 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Speech-to-Text Translation with a SpeechLLM
May 14, 2026Normally, a system that translates speech into text consists of separate modules for speech recognition and text-to-text translation. Combining those tasks into a SpeechLLM promises to exploit paralinguistic information in the speech and to reduce cascaded errors. But existing SpeechLLM systems are slow since they do not work in a real streaming fashion: they wait for a complete utterance of audio before outputting a translation, or output tokens at fixed intervals, which is not suitable for real applications. This work proposes an LLM-based architecture for real streaming speech-to-text translation. The LLM learns not just to emit output tokens, but also to decide whether it has seen enough audio to do so. The system is trained using automatic alignments of the input speech and the output text. In experiments on different language pairs, the system achieves a translation quality close to the non-streaming baseline, but with a latency of only 1-2 seconds.
Adaptive Federated Fine-Tuning of Self-Supervised Speech Representations
Mar 23, 2026Integrating Federated Learning (FL) with self-supervised learning (SSL) enables privacy-preserving fine-tuning for speech tasks. However, federated environments exhibit significant heterogeneity: clients differ in computational capacity, causing straggler effects under unified fine-tuning, while diverse downstream tasks require different representation depths, making full-model updates inefficient. To address these challenges, we propose an adaptive federated fine-tuning framework with early exits. Lightweight prediction heads are inserted at intermediate layers of the SSL backbone, allowing clients to terminate computation based on local constraints and task requirements. We further introduce a layer-wise, depth-aware partial aggregation strategy to better utilize representations from different network depths. Experiments show that the framework reduces edge overhead, supports heterogeneous hardware, and maintains competitive performance in resource-constrained federated environments.
SOT Triggered Neural Clustering for Speaker Attributed ASR
Jul 02, 2024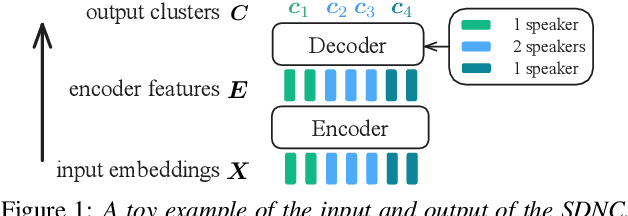
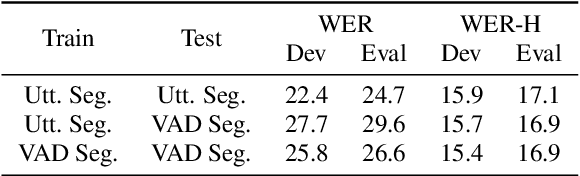
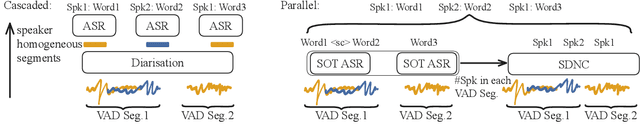

This paper introduces a novel approach to speaker-attributed ASR transcription using a neural clustering method. With a parallel processing mechanism, diarisation and ASR can be applied simultaneously, helping to prevent the accumulation of errors from one sub-system to the next in a cascaded system. This is achieved by the use of ASR, trained using a serialised output training method, together with segment-level discriminative neural clustering (SDNC) to assign speaker labels. With SDNC, our system does not require an extra non-neural clustering method to assign speaker labels, thus allowing the entire system to be based on neural networks. Experimental results on the AMI meeting dataset demonstrate that SDNC outperforms spectral clustering (SC) by a 19% relative diarisation error rate (DER) reduction on the AMI Eval set. When compared with the cascaded system with SC, the parallel system with SDNC gives a 7%/4% relative improvement in cpWER on the Dev/Eval set.
Conditional Diffusion Model for Target Speaker Extraction
Oct 07, 2023



We propose DiffSpEx, a generative target speaker extraction method based on score-based generative modelling through stochastic differential equations. DiffSpEx deploys a continuous-time stochastic diffusion process in the complex short-time Fourier transform domain, starting from the target speaker source and converging to a Gaussian distribution centred on the mixture of sources. For the reverse-time process, a parametrised score function is conditioned on a target speaker embedding to extract the target speaker from the mixture of sources. We utilise ECAPA-TDNN target speaker embeddings and condition the score function alternately on the SDE time embedding and the target speaker embedding. The potential of DiffSpEx is demonstrated with the WSJ0-2mix dataset, achieving an SI-SDR of 12.9 dB and a NISQA score of 3.56. Moreover, we show that fine-tuning a pre-trained DiffSpEx model to a specific speaker further improves performance, enabling personalisation in target speaker extraction.
Can Contextual Biasing Remain Effective with Whisper and GPT-2?
Jun 02, 2023End-to-end automatic speech recognition (ASR) and large language models, such as Whisper and GPT-2, have recently been scaled to use vast amounts of training data. Despite the large amount of training data, infrequent content words that occur in a particular task may still exhibit poor ASR performance, with contextual biasing a possible remedy. This paper investigates the effectiveness of neural contextual biasing for Whisper combined with GPT-2. Specifically, this paper proposes integrating an adapted tree-constrained pointer generator (TCPGen) component for Whisper and a dedicated training scheme to dynamically adjust the final output without modifying any Whisper model parameters. Experiments across three datasets show a considerable reduction in errors on biasing words with a biasing list of 1000 words. Contextual biasing was more effective when applied to domain-specific data and can boost the performance of Whisper and GPT-2 without losing their generality.
Self-Supervised Learning-Based Source Separation for Meeting Data
Apr 03, 2023



Source separation can improve automatic speech recognition (ASR) under multi-party meeting scenarios by extracting single-speaker signals from overlapped speech. Despite the success of self-supervised learning models in single-channel source separation, most studies have focused on simulated setups. In this paper, seven SSL models were compared on both simulated and real-world corpora. Then, we propose to integrate the best-performing model WavLM into an automatic transcription system through a novel iterative source selection method. To improve real-world performance, time-domain unsupervised mixture invariant training was adapted to the time-frequency domain. Experiments showed that in the transcription system when source separation was inserted before an ASR model fine-tuned on separated speech, absolute reductions of 1.9% and 1.5% in concatenated minimum-permutation word error rate for an unknown number of speakers (cpWER-us) were observed on the AMI dev and test sets.
Tandem Multitask Training of Speaker Diarisation and Speech Recognition for Meeting Transcription
Jul 08, 2022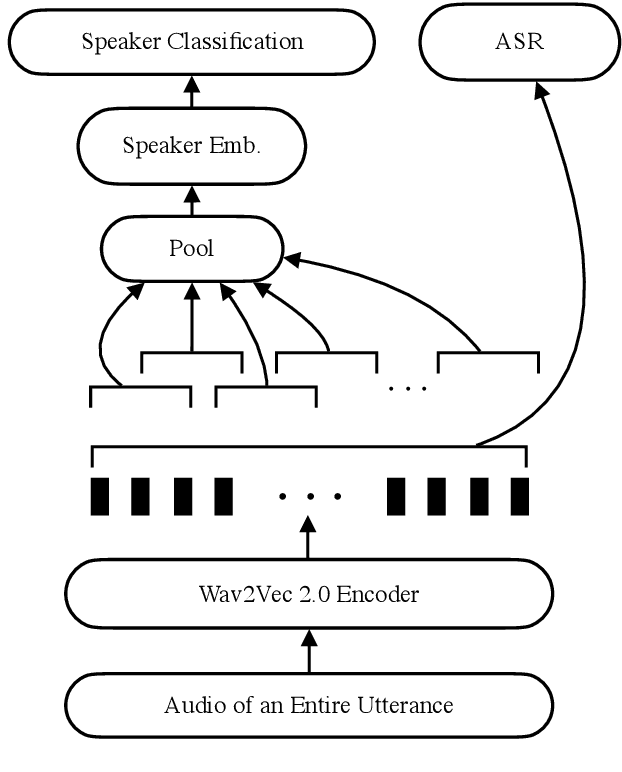
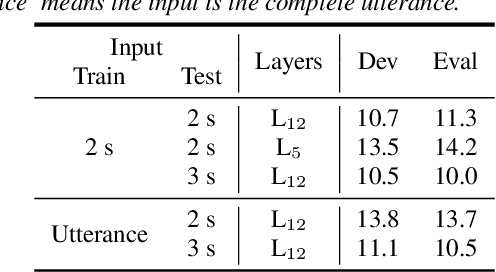
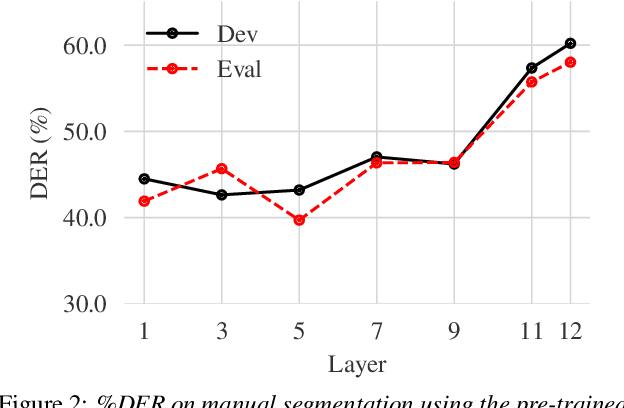
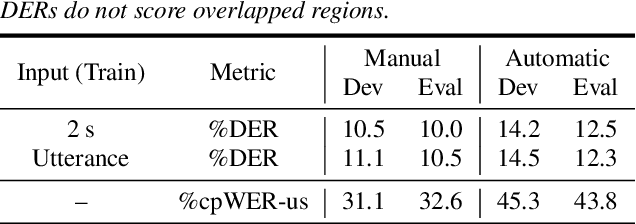
Self-supervised-learning-based pre-trained models for speech data, such as Wav2Vec 2.0 (W2V2), have become the backbone of many speech tasks. In this paper, to achieve speaker diarisation and speech recognition using a single model, a tandem multitask training (TMT) method is proposed to fine-tune W2V2. For speaker diarisation, the tasks of voice activity detection (VAD) and speaker classification (SC) are required, and connectionist temporal classification (CTC) is used for ASR. The multitask framework implements VAD, SC, and ASR using an early layer, middle layer, and late layer of W2V2, which coincides with the order of segmenting the audio with VAD, clustering the segments based on speaker embeddings, and transcribing each segment with ASR. Experimental results on the augmented multi-party (AMI) dataset showed that using different W2V2 layers for VAD, SC, and ASR from the earlier to later layers for TMT not only saves computational cost, but also reduces diarisation error rates (DERs). Joint fine-tuning of VAD, SC, and ASR yielded 16%/17% relative reductions of DER with manual/automatic segmentation respectively, and consistent reductions in speaker attributed word error rate, compared to the baseline with separately fine-tuned models.
Multi-turn RNN-T for streaming recognition of multi-party speech
Dec 19, 2021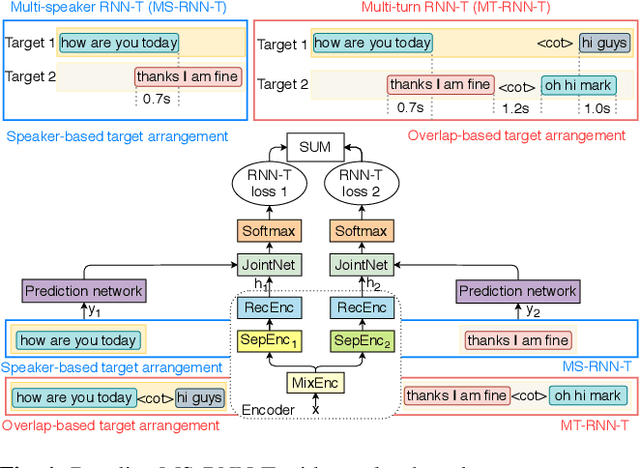

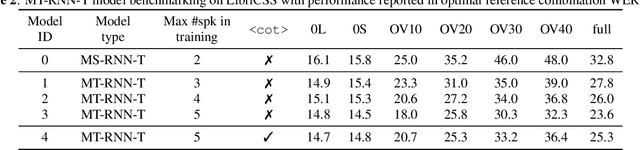
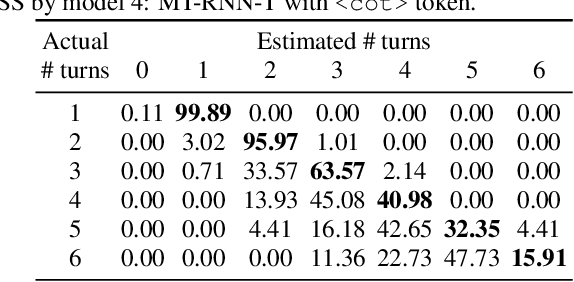
Automatic speech recognition (ASR) of single channel far-field recordings with an unknown number of speakers is traditionally tackled by cascaded modules. Recent research shows that end-to-end (E2E) multi-speaker ASR models can achieve superior recognition accuracy compared to modular systems. However, these models do not ensure real-time applicability due to their dependency on full audio context. This work takes real-time applicability as the first priority in model design and addresses a few challenges in previous work on multi-speaker recurrent neural network transducer (MS-RNN-T). First, we introduce on-the-fly overlapping speech simulation during training, yielding 14% relative word error rate (WER) improvement on LibriSpeechMix test set. Second, we propose a novel multi-turn RNN-T (MT-RNN-T) model with an overlap-based target arrangement strategy that generalizes to an arbitrary number of speakers without changes in the model architecture. We investigate the impact of the maximum number of speakers seen during training on MT-RNN-T performance on LibriCSS test set, and report 28% relative WER improvement over the two-speaker MS-RNN-T. Third, we experiment with a rich transcription strategy for joint recognition and segmentation of multi-party speech. Through an in-depth analysis, we discuss potential pitfalls of the proposed system as well as promising future research directions.
Adapting GPT, GPT-2 and BERT Language Models for Speech Recognition
Jul 29, 2021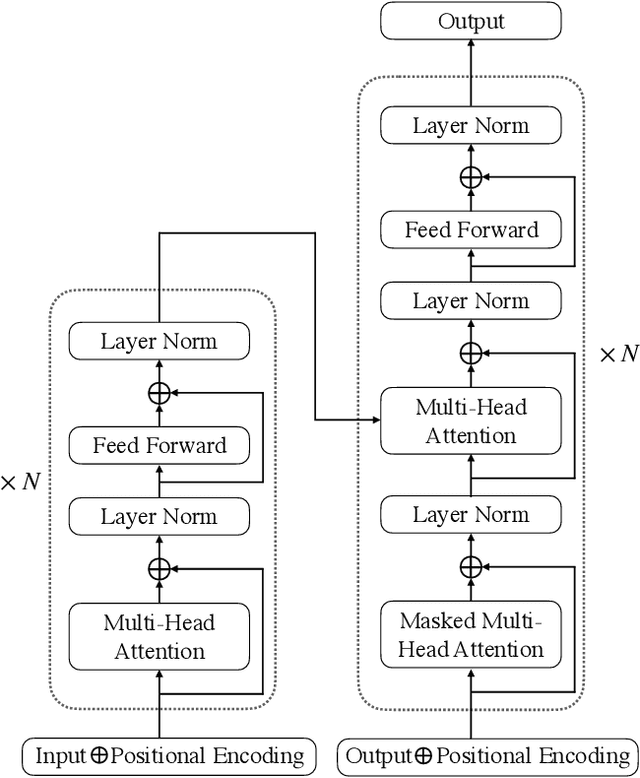
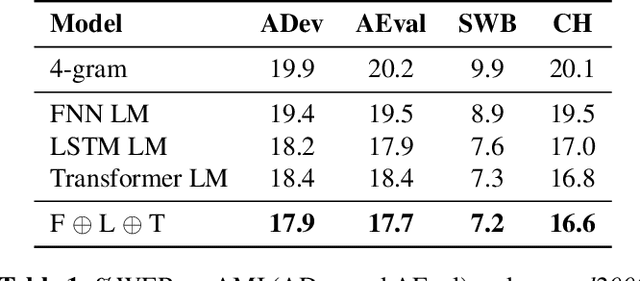
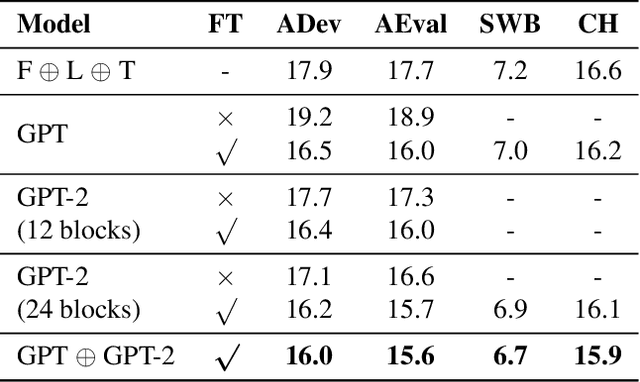
Language models (LMs) pre-trained on massive amounts of text, in particular bidirectional encoder representations from Transformers (BERT), generative pre-training (GPT), and GPT-2, have become a key technology for many natural language processing tasks. In this paper, we present results using fine-tuned GPT, GPT-2, and their combination for automatic speech recognition (ASR). Unlike unidirectional LM GPT and GPT-2, BERT is bidirectional whose direct product of the output probabilities is no longer a valid language prior probability. A conversion method is proposed to compute the correct language prior probability based on bidirectional LM outputs in a mathematically exact way. Experimental results on the widely used AMI and Switchboard ASR tasks showed that the combination of the fine-tuned GPT and GPT-2 outperformed the combination of three neural LMs with different architectures trained from scratch on the in-domain text by up to a 12% relative word error rate reduction (WERR). Furthermore, the proposed conversion for language prior probabilities enables BERT to receive an extra 3% relative WERR, and the combination of BERT, GPT and GPT-2 results in further improvements.