 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Blending Generative Adversarial Image Synthesis with Rendering for Computer Graphics
Jul 31, 2020
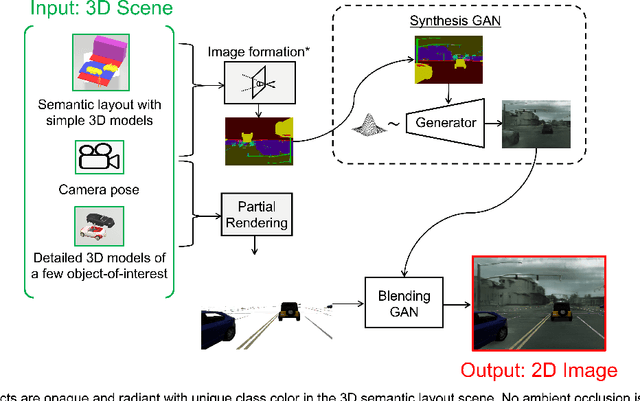
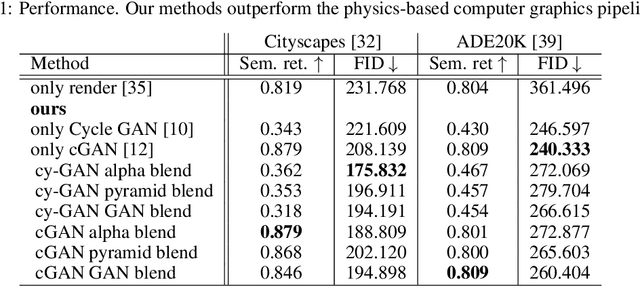
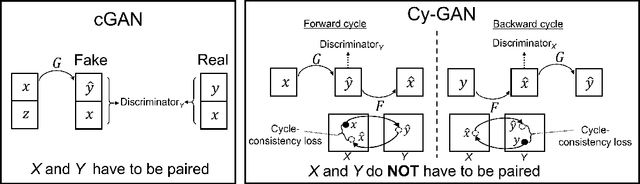

Conventional computer graphics pipelines require detailed 3D models, meshes, textures, and rendering engines to generate 2D images from 3D scenes. These processes are labor-intensive. We introduce Hybrid Neural Computer Graphics (HNCG) as an alternative. The contribution is a novel image formation strategy to reduce the 3D model and texture complexity of computer graphics pipelines. Our main idea is straightforward: Given a 3D scene, render only important objects of interest and use generative adversarial processes for synthesizing the rest of the image. To this end, we propose a novel image formation strategy to form 2D semantic images from 3D scenery consisting of simple object models without textures. These semantic images are then converted into photo-realistic RGB images with a state-of-the-art conditional Generative Adversarial Network (cGAN) based image synthesizer trained on real-world data. Meanwhile, objects of interest are rendered using a physics-based graphics engine. This is necessary as we want to have full control over the appearance of objects of interest. Finally, the partially-rendered and cGAN synthesized images are blended with a blending GAN. We show that the proposed framework outperforms conventional rendering with ablation and comparison studies. Semantic retention and Fr\'echet Inception Distance (FID) measurements were used as the main performance metrics.
Sequential Gallery for Interactive Visual Design Optimization
May 08, 2020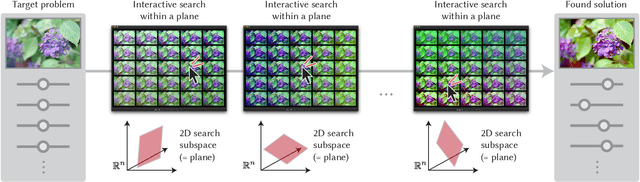
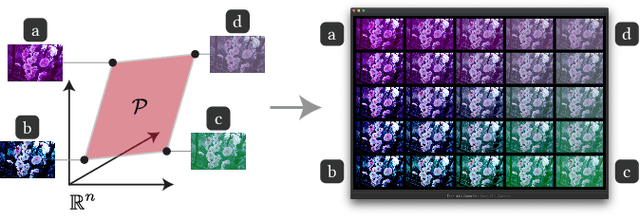


Visual design tasks often involve tuning many design parameters. For example, color grading of a photograph involves many parameters, some of which non-expert users might be unfamiliar with. We propose a novel user-in-the-loop optimization method that allows users to efficiently find an appropriate parameter set by exploring such a high-dimensional design space through much easier two-dimensional search subtasks. This method, called sequential plane search, is based on Bayesian optimization to keep necessary queries to users as few as possible. To help users respond to plane-search queries, we also propose using a gallery-based interface that provides options in the two-dimensional subspace arranged in an adaptive grid view. We call this interactive framework Sequential Gallery since users sequentially select the best option from the options provided by the interface. Our experiment with synthetic functions shows that our sequential plane search can find satisfactory solutions in fewer iterations than baselines. We also conducted a preliminary user study, results of which suggest that novices can effectively complete search tasks with Sequential Gallery in a photo-enhancement scenario.
* To be published at ACM Trans. Graph. (Proc. SIGGRAPH 2020); Project page available at https://koyama.xyz/project/sequential_gallery/
HeadOn: Real-time Reenactment of Human Portrait Videos
May 29, 2018



We propose HeadOn, the first real-time source-to-target reenactment approach for complete human portrait videos that enables transfer of torso and head motion, face expression, and eye gaze. Given a short RGB-D video of the target actor, we automatically construct a personalized geometry proxy that embeds a parametric head, eye, and kinematic torso model. A novel real-time reenactment algorithm employs this proxy to photo-realistically map the captured motion from the source actor to the target actor. On top of the coarse geometric proxy, we propose a video-based rendering technique that composites the modified target portrait video via view- and pose-dependent texturing, and creates photo-realistic imagery of the target actor under novel torso and head poses, facial expressions, and gaze directions. To this end, we propose a robust tracking of the face and torso of the source actor. We extensively evaluate our approach and show significant improvements in enabling much greater flexibility in creating realistic reenacted output videos.
Language-guided Navigation via Cross-Modal Grounding and Alternate Adversarial Learning
Nov 22, 2020
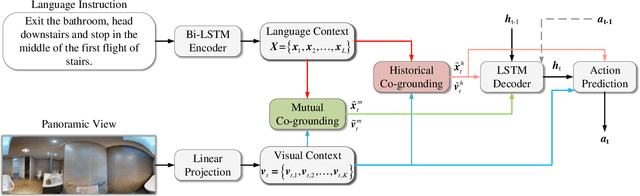
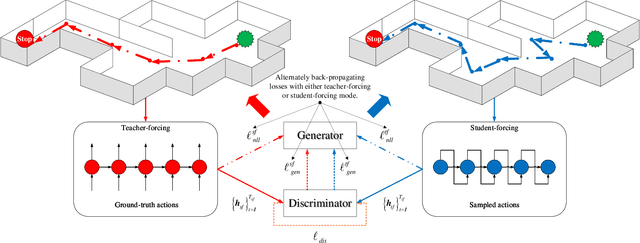

The emerging vision-and-language navigation (VLN) problem aims at learning to navigate an agent to the target location in unseen photo-realistic environments according to the given language instruction. The main challenges of VLN arise mainly from two aspects: first, the agent needs to attend to the meaningful paragraphs of the language instruction corresponding to the dynamically-varying visual environments; second, during the training process, the agent usually imitate the shortest-path to the target location. Due to the discrepancy of action selection between training and inference, the agent solely on the basis of imitation learning does not perform well. Sampling the next action from its predicted probability distribution during the training process allows the agent to explore diverse routes from the environments, yielding higher success rates. Nevertheless, without being presented with the shortest navigation paths during the training process, the agent may arrive at the target location through an unexpected longer route. To overcome these challenges, we design a cross-modal grounding module, which is composed of two complementary attention mechanisms, to equip the agent with a better ability to track the correspondence between the textual and visual modalities. We then propose to recursively alternate the learning schemes of imitation and exploration to narrow the discrepancy between training and inference. We further exploit the advantages of both these two learning schemes via adversarial learning. Extensive experimental results on the Room-to-Room (R2R) benchmark dataset demonstrate that the proposed learning scheme is generalized and complementary to prior arts. Our method performs well against state-of-the-art approaches in terms of effectiveness and efficiency.
Active Visual Information Gathering for Vision-Language Navigation
Jul 23, 2020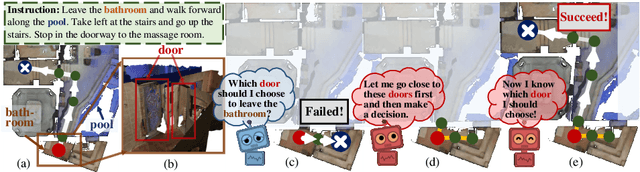
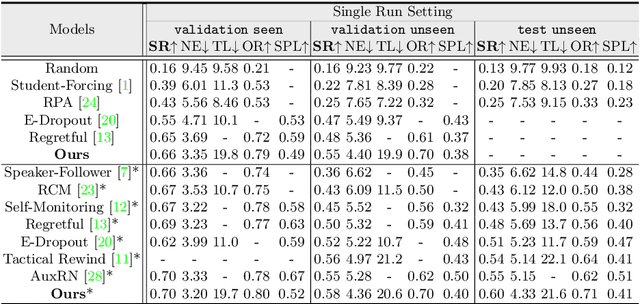
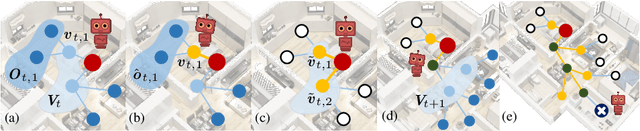
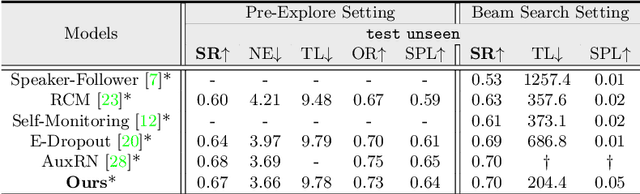
Vision-language navigation (VLN) is the task of entailing an agent to carry out navigational instructions inside photo-realistic environments. One of the key challenges in VLN is how to conduct a robust navigation by mitigating the uncertainty caused by ambiguous instructions and insufficient observation of the environment. Agents trained by current approaches typically suffer from this and would consequently struggle to avoid random and inefficient actions at every step. In contrast, when humans face such a challenge, they can still maintain robust navigation by actively exploring the surroundings to gather more information and thus make more confident navigation decisions. This work draws inspiration from human navigation behavior and endows an agent with an active information gathering ability for a more intelligent vision-language navigation policy. To achieve this, we propose an end-to-end framework for learning an exploration policy that decides i) when and where to explore, ii) what information is worth gathering during exploration, and iii) how to adjust the navigation decision after the exploration. The experimental results show promising exploration strategies emerged from training, which leads to significant boost in navigation performance. On the R2R challenge leaderboard, our agent gets promising results all three VLN settings, i.e., single run, pre-exploration, and beam search.
Generative Adversarial Network-based Synthesis of Visible Faces from Polarimetric Thermal Faces
Aug 08, 2017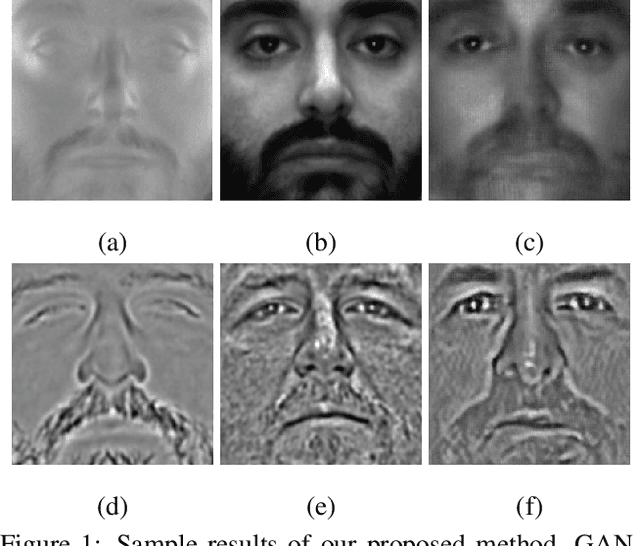

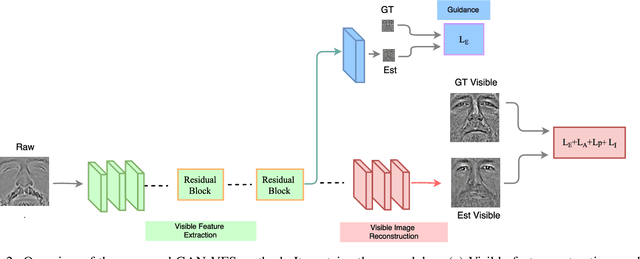

The large domain discrepancy between faces captured in polarimetric (or conventional) thermal and visible domain makes cross-domain face recognition quite a challenging problem for both human-examiners and computer vision algorithms. Previous approaches utilize a two-step procedure (visible feature estimation and visible image reconstruction) to synthesize the visible image given the corresponding polarimetric thermal image. However, these are regarded as two disjoint steps and hence may hinder the performance of visible face reconstruction. We argue that joint optimization would be a better way to reconstruct more photo-realistic images for both computer vision algorithms and human-examiners to examine. To this end, this paper proposes a Generative Adversarial Network-based Visible Face Synthesis (GAN-VFS) method to synthesize more photo-realistic visible face images from their corresponding polarimetric images. To ensure that the encoded visible-features contain more semantically meaningful information in reconstructing the visible face image, a guidance sub-network is involved into the training procedure. To achieve photo realistic property while preserving discriminative characteristics for the reconstructed outputs, an identity loss combined with the perceptual loss are optimized in the framework. Multiple experiments evaluated on different experimental protocols demonstrate that the proposed method achieves state-of-the-art performance.
DocFace: Matching ID Document Photos to Selfies
May 06, 2018
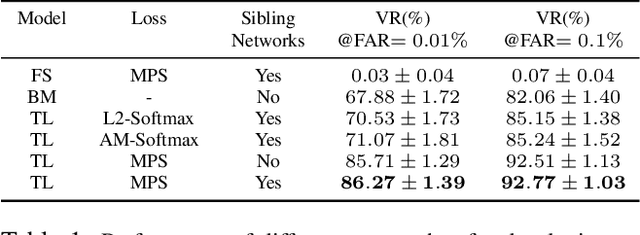

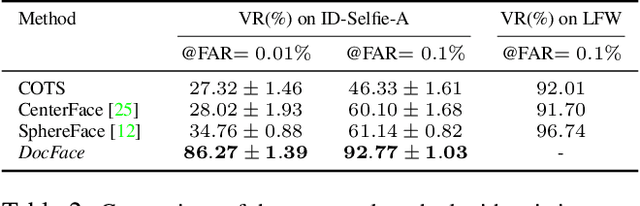
Numerous activities in our daily life, including transactions, access to services and transportation, require us to verify who we are by showing our ID documents containing face images, e.g. passports and driver licenses. An automatic system for matching ID document photos to live face images in real time with high accuracy would speedup the verification process and remove the burden on human operators. In this paper, by employing the transfer learning technique, we propose a new method, DocFace, to train a domain-specific network for ID document photo matching without a large dataset. Compared with the baseline of applying existing methods for general face recognition to this problem, our method achieves considerable improvement. A cross validation on an ID-Selfie dataset shows that DocFace improves the TAR from 61.14% to 92.77% at FAR=0.1%. Experimental results also indicate that given more training data, a viable system for automatic ID document photo matching can be developed and deployed.
Rendering Natural Camera Bokeh Effect with Deep Learning
Jun 10, 2020



Bokeh is an important artistic effect used to highlight the main object of interest on the photo by blurring all out-of-focus areas. While DSLR and system camera lenses can render this effect naturally, mobile cameras are unable to produce shallow depth-of-field photos due to a very small aperture diameter of their optics. Unlike the current solutions simulating bokeh by applying Gaussian blur to image background, in this paper we propose to learn a realistic shallow focus technique directly from the photos produced by DSLR cameras. For this, we present a large-scale bokeh dataset consisting of 5K shallow / wide depth-of-field image pairs captured using the Canon 7D DSLR with 50mm f/1.8 lenses. We use these images to train a deep learning model to reproduce a natural bokeh effect based on a single narrow-aperture image. The experimental results show that the proposed approach is able to render a plausible non-uniform bokeh even in case of complex input data with multiple objects. The dataset, pre-trained models and codes used in this paper are available on the project website.
Development of a High Fidelity Simulator for Generalised Photometric Based Space Object Classification using Machine Learning
Apr 26, 2020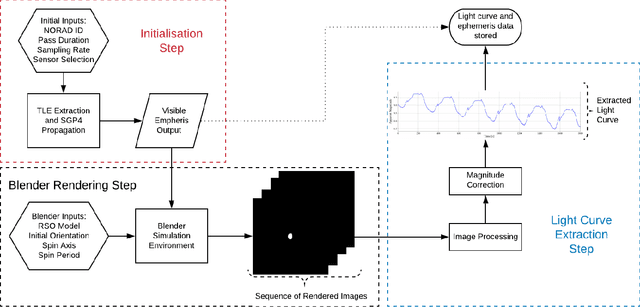



This paper presents the initial stages in the development of a deep learning classifier for generalised Resident Space Object (RSO) characterisation that combines high-fidelity simulated light curves with transfer learning to improve the performance of object characterisation models that are trained on real data. The classification and characterisation of RSOs is a significant goal in Space Situational Awareness (SSA) in order to improve the accuracy of orbital predictions. The specific focus of this paper is the development of a high-fidelity simulation environment for generating realistic light curves. The simulator takes in a textured geometric model of an RSO as well as the objects ephemeris and uses Blender to generate photo-realistic images of the RSO that are then processed to extract the light curve. Simulated light curves have been compared with real light curves extracted from telescope imagery to provide validation for the simulation environment. Future work will involve further validation and the use of the simulator to generate a dataset of realistic light curves for the purpose of training neural networks.
* This paper is a pre-print that appeared in Proceedings of 70th International Astronautical Congress (IAC), 2019
Unsupervised Controllable Generation with Self-Training
Jul 17, 2020
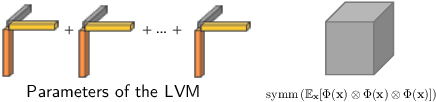
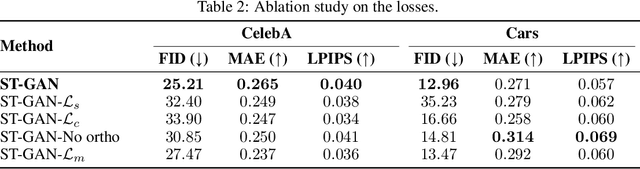

Recent generative adversarial networks (GANs) are able to generate impressive photo-realistic images. However, controllable generation with GANs remains a challenging research problem. Achieving controllable generation requires semantically interpretable and disentangled factors of variation. It is challenging to achieve this goal using simple fixed distributions such as Gaussian distribution. Instead, we propose an unsupervised framework to learn a distribution of latent codes that control the generator through self-training. Self-training provides an iterative feedback in the GAN training, from the discriminator to the generator, and progressively improves the proposal of the latent codes as training proceeds. The latent codes are sampled from a latent variable model that is learned in the feature space of the discriminator. We consider a normalized independent component analysis model and learn its parameters through tensor factorization of the higher-order moments. Our framework exhibits better disentanglement compared to other variants such as the variational autoencoder, and is able to discover semantically meaningful latent codes without any supervision. We demonstrate empirically on both cars and faces datasets that each group of elements in the learned code controls a mode of variation with a semantic meaning, e.g. pose or background change. We also demonstrate with quantitative metrics that our method generates better results compared to other approaches.