 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Edema Estimation From Facial Images Taken Before and After Dialysis via Contrastive Multi-Patient Pre-Training
Dec 15, 2022
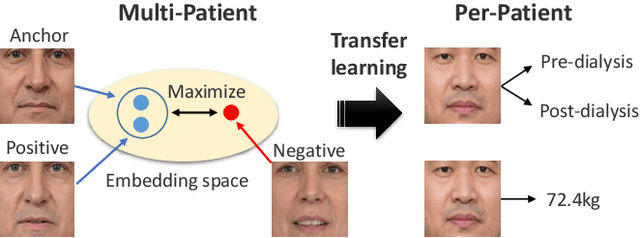
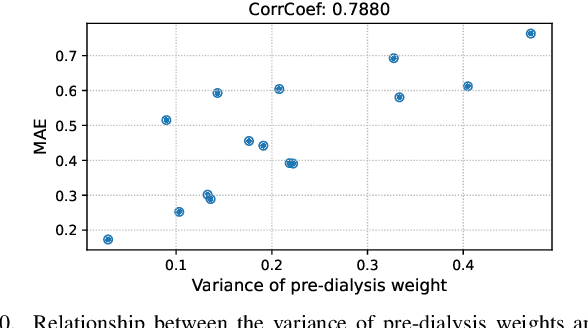
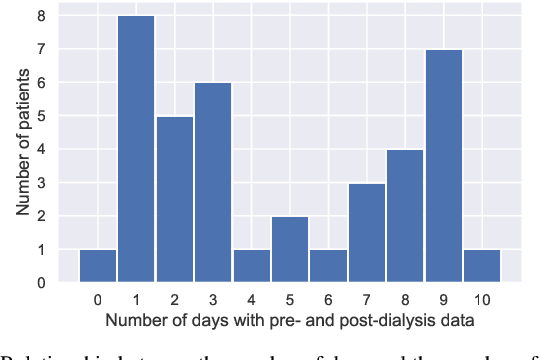
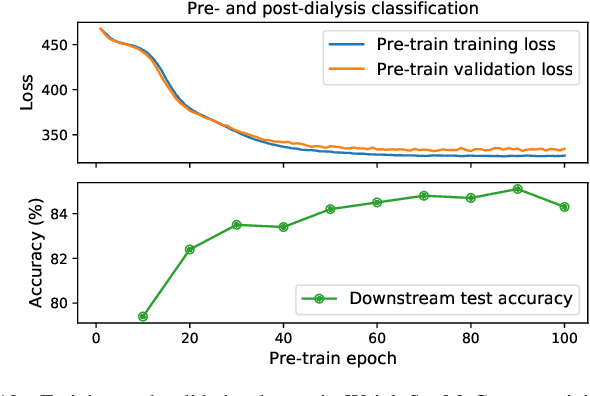
Edema is a common symptom of kidney disease, and quantitative measurement of edema is desired. This paper presents a method to estimate the degree of edema from facial images taken before and after dialysis of renal failure patients. As tasks to estimate the degree of edema, we perform pre- and post-dialysis classification and body weight prediction. We develop a multi-patient pre-training framework for acquiring knowledge of edema and transfer the pre-trained model to a model for each patient. For effective pre-training, we propose a novel contrastive representation learning, called weight-aware supervised momentum contrast (WeightSupMoCo). WeightSupMoCo aims to make feature representations of facial images closer in similarity of patient weight when the pre- and post-dialysis labels are the same. Experimental results show that our pre-training approach improves the accuracy of pre- and post-dialysis classification by 15.1% and reduces the mean absolute error of weight prediction by 0.243 kg compared with training from scratch. The proposed method accurately estimate the degree of edema from facial images; our edema estimation system could thus be beneficial to dialysis patients.
* Published in IEEE Journal of Biomedical and Health Informatics (J-BHI)
A Closer Look at Geometric Temporal Dynamics for Face Anti-Spoofing
Jun 25, 2023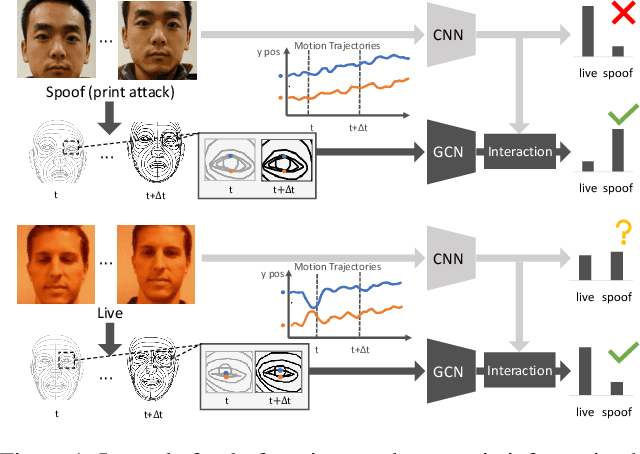
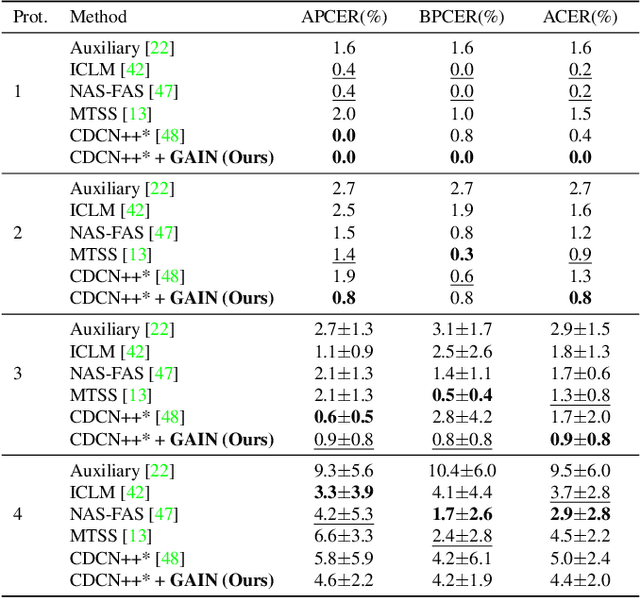
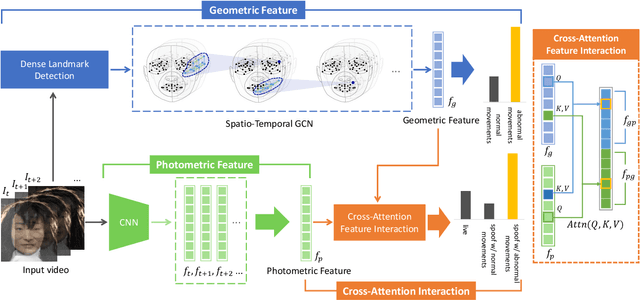
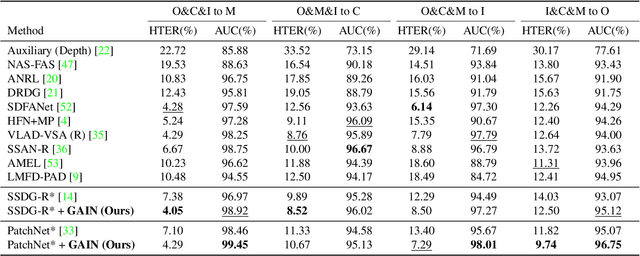
Face anti-spoofing (FAS) is indispensable for a face recognition system. Many texture-driven countermeasures were developed against presentation attacks (PAs), but the performance against unseen domains or unseen spoofing types is still unsatisfactory. Instead of exhaustively collecting all the spoofing variations and making binary decisions of live/spoof, we offer a new perspective on the FAS task to distinguish between normal and abnormal movements of live and spoof presentations. We propose Geometry-Aware Interaction Network (GAIN), which exploits dense facial landmarks with spatio-temporal graph convolutional network (ST-GCN) to establish a more interpretable and modularized FAS model. Additionally, with our cross-attention feature interaction mechanism, GAIN can be easily integrated with other existing methods to significantly boost performance. Our approach achieves state-of-the-art performance in the standard intra- and cross-dataset evaluations. Moreover, our model outperforms state-of-the-art methods by a large margin in the cross-dataset cross-type protocol on CASIA-SURF 3DMask (+10.26% higher AUC score), exhibiting strong robustness against domain shifts and unseen spoofing types.
Deep Learning-based Facial Appearance Simulation Driven by Surgically Planned Craniomaxillofacial Bony Movement
Oct 04, 2022Simulating facial appearance change following bony movement is a critical step in orthognathic surgical planning for patients with jaw deformities. Conventional biomechanics-based methods such as the finite-element method (FEM) are labor intensive and computationally inefficient. Deep learning-based approaches can be promising alternatives due to their high computational efficiency and strong modeling capability. However, the existing deep learning-based method ignores the physical correspondence between facial soft tissue and bony segments and thus is significantly less accurate compared to FEM. In this work, we propose an Attentive Correspondence assisted Movement Transformation network (ACMT-Net) to estimate the facial appearance by transforming the bony movement to facial soft tissue through a point-to-point attentive correspondence matrix. Experimental results on patients with jaw deformity show that our proposed method can achieve comparable facial change prediction accuracy compared with the state-of-the-art FEM-based approach with significantly improved computational efficiency.
Multi-Modal Face Stylization with a Generative Prior
May 29, 2023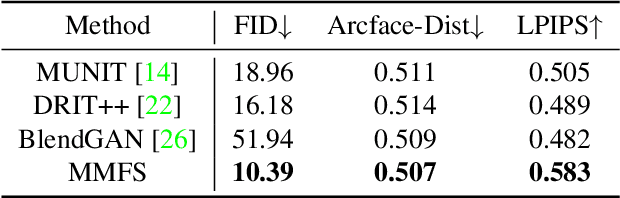
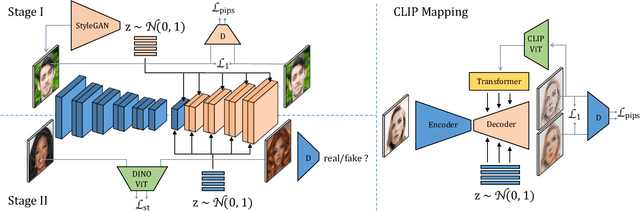


In this work, we introduce a new approach for artistic face stylization. Despite existing methods achieving impressive results in this task, there is still room for improvement in generating high-quality stylized faces with diverse styles and accurate facial reconstruction. Our proposed framework, MMFS, supports multi-modal face stylization by leveraging the strengths of StyleGAN and integrates it into an encoder-decoder architecture. Specifically, we use the mid-resolution and high-resolution layers of StyleGAN as the decoder to generate high-quality faces, while aligning its low-resolution layer with the encoder to extract and preserve input facial details. We also introduce a two-stage training strategy, where we train the encoder in the first stage to align the feature maps with StyleGAN and enable a faithful reconstruction of input faces. In the second stage, the entire network is fine-tuned with artistic data for stylized face generation. To enable the fine-tuned model to be applied in zero-shot and one-shot stylization tasks, we train an additional mapping network from the large-scale Contrastive-Language-Image-Pre-training (CLIP) space to a latent $w+$ space of fine-tuned StyleGAN. Qualitative and quantitative experiments show that our framework achieves superior face stylization performance in both one-shot and zero-shot stylization tasks, outperforming state-of-the-art methods by a large margin.
DisCoHead: Audio-and-Video-Driven Talking Head Generation by Disentangled Control of Head Pose and Facial Expressions
Mar 14, 2023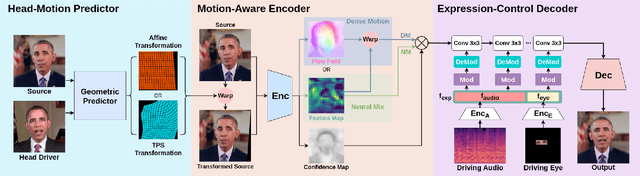
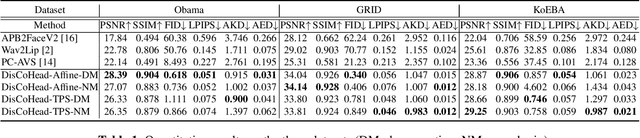


For realistic talking head generation, creating natural head motion while maintaining accurate lip synchronization is essential. To fulfill this challenging task, we propose DisCoHead, a novel method to disentangle and control head pose and facial expressions without supervision. DisCoHead uses a single geometric transformation as a bottleneck to isolate and extract head motion from a head-driving video. Either an affine or a thin-plate spline transformation can be used and both work well as geometric bottlenecks. We enhance the efficiency of DisCoHead by integrating a dense motion estimator and the encoder of a generator which are originally separate modules. Taking a step further, we also propose a neural mix approach where dense motion is estimated and applied implicitly by the encoder. After applying the disentangled head motion to a source identity, DisCoHead controls the mouth region according to speech audio, and it blinks eyes and moves eyebrows following a separate driving video of the eye region, via the weight modulation of convolutional neural networks. The experiments using multiple datasets show that DisCoHead successfully generates realistic audio-and-video-driven talking heads and outperforms state-of-the-art methods. Project page: https://deepbrainai-research.github.io/discohead/
Gradient Attention Balance Network: Mitigating Face Recognition Racial Bias via Gradient Attention
Apr 05, 2023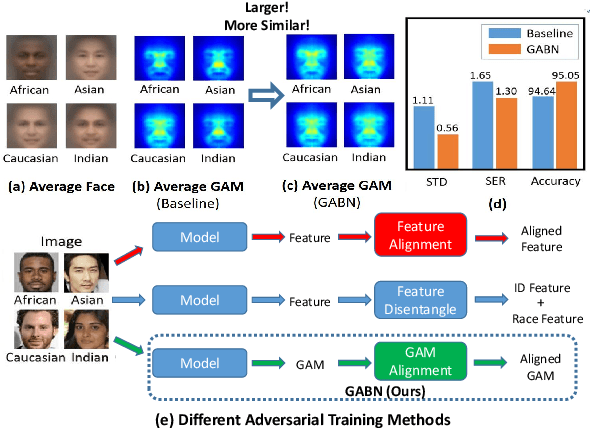
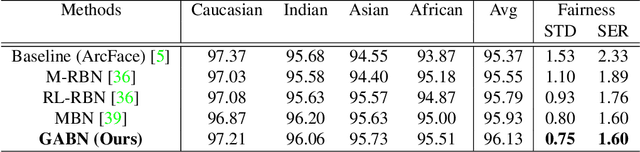

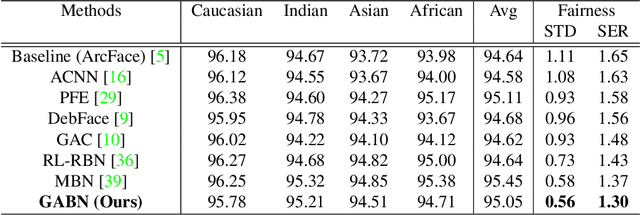
Although face recognition has made impressive progress in recent years, we ignore the racial bias of the recognition system when we pursue a high level of accuracy. Previous work found that for different races, face recognition networks focus on different facial regions, and the sensitive regions of darker-skinned people are much smaller. Based on this discovery, we propose a new de-bias method based on gradient attention, called Gradient Attention Balance Network (GABN). Specifically, we use the gradient attention map (GAM) of the face recognition network to track the sensitive facial regions and make the GAMs of different races tend to be consistent through adversarial learning. This method mitigates the bias by making the network focus on similar facial regions. In addition, we also use masks to erase the Top-N sensitive facial regions, forcing the network to allocate its attention to a larger facial region. This method expands the sensitive region of darker-skinned people and further reduces the gap between GAM of darker-skinned people and GAM of Caucasians. Extensive experiments show that GABN successfully mitigates racial bias in face recognition and learns more balanced performance for people of different races.
Towards Accurate Facial Landmark Detection via Cascaded Transformers
Aug 23, 2022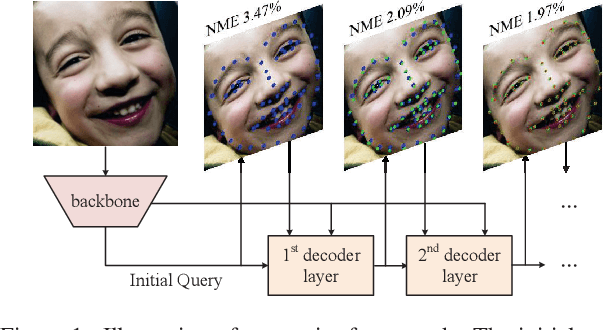
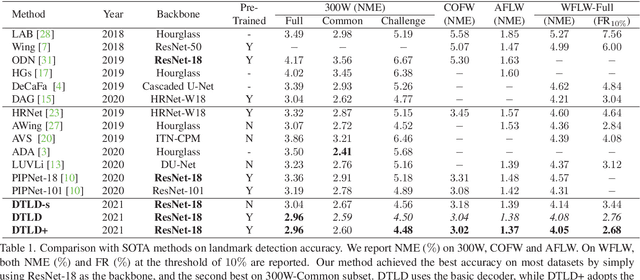
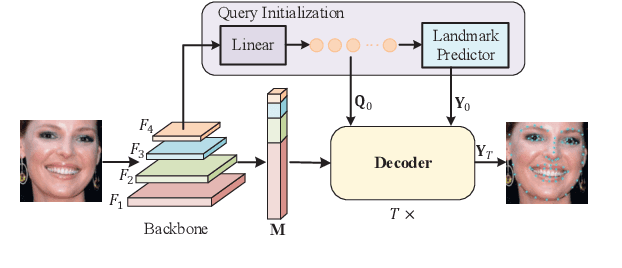

Accurate facial landmarks are essential prerequisites for many tasks related to human faces. In this paper, an accurate facial landmark detector is proposed based on cascaded transformers. We formulate facial landmark detection as a coordinate regression task such that the model can be trained end-to-end. With self-attention in transformers, our model can inherently exploit the structured relationships between landmarks, which would benefit landmark detection under challenging conditions such as large pose and occlusion. During cascaded refinement, our model is able to extract the most relevant image features around the target landmark for coordinate prediction, based on deformable attention mechanism, thus bringing more accurate alignment. In addition, we propose a novel decoder that refines image features and landmark positions simultaneously. With few parameter increasing, the detection performance improves further. Our model achieves new state-of-the-art performance on several standard facial landmark detection benchmarks, and shows good generalization ability in cross-dataset evaluation.
A Comparison of Time-based Models for Multimodal Emotion Recognition
Jun 22, 2023Emotion recognition has become an important research topic in the field of human-computer interaction. Studies on sound and videos to understand emotions focused mainly on analyzing facial expressions and classified 6 basic emotions. In this study, the performance of different sequence models in multi-modal emotion recognition was compared. The sound and images were first processed by multi-layered CNN models, and the outputs of these models were fed into various sequence models. The sequence model is GRU, Transformer, LSTM and Max Pooling. Accuracy, precision, and F1 Score values of all models were calculated. The multi-modal CREMA-D dataset was used in the experiments. As a result of the comparison of the CREMA-D dataset, GRU-based architecture with 0.640 showed the best result in F1 score, LSTM-based architecture with 0.699 in precision metric, while sensitivity showed the best results over time with Max Pooling-based architecture with 0.620. As a result, it has been observed that the sequence models compare performances close to each other.
Fast refacing of MR images with a generative neural network lowers re-identification risk and preserves volumetric consistency
May 26, 2023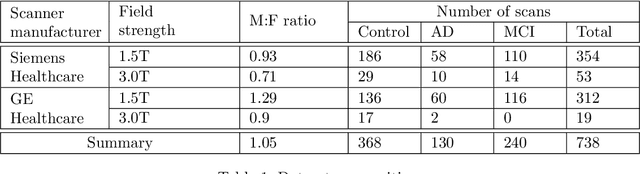
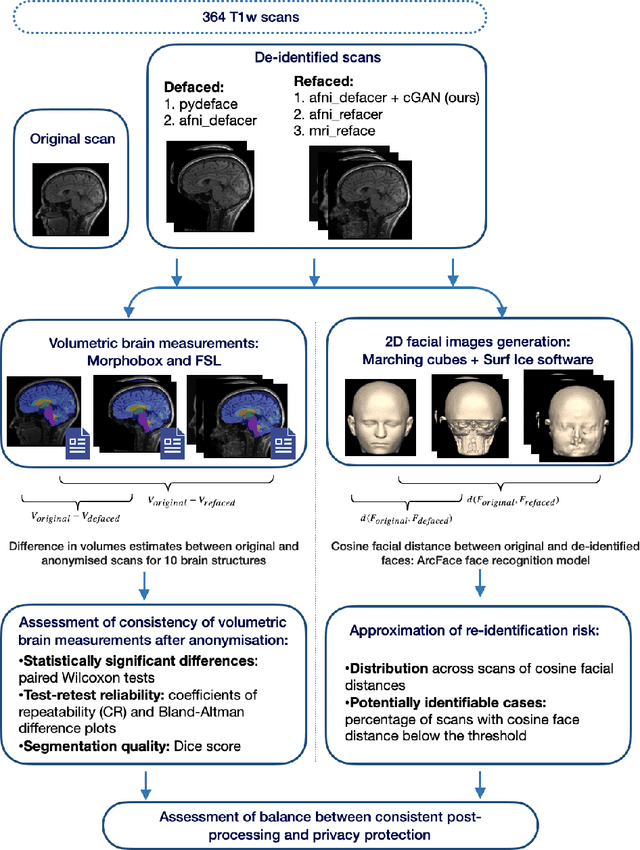
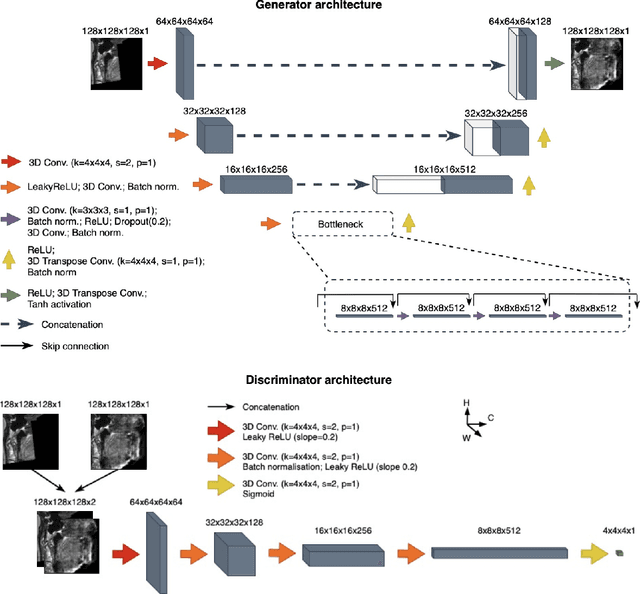

With the rise of open data, identifiability of individuals based on 3D renderings obtained from routine structural magnetic resonance imaging (MRI) scans of the head has become a growing privacy concern. To protect subject privacy, several algorithms have been developed to de-identify imaging data using blurring, defacing or refacing. Completely removing facial structures provides the best re-identification protection but can significantly impact post-processing steps, like brain morphometry. As an alternative, refacing methods that replace individual facial structures with generic templates have a lower effect on the geometry and intensity distribution of original scans, and are able to provide more consistent post-processing results by the price of higher re-identification risk and computational complexity. In the current study, we propose a novel method for anonymised face generation for defaced 3D T1-weighted scans based on a 3D conditional generative adversarial network. To evaluate the performance of the proposed de-identification tool, a comparative study was conducted between several existing defacing and refacing tools, with two different segmentation algorithms (FAST and Morphobox). The aim was to evaluate (i) impact on brain morphometry reproducibility, (ii) re-identification risk, (iii) balance between (i) and (ii), and (iv) the processing time. The proposed method takes 9 seconds for face generation and is suitable for recovering consistent post-processing results after defacing.
Learning-to-Rank Meets Language: Boosting Language-Driven Ordering Alignment for Ordinal Classification
Jun 24, 2023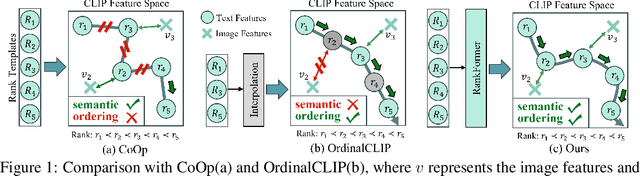

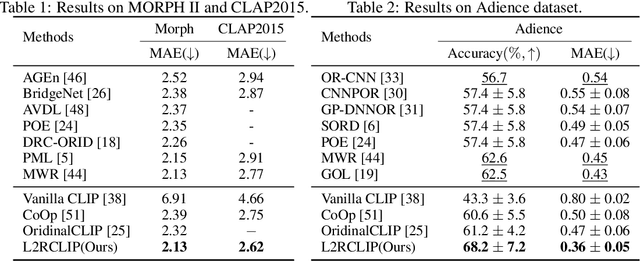
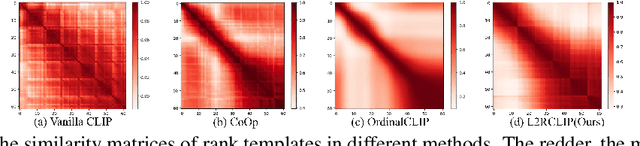
We present a novel language-driven ordering alignment method for ordinal classification. The labels in ordinal classification contain additional ordering relations, making them prone to overfitting when relying solely on training data. Recent developments in pre-trained vision-language models inspire us to leverage the rich ordinal priors in human language by converting the original task into a vision-language alignment task. Consequently, we propose L2RCLIP, which fully utilizes the language priors from two perspectives. First, we introduce a complementary prompt tuning technique called RankFormer, designed to enhance the ordering relation of original rank prompts. It employs token-level attention with residual-style prompt blending in the word embedding space. Second, to further incorporate language priors, we revisit the approximate bound optimization of vanilla cross-entropy loss and restructure it within the cross-modal embedding space. Consequently, we propose a cross-modal ordinal pairwise loss to refine the CLIP feature space, where texts and images maintain both semantic alignment and ordering alignment. Extensive experiments on three ordinal classification tasks, including facial age estimation, historical color image (HCI) classification, and aesthetic assessment demonstrate its promising performance.