 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Saccadic Eye Movements from Brain Signals Using an Endovascular Neural Interface
Jun 09, 2025An Oculomotor Brain-Computer Interface (BCI) records neural activity from regions of the brain involved in planning eye movements and translates this activity into control commands. While previous successful oculomotor BCI studies primarily relied on invasive microelectrode implants in non-human primates, this study investigates the feasibility of an oculomotor BCI using a minimally invasive endovascular Stentrode device implanted near the supplementary motor area in a patient with amyotrophic lateral sclerosis (ALS). To achieve this, self-paced visually-guided and free-viewing saccade tasks were designed, in which the participant performed saccades in four directions (left, right, up, down), with simultaneous recording of endovascular EEG and eye gaze. The visually guided saccades were cued with visual stimuli, whereas the free-viewing saccades were self-directed without explicit cues. The results showed that while the neural responses of visually guided saccades overlapped with the cue-evoked potentials, the free-viewing saccades exhibited distinct saccade-related potentials that began shortly before eye movement, peaked approximately 50 ms after saccade onset, and persisted for around 200 ms. In the frequency domain, these responses appeared as a low-frequency synchronisation below 15 Hz. Classification of 'fixation vs. saccade' was robust, achieving mean area under the receiver operating characteristic curve (AUC) scores of 0.88 within sessions and 0.86 between sessions. In contrast, classifying saccade direction proved more challenging, yielding within-session AUC scores of 0.67 for four-class decoding and up to 0.75 for the best-performing binary comparisons (left vs. up and left vs. down). This proof-of-concept study demonstrates the feasibility of an endovascular oculomotor BCI in an ALS patient, establishing a foundation for future oculomotor BCI studies in human subjects.
City-Wide Perceptions of Neighbourhood Quality using Street View Images
Nov 24, 2022



The interactions of individuals with city neighbourhoods is determined, in part, by the perceived quality of urban environments. Perceived neighbourhood quality is a core component of urban vitality, influencing social cohesion, sense of community, safety, activity and mental health of residents. Large-scale assessment of perceptions of neighbourhood quality was pioneered by the Place Pulse projects. Researchers demonstrated the efficacy of crowd-sourcing perception ratings of image pairs across 56 cities and training a model to predict perceptions from street-view images. Variation across cities may limit Place Pulse's usefulness for assessing within-city perceptions. In this paper, we set forth a protocol for city-specific dataset collection for the perception: 'On which street would you prefer to walk?'. This paper describes our methodology, based in London, including collection of images and ratings, web development, model training and mapping. Assessment of within-city perceptions of neighbourhoods can identify inequities, inform planning priorities, and identify temporal dynamics. Code available: https://emilymuller1991.github.io/urban-perceptions/.
Development of a High Fidelity Simulator for Generalised Photometric Based Space Object Classification using Machine Learning
Apr 26, 2020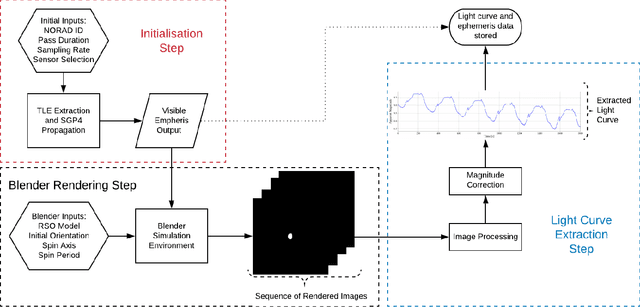



This paper presents the initial stages in the development of a deep learning classifier for generalised Resident Space Object (RSO) characterisation that combines high-fidelity simulated light curves with transfer learning to improve the performance of object characterisation models that are trained on real data. The classification and characterisation of RSOs is a significant goal in Space Situational Awareness (SSA) in order to improve the accuracy of orbital predictions. The specific focus of this paper is the development of a high-fidelity simulation environment for generating realistic light curves. The simulator takes in a textured geometric model of an RSO as well as the objects ephemeris and uses Blender to generate photo-realistic images of the RSO that are then processed to extract the light curve. Simulated light curves have been compared with real light curves extracted from telescope imagery to provide validation for the simulation environment. Future work will involve further validation and the use of the simulator to generate a dataset of realistic light curves for the purpose of training neural networks.
* This paper is a pre-print that appeared in Proceedings of 70th International Astronautical Congress (IAC), 2019
Omni-tomography/Multi-tomography -- Integrating Multiple Modalities for Simultaneous Imaging
Jun 10, 2011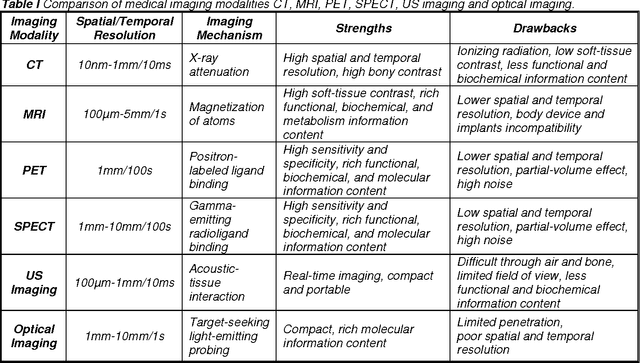
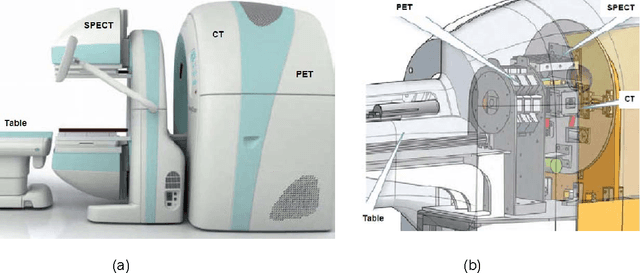

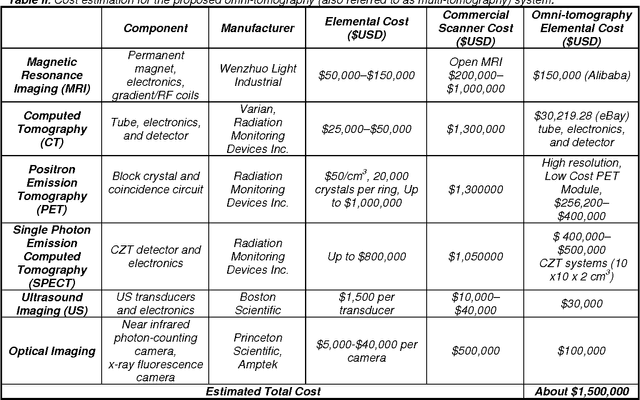
Current tomographic imaging systems need major improvements, especially when multi-dimensional, multi-scale, multi-temporal and multi-parametric phenomena are under investigation. Both preclinical and clinical imaging now depend on in vivo tomography, often requiring separate evaluations by different imaging modalities to define morphologic details, delineate interval changes due to disease or interventions, and study physiological functions that have interconnected aspects. Over the past decade, fusion of multimodality images has emerged with two different approaches: post-hoc image registration and combined acquisition on PET-CT, PET-MRI and other hybrid scanners. There are intrinsic limitations for both the post-hoc image analysis and dual/triple modality approaches defined by registration errors and physical constraints in the acquisition chain. We envision that tomography will evolve beyond current modality fusion and towards grand fusion, a large scale fusion of all or many imaging modalities, which may be referred to as omni-tomography or multi-tomography. Unlike modality fusion, grand fusion is here proposed for truly simultaneous but often localized reconstruction in terms of all or many relevant imaging mechanisms such as CT, MRI, PET, SPECT, US, optical, and possibly more. In this paper, the technical basis for omni-tomography is introduced and illustrated with a top-level design of a next generation scanner, interior tomographic reconstructions of representative modalities, and anticipated applications of omni-tomography.