 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical and Structural Approaches to Algorithmic Fairness
Jun 24, 2026Modern machine learning systems have outgrown their origins as isolated predictive constructs, evolving into complex socio-technical architectures that actively mediate human opportunity. As algorithms increasingly determine access to economic and social opportunities, it has become widely recognized that these systems are deeply embedded with the structural inequalities and prejudices of their environments. The field of algorithmic fairness emerged in response to the growing recognition that models optimized for predictive accuracy can systematically disadvantage marginalized groups. Early mitigation strategies, however, rested on fragile simplifications that limited their effectiveness in complex socio-technical environments. This thesis identifies and addresses two fundamental limitations of contemporary fairness paradigms: the reliance on deterministic point estimates for auditing and the treatment of individuals as isolated entities devoid of structural context.
WarpRec: Unifying Academic Rigor and Industrial Scale for Responsible, Reproducible, and Efficient Recommendation
Feb 19, 2026Innovation in Recommender Systems is currently impeded by a fractured ecosystem, where researchers must choose between the ease of in-memory experimentation and the costly, complex rewriting required for distributed industrial engines. To bridge this gap, we present WarpRec, a high-performance framework that eliminates this trade-off through a novel, backend-agnostic architecture. It includes 50+ state-of-the-art algorithms, 40 metrics, and 19 filtering and splitting strategies that seamlessly transition from local execution to distributed training and optimization. The framework enforces ecological responsibility by integrating CodeCarbon for real-time energy tracking, showing that scalability need not come at the cost of scientific integrity or sustainability. Furthermore, WarpRec anticipates the shift toward Agentic AI, leading Recommender Systems to evolve from static ranking engines into interactive tools within the Generative AI ecosystem. In summary, WarpRec not only bridges the gap between academia and industry but also can serve as the architectural backbone for the next generation of sustainable, agent-ready Recommender Systems. Code is available at https://github.com/sisinflab/warprec/
Size-adaptive Hypothesis Testing for Fairness
Jun 12, 2025



Determining whether an algorithmic decision-making system discriminates against a specific demographic typically involves comparing a single point estimate of a fairness metric against a predefined threshold. This practice is statistically brittle: it ignores sampling error and treats small demographic subgroups the same as large ones. The problem intensifies in intersectional analyses, where multiple sensitive attributes are considered jointly, giving rise to a larger number of smaller groups. As these groups become more granular, the data representing them becomes too sparse for reliable estimation, and fairness metrics yield excessively wide confidence intervals, precluding meaningful conclusions about potential unfair treatments. In this paper, we introduce a unified, size-adaptive, hypothesis-testing framework that turns fairness assessment into an evidence-based statistical decision. Our contribution is twofold. (i) For sufficiently large subgroups, we prove a Central-Limit result for the statistical parity difference, leading to analytic confidence intervals and a Wald test whose type-I (false positive) error is guaranteed at level $\alpha$. (ii) For the long tail of small intersectional groups, we derive a fully Bayesian Dirichlet-multinomial estimator; Monte-Carlo credible intervals are calibrated for any sample size and naturally converge to Wald intervals as more data becomes available. We validate our approach empirically on benchmark datasets, demonstrating how our tests provide interpretable, statistically rigorous decisions under varying degrees of data availability and intersectionality.
Bounded-Abstention Pairwise Learning to Rank
May 29, 2025



Ranking systems influence decision-making in high-stakes domains like health, education, and employment, where they can have substantial economic and social impacts. This makes the integration of safety mechanisms essential. One such mechanism is $\textit{abstention}$, which enables algorithmic decision-making system to defer uncertain or low-confidence decisions to human experts. While abstention have been predominantly explored in the context of classification tasks, its application to other machine learning paradigms remains underexplored. In this paper, we introduce a novel method for abstention in pairwise learning-to-rank tasks. Our approach is based on thresholding the ranker's conditional risk: the system abstains from making a decision when the estimated risk exceeds a predefined threshold. Our contributions are threefold: a theoretical characterization of the optimal abstention strategy, a model-agnostic, plug-in algorithm for constructing abstaining ranking models, and a comprehensive empirical evaluations across multiple datasets, demonstrating the effectiveness of our approach.
DataRec: A Framework for Standardizing Recommendation Data Processing and Analysis
Oct 30, 2024



Thanks to the great interest posed by researchers and companies, recommendation systems became a cornerstone of machine learning applications. However, concerns have arisen recently about the need for reproducibility, making it challenging to identify suitable pipelines. Several frameworks have been proposed to improve reproducibility, covering the entire process from data reading to performance evaluation. Despite this effort, these solutions often overlook the role of data management, do not promote interoperability, and neglect data analysis despite its well-known impact on recommender performance. To address these gaps, we propose DataRec, which facilitates using and manipulating recommendation datasets. DataRec supports reading and writing in various formats, offers filtering and splitting techniques, and enables data distribution analysis using well-known metrics. It encourages a unified approach to data manipulation by allowing data export in formats compatible with several recommendation frameworks.
KGUF: Simple Knowledge-aware Graph-based Recommender with User-based Semantic Features Filtering
Mar 29, 2024



The recent integration of Graph Neural Networks (GNNs) into recommendation has led to a novel family of Collaborative Filtering (CF) approaches, namely Graph Collaborative Filtering (GCF). Following the same GNNs wave, recommender systems exploiting Knowledge Graphs (KGs) have also been successfully empowered by the GCF rationale to combine the representational power of GNNs with the semantics conveyed by KGs, giving rise to Knowledge-aware Graph Collaborative Filtering (KGCF), which use KGs to mine hidden user intent. Nevertheless, empirical evidence suggests that computing and combining user-level intent might not always be necessary, as simpler approaches can yield comparable or superior results while keeping explicit semantic features. Under this perspective, user historical preferences become essential to refine the KG and retain the most discriminating features, thus leading to concise item representation. Driven by the assumptions above, we propose KGUF, a KGCF model that learns latent representations of semantic features in the KG to better define the item profile. By leveraging user profiles through decision trees, KGUF effectively retains only those features relevant to users. Results on three datasets justify KGUF's rationale, as our approach is able to reach performance comparable or superior to SOTA methods while maintaining a simpler formalization. Link to the repository: https://github.com/sisinflab/KGUF.
Demographic Parity Inspector: Fairness Audits via the Explanation Space
Mar 14, 2023



Even if deployed with the best intentions, machine learning methods can perpetuate, amplify or even create social biases. Measures of (un-)fairness have been proposed as a way to gauge the (non-)discriminatory nature of machine learning models. However, proxies of protected attributes causing discriminatory effects remain challenging to address. In this work, we propose a new algorithmic approach that measures group-wise demographic parity violations and allows us to inspect the causes of inter-group discrimination. Our method relies on the novel idea of measuring the dependence of a model on the protected attribute based on the explanation space, an informative space that allows for more sensitive audits than the primary space of input data or prediction distributions, and allowing for the assertion of theoretical demographic parity auditing guarantees. We provide a mathematical analysis, synthetic examples, and experimental evaluation of real-world data. We release an open-source Python package with methods, routines, and tutorials.
Sparse Feature Factorization for Recommender Systems with Knowledge Graphs
Jul 29, 2021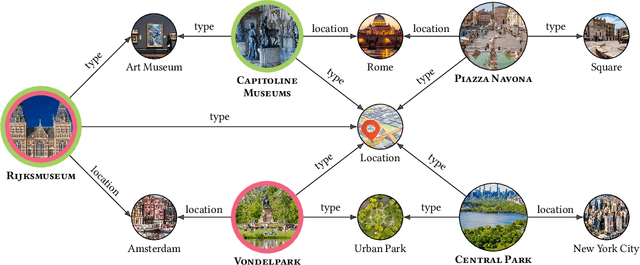
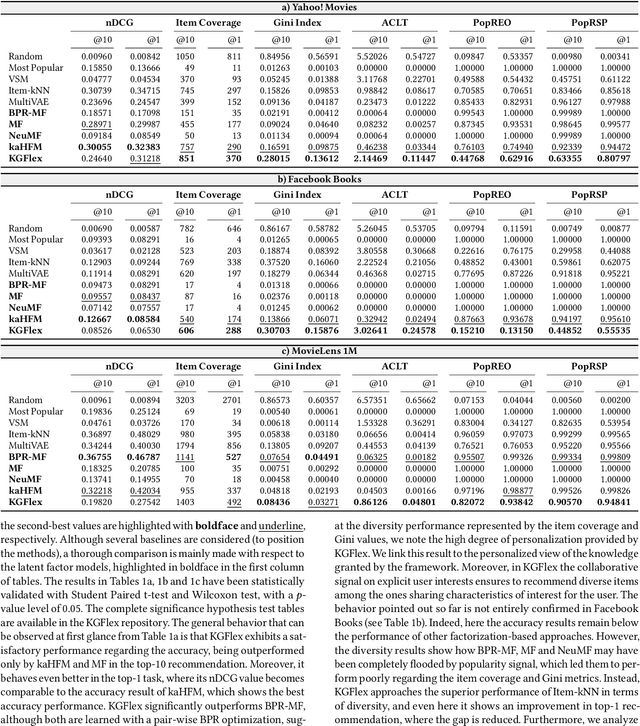
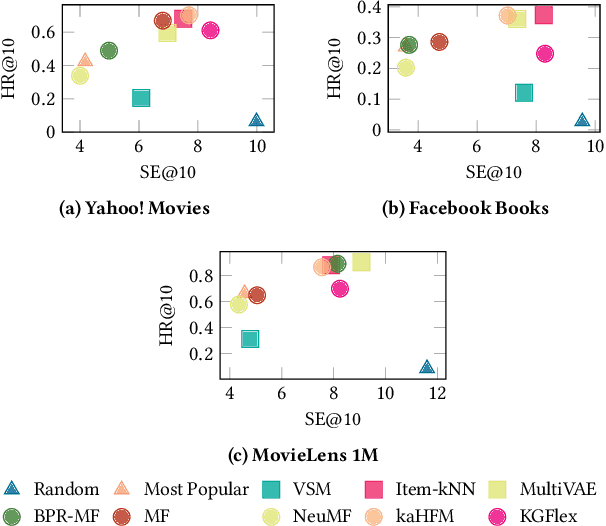
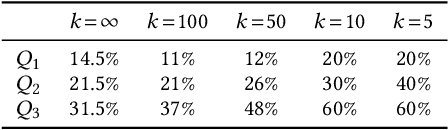
Deep Learning and factorization-based collaborative filtering recommendation models have undoubtedly dominated the scene of recommender systems in recent years. However, despite their outstanding performance, these methods require a training time proportional to the size of the embeddings and it further increases when also side information is considered for the computation of the recommendation list. In fact, in these cases we have that with a large number of high-quality features, the resulting models are more complex and difficult to train. This paper addresses this problem by presenting KGFlex: a sparse factorization approach that grants an even greater degree of expressiveness. To achieve this result, KGFlex analyzes the historical data to understand the dimensions the user decisions depend on (e.g., movie direction, musical genre, nationality of book writer). KGFlex represents each item feature as an embedding and it models user-item interactions as a factorized entropy-driven combination of the item attributes relevant to the user. KGFlex facilitates the training process by letting users update only those relevant features on which they base their decisions. In other words, the user-item prediction is mediated by the user's personal view that considers only relevant features. An extensive experimental evaluation shows the approach's effectiveness, considering the recommendation results' accuracy, diversity, and induced bias. The public implementation of KGFlex is available at https://split.to/kgflex.
Elliot: a Comprehensive and Rigorous Framework for Reproducible Recommender Systems Evaluation
Mar 03, 2021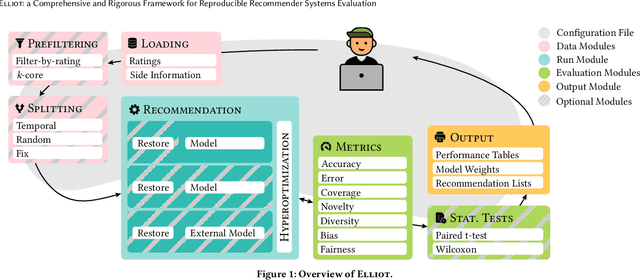
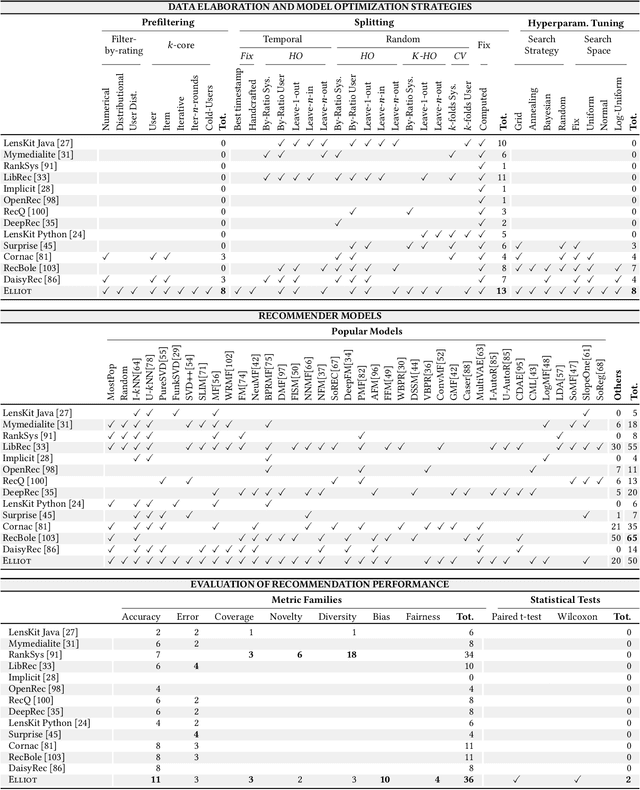


Recommender Systems have shown to be an effective way to alleviate the over-choice problem and provide accurate and tailored recommendations. However, the impressive number of proposed recommendation algorithms, splitting strategies, evaluation protocols, metrics, and tasks, has made rigorous experimental evaluation particularly challenging. Puzzled and frustrated by the continuous recreation of appropriate evaluation benchmarks, experimental pipelines, hyperparameter optimization, and evaluation procedures, we have developed an exhaustive framework to address such needs. Elliot is a comprehensive recommendation framework that aims to run and reproduce an entire experimental pipeline by processing a simple configuration file. The framework loads, filters, and splits the data considering a vast set of strategies (13 splitting methods and 8 filtering approaches, from temporal training-test splitting to nested K-folds Cross-Validation). Elliot optimizes hyperparameters (51 strategies) for several recommendation algorithms (50), selects the best models, compares them with the baselines providing intra-model statistics, computes metrics (36) spanning from accuracy to beyond-accuracy, bias, and fairness, and conducts statistical analysis (Wilcoxon and Paired t-test). The aim is to provide the researchers with a tool to ease (and make them reproducible) all the experimental evaluation phases, from data reading to results collection. Elliot is available on GitHub (https://github.com/sisinflab/elliot).
FedeRank: User Controlled Feedback with Federated Recommender Systems
Jan 20, 2021
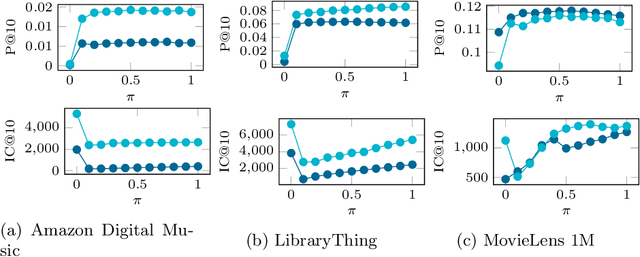
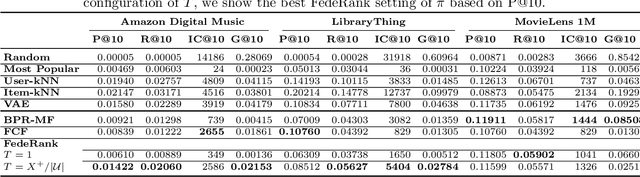
Recommender systems have shown to be a successful representative of how data availability can ease our everyday digital life. However, data privacy is one of the most prominent concerns in the digital era. After several data breaches and privacy scandals, the users are now worried about sharing their data. In the last decade, Federated Learning has emerged as a new privacy-preserving distributed machine learning paradigm. It works by processing data on the user device without collecting data in a central repository. We present FedeRank (https://split.to/federank), a federated recommendation algorithm. The system learns a personal factorization model onto every device. The training of the model is a synchronous process between the central server and the federated clients. FedeRank takes care of computing recommendations in a distributed fashion and allows users to control the portion of data they want to share. By comparing with state-of-the-art algorithms, extensive experiments show the effectiveness of FedeRank in terms of recommendation accuracy, even with a small portion of shared user data. Further analysis of the recommendation lists' diversity and novelty guarantees the suitability of the algorithm in real production environments.