 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Optimizing Speech Recognition For The Edge
Sep 26, 2019
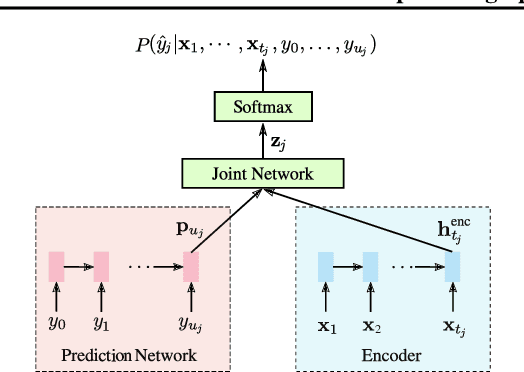
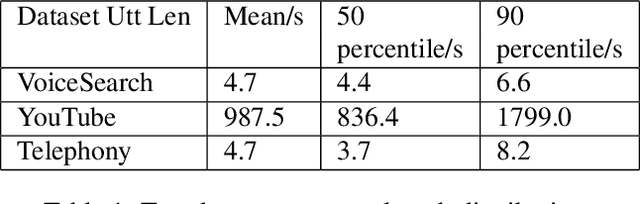
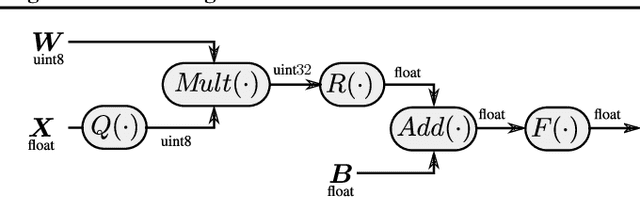
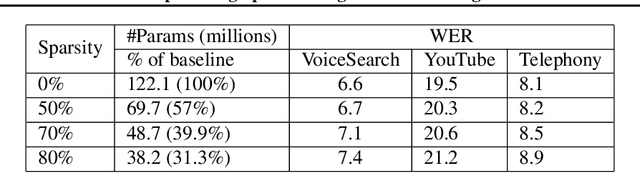
While most deployed speech recognition systems today still run on servers, we are in the midst of a transition towards deployments on edge devices. This leap to the edge is powered by the progression from traditional speech recognition pipelines to end-to-end (E2E) neural architectures, and the parallel development of more efficient neural network topologies and optimization techniques. Thus, we are now able to create highly accurate speech recognizers that are both small and fast enough to execute on typical mobile devices. In this paper, we begin with a baseline RNN-Transducer architecture comprised of Long Short-Term Memory (LSTM) layers. We then experiment with a variety of more computationally efficient layer types, as well as apply optimization techniques like neural connection pruning and parameter quantization to construct a small, high quality, on-device speech recognizer that is an order of magnitude smaller than the baseline system without any optimizations.
ElectrodeNet -- A Deep Learning Based Sound Coding Strategy for Cochlear Implants
May 26, 2023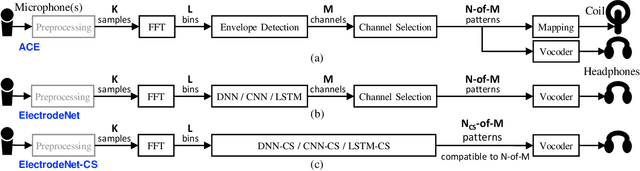
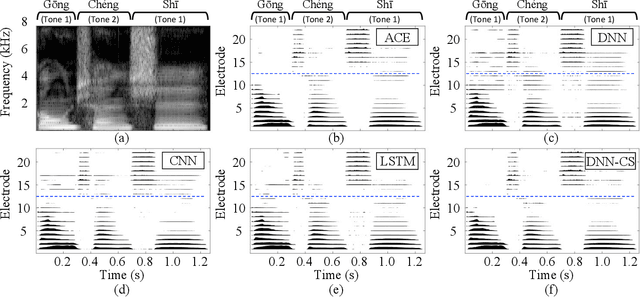
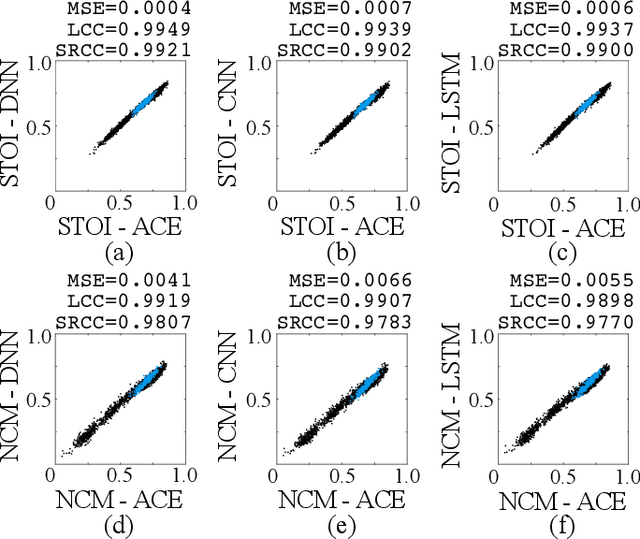
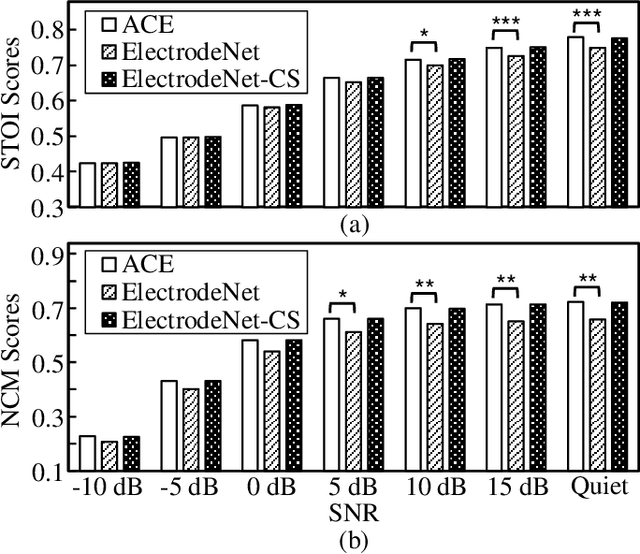
ElectrodeNet, a deep learning based sound coding strategy for the cochlear implant (CI), is proposed to emulate the advanced combination encoder (ACE) strategy by replacing the conventional envelope detection using various artificial neural networks. The extended ElectrodeNet-CS strategy further incorporates the channel selection (CS). Network models of deep neural network (DNN), convolutional neural network (CNN), and long short-term memory (LSTM) were trained using the Fast Fourier Transformed bins and channel envelopes obtained from the processing of clean speech by the ACE strategy. Objective speech understanding using short-time objective intelligibility (STOI) and normalized covariance metric (NCM) was estimated for ElectrodeNet using CI simulations. Sentence recognition tests for vocoded Mandarin speech were conducted with normal-hearing listeners. DNN, CNN, and LSTM based ElectrodeNets exhibited strong correlations to ACE in objective and subjective scores using mean squared error (MSE), linear correlation coefficient (LCC) and Spearman's rank correlation coefficient (SRCC). The ElectrodeNet-CS strategy was capable of producing N-of-M compatible electrode patterns using a modified DNN network to embed maxima selection, and to perform in similar or even slightly higher average in STOI and sentence recognition compared to ACE. The methods and findings demonstrated the feasibility and potential of using deep learning in CI coding strategy.
Speech Pattern based Black-box Model Watermarking for Automatic Speech Recognition
Oct 19, 2021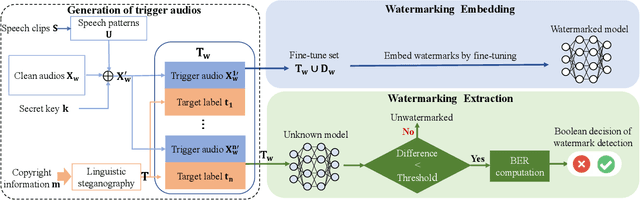

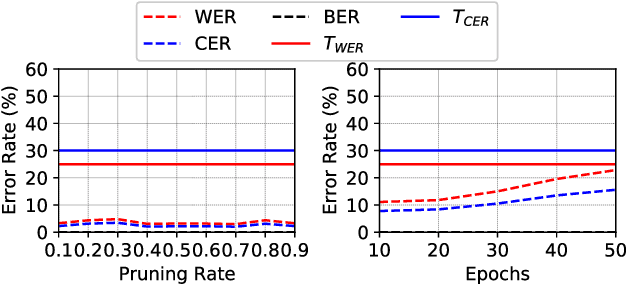

As an effective method for intellectual property (IP) protection, model watermarking technology has been applied on a wide variety of deep neural networks (DNN), including speech classification models. However, how to design a black-box watermarking scheme for automatic speech recognition (ASR) models is still an unsolved problem, which is a significant demand for protecting remote ASR Application Programming Interface (API) deployed in cloud servers. Due to conditional independence assumption and label-detection-based evasion attack risk of ASR models, the black-box model watermarking scheme for speech classification models cannot apply to ASR models. In this paper, we propose the first black-box model watermarking framework for protecting the IP of ASR models. Specifically, we synthesize trigger audios by spreading the speech clips of model owners over the entire input audios and labeling the trigger audios with the stego texts, which hides the authorship information with linguistic steganography. Experiments on the state-of-the-art open-source ASR system DeepSpeech demonstrate the feasibility of the proposed watermarking scheme, which is robust against five kinds of attacks and has little impact on accuracy.
EasyASR: A Distributed Machine Learning Platform for End-to-end Automatic Speech Recognition
Sep 14, 2020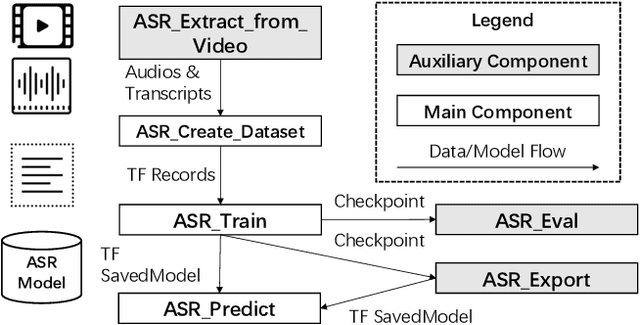
We present EasyASR, a distributed machine learning platform for training and serving large-scale Automatic Speech Recognition (ASR) models, as well as collecting and processing audio data at scale. Our platform is built upon the Machine Learning Platform for AI of Alibaba Cloud. Its main functionality is to support efficient learning and inference for end-to-end ASR models on distributed GPU clusters. It allows users to learn ASR models with either pre-defined or user-customized network architectures via simple user interface. On EasyASR, we have produced state-of-the-art results over several public datasets for Mandarin speech recognition.
Mondegreen: A Post-Processing Solution to Speech Recognition Error Correction for Voice Search Queries
May 20, 2021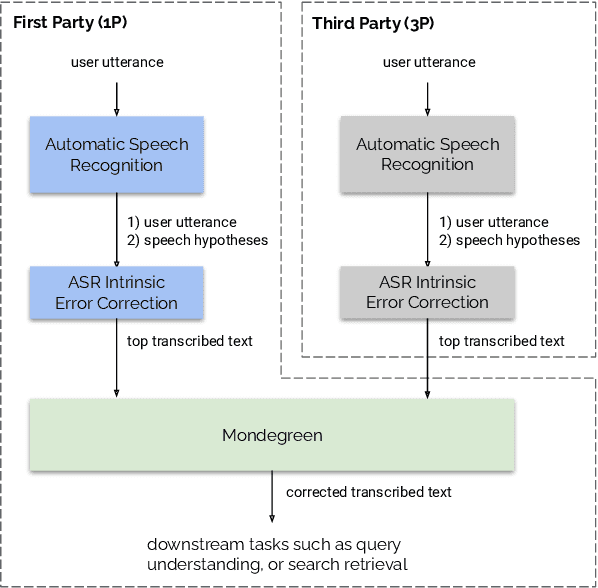
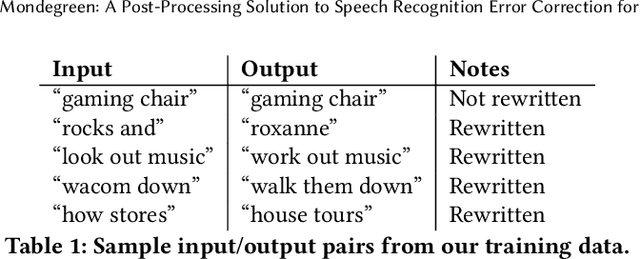
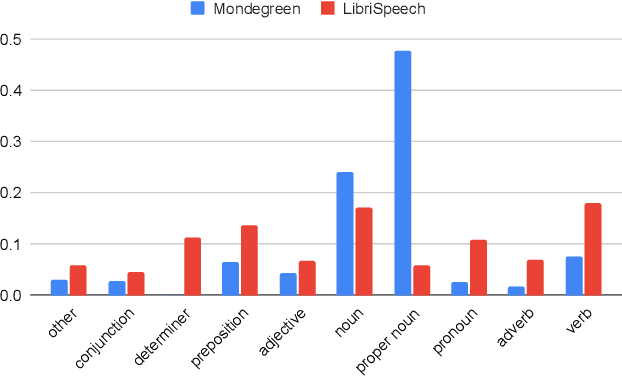
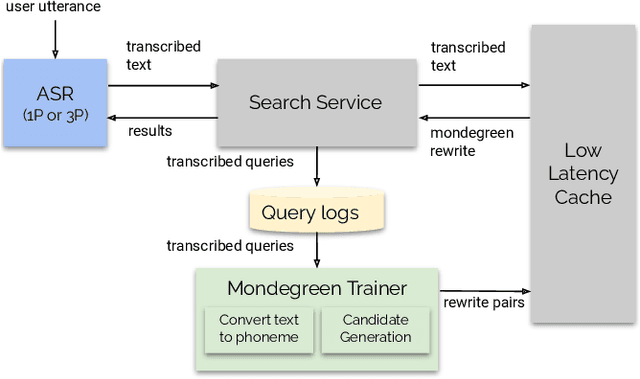
As more and more online search queries come from voice, automatic speech recognition becomes a key component to deliver relevant search results. Errors introduced by automatic speech recognition (ASR) lead to irrelevant search results returned to the user, thus causing user dissatisfaction. In this paper, we introduce an approach, Mondegreen, to correct voice queries in text space without depending on audio signals, which may not always be available due to system constraints or privacy or bandwidth (for example, some ASR systems run on-device) considerations. We focus on voice queries transcribed via several proprietary commercial ASR systems. These queries come from users making internet, or online service search queries. We first present an analysis showing how different the language distribution coming from user voice queries is from that in traditional text corpora used to train off-the-shelf ASR systems. We then demonstrate that Mondegreen can achieve significant improvements in increased user interaction by correcting user voice queries in one of the largest search systems in Google. Finally, we see Mondegreen as complementing existing highly-optimized production ASR systems, which may not be frequently retrained and thus lag behind due to vocabulary drifts.
A practical framework for multi-domain speech recognition and an instance sampling method to neural language modeling
Mar 09, 2022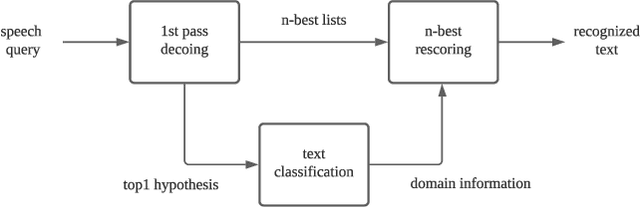

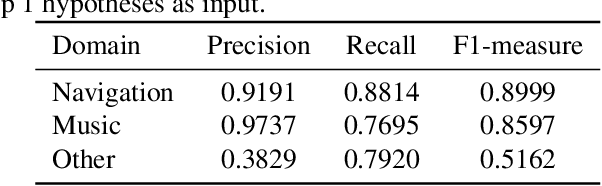
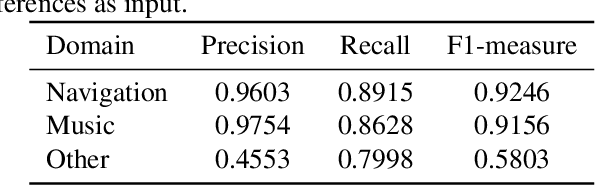
Automatic speech recognition (ASR) systems used on smart phones or vehicles are usually required to process speech queries from very different domains. In such situations, a vanilla ASR system usually fails to perform well on every domain. This paper proposes a multi-domain ASR framework for Tencent Map, a navigation app used on smart phones and in-vehicle infotainment systems. The proposed framework consists of three core parts: a basic ASR module to generate n-best lists of a speech query, a text classification module to determine which domain the speech query belongs to, and a reranking module to rescore n-best lists using domain-specific language models. In addition, an instance sampling based method to training neural network language models (NNLMs) is proposed to address the data imbalance problem in multi-domain ASR. In experiments, the proposed framework was evaluated on navigation domain and music domain, since navigating and playing music are two main features of Tencent Map. Compared to a general ASR system, the proposed framework achieves a relative 13% $\sim$ 22% character error rate reduction on several test sets collected from Tencent Map and our in-car voice assistant.
VoiceFilter-Lite: Streaming Targeted Voice Separation for On-Device Speech Recognition
Sep 09, 2020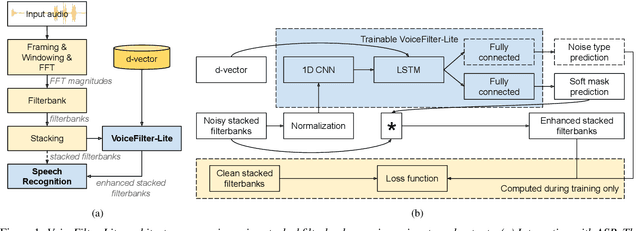

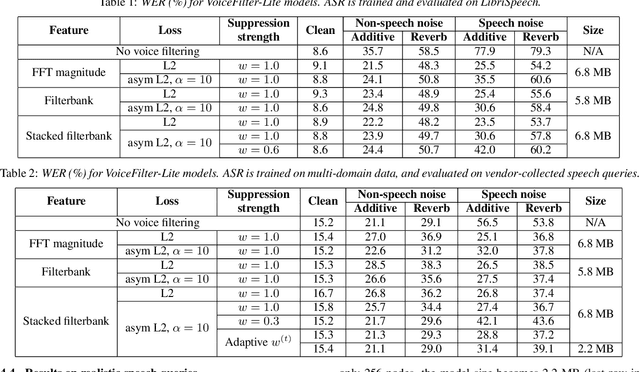
We introduce VoiceFilter-Lite, a single-channel source separation model that runs on the device to preserve only the speech signals from a target user, as part of a streaming speech recognition system. Delivering such a model presents numerous challenges: It should improve the performance when the input signal consists of overlapped speech, and must not hurt the speech recognition performance under all other acoustic conditions. Besides, this model must be tiny, fast, and perform inference in a streaming fashion, in order to have minimal impact on CPU, memory, battery and latency. We propose novel techniques to meet these multi-faceted requirements, including using a new asymmetric loss, and adopting adaptive runtime suppression strength. We also show that such a model can be quantized as a 8-bit integer model and run in realtime.
Dynamic Acoustic Unit Augmentation With BPE-Dropout for Low-Resource End-to-End Speech Recognition
Mar 12, 2021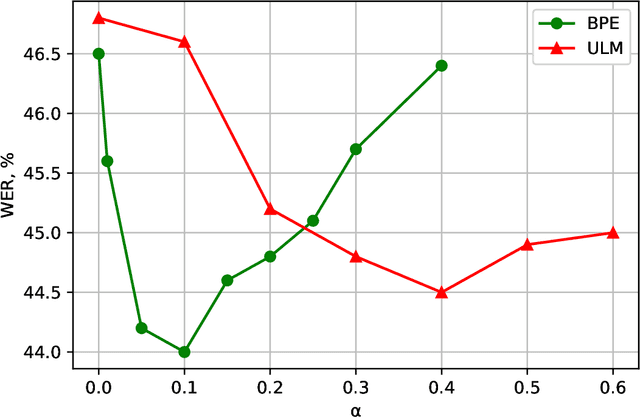
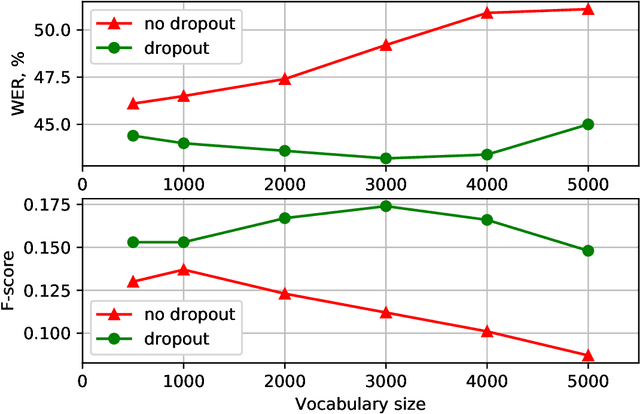
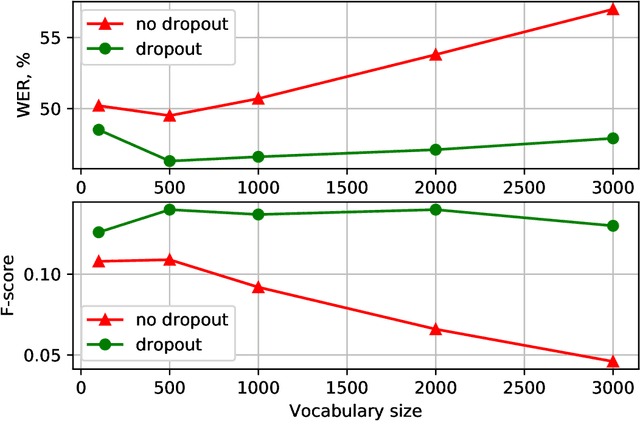
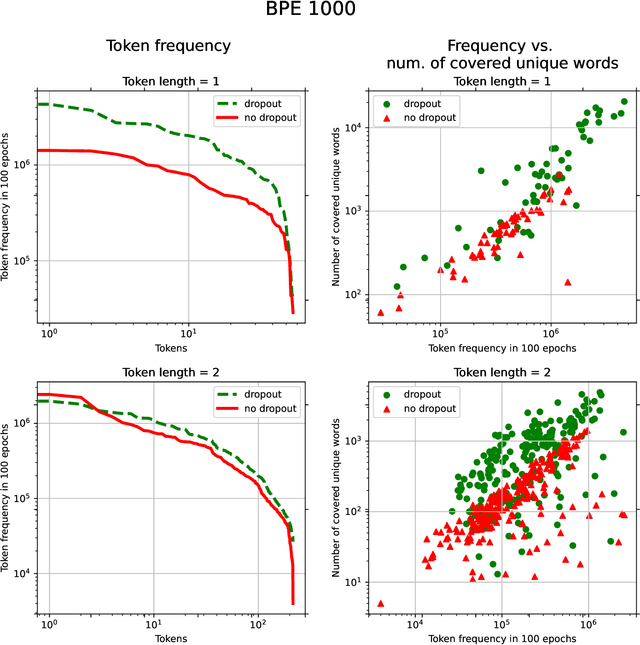
With the rapid development of speech assistants, adapting server-intended automatic speech recognition (ASR) solutions to a direct device has become crucial. Researchers and industry prefer to use end-to-end ASR systems for on-device speech recognition tasks. This is because end-to-end systems can be made resource-efficient while maintaining a higher quality compared to hybrid systems. However, building end-to-end models requires a significant amount of speech data. Another challenging task associated with speech assistants is personalization, which mainly lies in handling out-of-vocabulary (OOV) words. In this work, we consider building an effective end-to-end ASR system in low-resource setups with a high OOV rate, embodied in Babel Turkish and Babel Georgian tasks. To address the aforementioned problems, we propose a method of dynamic acoustic unit augmentation based on the BPE-dropout technique. It non-deterministically tokenizes utterances to extend the token's contexts and to regularize their distribution for the model's recognition of unseen words. It also reduces the need for optimal subword vocabulary size search. The technique provides a steady improvement in regular and personalized (OOV-oriented) speech recognition tasks (at least 6% relative WER and 25% relative F-score) at no additional computational cost. Owing to the use of BPE-dropout, our monolingual Turkish Conformer established a competitive result with 22.2% character error rate (CER) and 38.9% word error rate (WER), which is close to the best published multilingual system.
Fusing Wav2vec2.0 and BERT into End-to-end Model for Low-resource Speech Recognition
Jan 17, 2021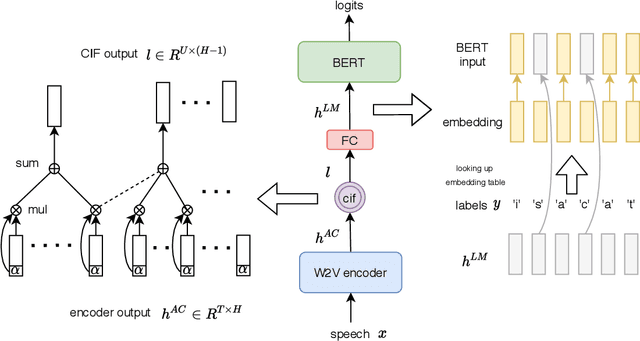
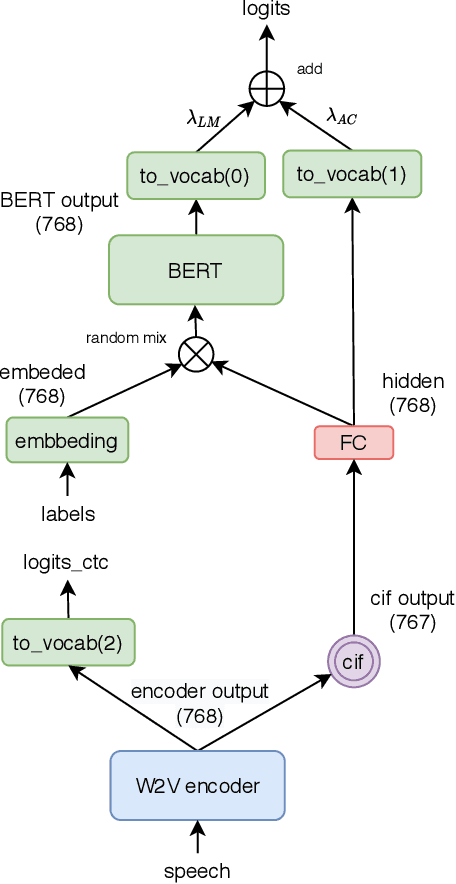
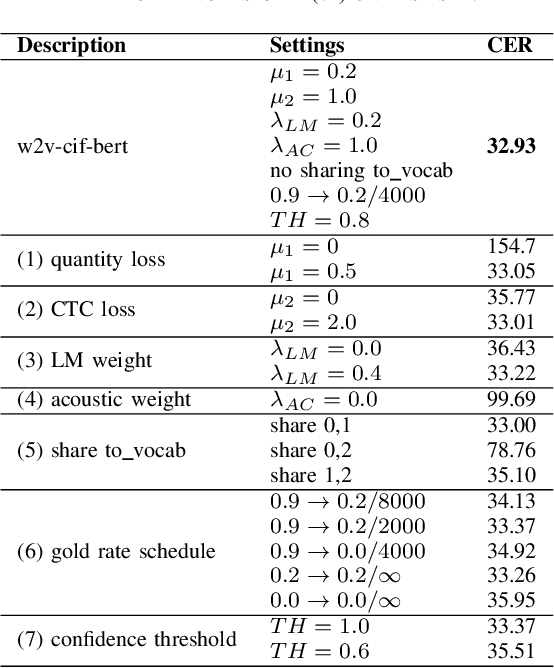
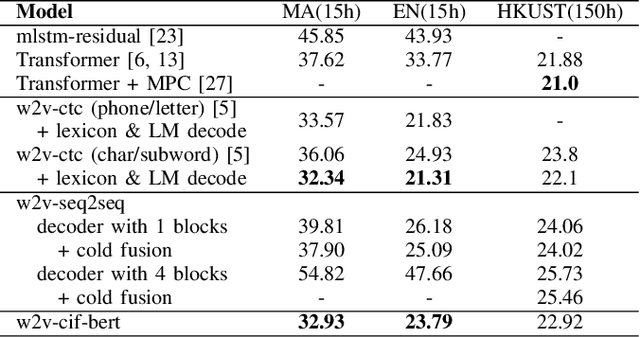
Self-supervised acoustic pre-training has achieved impressive results on low-resource speech recognition tasks. It indicates that the pretrain-and-finetune paradigm is a promising direction. In this work, we propose an end-to-end model for the low-resource speech recognition, which fuses a pre-trained audio encoder (wav2vec2.0) and a pre-trained text decoder (BERT). The two modules are connected by a linear attention mechanism without parameters. A fully connected layer is introduced for hidden mapping between speech and language modalities. Besides, we design an effective fine-tuning strategy to preserve and utilize the text context modeling ability of the pre-trained decoder. Armed with this strategy, our model exhibits distinct faster convergence and better performance. Our model achieves approaching recognition performance in CALLHOME corpus (15h) as the SOTA pipeline modeling.
Exploring CTC Based End-to-End Techniques for Myanmar Speech Recognition
May 14, 2021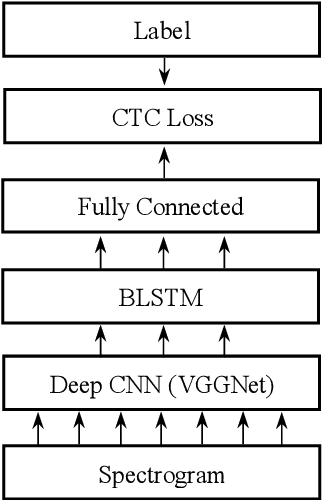
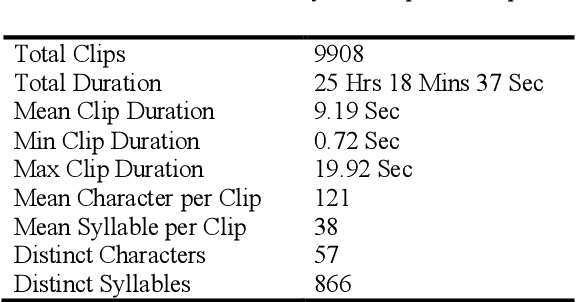
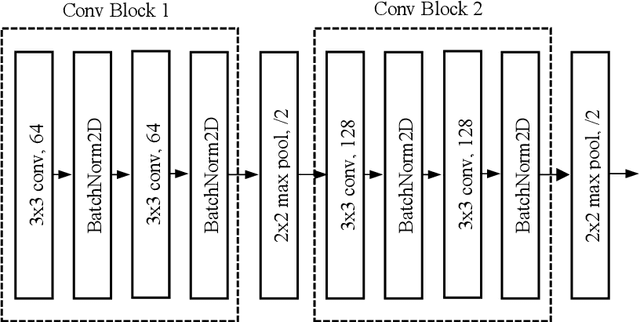
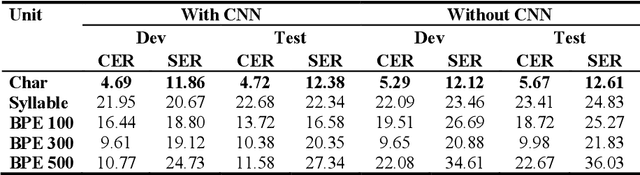
In this work, we explore a Connectionist Temporal Classification (CTC) based end-to-end Automatic Speech Recognition (ASR) model for the Myanmar language. A series of experiments is presented on the topology of the model in which the convolutional layers are added and dropped, different depths of bidirectional long short-term memory (BLSTM) layers are used and different label encoding methods are investigated. The experiments are carried out in low-resource scenarios using our recorded Myanmar speech corpus of nearly 26 hours. The best model achieves character error rate (CER) of 4.72% and syllable error rate (SER) of 12.38% on the test set.
* This is a preprint of the chapter: Chit K.M.M., Lin L.L., Exploring CTC Based End-To-End Techniques for Myanmar Speech Recognition, published in Advances in Intelligent Systems and Computing, vol 1324, edited by Vasant P., Zelinka I., Weber GW., 2021, Springer, Cham reproduced with permission of Springer. The final authenticated version is available at https://doi.org/10.1007/978-3-030-68154-8_87