 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Audio-Text Retrieval via Cross-Modal Attention and Hybrid Loss
Apr 25, 2026Audio-text retrieval enables semantic alignment between audio content and natural language queries, supporting applications in multimedia search, accessibility, and surveillance. However, current state-of-the-art approaches struggle with long, noisy, and weakly labeled audio due to their reliance on contrastive learning and large-batch training. We propose a novel multimodal retrieval framework that refines audio and text embeddings using a cross-modal embedding refinement module combining transformer-based projection, linear mapping, and bidirectional attention. To further improve robustness, we introduce a hybrid loss function blending cosine similarity, $\mathcal{L}_{1}$, and contrastive objectives, enabling stable training even under small-batch constraints. Our approach efficiently handles long-form and noisy audio (SNR 5 to 15) via silence-aware chunking and attention-based pooling. Experiments on benchmark datasets demonstrate improvements over prior methods.
JTPRO: A Joint Tool-Prompt Reflective Optimization Framework for Language Agents
Apr 20, 2026Large language model (LLM) agents augmented with external tools often struggle as number of tools grow large and become domain-specific. In such settings, ambiguous tool descriptions and under-specified agent instructions frequently lead to tool mis-selection and incorrect slot/value instantiation. We hypothesize that this is due to two root causes: generic, one-size-fits-all prompts that ignore tool-specific nuances, and underspecified tool schemas that lack clear guidance on when and how to use each tool and how to format its parameters. We introduce Joint Tool-Prompt Reflective Optimization (JTPRO), a framework for improving tool-calling reliability in trace-supervised settings by iteratively using rollout-driven reflection to co-optimize global instructions and per-tool schema/argument descriptions for accurate tool selection and argument instantiation in large tool inventories. JTPRO is designed to preserve only tool-local cues needed for correct disambiguation and slot filling. We evaluate JTPRO across multi-tool benchmarks, which account for different number of tools using three metrics: Tool Selection Accuracy (TSA), Slot Filling Accuracy(SFA), and Overall Success Rate(OSR) (correct tool + correct slots + correct values). JTPRO consistently outperforms strong baselines, including CoT-style agents, and reflective prompt optimizers such as GEPA by 5%-20% (relative) on OSR. Ablations show that joint optimization of instructions and tool schemas is more effective and robust than optimizing either component in isolation.
MT-OSC: Path for LLMs that Get Lost in Multi-Turn Conversation
Apr 09, 2026Large language models (LLMs) suffer significant performance degradation when user instructions and context are distributed over multiple conversational turns, yet multi-turn (MT) interactions dominate chat interfaces. The routine approach of appending full chat history to prompts rapidly exhausts context windows, leading to increased latency, higher computational costs, and diminishing returns as conversations extend. We introduce MT-OSC, a One-off Sequential Condensation framework that efficiently and automatically condenses chat history in the background without disrupting the user experience. MT-OSC employs a Condenser Agent that uses a few-shot inference-based Condenser and a lightweight Decider to selectively retain essential information, reducing token counts by up to 72% in 10-turn dialogues. Evaluated across 13 state-of-the-art LLMs and diverse multi-turn benchmarks, MT-OSC consistently narrows the multi-turn performance gap - yielding improved or preserved accuracy across datasets while remaining robust to distractors and irrelevant turns. Our results establish MT-OSC as a scalable solution for multi-turn chats, enabling richer context within constrained input spaces, reducing latency and operational cost, while balancing performance.
DiffuMask: Diffusion Language Model for Token-level Prompt Pruning
Apr 08, 2026In-Context Learning and Chain-of-Thought prompting improve reasoning in large language models (LLMs). These typically come at the cost of longer, more expensive prompts that may contain redundant information. Prompt compression based on pruning offers a practical solution, yet existing methods rely on sequential token removal which is computationally intensive. We present DiffuMask, a diffusion-based framework integrating hierarchical shot-level and token-level pruning signals, that enables rapid and parallel prompt pruning via iterative mask prediction. DiffuMask substantially accelerates the compression process via masking multiple tokens in each denoising step. It offers tunable control over retained content, preserving essential reasoning context and achieving up to 80\% prompt length reduction. Meanwhile, it maintains or improves accuracy across in-domain, out-of-domain, and cross-model settings. Our results show that DiffuMask provides a generalizable and controllable framework for prompt compression, facilitating faster and more reliable in-context reasoning in LLMs.
PAR$^2$-RAG: Planned Active Retrieval and Reasoning for Multi-Hop Question Answering
Mar 30, 2026Large language models (LLMs) remain brittle on multi-hop question answering (MHQA), where answering requires combining evidence across documents through retrieval and reasoning. Iterative retrieval systems can fail by locking onto an early low-recall trajectory and amplifying downstream errors, while planning-only approaches may produce static query sets that cannot adapt when intermediate evidence changes. We propose \textbf{Planned Active Retrieval and Reasoning RAG (PAR$^2$-RAG)}, a two-stage framework that separates \emph{coverage} from \emph{commitment}. PAR$^2$-RAG first performs breadth-first anchoring to build a high-recall evidence frontier, then applies depth-first refinement with evidence sufficiency control in an iterative loop. Across four MHQA benchmarks, PAR$^2$-RAG consistently outperforms existing state-of-the-art baselines, compared with IRCoT, PAR$^2$-RAG achieves up to \textbf{23.5\%} higher accuracy, with retrieval gains of up to \textbf{10.5\%} in NDCG.
GraphER: An Efficient Graph-Based Enrichment and Reranking Method for Retrieval-Augmented Generation
Mar 26, 2026Semantic search in retrieval-augmented generation (RAG) systems is often insufficient for complex information needs, particularly when relevant evidence is scattered across multiple sources. Prior approaches to this problem include agentic retrieval strategies, which expand the semantic search space by generating additional queries. However, these methods do not fully leverage the organizational structure of the data and instead rely on iterative exploration, which can lead to inefficient retrieval. Another class of approaches employs knowledge graphs to model non-semantic relationships through graph edges. Although effective in capturing richer proximities, such methods incur significant maintenance costs and are often incompatible with the vector stores used in most production systems. To address these limitations, we propose GraphER, a graph-based enrichment and reranking method that captures multiple forms of proximity beyond semantic similarity. GraphER independently enriches data objects during offline indexing and performs graph-based reranking over candidate objects at query time. This design does not require a knowledge graph, allowing GraphER to integrate seamlessly with standard vector stores. In addition, GraphER is retriever-agnostic and introduces negligible latency overhead. Experiments on multiple retrieval benchmarks demonstrate the effectiveness of the proposed approach.
LAD-RAG: Layout-aware Dynamic RAG for Visually-Rich Document Understanding
Oct 08, 2025



Question answering over visually rich documents (VRDs) requires reasoning not only over isolated content but also over documents' structural organization and cross-page dependencies. However, conventional retrieval-augmented generation (RAG) methods encode content in isolated chunks during ingestion, losing structural and cross-page dependencies, and retrieve a fixed number of pages at inference, regardless of the specific demands of the question or context. This often results in incomplete evidence retrieval and degraded answer quality for multi-page reasoning tasks. To address these limitations, we propose LAD-RAG, a novel Layout-Aware Dynamic RAG framework. During ingestion, LAD-RAG constructs a symbolic document graph that captures layout structure and cross-page dependencies, adding it alongside standard neural embeddings to yield a more holistic representation of the document. During inference, an LLM agent dynamically interacts with the neural and symbolic indices to adaptively retrieve the necessary evidence based on the query. Experiments on MMLongBench-Doc, LongDocURL, DUDE, and MP-DocVQA demonstrate that LAD-RAG improves retrieval, achieving over 90% perfect recall on average without any top-k tuning, and outperforming baseline retrievers by up to 20% in recall at comparable noise levels, yielding higher QA accuracy with minimal latency.
Approximating 1-Wasserstein Distance with Trees
Jun 24, 2022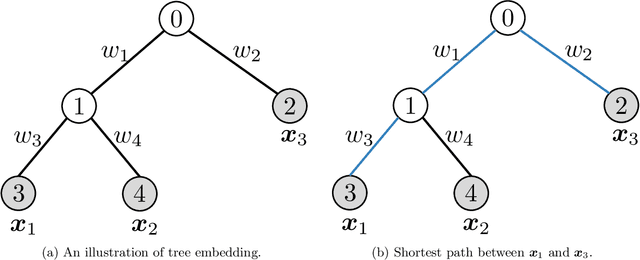
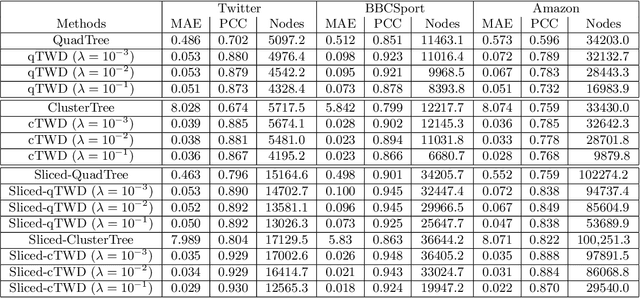
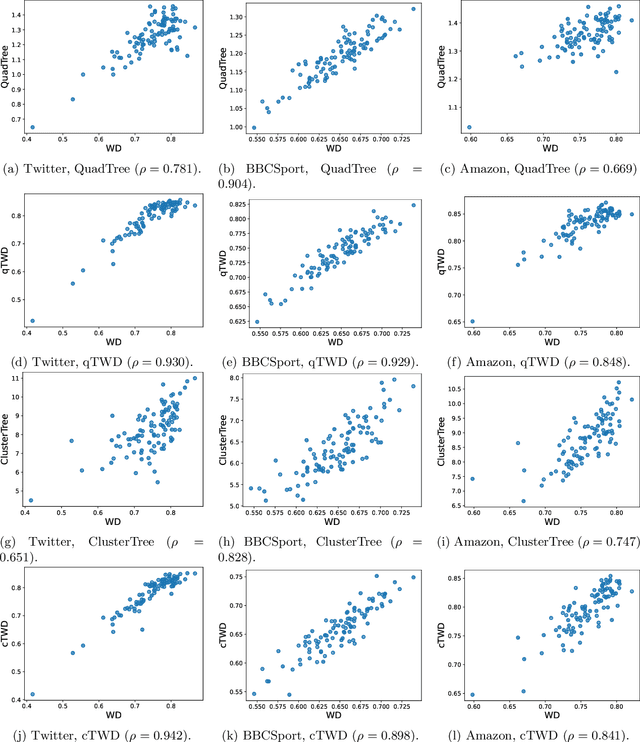
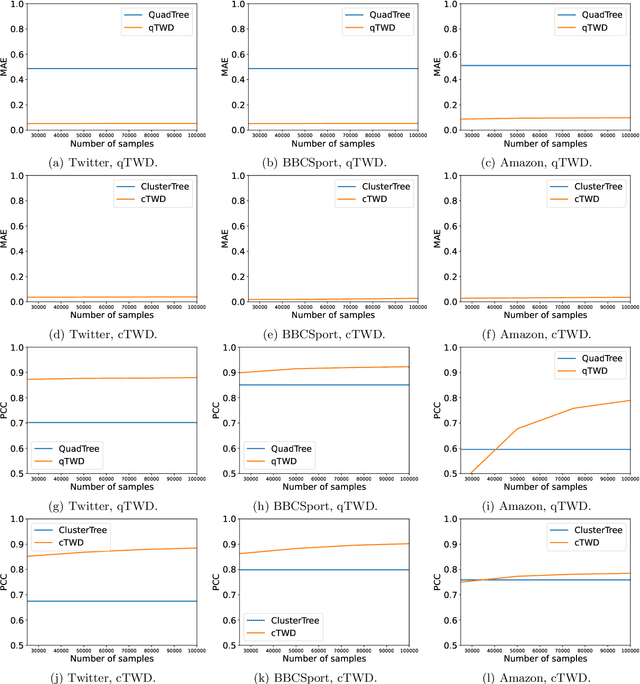
Wasserstein distance, which measures the discrepancy between distributions, shows efficacy in various types of natural language processing (NLP) and computer vision (CV) applications. One of the challenges in estimating Wasserstein distance is that it is computationally expensive and does not scale well for many distribution comparison tasks. In this paper, we aim to approximate the 1-Wasserstein distance by the tree-Wasserstein distance (TWD), where TWD is a 1-Wasserstein distance with tree-based embedding and can be computed in linear time with respect to the number of nodes on a tree. More specifically, we propose a simple yet efficient L1-regularized approach to learning the weights of the edges in a tree. To this end, we first show that the 1-Wasserstein approximation problem can be formulated as a distance approximation problem using the shortest path distance on a tree. We then show that the shortest path distance can be represented by a linear model and can be formulated as a Lasso-based regression problem. Owing to the convex formulation, we can obtain a globally optimal solution efficiently. Moreover, we propose a tree-sliced variant of these methods. Through experiments, we demonstrated that the weighted TWD can accurately approximate the original 1-Wasserstein distance.
Fixed Support Tree-Sliced Wasserstein Barycenter
Sep 08, 2021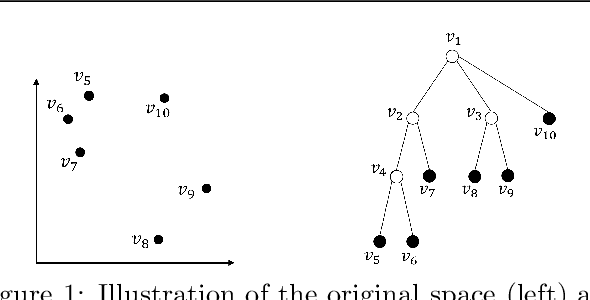
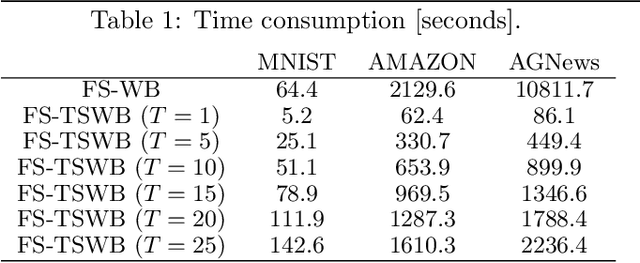
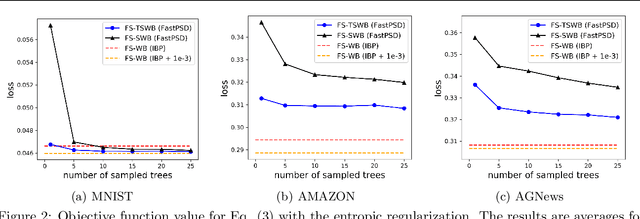
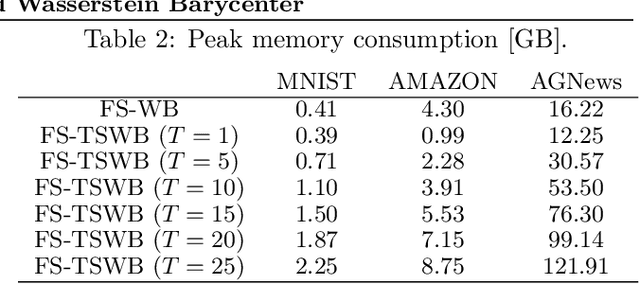
The Wasserstein barycenter has been widely studied in various fields, including natural language processing, and computer vision. However, it requires a high computational cost to solve the Wasserstein barycenter problem because the computation of the Wasserstein distance requires a quadratic time with respect to the number of supports. By contrast, the Wasserstein distance on a tree, called the tree-Wasserstein distance, can be computed in linear time and allows for the fast comparison of a large number of distributions. In this study, we propose a barycenter under the tree-Wasserstein distance, called the fixed support tree-Wasserstein barycenter (FS-TWB) and its extension, called the fixed support tree-sliced Wasserstein barycenter (FS-TSWB). More specifically, we first show that the FS-TWB and FS-TSWB problems are convex optimization problems and can be solved by using the projected subgradient descent. Moreover, we propose a more efficient algorithm to compute the subgradient and objective function value by using the properties of tree-Wasserstein barycenter problems. Through real-world experiments, we show that, by using the proposed algorithm, the FS-TWB and FS-TSWB can be solved two orders of magnitude faster than the original Wasserstein barycenter.
Analyzing the Abstractiveness-Factuality Tradeoff With Nonlinear Abstractiveness Constraints
Aug 05, 2021
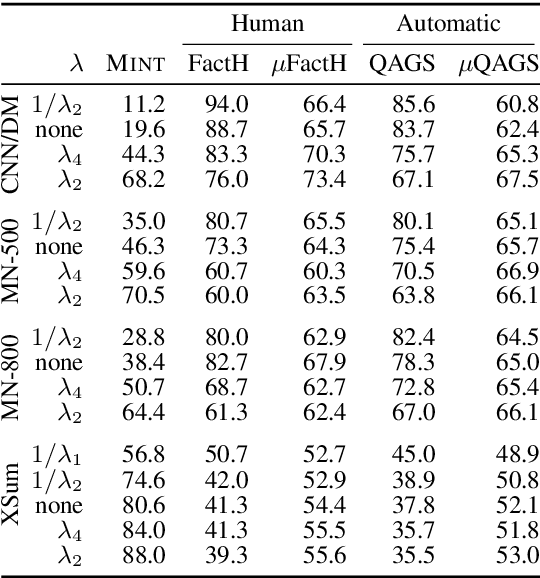
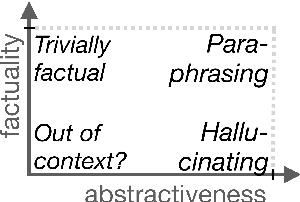
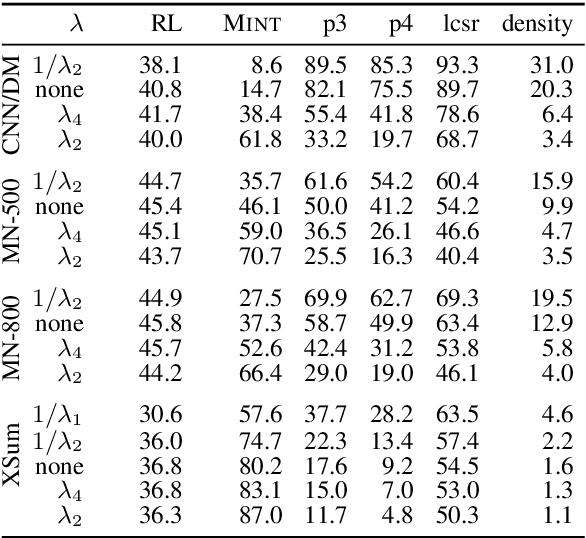
We analyze the tradeoff between factuality and abstractiveness of summaries. We introduce abstractiveness constraints to control the degree of abstractiveness at decoding time, and we apply this technique to characterize the abstractiveness-factuality tradeoff across multiple widely-studied datasets, using extensive human evaluations. We train a neural summarization model on each dataset and visualize the rates of change in factuality as we gradually increase abstractiveness using our abstractiveness constraints. We observe that, while factuality generally drops with increased abstractiveness, different datasets lead to different rates of factuality decay. We propose new measures to quantify the tradeoff between factuality and abstractiveness, incl. muQAGS, which balances factuality with abstractiveness. We also quantify this tradeoff in previous works, aiming to establish baselines for the abstractiveness-factuality tradeoff that future publications can compare against.