 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePower Distribution Bridges Sampling, Self-Reward RL, and Self-Distillation
May 06, 2026Recent analyses question whether reinforcement learning (RL) is responsible for strong reasoning in large language models (LLMs). At the same time, distillation and inference-time sampling, including power sampling, have emerged as effective ways to improve LLM performance. However, the relationship among RL, distillation, and sampling remains unclear. In this study, we focus on the power distribution, the target distribution of power sampling, and show that the power distribution bridges sampling, self-reward KL-regularized RL, and self-distillation. From the sampling perspective, we show that inexpensive local approximations cannot reproduce sequence-level power without information about possible suffixes. From the RL perspective, the power distribution is the closed-form optimizer of KL-regularized RL when the model's sequence-level log-probabilities are used as the reward. This identification leads to power self-distillation, an offline distillation surrogate that shares the same target distribution and amortizes the cost of power sampling into supervised training on teacher samples. We further show that power self-distillation can achieve self-reward sharpening, while improvement in a downstream true reward is governed by the covariance between true reward and self-reward under the power distribution. Experiments on reasoning tasks support our analysis: power sampling raises self-reward, true-reward gains depend on alignment with self-reward, and power self-distillation can match or exceed the performance of power sampling at much lower inference cost.
Fix Initial Codes and Iteratively Refine Textual Directions Toward Safe Multi-Turn Code Correction
Apr 27, 2026Recent work on large language models (LLMs) has emphasized the importance of scaling inference compute. From this perspective, the state-of-the-art method Scattered Forest Search (SFS) has been proposed, employing Monte Carlo Tree Search with carefully crafted initial seeds and textual optimization for multi-turn code correction. However, its complexity makes it unclear what factors contribute to improvements in inference performance. To address this problem, we analyze SFS and propose a simpler method, Iterative Refinement of Textual Directions (IRTD), which fixes initial codes and iteratively refines textual directions. Because of the simplicity of IRTD, we theoretically establish the safety of IRTD using Oracle-Guided Inductive Synthesis (OGIS). Experiments on several code generation benchmarks suggest that IRTD achieves inference performance comparable to state-of-the-art methods. These results indicate that, even without complex search structures, refining initial codes with high-quality textual directions alone can effectively improve inference performance.
Can Test-time Computation Mitigate Memorization Bias in Neural Symbolic Regression?
May 28, 2025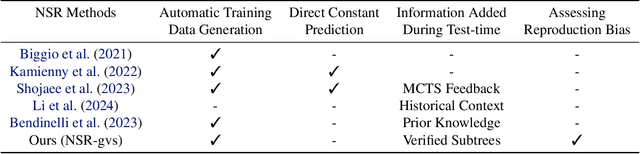



Symbolic regression aims to discover mathematical equations that fit given numerical data. It has been applied in various fields of scientific research, such as producing human-readable expressions that explain physical phenomena. Recently, Neural symbolic regression (NSR) methods that involve Transformers pre-trained on large-scale synthetic datasets have gained attention. While these methods offer advantages such as short inference time, they suffer from low performance, particularly when the number of input variables is large. In this study, we hypothesized that this limitation stems from the memorization bias of Transformers in symbolic regression. We conducted a quantitative evaluation of this bias in Transformers using a synthetic dataset and found that Transformers rarely generate expressions not present in the training data. Additional theoretical analysis reveals that this bias arises from the Transformer's inability to construct expressions compositionally while verifying their numerical validity. We finally examined if tailoring test-time strategies can lead to reduced memorization bias and better performance. We empirically demonstrate that providing additional information to the model at test time can significantly mitigate memorization bias. On the other hand, we also find that reducing memorization bias does not necessarily correlate with improved performance. These findings contribute to a deeper understanding of the limitations of NSR approaches and offer a foundation for designing more robust, generalizable symbolic regression methods. Code is available at https://github.com/Shun-0922/Mem-Bias-NSR .
To CoT or To Loop? A Formal Comparison Between Chain-of-Thought and Looped Transformers
May 25, 2025


Chain-of-Thought (CoT) and Looped Transformers have been shown to empirically improve performance on reasoning tasks and to theoretically enhance expressivity by recursively increasing the number of computational steps. However, their comparative capabilities are still not well understood. In this paper, we provide a formal analysis of their respective strengths and limitations. We show that Looped Transformers can efficiently simulate parallel computations for deterministic tasks, which we formalize as evaluation over directed acyclic graphs. In contrast, CoT with stochastic decoding excels at approximate inference for compositional structures, namely self-reducible problems. These separations suggest the tasks for which depth-driven recursion is more suitable, thereby offering practical cues for choosing between reasoning paradigms.
FairT2I: Mitigating Social Bias in Text-to-Image Generation via Large Language Model-Assisted Detection and Attribute Rebalancing
Feb 06, 2025



The proliferation of Text-to-Image (T2I) models has revolutionized content creation, providing powerful tools for diverse applications ranging from artistic expression to educational material development and marketing. Despite these technological advancements, significant ethical concerns arise from these models' reliance on large-scale datasets that often contain inherent societal biases. These biases are further amplified when AI-generated content is included in training data, potentially reinforcing and perpetuating stereotypes in the generated outputs. In this paper, we introduce FairT2I, a novel framework that harnesses large language models to detect and mitigate social biases in T2I generation. Our framework comprises two key components: (1) an LLM-based bias detection module that identifies potential social biases in generated images based on text prompts, and (2) an attribute rebalancing module that fine-tunes sensitive attributes within the T2I model to mitigate identified biases. Our extensive experiments across various T2I models and datasets show that FairT2I can significantly reduce bias while maintaining high-quality image generation. We conducted both qualitative user studies and quantitative non-parametric analyses in the generated image feature space, building upon the occupational dataset introduced in the Stable Bias study. Our results show that FairT2I successfully mitigates social biases and enhances the diversity of sensitive attributes in generated images. We further demonstrate, using the P2 dataset, that our framework can detect subtle biases that are challenging for human observers to perceive, extending beyond occupation-related prompts. On the basis of these findings, we introduce a new benchmark dataset for evaluating bias in T2I models.
Understanding Generalization in Physics Informed Models through Affine Variety Dimensions
Jan 31, 2025



In recent years, physics-informed machine learning has gained significant attention for its ability to enhance statistical performance and sample efficiency by integrating physical structures into machine learning models. These structures, such as differential equations, conservation laws, and symmetries, serve as inductive biases that can improve the generalization capacity of the hybrid model. However, the mechanisms by which these physical structures enhance generalization capacity are not fully understood, limiting the ability to guarantee the performance of the models. In this study, we show that the generalization performance of linear regressors incorporating differential equation structures is determined by the dimension of the associated affine variety, rather than the number of parameters. This finding enables a unified analysis of various equations, including nonlinear ones. We introduce a method to approximate the dimension of the affine variety and provide experimental evidence to validate our theoretical insights.
Understanding Knowledge Hijack Mechanism in In-context Learning through Associative Memory
Dec 16, 2024



In-context learning (ICL) enables large language models (LLMs) to adapt to new tasks without fine-tuning by leveraging contextual information provided within a prompt. However, ICL relies not only on contextual clues but also on the global knowledge acquired during pretraining for the next token prediction. Analyzing this process has been challenging due to the complex computational circuitry of LLMs. This paper investigates the balance between in-context information and pretrained bigram knowledge in token prediction, focusing on the induction head mechanism, a key component in ICL. Leveraging the fact that a two-layer transformer can implement the induction head mechanism with associative memories, we theoretically analyze the logits when a two-layer transformer is given prompts generated by a bigram model. In the experiments, we design specific prompts to evaluate whether the outputs of a two-layer transformer align with the theoretical results.
Theoretical Analysis of Hierarchical Language Recognition and Generation by Transformers without Positional Encoding
Oct 16, 2024



In this study, we provide constructive proof that Transformers can recognize and generate hierarchical language efficiently with respect to model size, even without the need for a specific positional encoding. Specifically, we show that causal masking and a starting token enable Transformers to compute positional information and depth within hierarchical structures. We demonstrate that Transformers without positional encoding can generate hierarchical languages. Furthermore, we suggest that explicit positional encoding might have a detrimental effect on generalization with respect to sequence length.
On Expressive Power of Looped Transformers: Theoretical Analysis and Enhancement via Timestep Encoding
Oct 02, 2024



Looped Transformers offer advantages in parameter efficiency and Turing completeness. However, their expressive power for function approximation and approximation rate remains underexplored. In this paper, we establish approximation rates of Looped Transformers by defining the concept of the modulus of continuity for sequence-to-sequence functions. This reveals a limitation specific to the looped architecture. That is, the analysis prompts us to incorporate scaling parameters for each loop, conditioned on timestep encoding. Experimental results demonstrate that increasing the number of loops enhances performance, with further gains achieved through the timestep encoding architecture.
Optimal Memorization Capacity of Transformers
Sep 26, 2024
Recent research in the field of machine learning has increasingly focused on the memorization capacity of Transformers, but how efficient they are is not yet well understood. We demonstrate that Transformers can memorize labels with $\tilde{O}(\sqrt{N})$ parameters in a next-token prediction setting for $N$ input sequences of length $n$, which is proved to be optimal up to logarithmic factors. This indicates that Transformers can efficiently perform memorization with little influence from the input length $n$ owing to the benefit of parameter sharing. We also analyze the memorization capacity in the sequence-to-sequence setting, and find that $\tilde{O}(\sqrt{nN})$ parameters are not only sufficient, but also necessary at least for Transformers with hardmax. These results suggest that while self-attention mechanisms can efficiently identify input sequences, the feed-forward network becomes a bottleneck when associating a label to each token.