 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Flightmare: A Flexible Quadrotor Simulator
Sep 01, 2020
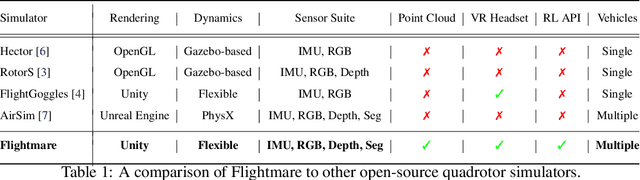
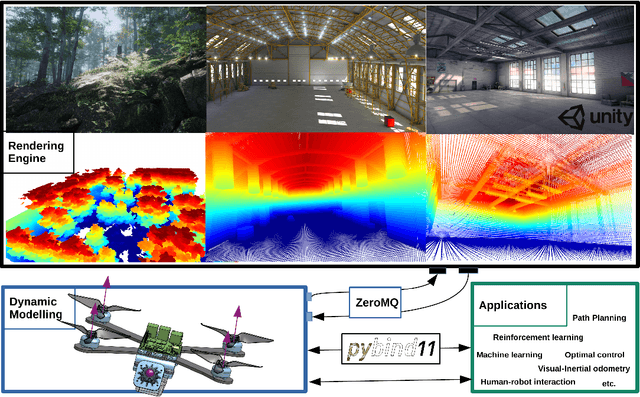


Currently available quadrotor simulators have a rigid and highly-specialized structure: either are they really fast, physically accurate, or photo-realistic. In this work, we propose a paradigm-shift in the development of simulators: moving the trade-off between accuracy and speed from the developers to the end-users. We use this design idea to develop a novel modular quadrotor simulator: Flightmare. Flightmare is composed of two main components: a configurable rendering engine built on Unity and a flexible physics engine for dynamics simulation. Those two components are totally decoupled and can run independently from each other. This makes our simulator extremely fast: rendering achieves speeds of up to 230 Hz, while physics simulation of up to 200,000 Hz. In addition, Flightmare comes with several desirable features: (i) a large multi-modal sensor suite, including an interface to extract the 3D point-cloud of the scene; (ii) an API for reinforcement learning which can simulate hundreds of quadrotors in parallel; and (iii) an integration with a virtual-reality headset for interaction with the simulated environment. We demonstrate the flexibility of Flightmare by using it for two completely different robotic tasks: learning a sensorimotor control policy for a quadrotor and path-planning in a complex 3D environment.
Transferable Active Grasping and Real Embodied Dataset
Apr 28, 2020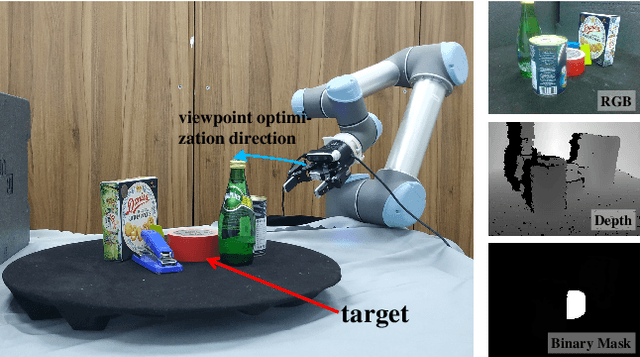



Grasping in cluttered scenes is challenging for robot vision systems, as detection accuracy can be hindered by partial occlusion of objects. We adopt a reinforcement learning (RL) framework and 3D vision architectures to search for feasible viewpoints for grasping by the use of hand-mounted RGB-D cameras. To overcome the disadvantages of photo-realistic environment simulation, we propose a large-scale dataset called Real Embodied Dataset (RED), which includes full-viewpoint real samples on the upper hemisphere with amodal annotation and enables a simulator that has real visual feedback. Based on this dataset, a practical 3-stage transferable active grasping pipeline is developed, that is adaptive to unseen clutter scenes. In our pipeline, we propose a novel mask-guided reward to overcome the sparse reward issue in grasping and ensure category-irrelevant behavior. The grasping pipeline and its possible variants are evaluated with extensive experiments both in simulation and on a real-world UR-5 robotic arm.
Adversarial Privacy-preserving Filter
Jul 25, 2020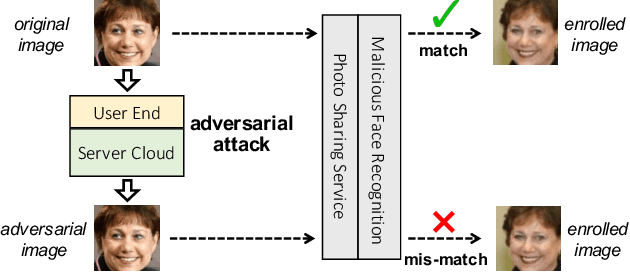
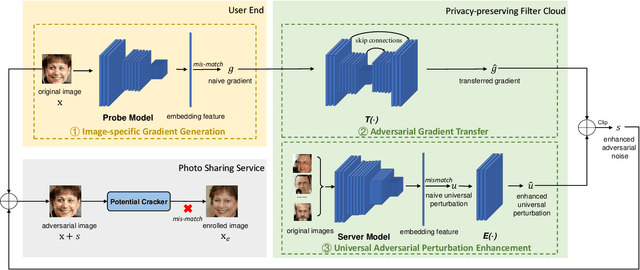
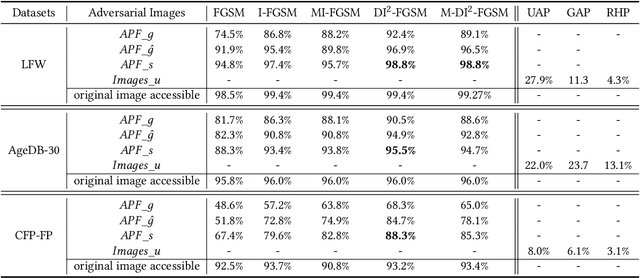
While widely adopted in practical applications, face recognition has been critically discussed regarding the malicious use of face images and the potential privacy problems, e.g., deceiving payment system and causing personal sabotage. Online photo sharing services unintentionally act as the main repository for malicious crawler and face recognition applications. This work aims to develop a privacy-preserving solution, called Adversarial Privacy-preserving Filter (APF), to protect the online shared face images from being maliciously used.We propose an end-cloud collaborated adversarial attack solution to satisfy requirements of privacy, utility and nonaccessibility. Specifically, the solutions consist of three modules: (1) image-specific gradient generation, to extract image-specific gradient in the user end with a compressed probe model; (2) adversarial gradient transfer, to fine-tune the image-specific gradient in the server cloud; and (3) universal adversarial perturbation enhancement, to append image-independent perturbation to derive the final adversarial noise. Extensive experiments on three datasets validate the effectiveness and efficiency of the proposed solution. A prototype application is also released for further evaluation.We hope the end-cloud collaborated attack framework could shed light on addressing the issue of online multimedia sharing privacy-preserving issues from user side.
SocialGuard: An Adversarial Example Based Privacy-Preserving Technique for Social Images
Nov 27, 2020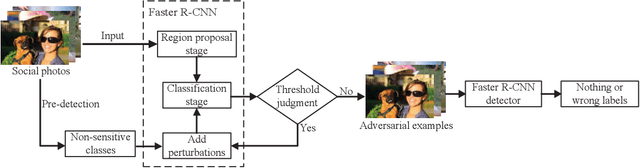
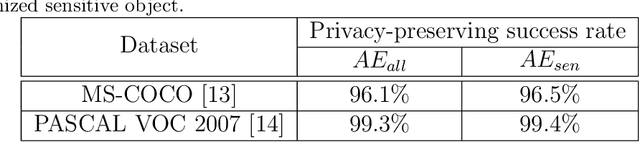

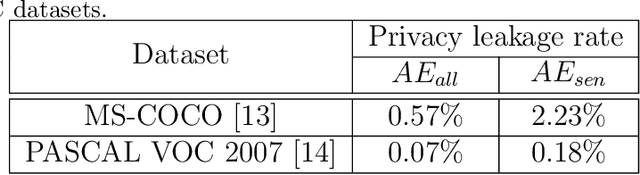
The popularity of various social platforms has prompted more people to share their routine photos online. However, undesirable privacy leakages occur due to such online photo sharing behaviors. Advanced deep neural network (DNN) based object detectors can easily steal users' personal information exposed in shared photos. In this paper, we propose a novel adversarial example based privacy-preserving technique for social images against object detectors based privacy stealing. Specifically, we develop an Object Disappearance Algorithm to craft two kinds of adversarial social images. One can hide all objects in the social images from being detected by an object detector, and the other can make the customized sensitive objects be incorrectly classified by the object detector. The Object Disappearance Algorithm constructs perturbation on a clean social image. After being injected with the perturbation, the social image can easily fool the object detector, while its visual quality will not be degraded. We use two metrics, privacy-preserving success rate and privacy leakage rate, to evaluate the effectiveness of the proposed method. Experimental results show that, the proposed method can effectively protect the privacy of social images. The privacy-preserving success rates of the proposed method on MS-COCO and PASCAL VOC 2007 datasets are high up to 96.1% and 99.3%, respectively, and the privacy leakage rates on these two datasets are as low as 0.57% and 0.07%, respectively. In addition, compared with existing image processing methods (low brightness, noise, blur, mosaic and JPEG compression), the proposed method can achieve much better performance in privacy protection and image visual quality maintenance.
Perception Matters: Exploring Imperceptible and Transferable Anti-forensics for GAN-generated Fake Face Imagery Detection
Oct 29, 2020
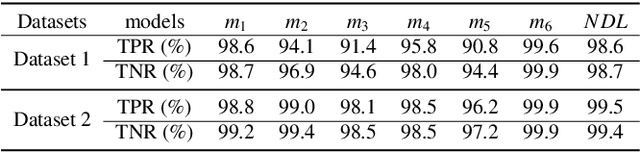
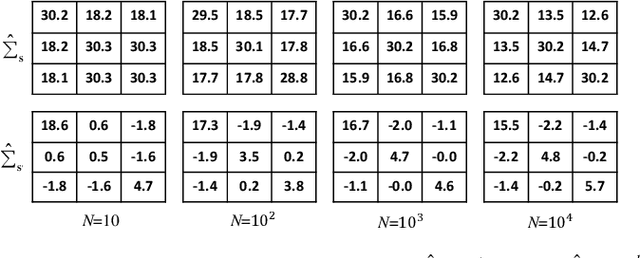
Recently, generative adversarial networks (GANs) can generate photo-realistic fake facial images which are perceptually indistinguishable from real face photos, promoting research on fake face detection. Though fake face forensics can achieve high detection accuracy, their anti-forensic counterparts are less investigated. Here we explore more \textit{imperceptible} and \textit{transferable} anti-forensics for fake face imagery detection based on adversarial attacks. Since facial and background regions are often smooth, even small perturbation could cause noticeable perceptual impairment in fake face images. Therefore it makes existing adversarial attacks ineffective as an anti-forensic method. Our perturbation analysis reveals the intuitive reason of the perceptual degradation issue when directly applying existing attacks. We then propose a novel adversarial attack method, better suitable for image anti-forensics, in the transformed color domain by considering visual perception. Simple yet effective, the proposed method can fool both deep learning and non-deep learning based forensic detectors, achieving higher attack success rate and significantly improved visual quality. Specially, when adversaries consider imperceptibility as a constraint, the proposed anti-forensic method can improve the average attack success rate by around 30\% on fake face images over two baseline attacks. \textit{More imperceptible} and \textit{more transferable}, the proposed method raises new security concerns to fake face imagery detection. We have released our code for public use, and hopefully the proposed method can be further explored in related forensic applications as an anti-forensic benchmark.
Learning to Predict Indoor Illumination from a Single Image
Nov 21, 2017


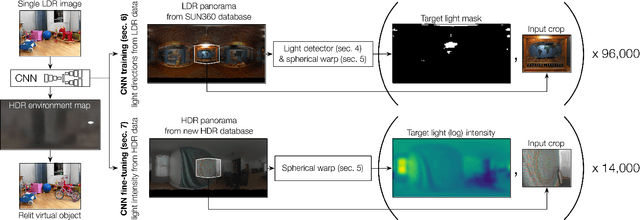
We propose an automatic method to infer high dynamic range illumination from a single, limited field-of-view, low dynamic range photograph of an indoor scene. In contrast to previous work that relies on specialized image capture, user input, and/or simple scene models, we train an end-to-end deep neural network that directly regresses a limited field-of-view photo to HDR illumination, without strong assumptions on scene geometry, material properties, or lighting. We show that this can be accomplished in a three step process: 1) we train a robust lighting classifier to automatically annotate the location of light sources in a large dataset of LDR environment maps, 2) we use these annotations to train a deep neural network that predicts the location of lights in a scene from a single limited field-of-view photo, and 3) we fine-tune this network using a small dataset of HDR environment maps to predict light intensities. This allows us to automatically recover high-quality HDR illumination estimates that significantly outperform previous state-of-the-art methods. Consequently, using our illumination estimates for applications like 3D object insertion, we can achieve results that are photo-realistic, which is validated via a perceptual user study.
Detecting Dominant Vanishing Points in Natural Scenes with Application to Composition-Sensitive Image Retrieval
May 13, 2017

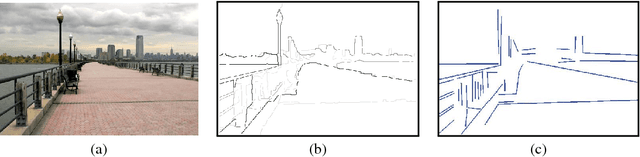
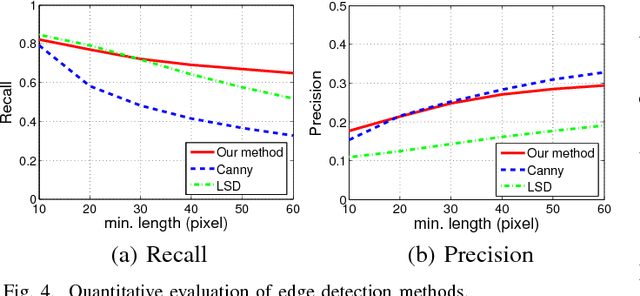
Linear perspective is widely used in landscape photography to create the impression of depth on a 2D photo. Automated understanding of linear perspective in landscape photography has several real-world applications, including aesthetics assessment, image retrieval, and on-site feedback for photo composition, yet adequate automated understanding has been elusive. We address this problem by detecting the dominant vanishing point and the associated line structures in a photo. However, natural landscape scenes pose great technical challenges because often the inadequate number of strong edges converging to the dominant vanishing point is inadequate. To overcome this difficulty, we propose a novel vanishing point detection method that exploits global structures in the scene via contour detection. We show that our method significantly outperforms state-of-the-art methods on a public ground truth landscape image dataset that we have created. Based on the detection results, we further demonstrate how our approach to linear perspective understanding provides on-site guidance to amateur photographers on their work through a novel viewpoint-specific image retrieval system.
Unsupervised Domain Attention Adaptation Network for Caricature Attribute Recognition
Jul 18, 2020
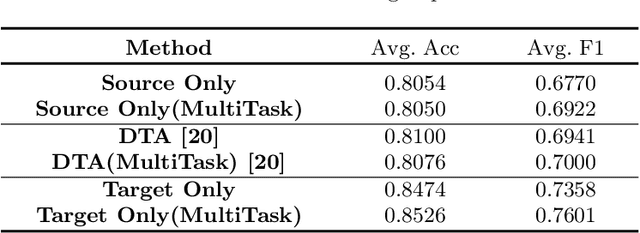
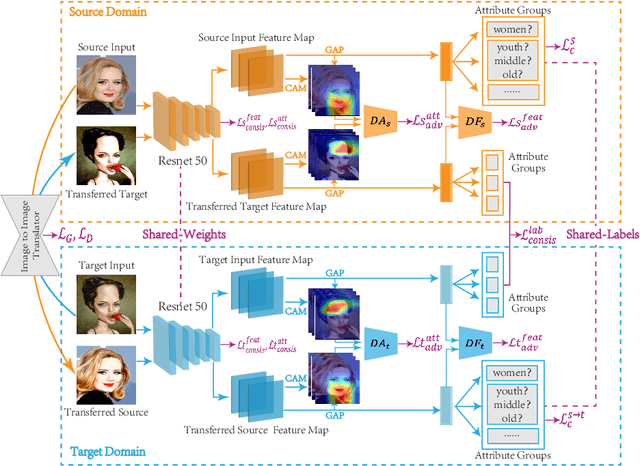
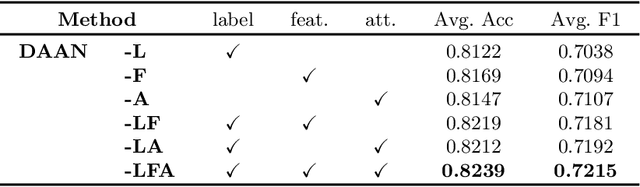
Caricature attributes provide distinctive facial features to help research in Psychology and Neuroscience. However, unlike the facial photo attribute datasets that have a quantity of annotated images, the annotations of caricature attributes are rare. To facility the research in attribute learning of caricatures, we propose a caricature attribute dataset, namely WebCariA. Moreover, to utilize models that trained by face attributes, we propose a novel unsupervised domain adaptation framework for cross-modality (i.e., photos to caricatures) attribute recognition, with an integrated inter- and intra-domain consistency learning scheme. Specifically, the inter-domain consistency learning scheme consisting an image-to-image translator to first fill the domain gap between photos and caricatures by generating intermediate image samples, and a label consistency learning module to align their semantic information. The intra-domain consistency learning scheme integrates the common feature consistency learning module with a novel attribute-aware attention-consistency learning module for a more efficient alignment. We did an extensive ablation study to show the effectiveness of the proposed method. And the proposed method also outperforms the state-of-the-art methods by a margin. The implementation of the proposed method is available at https://github.com/KeleiHe/DAAN.
Implementing AI-powered semantic character recognition in motor racing sports
Jun 01, 2020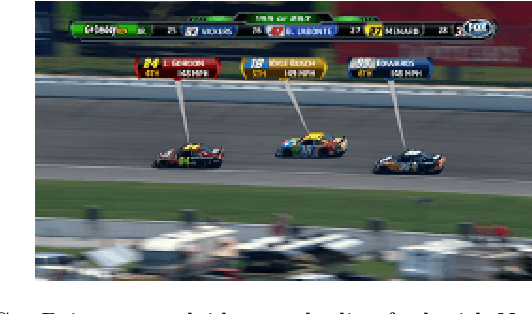


Oftentimes TV producers of motor-racing programs overlay visual and textual media to provide on-screen context about drivers, such as a driver's name, position or photo. Typically this is accomplished by a human producer who visually identifies the drivers on screen, manually toggling the contextual media associated to each one and coordinating with cameramen and other TV producers to keep the racer in the shot while the contextual media is on screen. This labor-intensive and highly dedicated process is mostly suited to static overlays and makes it difficult to overlay contextual information about many drivers at the same time in short shots. This paper presents a system that largely automates these tasks and enables dynamic overlays using deep learning to track the drivers as they move on screen, without human intervention. This system is not merely theoretical, but an implementation has already been deployed during live races by a TV production company at Formula E races. We present the challenges faced during the implementation and discuss the implications. Additionally, we cover future applications and roadmap of this new technological development.
Active Visual Information Gathering for Vision-Language Navigation
Aug 19, 2020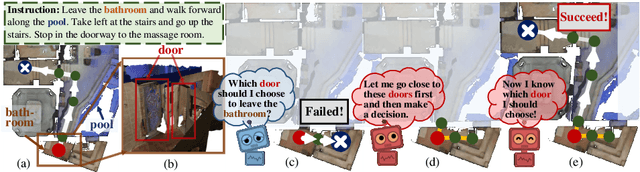
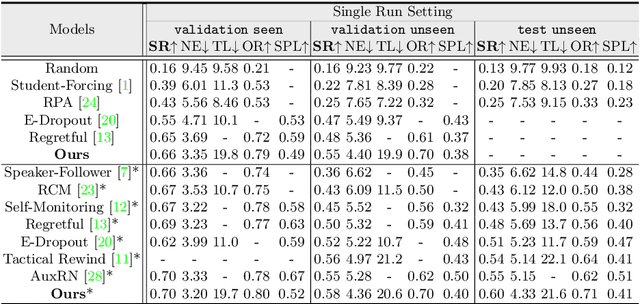
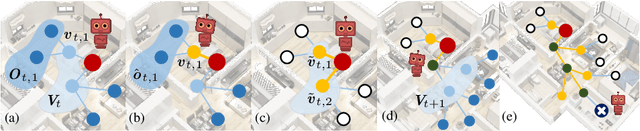
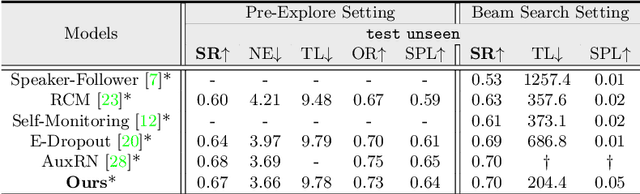
Vision-language navigation (VLN) is the task of entailing an agent to carry out navigational instructions inside photo-realistic environments. One of the key challenges in VLN is how to conduct a robust navigation by mitigating the uncertainty caused by ambiguous instructions and insufficient observation of the environment. Agents trained by current approaches typically suffer from this and would consequently struggle to avoid random and inefficient actions at every step. In contrast, when humans face such a challenge, they can still maintain robust navigation by actively exploring the surroundings to gather more information and thus make more confident navigation decisions. This work draws inspiration from human navigation behavior and endows an agent with an active information gathering ability for a more intelligent vision-language navigation policy. To achieve this, we propose an end-to-end framework for learning an exploration policy that decides i) when and where to explore, ii) what information is worth gathering during exploration, and iii) how to adjust the navigation decision after the exploration. The experimental results show promising exploration strategies emerged from training, which leads to significant boost in navigation performance. On the R2R challenge leaderboard, our agent gets promising results all three VLN settings, i.e., single run, pre-exploration, and beam search.