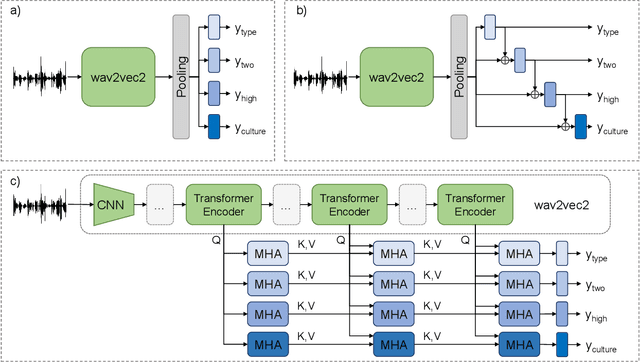
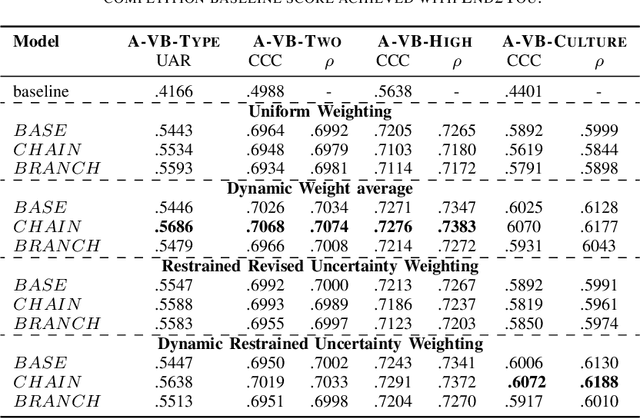

Vocal bursts play an important role in communicating affect, making them valuable for improving speech emotion recognition. Here, we present our approach for classifying vocal bursts and predicting their emotional significance in the ACII Affective Vocal Burst Workshop & Challenge 2022 (A-VB). We use a large self-supervised audio model as shared feature extractor and compare multiple architectures built on classifier chains and attention networks, combined with uncertainty loss weighting strategies. Our approach surpasses the challenge baseline by a wide margin on all four tasks.
Unified Streaming and Non-streaming Two-pass End-to-end Model for Speech Recognition
Dec 10, 2020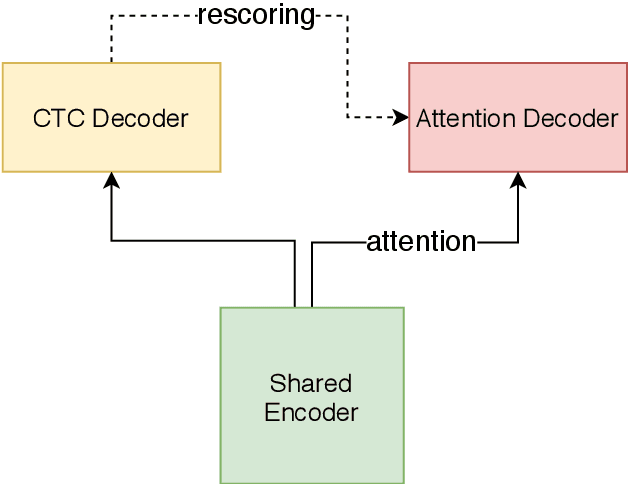

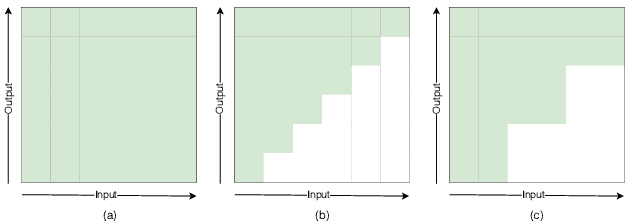
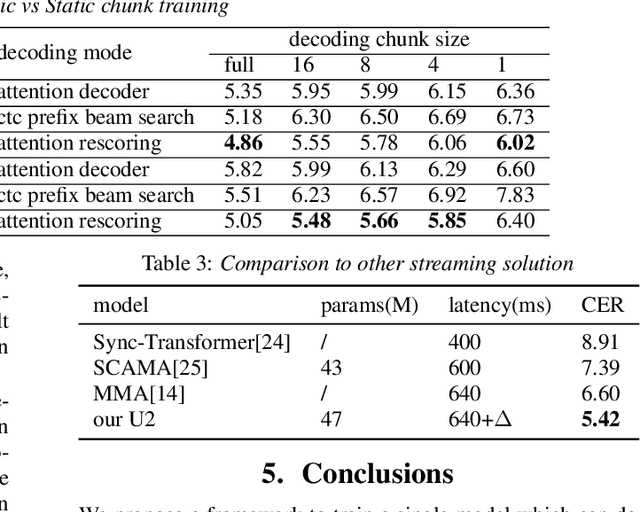
In this paper, we present a novel two-pass approach to unify streaming and non-streaming end-to-end (E2E) speech recognition in a single model. Our model adopts the hybrid CTC/attention architecture, in which the conformer layers in the encoder are modified. We propose a dynamic chunk-based attention strategy to allow arbitrary right context length. At inference time, the CTC decoder generates n-best hypotheses in a streaming way. The inference latency could be easily controlled by only changing the chunk size. The CTC hypotheses are then rescored by the attention decoder to get the final result. This efficient rescoring process causes very little sentence-level latency. Our experiments on the open 170-hour AISHELL-1 dataset show that, the proposed method can unify the streaming and non-streaming model simply and efficiently. On the AISHELL-1 test set, our unified model achieves 5.60% relative character error rate (CER) reduction in non-streaming ASR compared to a standard non-streaming transformer. The same model achieves 5.42% CER with 640ms latency in a streaming ASR system.
Emformer: Efficient Memory Transformer Based Acoustic Model For Low Latency Streaming Speech Recognition
Oct 29, 2020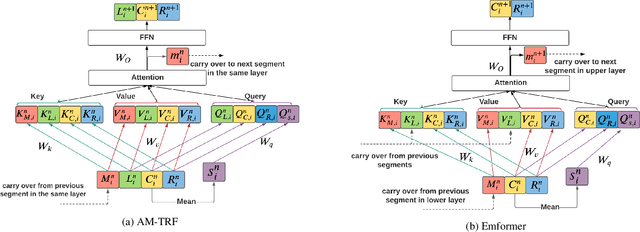
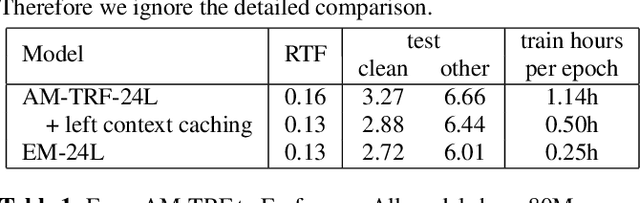
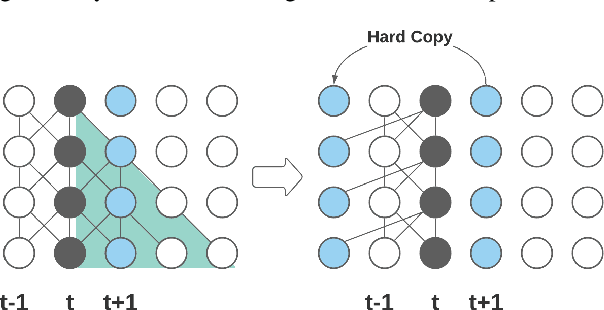
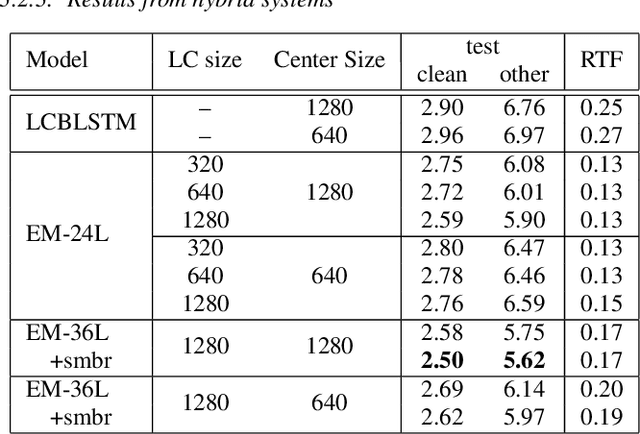
This paper proposes an efficient memory transformer Emformer for low latency streaming speech recognition. In Emformer, the long-range history context is distilled into an augmented memory bank to reduce self-attention's computation complexity. A cache mechanism saves the computation for the key and value in self-attention for the left context. Emformer applies a parallelized block processing in training to support low latency models. We carry out experiments on benchmark LibriSpeech data. Under average latency of 960 ms, Emformer gets WER $2.50\%$ on test-clean and $5.62\%$ on test-other. Comparing with a strong baseline augmented memory transformer (AM-TRF), Emformer gets $4.6$ folds training speedup and $18\%$ relative real-time factor (RTF) reduction in decoding with relative WER reduction $17\%$ on test-clean and $9\%$ on test-other. For a low latency scenario with an average latency of 80 ms, Emformer achieves WER $3.01\%$ on test-clean and $7.09\%$ on test-other. Comparing with the LSTM baseline with the same latency and model size, Emformer gets relative WER reduction $9\%$ and $16\%$ on test-clean and test-other, respectively.
Confidence Estimation for Attention-based Sequence-to-sequence Models for Speech Recognition
Oct 23, 2020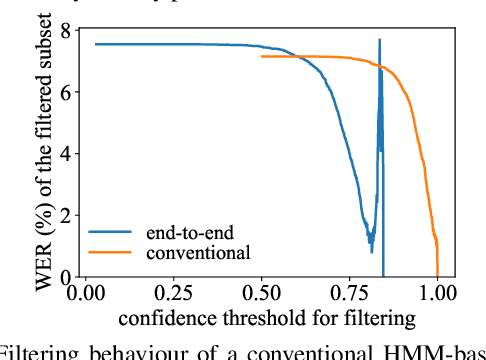
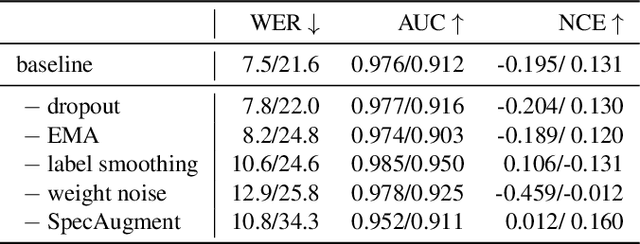
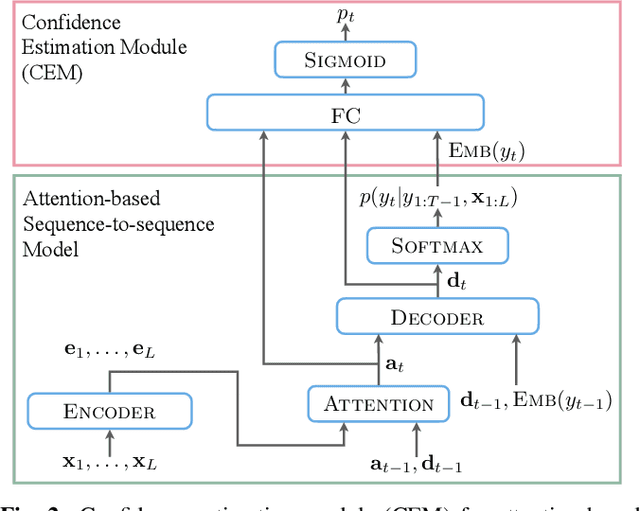
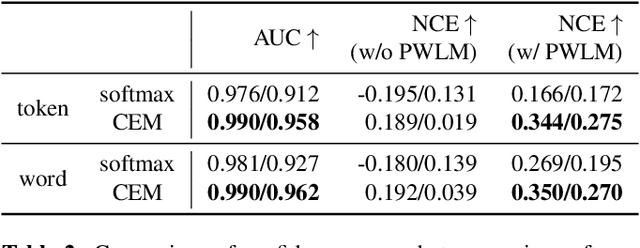
For various speech-related tasks, confidence scores from a speech recogniser are a useful measure to assess the quality of transcriptions. In traditional hidden Markov model-based automatic speech recognition (ASR) systems, confidence scores can be reliably obtained from word posteriors in decoding lattices. However, for an ASR system with an auto-regressive decoder, such as an attention-based sequence-to-sequence model, computing word posteriors is difficult. An obvious alternative is to use the decoder softmax probability as the model confidence. In this paper, we first examine how some commonly used regularisation methods influence the softmax-based confidence scores and study the overconfident behaviour of end-to-end models. Then we propose a lightweight and effective approach named confidence estimation module (CEM) on top of an existing end-to-end ASR model. Experiments on LibriSpeech show that CEM can mitigate the overconfidence problem and can produce more reliable confidence scores with and without shallow fusion of a language model. Further analysis shows that CEM generalises well to speech from a moderately mismatched domain and can potentially improve downstream tasks such as semi-supervised learning.
Improving speech recognition by revising gated recurrent units
Sep 29, 2017
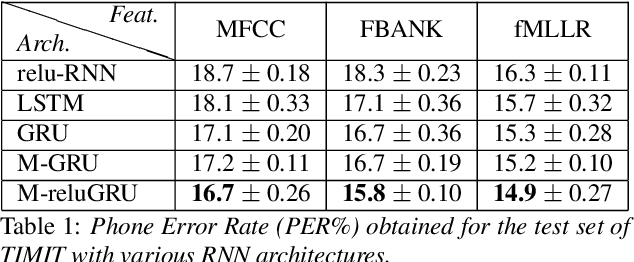
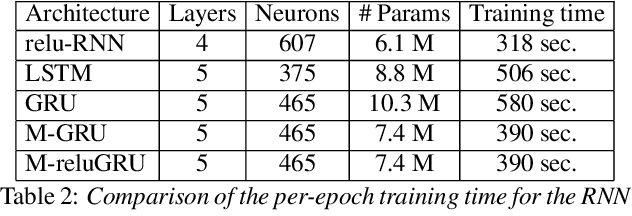
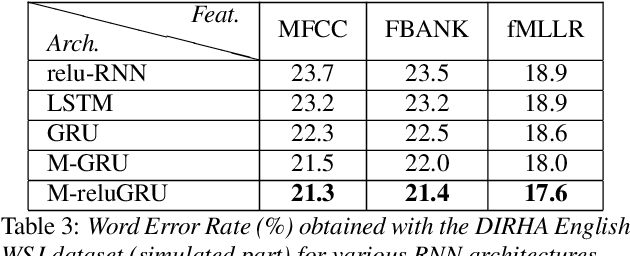
Speech recognition is largely taking advantage of deep learning, showing that substantial benefits can be obtained by modern Recurrent Neural Networks (RNNs). The most popular RNNs are Long Short-Term Memory (LSTMs), which typically reach state-of-the-art performance in many tasks thanks to their ability to learn long-term dependencies and robustness to vanishing gradients. Nevertheless, LSTMs have a rather complex design with three multiplicative gates, that might impair their efficient implementation. An attempt to simplify LSTMs has recently led to Gated Recurrent Units (GRUs), which are based on just two multiplicative gates. This paper builds on these efforts by further revising GRUs and proposing a simplified architecture potentially more suitable for speech recognition. The contribution of this work is two-fold. First, we suggest to remove the reset gate in the GRU design, resulting in a more efficient single-gate architecture. Second, we propose to replace tanh with ReLU activations in the state update equations. Results show that, in our implementation, the revised architecture reduces the per-epoch training time with more than 30% and consistently improves recognition performance across different tasks, input features, and noisy conditions when compared to a standard GRU.