 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Deep Learning Enabled Semantic Communications with Speech Recognition and Synthesis
May 09, 2022
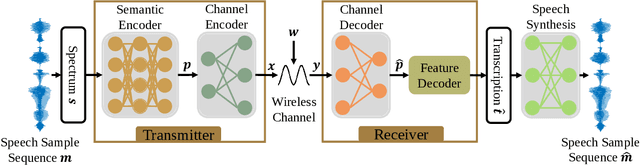
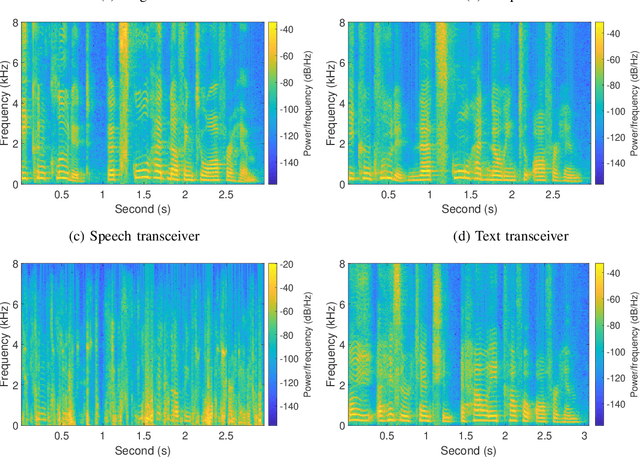
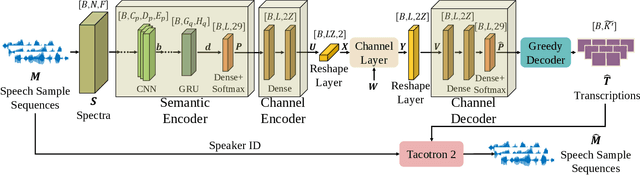
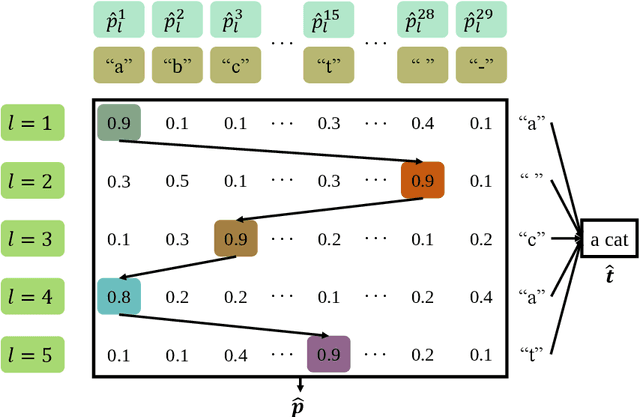
In this paper, we develop a deep learning based semantic communication system for speech transmission, named DeepSC-ST. We take the speech recognition and speech synthesis as the transmission tasks of the communication system, respectively. First, the speech recognition-related semantic features are extracted for transmission by a joint semantic-channel encoder and the text is recovered at the receiver based on the received semantic features, which significantly reduces the required amount of data transmission without performance degradation. Then, we perform speech synthesis at the receiver, which dedicates to re-generate the speech signals by feeding the recognized text transcription into a neural network based speech synthesis module. To enable the DeepSC-ST adaptive to dynamic channel environments, we identify a robust model to cope with different channel conditions. According to the simulation results, the proposed DeepSC-ST significantly outperforms conventional communication systems, especially in the low signal-to-noise ratio (SNR) regime. A demonstration is further developed as a proof-of-concept of the DeepSC-ST.
DisfluencyFixer: A tool to enhance Language Learning through Speech To Speech Disfluency Correction
May 26, 2023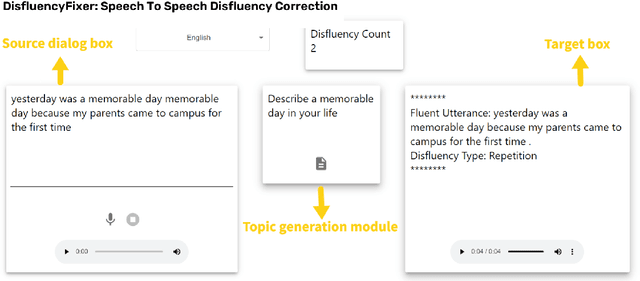
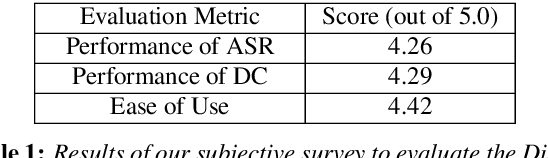
Conversational speech often consists of deviations from the speech plan, producing disfluent utterances that affect downstream NLP tasks. Removing these disfluencies is necessary to create fluent and coherent speech. This paper presents DisfluencyFixer, a tool that performs speech-to-speech disfluency correction in English and Hindi using a pipeline of Automatic Speech Recognition (ASR), Disfluency Correction (DC) and Text-To-Speech (TTS) models. Our proposed system removes disfluencies from input speech and returns fluent speech as output along with its transcript, disfluency type and total disfluency count in source utterance, providing a one-stop destination for language learners to improve the fluency of their speech. We evaluate the performance of our tool subjectively and receive scores of 4.26, 4.29 and 4.42 out of 5 in ASR performance, DC performance and ease-of-use of the system. Our tool can be accessed openly at the following link.
Improved DeepFake Detection Using Whisper Features
Jun 02, 2023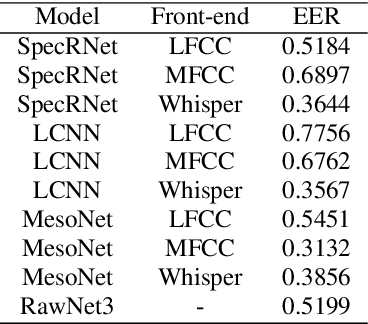
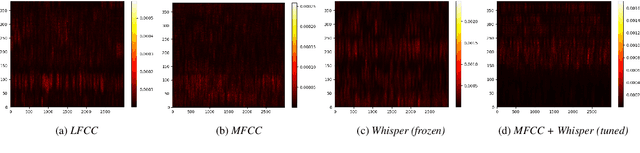

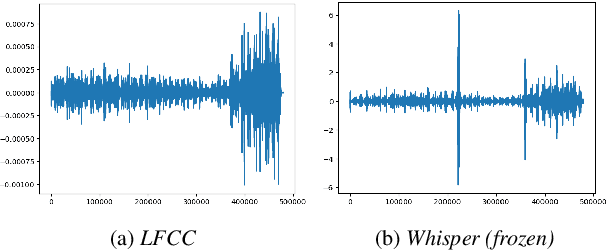
With a recent influx of voice generation methods, the threat introduced by audio DeepFake (DF) is ever-increasing. Several different detection methods have been presented as a countermeasure. Many methods are based on so-called front-ends, which, by transforming the raw audio, emphasize features crucial for assessing the genuineness of the audio sample. Our contribution contains investigating the influence of the state-of-the-art Whisper automatic speech recognition model as a DF detection front-end. We compare various combinations of Whisper and well-established front-ends by training 3 detection models (LCNN, SpecRNet, and MesoNet) on a widely used ASVspoof 2021 DF dataset and later evaluating them on the DF In-The-Wild dataset. We show that using Whisper-based features improves the detection for each model and outperforms recent results on the In-The-Wild dataset by reducing Equal Error Rate by 21%.
Can Contextual Biasing Remain Effective with Whisper and GPT-2?
Jun 02, 2023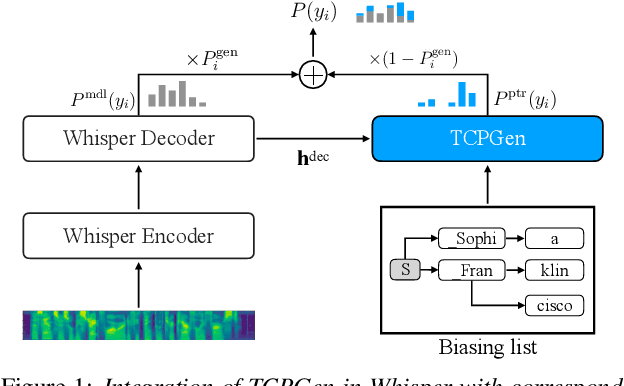
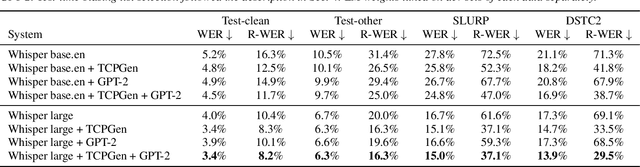


End-to-end automatic speech recognition (ASR) and large language models, such as Whisper and GPT-2, have recently been scaled to use vast amounts of training data. Despite the large amount of training data, infrequent content words that occur in a particular task may still exhibit poor ASR performance, with contextual biasing a possible remedy. This paper investigates the effectiveness of neural contextual biasing for Whisper combined with GPT-2. Specifically, this paper proposes integrating an adapted tree-constrained pointer generator (TCPGen) component for Whisper and a dedicated training scheme to dynamically adjust the final output without modifying any Whisper model parameters. Experiments across three datasets show a considerable reduction in errors on biasing words with a biasing list of 1000 words. Contextual biasing was more effective when applied to domain-specific data and can boost the performance of Whisper and GPT-2 without losing their generality.
Master-ASR: Achieving Multilingual Scalability and Low-Resource Adaptation in ASR with Modular Learning
Jun 23, 2023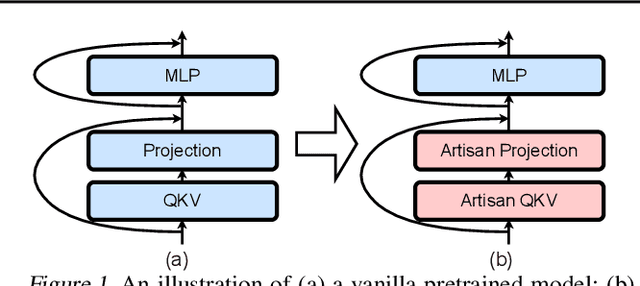
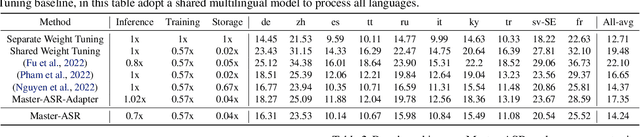
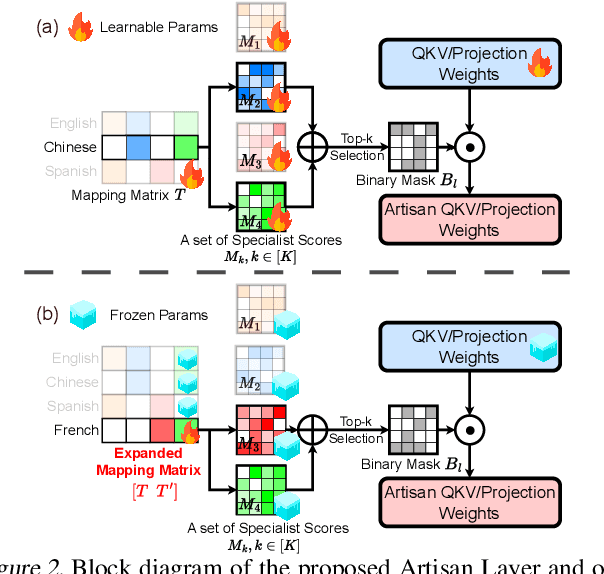
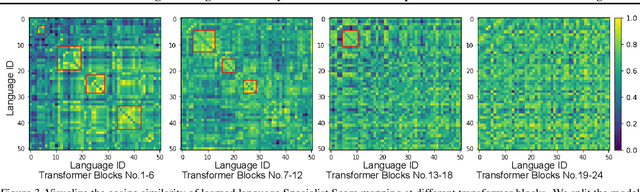
Despite the impressive performance recently achieved by automatic speech recognition (ASR), we observe two primary challenges that hinder its broader applications: (1) The difficulty of introducing scalability into the model to support more languages with limited training, inference, and storage overhead; (2) The low-resource adaptation ability that enables effective low-resource adaptation while avoiding over-fitting and catastrophic forgetting issues. Inspired by recent findings, we hypothesize that we can address the above challenges with modules widely shared across languages. To this end, we propose an ASR framework, dubbed \METHODNS, that, \textit{for the first time}, simultaneously achieves strong multilingual scalability and low-resource adaptation ability thanks to its modularize-then-assemble strategy. Specifically, \METHOD learns a small set of generalizable sub-modules and adaptively assembles them for different languages to reduce the multilingual overhead and enable effective knowledge transfer for low-resource adaptation. Extensive experiments and visualizations demonstrate that \METHOD can effectively discover language similarity and improve multilingual and low-resource ASR performance over state-of-the-art (SOTA) methods, e.g., under multilingual-ASR, our framework achieves a 0.13$\sim$2.41 lower character error rate (CER) with 30\% smaller inference overhead over SOTA solutions on multilingual ASR and a comparable CER, with nearly 50 times fewer trainable parameters over SOTA solutions on low-resource tuning, respectively.
Align With Purpose: Optimize Desired Properties in CTC Models with a General Plug-and-Play Framework
Jul 06, 2023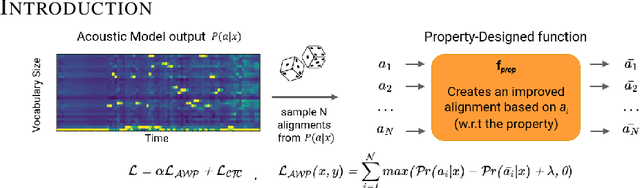

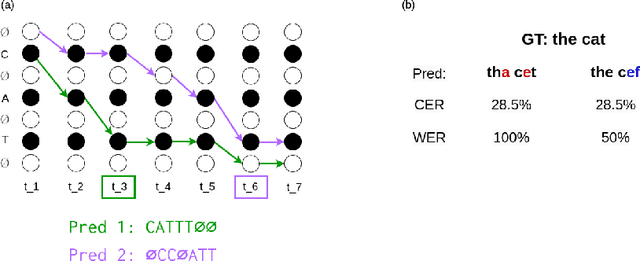
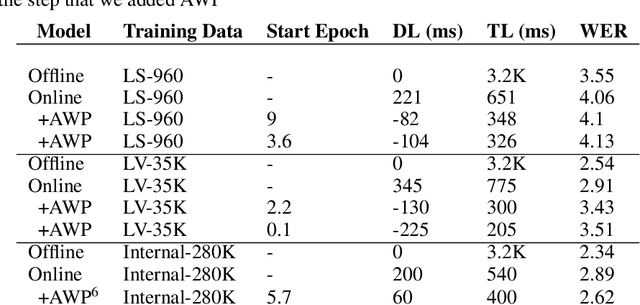
Connectionist Temporal Classification (CTC) is a widely used criterion for training supervised sequence-to-sequence (seq2seq) models. It enables learning the relations between input and output sequences, termed alignments, by marginalizing over perfect alignments (that yield the ground truth), at the expense of imperfect alignments. This binary differentiation of perfect and imperfect alignments falls short of capturing other essential alignment properties that hold significance in other real-world applications. Here we propose $\textit{Align With Purpose}$, a $\textbf{general Plug-and-Play framework}$ for enhancing a desired property in models trained with the CTC criterion. We do that by complementing the CTC with an additional loss term that prioritizes alignments according to a desired property. Our method does not require any intervention in the CTC loss function, enables easy optimization of a variety of properties, and allows differentiation between both perfect and imperfect alignments. We apply our framework in the domain of Automatic Speech Recognition (ASR) and show its generality in terms of property selection, architectural choice, and scale of training dataset (up to 280,000 hours). To demonstrate the effectiveness of our framework, we apply it to two unrelated properties: emission time and word error rate (WER). For the former, we report an improvement of up to 570ms in latency optimization with a minor reduction in WER, and for the latter, we report a relative improvement of 4.5% WER over the baseline models. To the best of our knowledge, these applications have never been demonstrated to work on a scale of data as large as ours. Notably, our method can be implemented using only a few lines of code, and can be extended to other alignment-free loss functions and to domains other than ASR.
Unified End-to-End Speech Recognition and Endpointing for Fast and Efficient Speech Systems
Nov 01, 2022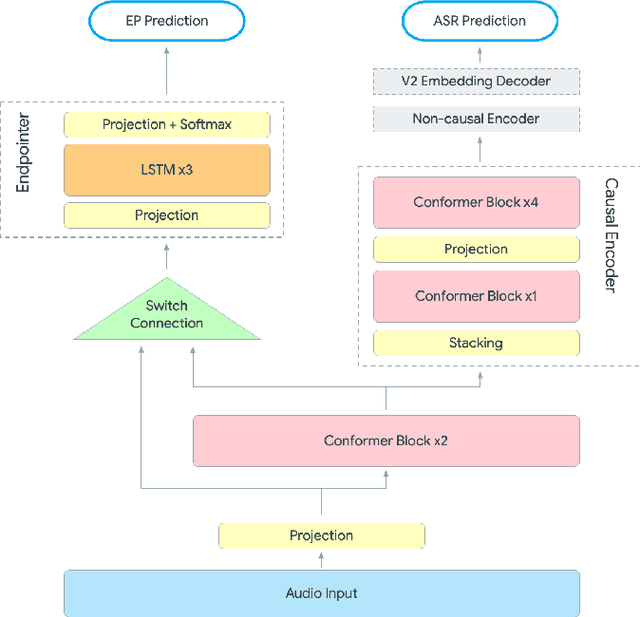
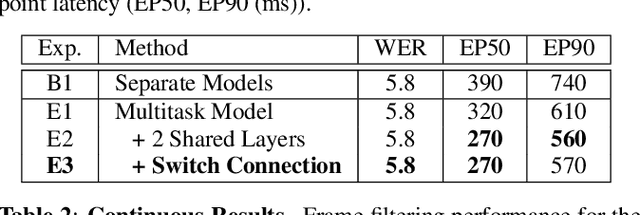
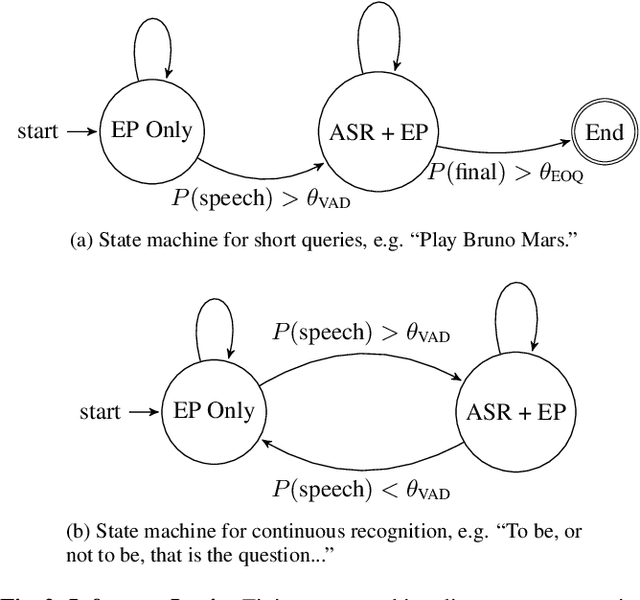
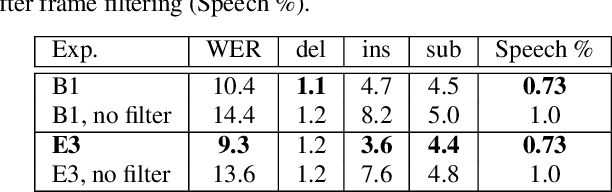
Automatic speech recognition (ASR) systems typically rely on an external endpointer (EP) model to identify speech boundaries. In this work, we propose a method to jointly train the ASR and EP tasks in a single end-to-end (E2E) multitask model, improving EP quality by optionally leveraging information from the ASR audio encoder. We introduce a "switch" connection, which trains the EP to consume either the audio frames directly or low-level latent representations from the ASR model. This results in a single E2E model that can be used during inference to perform frame filtering at low cost, and also make high quality end-of-query (EOQ) predictions based on ongoing ASR computation. We present results on a voice search test set showing that, compared to separate single-task models, this approach reduces median endpoint latency by 120 ms (30.8% reduction), and 90th percentile latency by 170 ms (23.0% reduction), without regressing word error rate. For continuous recognition, WER improves by 10.6% (relative).
End-to-End Integration of Speech Recognition, Dereverberation, Beamforming, and Self-Supervised Learning Representation
Oct 19, 2022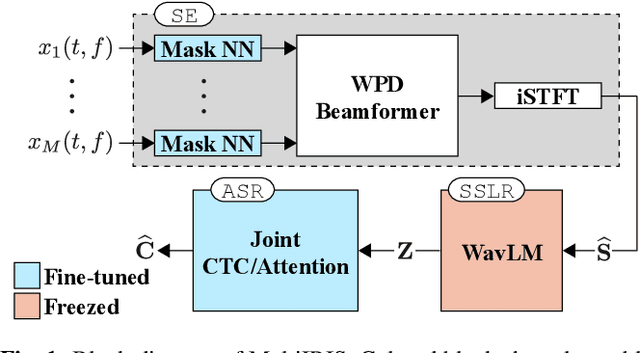
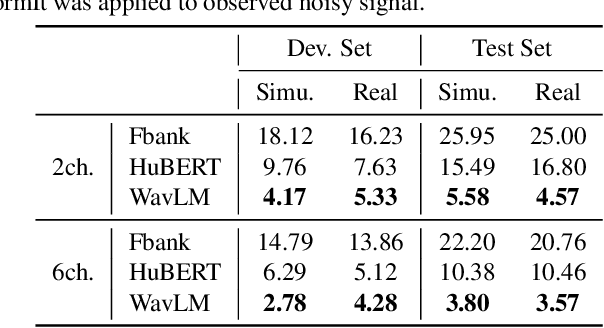
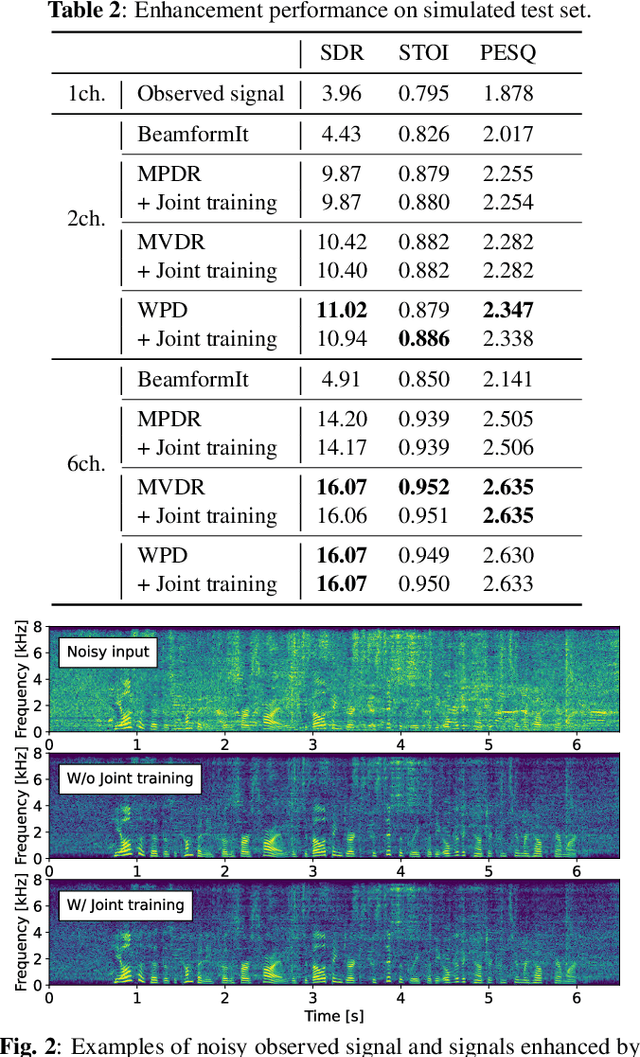
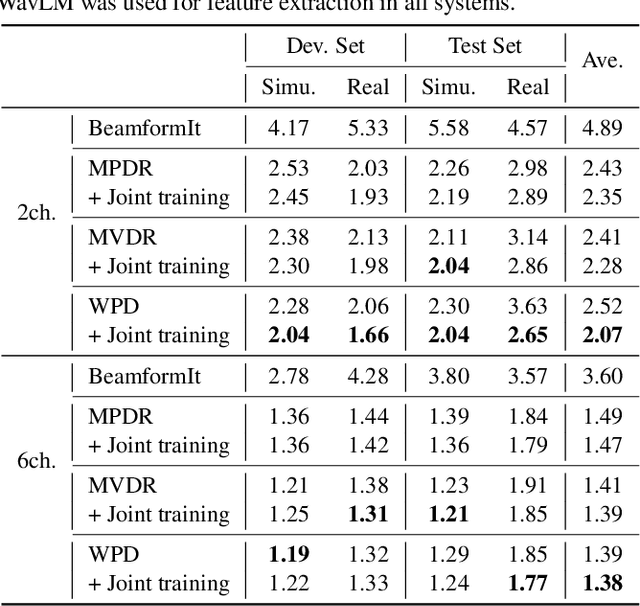
Self-supervised learning representation (SSLR) has demonstrated its significant effectiveness in automatic speech recognition (ASR), mainly with clean speech. Recent work pointed out the strength of integrating SSLR with single-channel speech enhancement for ASR in noisy environments. This paper further advances this integration by dealing with multi-channel input. We propose a novel end-to-end architecture by integrating dereverberation, beamforming, SSLR, and ASR within a single neural network. Our system achieves the best performance reported in the literature on the CHiME-4 6-channel track with a word error rate (WER) of 1.77%. While the WavLM-based strong SSLR demonstrates promising results by itself, the end-to-end integration with the weighted power minimization distortionless response beamformer, which simultaneously performs dereverberation and denoising, improves WER significantly. Its effectiveness is also validated on the REVERB dataset.
Filter and evolve: progressive pseudo label refining for semi-supervised automatic speech recognition
Oct 28, 2022
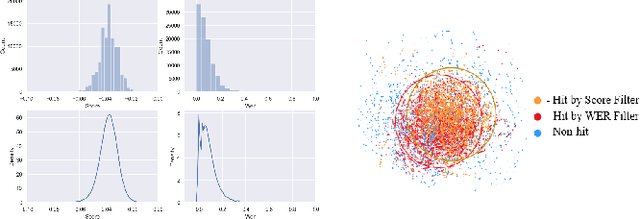
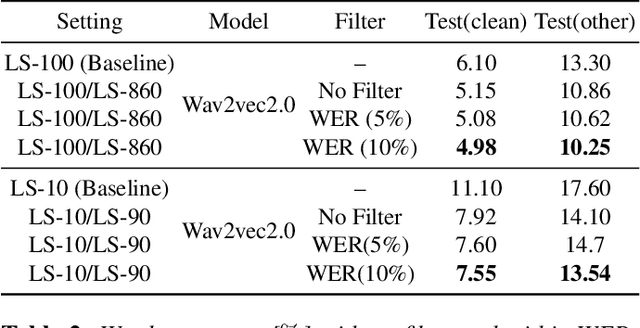
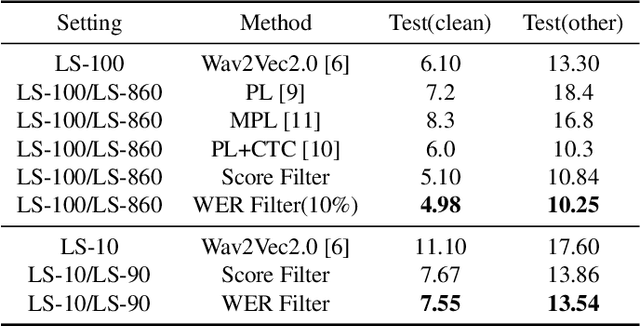
Fine tuning self supervised pretrained models using pseudo labels can effectively improve speech recognition performance. But, low quality pseudo labels can misguide decision boundaries and degrade performance. We propose a simple yet effective strategy to filter low quality pseudo labels to alleviate this problem. Specifically, pseudo-labels are produced over the entire training set and filtered via average probability scores calculated from the model output. Subsequently, an optimal percentage of utterances with high probability scores are considered reliable training data with trustworthy labels. The model is iteratively updated to correct the unreliable pseudo labels to minimize the effect of noisy labels. The process above is repeated until unreliable pseudo abels have been adequately corrected. Extensive experiments on LibriSpeech show that these filtered samples enable the refined model to yield more correct predictions, leading to better ASR performances under various experimental settings.
From Audio to Symbolic Encoding
Feb 26, 2023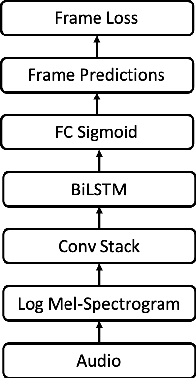
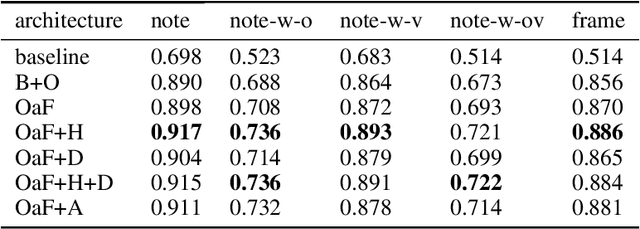
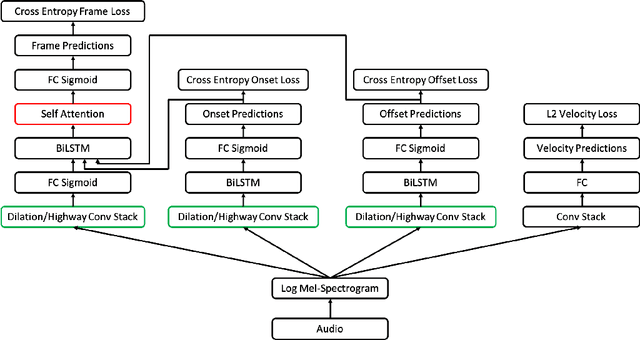
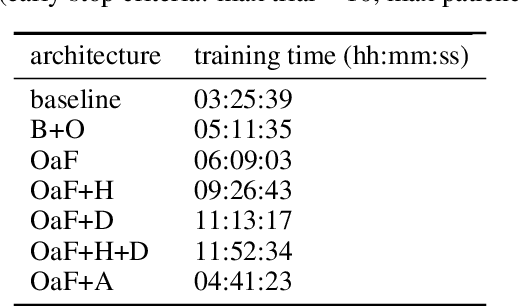
Automatic music transcription (AMT) aims to convert raw audio to symbolic music representation. As a fundamental problem of music information retrieval (MIR), AMT is considered a difficult task even for trained human experts due to overlap of multiple harmonics in the acoustic signal. On the other hand, speech recognition, as one of the most popular tasks in natural language processing, aims to translate human spoken language to texts. Based on the similar nature of AMT and speech recognition (as they both deal with tasks of translating audio signal to symbolic encoding), this paper investigated whether a generic neural network architecture could possibly work on both tasks. In this paper, we introduced our new neural network architecture built on top of the current state-of-the-art Onsets and Frames, and compared the performances of its multiple variations on AMT task. We also tested our architecture with the task of speech recognition. For AMT, our models were able to produce better results compared to the model trained using the state-of-art architecture; however, although similar architecture was able to be trained on the speech recognition task, it did not generate very ideal result compared to other task-specific models.