 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
MusicLM: Generating Music From Text
Jan 26, 2023
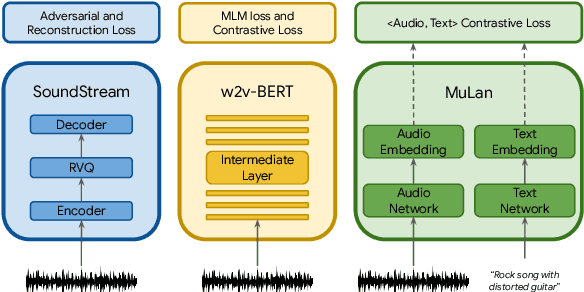
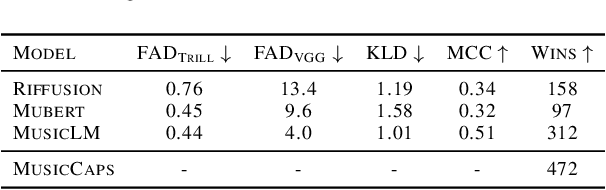
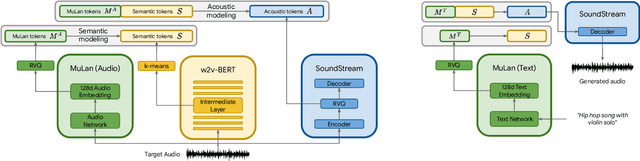
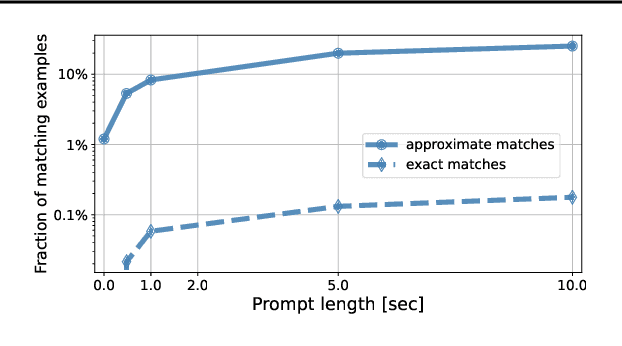
We introduce MusicLM, a model generating high-fidelity music from text descriptions such as "a calming violin melody backed by a distorted guitar riff". MusicLM casts the process of conditional music generation as a hierarchical sequence-to-sequence modeling task, and it generates music at 24 kHz that remains consistent over several minutes. Our experiments show that MusicLM outperforms previous systems both in audio quality and adherence to the text description. Moreover, we demonstrate that MusicLM can be conditioned on both text and a melody in that it can transform whistled and hummed melodies according to the style described in a text caption. To support future research, we publicly release MusicCaps, a dataset composed of 5.5k music-text pairs, with rich text descriptions provided by human experts.
In-depth analysis of music structure as a self-organized network
Mar 21, 2023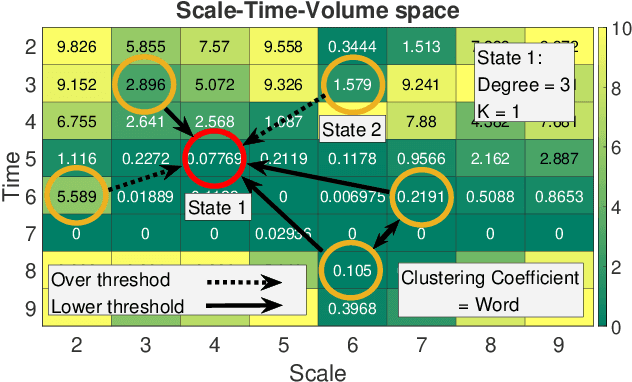
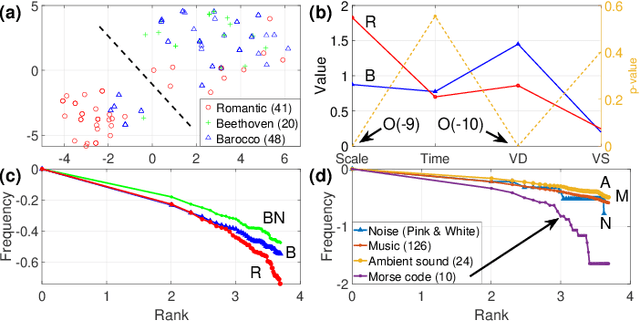
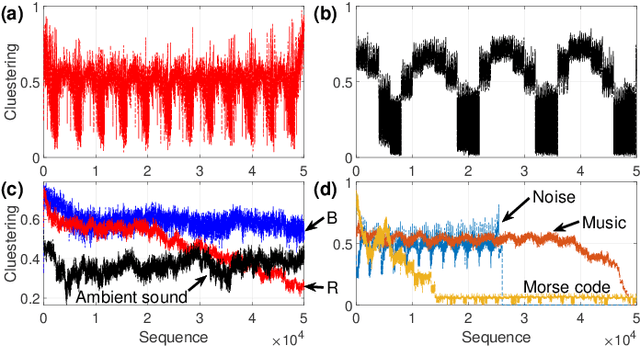
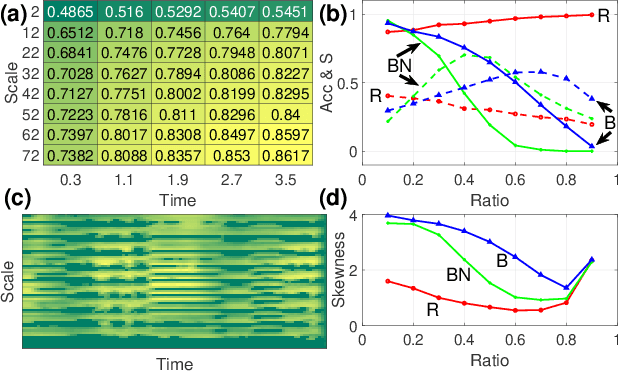
Words in a natural language not only transmit information but also evolve with the development of civilization and human migration. The same is true for music. To understand the complex structure behind the music, we introduced an algorithm called the Essential Element Network (EEN) to encode the audio into text. The network is obtained by calculating the correlations between scales, time, and volume. Optimizing EEN to generate Zipfs law for the frequency and rank of the clustering coefficient enables us to generate and regard the semantic relationships as words. We map these encoded words into the scale-temporal space, which helps us organize systematically the syntax in the deep structure of music. Our algorithm provides precise descriptions of the complex network behind the music, as opposed to the black-box nature of other deep learning approaches. As a result, the experience and properties accumulated through these processes can offer not only a new approach to the applications of Natural Language Processing (NLP) but also an easier and more objective way to analyze the evolution and development of music.
Contrastive Learning for Cross-modal Artist Retrieval
Aug 12, 2023Music retrieval and recommendation applications often rely on content features encoded as embeddings, which provide vector representations of items in a music dataset. Numerous complementary embeddings can be derived from processing items originally represented in several modalities, e.g., audio signals, user interaction data, or editorial data. However, data of any given modality might not be available for all items in any music dataset. In this work, we propose a method based on contrastive learning to combine embeddings from multiple modalities and explore the impact of the presence or absence of embeddings from diverse modalities in an artist similarity task. Experiments on two datasets suggest that our contrastive method outperforms single-modality embeddings and baseline algorithms for combining modalities, both in terms of artist retrieval accuracy and coverage. Improvements with respect to other methods are particularly significant for less popular query artists. We demonstrate our method successfully combines complementary information from diverse modalities, and is more robust to missing modality data (i.e., it better handles the retrieval of artists with different modality embeddings than the query artist's).
Pac-HuBERT: Self-Supervised Music Source Separation via Primitive Auditory Clustering and Hidden-Unit BERT
Apr 04, 2023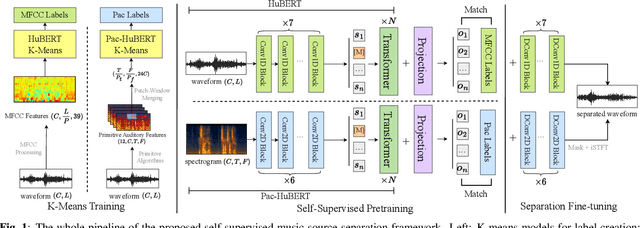

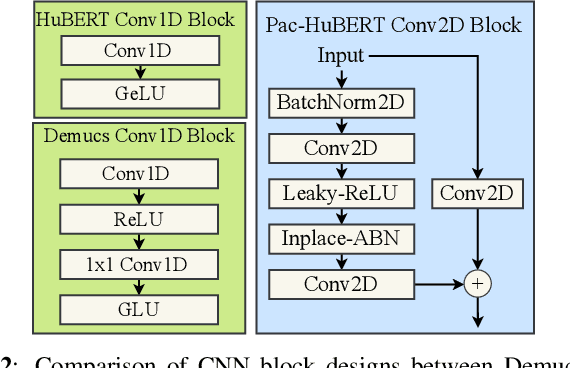
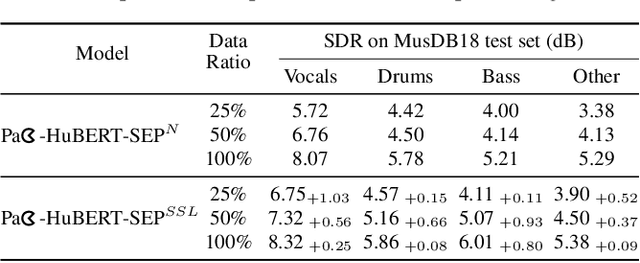
In spite of the progress in music source separation research, the small amount of publicly-available clean source data remains a constant limiting factor for performance. Thus, recent advances in self-supervised learning present a largely-unexplored opportunity for improving separation models by leveraging unlabelled music data. In this paper, we propose a self-supervised learning framework for music source separation inspired by the HuBERT speech representation model. We first investigate the potential impact of the original HuBERT model by inserting an adapted version of it into the well-known Demucs V2 time-domain separation model architecture. We then propose a time-frequency-domain self-supervised model, Pac-HuBERT (for primitive auditory clustering HuBERT), that we later use in combination with a Res-U-Net decoder for source separation. Pac-HuBERT uses primitive auditory features of music as unsupervised clustering labels to initialize the self-supervised pretraining process using the Free Music Archive (FMA) dataset. The resulting framework achieves better source-to-distortion ratio (SDR) performance on the MusDB18 test set than the original Demucs V2 and Res-U-Net models. We further demonstrate that it can boost performance with small amounts of supervised data. Ultimately, our proposed framework is an effective solution to the challenge of limited clean source data for music source separation.
AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining
Aug 10, 2023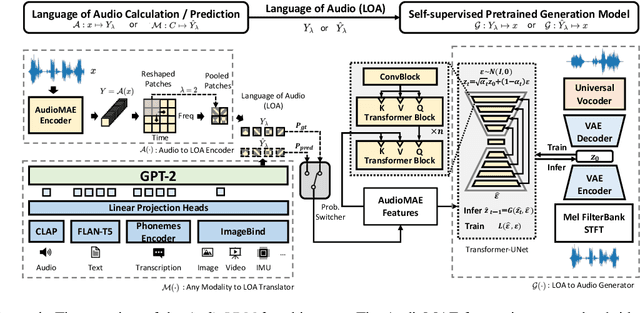
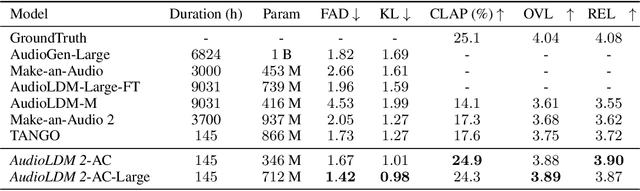

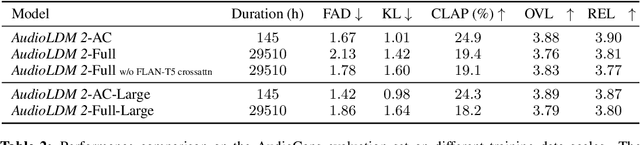
Although audio generation shares commonalities across different types of audio, such as speech, music, and sound effects, designing models for each type requires careful consideration of specific objectives and biases that can significantly differ from those of other types. To bring us closer to a unified perspective of audio generation, this paper proposes a framework that utilizes the same learning method for speech, music, and sound effect generation. Our framework introduces a general representation of audio, called language of audio (LOA). Any audio can be translated into LOA based on AudioMAE, a self-supervised pre-trained representation learning model. In the generation process, we translate any modalities into LOA by using a GPT-2 model, and we perform self-supervised audio generation learning with a latent diffusion model conditioned on LOA. The proposed framework naturally brings advantages such as in-context learning abilities and reusable self-supervised pretrained AudioMAE and latent diffusion models. Experiments on the major benchmarks of text-to-audio, text-to-music, and text-to-speech demonstrate new state-of-the-art or competitive performance to previous approaches. Our demo and code are available at https://audioldm.github.io/audioldm2.
Dance2MIDI: Dance-driven multi-instruments music generation
Jan 22, 2023

Dance-driven music generation aims to generate musical pieces conditioned on dance videos. Previous works focus on monophonic or raw audio generation, while the multiinstruments scenario is under-explored. The challenges of the dance-driven multi-instruments music (MIDI) generation are two-fold: 1) no publicly available multi-instruments MIDI and video paired dataset and 2) the weak correlation between music and video. To tackle these challenges, we build the first multi-instruments MIDI and dance paired dataset (D2MIDI). Based on our proposed dataset, we introduce a multi-instruments MIDI generation framework (Dance2MIDI) conditioned on dance video. Specifically, 1) to model the correlation between music and dance, we encode the dance motion using the GCN, and 2) to generate harmonious and coherent music, we employ Transformer to decode the MIDI sequence. We evaluate the generated music of our framework trained on D2MIDI dataset and demonstrate that our method outperforms existing methods. The data and code are available on https://github.com/Dance2MIDI/Dance2MIDI
Judging a video by its bitstream cover
Sep 14, 2023Classifying videos into distinct categories, such as Sport and Music Video, is crucial for multimedia understanding and retrieval, especially in an age where an immense volume of video content is constantly being generated. Traditional methods require video decompression to extract pixel-level features like color, texture, and motion, thereby increasing computational and storage demands. Moreover, these methods often suffer from performance degradation in low-quality videos. We present a novel approach that examines only the post-compression bitstream of a video to perform classification, eliminating the need for bitstream. We validate our approach using a custom-built data set comprising over 29,000 YouTube video clips, totaling 6,000 hours and spanning 11 distinct categories. Our preliminary evaluations indicate precision, accuracy, and recall rates well over 80%. The algorithm operates approximately 15,000 times faster than real-time for 30fps videos, outperforming traditional Dynamic Time Warping (DTW) algorithm by six orders of magnitude.
Interpretable and Efficient Beamforming-Based Deep Learning for Single Snapshot DOA Estimation
Sep 14, 2023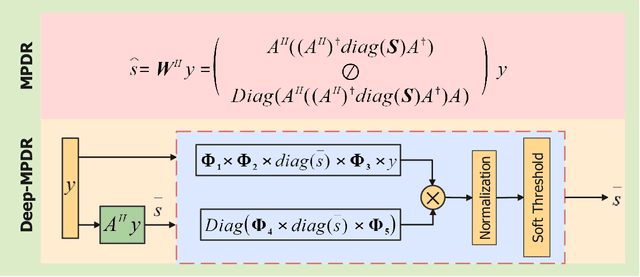
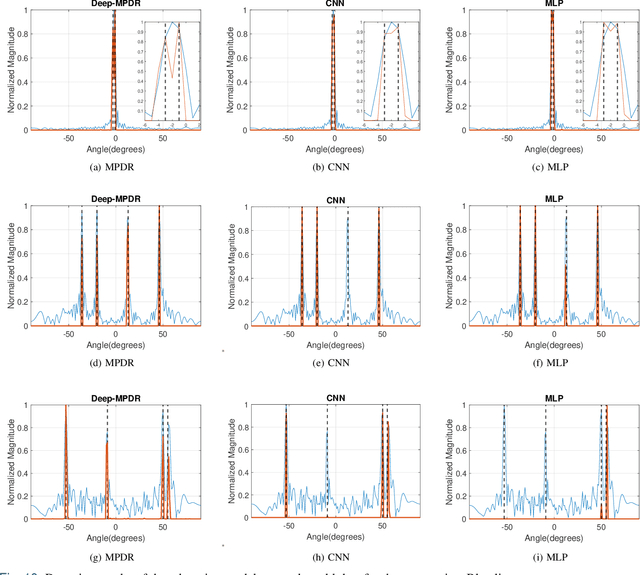
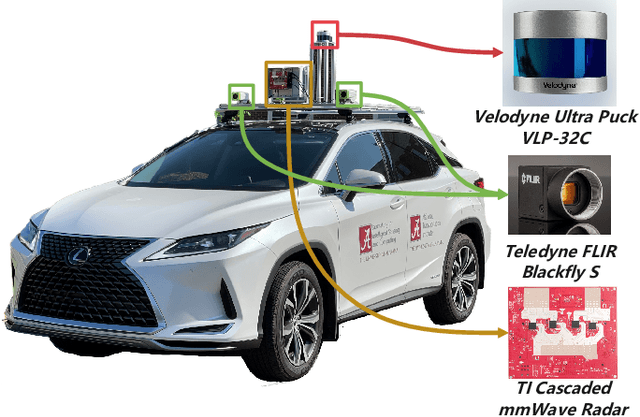
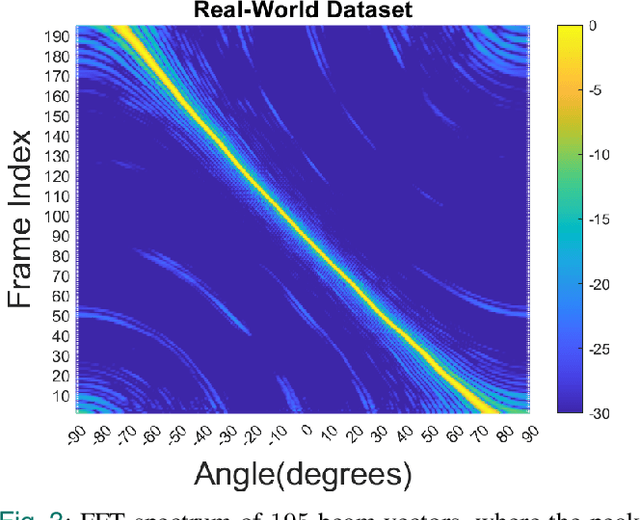
We introduce an interpretable deep learning approach for direction of arrival (DOA) estimation with a single snapshot. Classical subspace-based methods like MUSIC and ESPRIT use spatial smoothing on uniform linear arrays for single snapshot DOA estimation but face drawbacks in reduced array aperture and inapplicability to sparse arrays. Single-snapshot methods such as compressive sensing and iterative adaptation approach (IAA) encounter challenges with high computational costs and slow convergence, hampering real-time use. Recent deep learning DOA methods offer promising accuracy and speed. However, the practical deployment of deep networks is hindered by their black-box nature. To address this, we propose a deep-MPDR network translating minimum power distortionless response (MPDR)-type beamformer into deep learning, enhancing generalization and efficiency. Comprehensive experiments conducted using both simulated and real-world datasets substantiate its dominance in terms of inference time and accuracy in comparison to conventional methods. Moreover, it excels in terms of efficiency, generalizability, and interpretability when contrasted with other deep learning DOA estimation networks.
On Active Learning for Gaussian Process-based Global Sensitivity Analysis
Aug 27, 2023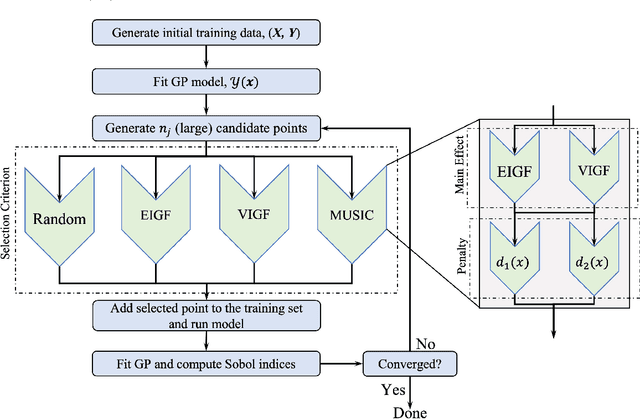

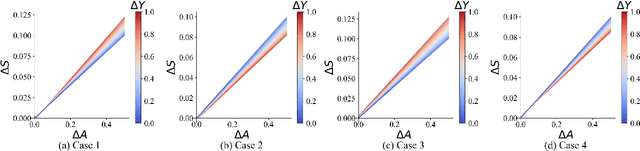
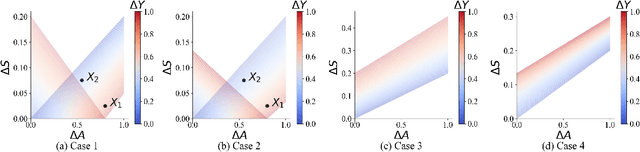
This paper explores the application of active learning strategies to adaptively learn Sobol indices for global sensitivity analysis. We demonstrate that active learning for Sobol indices poses unique challenges due to the definition of the Sobol index as a ratio of variances estimated from Gaussian process surrogates. Consequently, learning strategies must either focus on convergence in the numerator or the denominator of this ratio. However, rapid convergence in either one does not guarantee convergence in the Sobol index. We propose a novel strategy for active learning that focuses on resolving the main effects of the Gaussian process (associated with the numerator of the Sobol index) and compare this with existing strategies based on convergence in the total variance (the denominator of the Sobol index). The new strategy, implemented through a new learning function termed the MUSIC (minimize uncertainty in Sobol index convergence), generally converges in Sobol index error more rapidly than the existing strategies based on the Expected Improvement for Global Fit (EIGF) and the Variance Improvement for Global Fit (VIGF). Both strategies are compared with simple sequential random sampling and the MUSIC learning function generally converges most rapidly for low-dimensional problems. However, for high-dimensional problems, the performance is comparable to random sampling. The new learning strategy is demonstrated for a practical case of adaptive experimental design for large-scale Boundary Layer Wind Tunnel experiments.
Dance with You: The Diversity Controllable Dancer Generation via Diffusion Models
Sep 04, 2023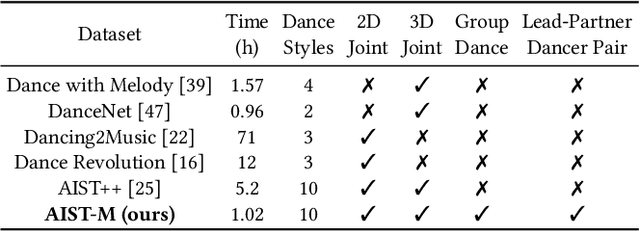
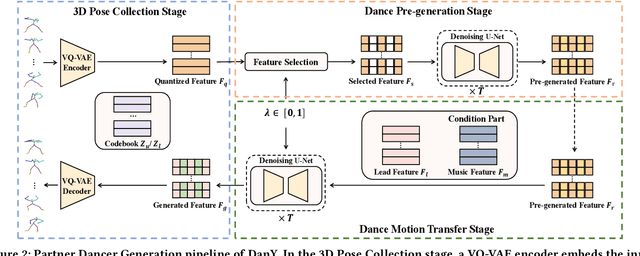
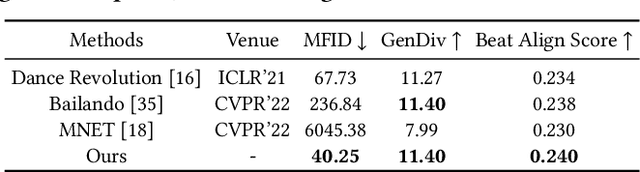
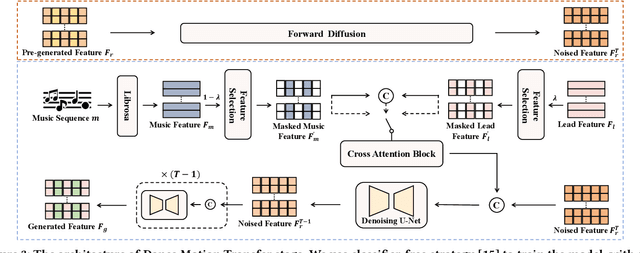
Recently, digital humans for interpersonal interaction in virtual environments have gained significant attention. In this paper, we introduce a novel multi-dancer synthesis task called partner dancer generation, which involves synthesizing virtual human dancers capable of performing dance with users. The task aims to control the pose diversity between the lead dancer and the partner dancer. The core of this task is to ensure the controllable diversity of the generated partner dancer while maintaining temporal coordination with the lead dancer. This scenario varies from earlier research in generating dance motions driven by music, as our emphasis is on automatically designing partner dancer postures according to pre-defined diversity, the pose of lead dancer, as well as the accompanying tunes. To achieve this objective, we propose a three-stage framework called Dance-with-You (DanY). Initially, we employ a 3D Pose Collection stage to collect a wide range of basic dance poses as references for motion generation. Then, we introduce a hyper-parameter that coordinates the similarity between dancers by masking poses to prevent the generation of sequences that are over-diverse or consistent. To avoid the rigidity of movements, we design a Dance Pre-generated stage to pre-generate these masked poses instead of filling them with zeros. After that, a Dance Motion Transfer stage is adopted with leader sequences and music, in which a multi-conditional sampling formula is rewritten to transfer the pre-generated poses into a sequence with a partner style. In practice, to address the lack of multi-person datasets, we introduce AIST-M, a new dataset for partner dancer generation, which is publicly availiable. Comprehensive evaluations on our AIST-M dataset demonstrate that the proposed DanY can synthesize satisfactory partner dancer results with controllable diversity.