 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Face Destylization
Feb 05, 2018

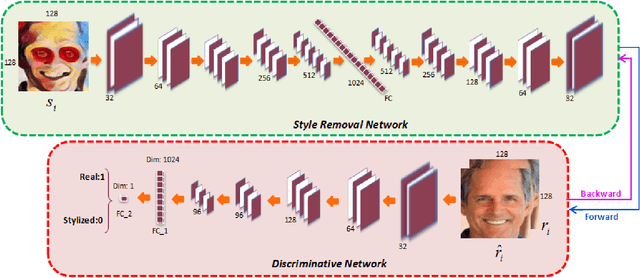


Numerous style transfer methods which produce artistic styles of portraits have been proposed to date. However, the inverse problem of converting the stylized portraits back into realistic faces is yet to be investigated thoroughly. Reverting an artistic portrait to its original photo-realistic face image has potential to facilitate human perception and identity analysis. In this paper, we propose a novel Face Destylization Neural Network (FDNN) to restore the latent photo-realistic faces from the stylized ones. We develop a Style Removal Network composed of convolutional, fully-connected and deconvolutional layers. The convolutional layers are designed to extract facial components from stylized face images. Consecutively, the fully-connected layer transfers the extracted feature maps of stylized images into the corresponding feature maps of real faces and the deconvolutional layers generate real faces from the transferred feature maps. To enforce the destylized faces to be similar to authentic face images, we employ a discriminative network, which consists of convolutional and fully connected layers. We demonstrate the effectiveness of our network by conducting experiments on an extensive set of synthetic images. Furthermore, we illustrate our network can recover faces from stylized portraits and real paintings for which the stylized data was unavailable during the training phase.
Domain-Specific Image Super-Resolution with Progressive Adversarial Network
Mar 10, 2020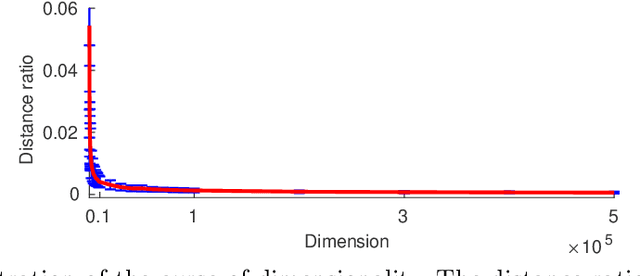
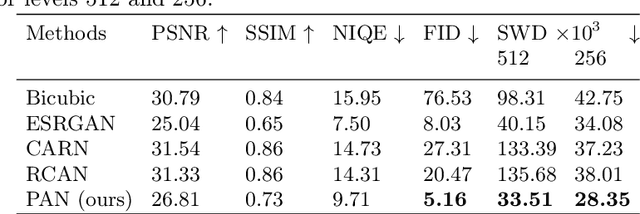
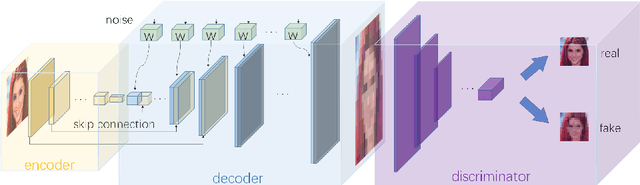
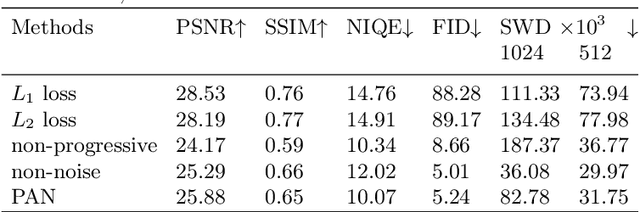
Single Image Super-Resolution (SISR) aims to improve resolution of small-size low-quality image from a single one. With popularity of consumer electronics in our daily life, this topic has become more and more attractive. In this paper, we argue that the curse of dimensionality is the underlying reason of limiting the performance of state-of-the-art algorithms. To address this issue, we propose Progressive Adversarial Network (PAN) that is capable of coping with this difficulty for domainspecific image super-resolution. The key principle of PAN is that we do not apply any distance-based reconstruction errors as the loss to be optimized, thus free from the restriction of the curse of dimensionality. To maintain faithful reconstruction precision, we resort to U-Net and progressive growing of neural architecture. The low-level features in encoder can be transferred into decoder to enhance textural details with U-Net. Progressive growing enhances image resolution gradually, thereby preserving precision of recovered image. Moreover, to obtain high-fidelity outputs, we leverage the framework of the powerful StyleGAN to perform adversarial learning. Without the curse of dimensionality, our model can super-resolve large-size images with remarkable photo-realistic details and few distortion. Extensive experiments demonstrate the superiority of our algorithm over existing state-of-the-arts both quantitatively and qualitatively.
Environment-agnostic Multitask Learning for Natural Language Grounded Navigation
Mar 09, 2020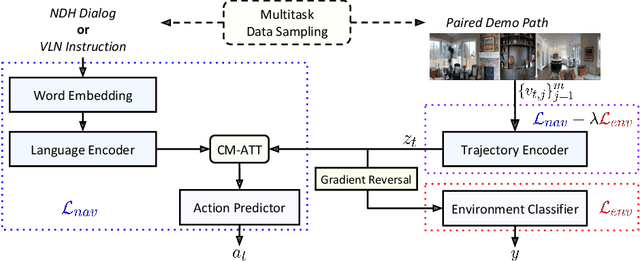
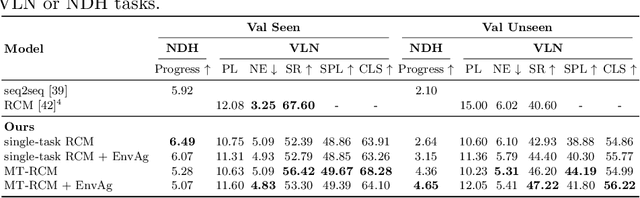
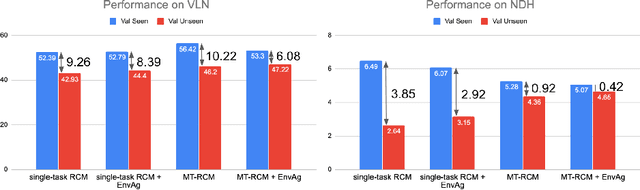
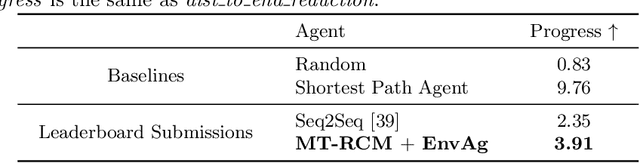
Recent research efforts enable study for natural language grounded navigation in photo-realistic environments, e.g., following natural language instructions or dialog. However, existing methods tend to overfit training data in seen environments and fail to generalize well in previously unseen environments. In order to close the gap between seen and unseen environments, we aim at learning a generalized navigation model from two novel perspectives: (1) we introduce a multitask navigation model that can be seamlessly trained on both Vision-Language Navigation (VLN) and Navigation from Dialog History (NDH) tasks, which benefits from richer natural language guidance and effectively transfers knowledge across tasks; (2) we propose to learn environment-agnostic representations for the navigation policy that are invariant among the environments seen during training, thus generalizing better on unseen environments. Extensive experiments show that training with environment-agnostic multitask learning objective significantly reduces the performance gap between seen and unseen environments and the navigation agent so trained outperforms the baselines on unseen environments by 16% (relative measure on success rate) on VLN and 120% (goal progress) on NDH. Our submission to the CVDN leaderboard establishes a new state-of-the-art for the NDH task outperforming the existing best model by more than 66% (goal progress) on the holdout test set. The code for training the navigation model using environment-agnostic multitask learning is available at https://github.com/google-research/valan.
Prioritized Multi-Criteria Federated Learning
Jul 17, 2020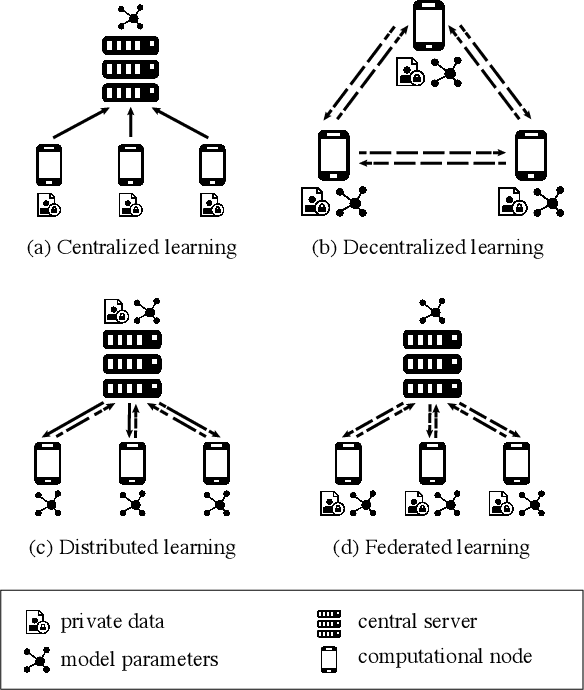
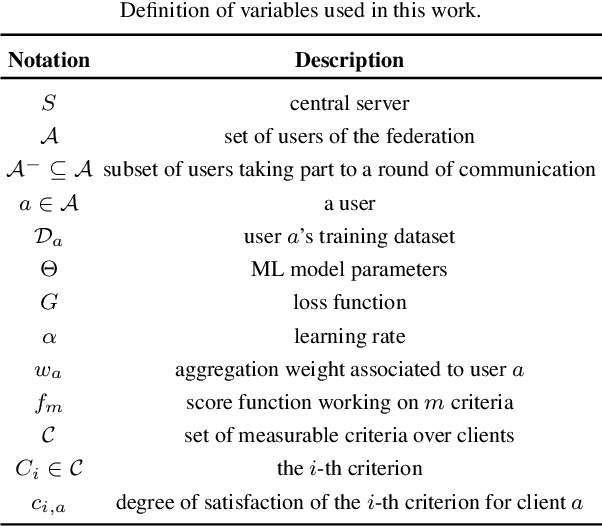
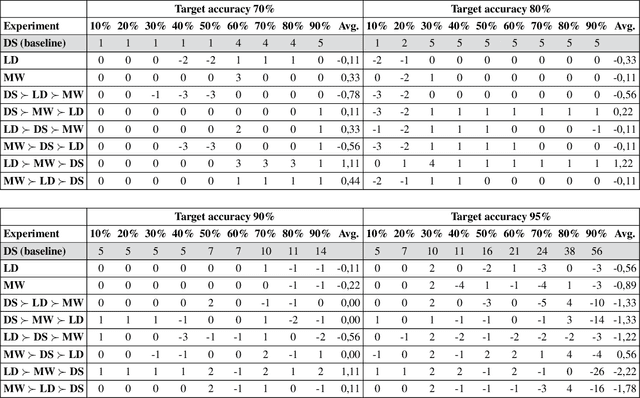
In Machine Learning scenarios, privacy is a crucial concern when models have to be trained with private data coming from users of a service, such as a recommender system, a location-based mobile service, a mobile phone text messaging service providing next word prediction, or a face image classification system. The main issue is that, often, data are collected, transferred, and processed by third parties. These transactions violate new regulations, such as GDPR. Furthermore, users usually are not willing to share private data such as their visited locations, the text messages they wrote, or the photo they took with a third party. On the other hand, users appreciate services that work based on their behaviors and preferences. In order to address these issues, Federated Learning (FL) has been recently proposed as a means to build ML models based on private datasets distributed over a large number of clients, while preventing data leakage. A federation of users is asked to train a same global model on their private data, while a central coordinating server receives locally computed updates by clients and aggregate them to obtain a better global model, without the need to use clients' actual data. In this work, we extend the FL approach by pushing forward the state-of-the-art approaches in the aggregation step of FL, which we deem crucial for building a high-quality global model. Specifically, we propose an approach that takes into account a suite of client-specific criteria that constitute the basis for assigning a score to each client based on a priority of criteria defined by the service provider. Extensive experiments on two publicly available datasets indicate the merits of the proposed approach compared to standard FL baseline.
DFVS: Deep Flow Guided Scene Agnostic Image Based Visual Servoing
Mar 08, 2020

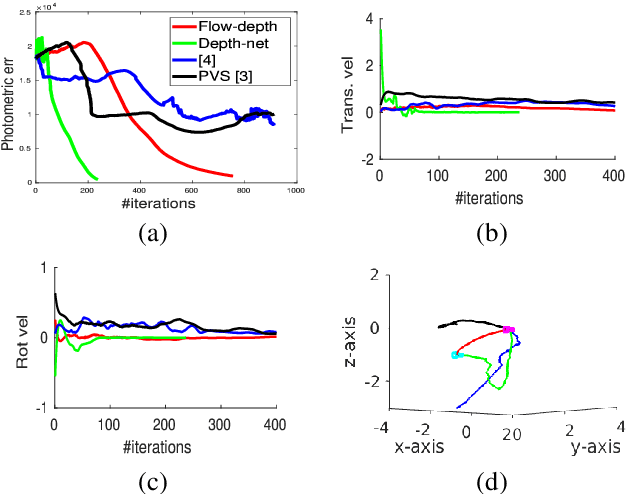
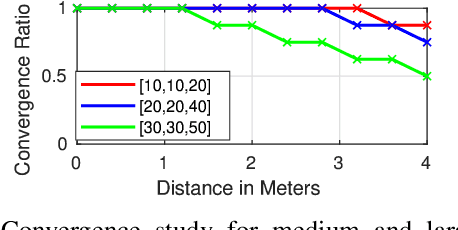
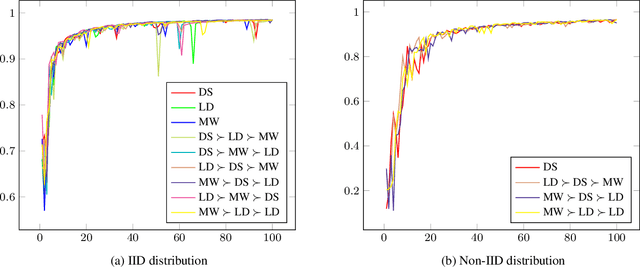
Existing deep learning based visual servoing approaches regress the relative camera pose between a pair of images. Therefore, they require a huge amount of training data and sometimes fine-tuning for adaptation to a novel scene. Furthermore, current approaches do not consider underlying geometry of the scene and rely on direct estimation of camera pose. Thus, inaccuracies in prediction of the camera pose, especially for distant goals, lead to a degradation in the servoing performance. In this paper, we propose a two-fold solution: (i) We consider optical flow as our visual features, which are predicted using a deep neural network. (ii) These flow features are then systematically integrated with depth estimates provided by another neural network using interaction matrix. We further present an extensive benchmark in a photo-realistic 3D simulation across diverse scenes to study the convergence and generalisation of visual servoing approaches. We show convergence for over 3m and 40 degrees while maintaining precise positioning of under 2cm and 1 degree on our challenging benchmark where the existing approaches that are unable to converge for majority of scenarios for over 1.5m and 20 degrees. Furthermore, we also evaluate our approach for a real scenario on an aerial robot. Our approach generalizes to novel scenarios producing precise and robust servoing performance for 6 degrees of freedom positioning tasks with even large camera transformations without any retraining or fine-tuning.
InterFaceGAN: Interpreting the Disentangled Face Representation Learned by GANs
May 18, 2020
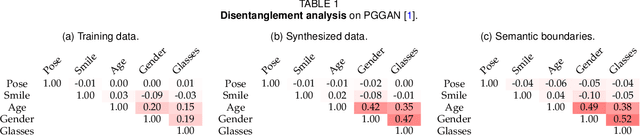
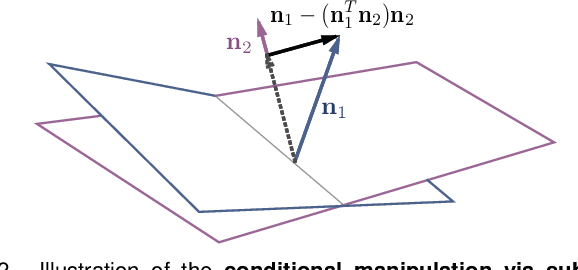
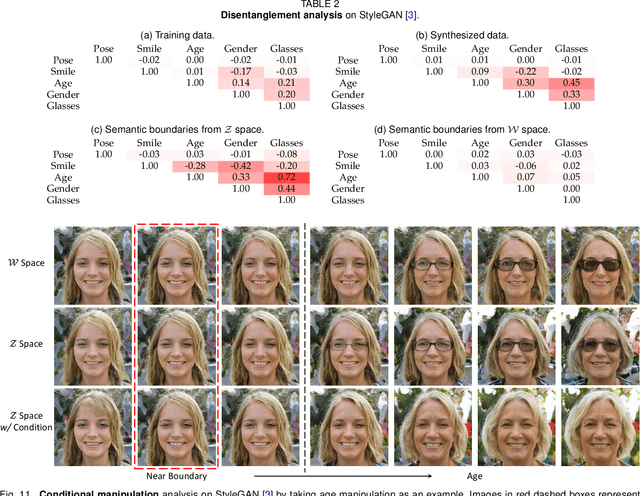
Although Generative Adversarial Networks (GANs) have made significant progress in face synthesis, there lacks enough understanding of what GANs have learned in the latent representation to map a randomly sampled code to a photo-realistic face image. In this work, we propose a framework, called InterFaceGAN, to interpret the disentangled face representation learned by the state-of-the-art GAN models and thoroughly analyze the properties of the facial semantics in the latent space. We first find that GANs actually learn various semantics in some linear subspaces of the latent space when being trained to synthesize high-quality faces. After identifying the subspaces of the corresponding latent semantics, we are able to realistically manipulate the facial attributes occurring in the synthesized images without retraining the model. We then conduct a detailed study on the correlation between different semantics and manage to better disentangle them via subspace projection, resulting in more precise control of the attribute manipulation. Besides manipulating gender, age, expression, and the presence of eyeglasses, we can even alter the face pose as well as fix the artifacts accidentally generated by GANs. Furthermore, we perform in-depth face identity analysis and layer-wise analysis to quantitatively evaluate the editing results. Finally, we apply our approach to real face editing by involving GAN inversion approaches as well as explicitly training additional feed-forward models based on the synthetic data established by InterFaceGAN. Extensive experimental results suggest that learning to synthesize faces spontaneously brings a disentangled and controllable face representation.
One-to-one Mapping for Unpaired Image-to-image Translation
Oct 12, 2019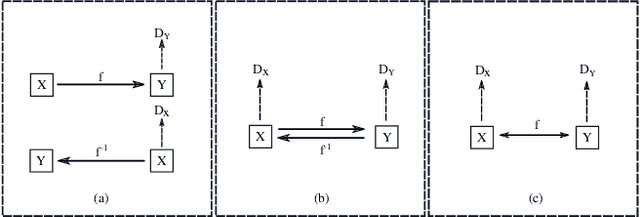



Recently image-to-image translation has attracted significant interests in the literature, starting from the successful use of the generative adversarial network (GAN), to the introduction of cyclic constraint, to extensions to multiple domains. However, in existing approaches, there is no guarantee that the mapping between two image domains is unique or one-to-one. Here we propose a self-inverse network learning approach for unpaired image-to-image translation. Building on top of CycleGAN, we learn a self-inverse function by simply augmenting the training samples by swapping inputs and outputs during training and with separated cycle consistency loss for each mapping direction. The outcome of such learning is a proven one-to-one mapping function. Our extensive experiments on a variety of datasets, including cross-modal medical image synthesis, object transfiguration, and semantic labeling, consistently demonstrate clear improvement over the CycleGAN method both qualitatively and quantitatively. Especially our proposed method reaches the state-of-the-art result on the cityscapes benchmark dataset for the label to photo unpaired directional image translation.
Synthetic Video Generation for Robust Hand Gesture Recognition in Augmented Reality Applications
Dec 06, 2019
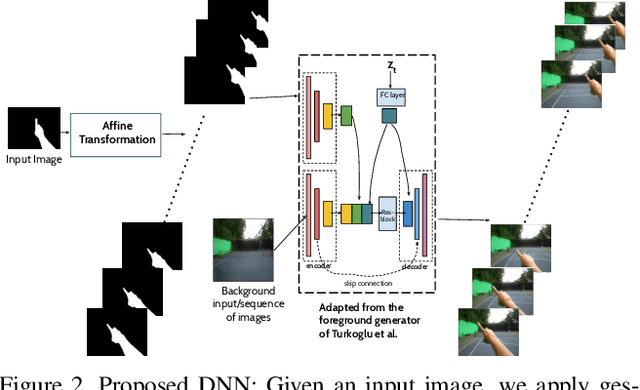


Hand gestures are a natural means of interaction in Augmented Reality and Virtual Reality (AR/VR) applications. Recently, there has been an increased focus on removing the dependence of accurate hand gesture recognition on complex sensor setup found in expensive proprietary devices such as the Microsoft HoloLens, Daqri and Meta Glasses. Most such solutions either rely on multi-modal sensor data or deep neural networks that can benefit greatly from abundance of labelled data. Datasets are an integral part of any deep learning based research. They have been the principal reason for the substantial progress in this field, both, in terms of providing enough data for the training of these models, and, for benchmarking competing algorithms. However, it is becoming increasingly difficult to generate enough labelled data for complex tasks such as hand gesture recognition. The goal of this work is to introduce a framework capable of generating photo-realistic videos that have labelled hand bounding box and fingertip that can help in designing, training, and benchmarking models for hand-gesture recognition in AR/VR applications. We demonstrate the efficacy of our framework in generating videos with diverse backgrounds.
Turbulence Enrichment using Physics-informed Generative Adversarial Networks
Mar 06, 2020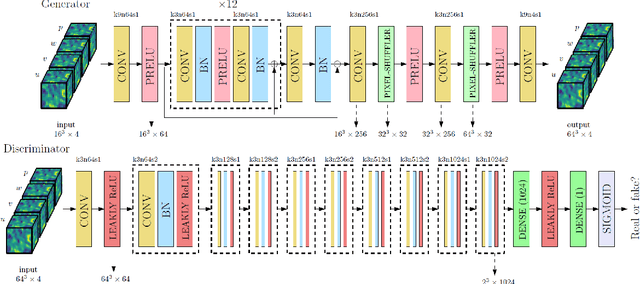
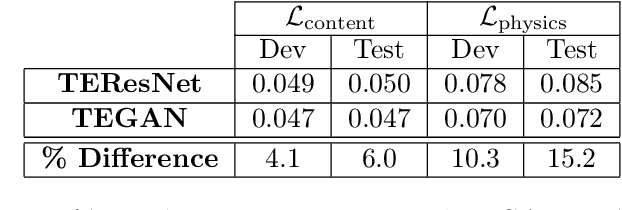
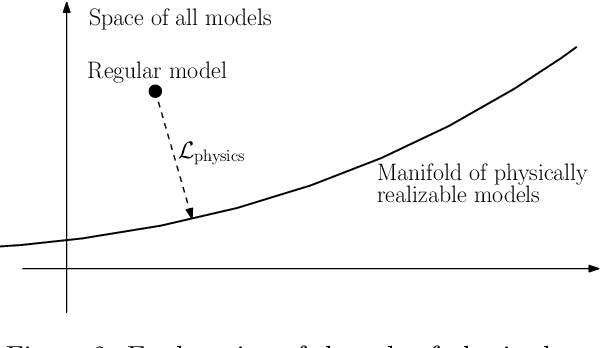
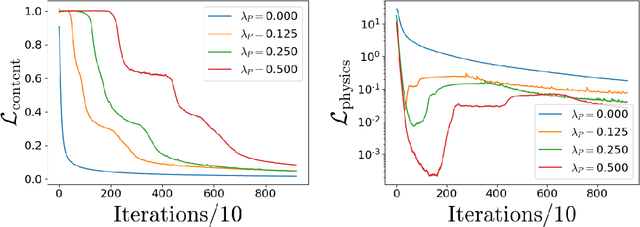
Generative Adversarial Networks (GANs) have been widely used for generating photo-realistic images. A variant of GANs called super-resolution GAN (SRGAN) has already been used successfully for image super-resolution where low resolution images can be upsampled to a $4\times$ larger image that is perceptually more realistic. However, when such generative models are used for data describing physical processes, there are additional known constraints that models must satisfy including governing equations and boundary conditions. In general, these constraints may not be obeyed by the generated data. In this work, we develop physics-based methods for generative enrichment of turbulence. We incorporate a physics-informed learning approach by a modification to the loss function to minimize the residuals of the governing equations for the generated data. We have analyzed two trained physics-informed models: a supervised model based on convolutional neural networks (CNN) and a generative model based on SRGAN: Turbulence Enrichment GAN (TEGAN), and show that they both outperform simple bicubic interpolation in turbulence enrichment. We have also shown that using the physics-informed learning can also significantly improve the model's ability in generating data that satisfies the physical governing equations. Finally, we compare the enriched data from TEGAN to show that it is able to recover statistical metrics of the flow field including energy metrics and well as inter-scale energy dynamics and flow morphology.
Mask-Guided Portrait Editing with Conditional GANs
May 24, 2019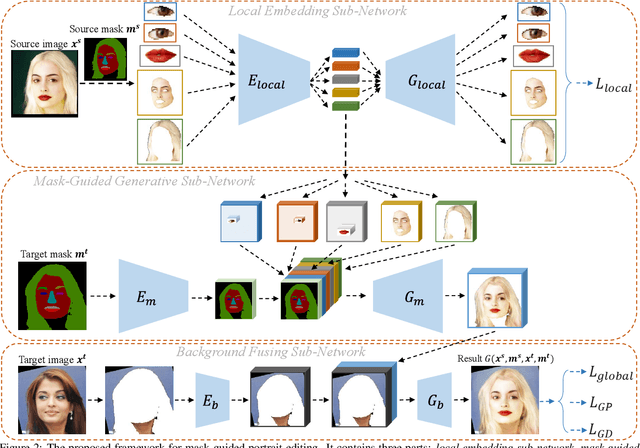
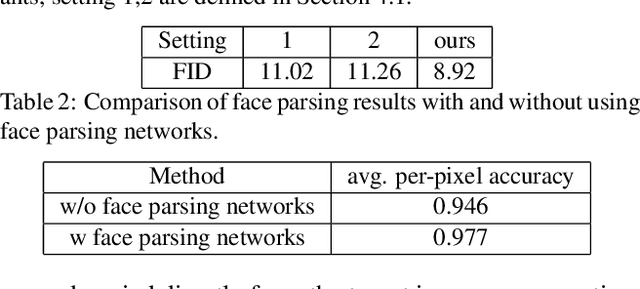


Portrait editing is a popular subject in photo manipulation. The Generative Adversarial Network (GAN) advances the generating of realistic faces and allows more face editing. In this paper, we argue about three issues in existing techniques: diversity, quality, and controllability for portrait synthesis and editing. To address these issues, we propose a novel end-to-end learning framework that leverages conditional GANs guided by provided face masks for generating faces. The framework learns feature embeddings for every face component (e.g., mouth, hair, eye), separately, contributing to better correspondences for image translation, and local face editing. With the mask, our network is available to many applications, like face synthesis driven by mask, face Swap+ (including hair in swapping), and local manipulation. It can also boost the performance of face parsing a bit as an option of data augmentation.