 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSP-Podcast SER Challenge 2024: L'antenne du Ventoux Multimodal Self-Supervised Learning for Speech Emotion Recognition
Jul 08, 2024



In this work, we detail our submission to the 2024 edition of the MSP-Podcast Speech Emotion Recognition (SER) Challenge. This challenge is divided into two distinct tasks: Categorical Emotion Recognition and Emotional Attribute Prediction. We concentrated our efforts on Task 1, which involves the categorical classification of eight emotional states using data from the MSP-Podcast dataset. Our approach employs an ensemble of models, each trained independently and then fused at the score level using a Support Vector Machine (SVM) classifier. The models were trained using various strategies, including Self-Supervised Learning (SSL) fine-tuning across different modalities: speech alone, text alone, and a combined speech and text approach. This joint training methodology aims to enhance the system's ability to accurately classify emotional states. This joint training methodology aims to enhance the system's ability to accurately classify emotional states. Thus, the system obtained F1-macro of 0.35\% on development set.
Open-Source Conversational AI with SpeechBrain 1.0
Jul 02, 2024

SpeechBrain is an open-source Conversational AI toolkit based on PyTorch, focused particularly on speech processing tasks such as speech recognition, speech enhancement, speaker recognition, text-to-speech, and much more. It promotes transparency and replicability by releasing both the pre-trained models and the complete "recipes" of code and algorithms required for training them. This paper presents SpeechBrain 1.0, a significant milestone in the evolution of the toolkit, which now has over 200 recipes for speech, audio, and language processing tasks, and more than 100 models available on Hugging Face. SpeechBrain 1.0 introduces new technologies to support diverse learning modalities, Large Language Model (LLM) integration, and advanced decoding strategies, along with novel models, tasks, and modalities. It also includes a new benchmark repository, offering researchers a unified platform for evaluating models across diverse tasks
DASB -- Discrete Audio and Speech Benchmark
Jun 20, 2024



Discrete audio tokens have recently gained considerable attention for their potential to connect audio and language processing, enabling the creation of modern multimodal large language models. Ideal audio tokens must effectively preserve phonetic and semantic content along with paralinguistic information, speaker identity, and other details. While several types of audio tokens have been recently proposed, identifying the optimal tokenizer for various tasks is challenging due to the inconsistent evaluation settings in existing studies. To address this gap, we release the Discrete Audio and Speech Benchmark (DASB), a comprehensive leaderboard for benchmarking discrete audio tokens across a wide range of discriminative tasks, including speech recognition, speaker identification and verification, emotion recognition, keyword spotting, and intent classification, as well as generative tasks such as speech enhancement, separation, and text-to-speech. Our results show that, on average, semantic tokens outperform compression tokens across most discriminative and generative tasks. However, the performance gap between semantic tokens and standard continuous representations remains substantial, highlighting the need for further research in this field.
How Should We Extract Discrete Audio Tokens from Self-Supervised Models?
Jun 15, 2024



Discrete audio tokens have recently gained attention for their potential to bridge the gap between audio and language processing. Ideal audio tokens must preserve content, paralinguistic elements, speaker identity, and many other audio details. Current audio tokenization methods fall into two categories: Semantic tokens, acquired through quantization of Self-Supervised Learning (SSL) models, and Neural compression-based tokens (codecs). Although previous studies have benchmarked codec models to identify optimal configurations, the ideal setup for quantizing pretrained SSL models remains unclear. This paper explores the optimal configuration of semantic tokens across discriminative and generative tasks. We propose a scalable solution to train a universal vocoder across multiple SSL layers. Furthermore, an attention mechanism is employed to identify task-specific influential layers, enhancing the adaptability and performance of semantic tokens in diverse audio applications.
Enhancing expressivity transfer in textless speech-to-speech translation
Oct 11, 2023



Textless speech-to-speech translation systems are rapidly advancing, thanks to the integration of self-supervised learning techniques. However, existing state-of-the-art systems fall short when it comes to capturing and transferring expressivity accurately across different languages. Expressivity plays a vital role in conveying emotions, nuances, and cultural subtleties, thereby enhancing communication across diverse languages. To address this issue this study presents a novel method that operates at the discrete speech unit level and leverages multilingual emotion embeddings to capture language-agnostic information. Specifically, we demonstrate how these embeddings can be used to effectively predict the pitch and duration of speech units in the target language. Through objective and subjective experiments conducted on a French-to-English translation task, our findings highlight the superior expressivity transfer achieved by our approach compared to current state-of-the-art systems.
Direct Text to Speech Translation System using Acoustic Units
Sep 14, 2023This paper proposes a direct text to speech translation system using discrete acoustic units. This framework employs text in different source languages as input to generate speech in the target language without the need for text transcriptions in this language. Motivated by the success of acoustic units in previous works for direct speech to speech translation systems, we use the same pipeline to extract the acoustic units using a speech encoder combined with a clustering algorithm. Once units are obtained, an encoder-decoder architecture is trained to predict them. Then a vocoder generates speech from units. Our approach for direct text to speech translation was tested on the new CVSS corpus with two different text mBART models employed as initialisation. The systems presented report competitive performance for most of the language pairs evaluated. Besides, results show a remarkable improvement when initialising our proposed architecture with a model pre-trained with more languages.
Learning Multilingual Expressive Speech Representation for Prosody Prediction without Parallel Data
Jun 29, 2023



We propose a method for speech-to-speech emotionpreserving translation that operates at the level of discrete speech units. Our approach relies on the use of multilingual emotion embedding that can capture affective information in a language-independent manner. We show that this embedding can be used to predict the pitch and duration of speech units in a target language, allowing us to resynthesize the source speech signal with the same emotional content. We evaluate our approach to English and French speech signals and show that it outperforms a baseline method that does not use emotional information, including when the emotion embedding is extracted from a different language. Even if this preliminary study does not address directly the machine translation issue, our results demonstrate the effectiveness of our approach for cross-lingual emotion preservation in the context of speech resynthesis.
End-to-end model for named entity recognition from speech without paired training data
Apr 02, 2022


Recent works showed that end-to-end neural approaches tend to become very popular for spoken language understanding (SLU). Through the term end-to-end, one considers the use of a single model optimized to extract semantic information directly from the speech signal. A major issue for such models is the lack of paired audio and textual data with semantic annotation. In this paper, we propose an approach to build an end-to-end neural model to extract semantic information in a scenario in which zero paired audio data is available. Our approach is based on the use of an external model trained to generate a sequence of vectorial representations from text. These representations mimic the hidden representations that could be generated inside an end-to-end automatic speech recognition (ASR) model by processing a speech signal. An SLU neural module is then trained using these representations as input and the annotated text as output. Last, the SLU module replaces the top layers of the ASR model to achieve the construction of the end-to-end model. Our experiments on named entity recognition, carried out on the QUAERO corpus, show that this approach is very promising, getting better results than a comparable cascade approach or than the use of synthetic voices.
Study on the temporal pooling used in deep neural networks for speaker verification
May 10, 2021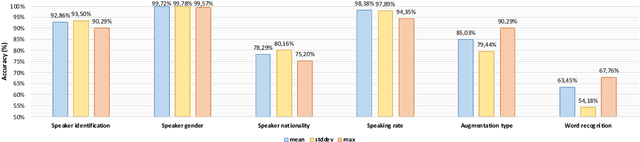
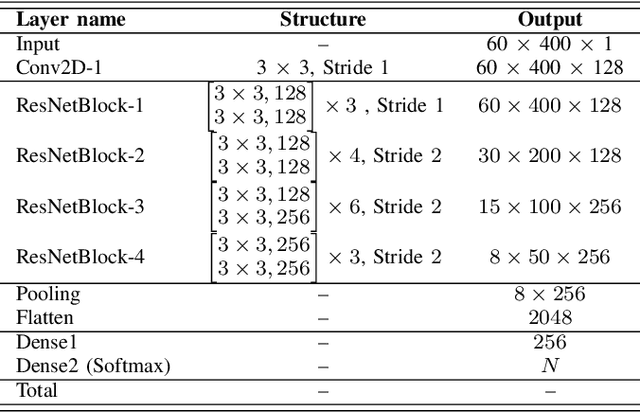
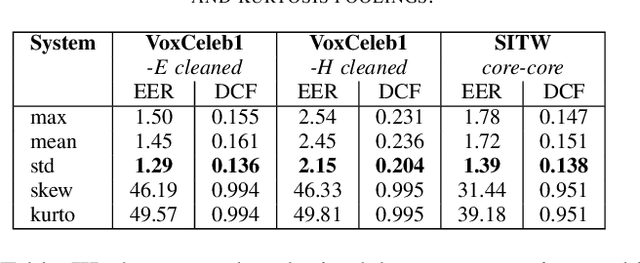
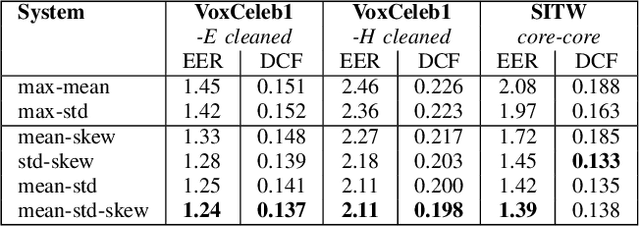
The x-vector architecture has recently achieved state-of-the-art results on the speaker verification task. This architecture incorporates a central layer, referred to as temporal pooling, which stacks statistical parameters of the acoustic frame distribution. This work proposes to highlight the significant effect of the temporal pooling content on the training dynamics and task performance. An evaluation with different pooling layers is conducted, that is, including different statistical measures of central tendency. Notably, 3rd and 4th moment-based statistics (skewness and kurtosis) are also tested to complete the usual mean and standard-deviation parameters. Our experiments show the influence of the pooling layer content in terms of speaker verification performance, but also for several classification tasks (speaker, channel or text related), and allow to better reveal the presence of external information to the speaker identity depending on the layer content.