 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Lagrangian Motion Magnification with Double Sparse Optical Flow Decomposition
Apr 15, 2022

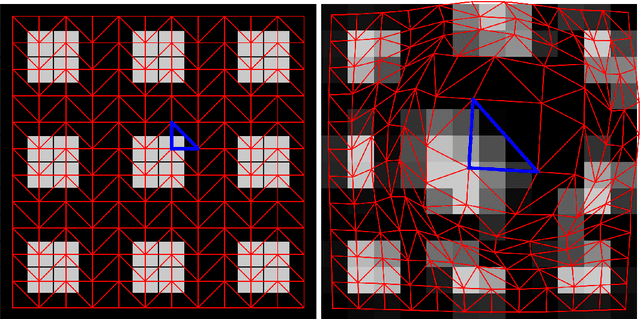
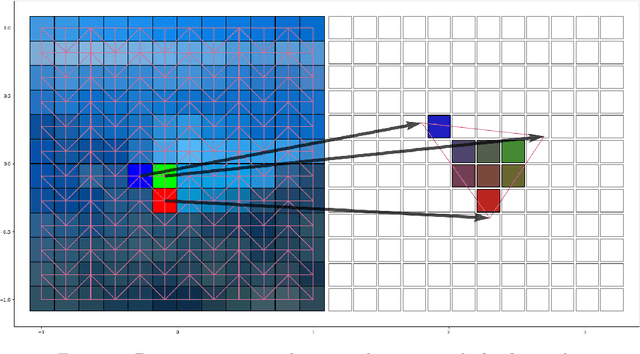
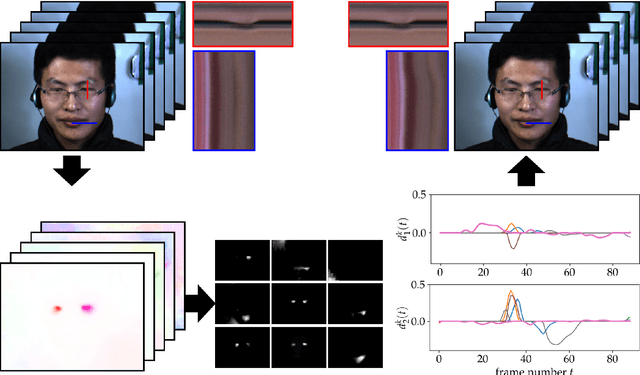
Motion magnification techniques aim at amplifying and hence revealing subtle motion in videos. There are basically two main approaches to reach this goal, namely via Eulerian or Lagrangian techniques. While the first one magnifies motion implicitly by operating directly on image pixels, the Lagrangian approach uses optical flow techniques to extract and amplify pixel trajectories. Microexpressions are fast and spatially small facial expressions that are difficult to detect. In this paper, we propose a novel approach for local Lagrangian motion magnification of facial micromovements. Our contribution is three-fold: first, we fine-tune the recurrent all-pairs field transforms for optical flows (RAFT) deep learning approach for faces by adding ground truth obtained from the variational dense inverse search (DIS) for optical flow algorithm applied to the CASME II video set of faces. This enables us to produce optical flows of facial videos in an efficient and sufficiently accurate way. Second, since facial micromovements are both local in space and time, we propose to approximate the optical flow field by sparse components both in space and time leading to a double sparse decomposition. Third, we use this decomposition to magnify micro-motions in specific areas of the face, where we introduce a new forward warping strategy using a triangular splitting of the image grid and barycentric interpolation of the RGB vectors at the corners of the transformed triangles. We demonstrate the very good performance of our approach by various examples.
Facial Expression Recognition using Facial Landmark Detection and Feature Extraction via Neural Networks
Dec 12, 2018

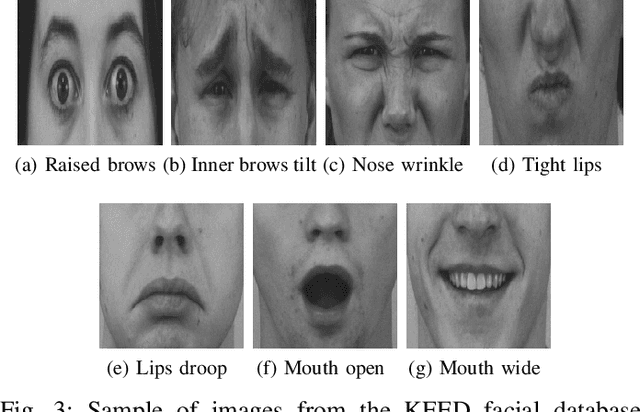
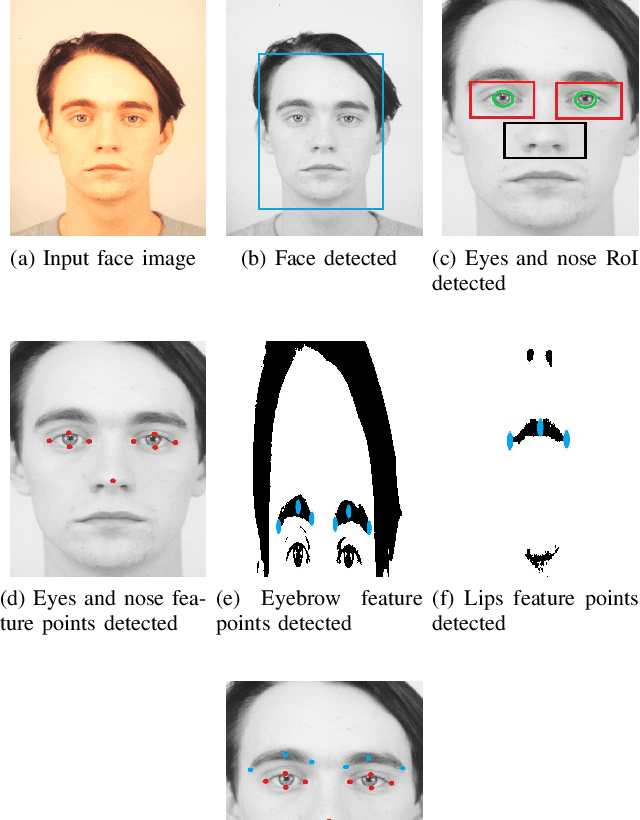
The proposed framework in this paper has the primary objective of classifying the facial expression shown by a person. These classifiable expressions can be any one of the six universal emotions along with the neutral emotion. After the initial facial localization is performed, facial landmark detection and feature extraction are applied where in the landmarks are determined to be the fiducial features: the eyebrows, eyes, nose and lips. This is primarily done using the Sobel operator and the Hough transform followed by Shi Tomasi corner point detection. This leads to input feature vectors being formulated using Euclidean distances and trained into a Multi-Layer Perceptron (MLP) neural network in order to classify the expression being displayed. The results achieved have further dealt with higher uniformity in certain emotions and the inherently subjective nature of expression.
DuetFace: Collaborative Privacy-Preserving Face Recognition via Channel Splitting in the Frequency Domain
Jul 15, 2022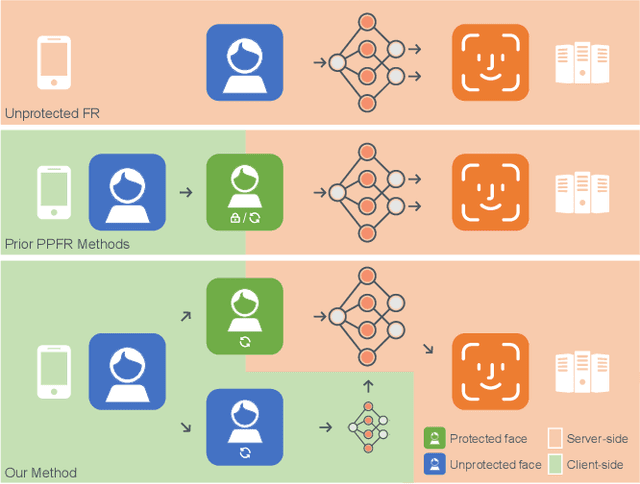
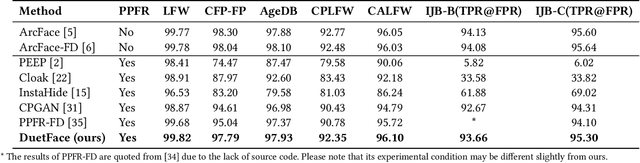
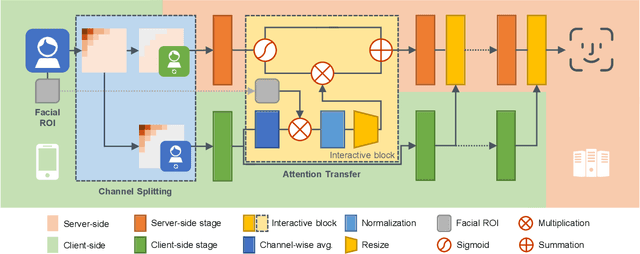
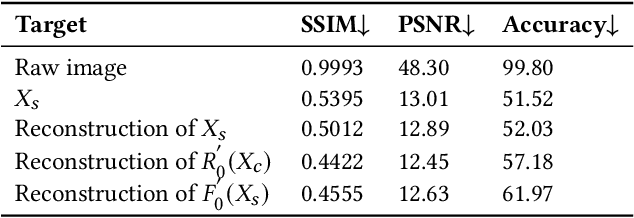
With the wide application of face recognition systems, there is rising concern that original face images could be exposed to malicious intents and consequently cause personal privacy breaches. This paper presents DuetFace, a novel privacy-preserving face recognition method that employs collaborative inference in the frequency domain. Starting from a counterintuitive discovery that face recognition can achieve surprisingly good performance with only visually indistinguishable high-frequency channels, this method designs a credible split of frequency channels by their cruciality for visualization and operates the server-side model on non-crucial channels. However, the model degrades in its attention to facial features due to the missing visual information. To compensate, the method introduces a plug-in interactive block to allow attention transfer from the client-side by producing a feature mask. The mask is further refined by deriving and overlaying a facial region of interest (ROI). Extensive experiments on multiple datasets validate the effectiveness of the proposed method in protecting face images from undesired visual inspection, reconstruction, and identification while maintaining high task availability and performance. Results show that the proposed method achieves a comparable recognition accuracy and computation cost to the unprotected ArcFace and outperforms the state-of-the-art privacy-preserving methods. The source code is available at https://github.com/Tencent/TFace/tree/master/recognition/tasks/duetface.
DigiFace-1M: 1 Million Digital Face Images for Face Recognition
Oct 05, 2022


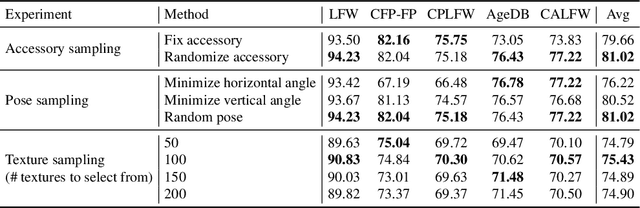
State-of-the-art face recognition models show impressive accuracy, achieving over 99.8% on Labeled Faces in the Wild (LFW) dataset. Such models are trained on large-scale datasets that contain millions of real human face images collected from the internet. Web-crawled face images are severely biased (in terms of race, lighting, make-up, etc) and often contain label noise. More importantly, the face images are collected without explicit consent, raising ethical concerns. To avoid such problems, we introduce a large-scale synthetic dataset for face recognition, obtained by rendering digital faces using a computer graphics pipeline. We first demonstrate that aggressive data augmentation can significantly reduce the synthetic-to-real domain gap. Having full control over the rendering pipeline, we also study how each attribute (e.g., variation in facial pose, accessories and textures) affects the accuracy. Compared to SynFace, a recent method trained on GAN-generated synthetic faces, we reduce the error rate on LFW by 52.5% (accuracy from 91.93% to 96.17%). By fine-tuning the network on a smaller number of real face images that could reasonably be obtained with consent, we achieve accuracy that is comparable to the methods trained on millions of real face images.
Latents2Segments: Disentangling the Latent Space of Generative Models for Semantic Segmentation of Face Images
Jul 06, 2022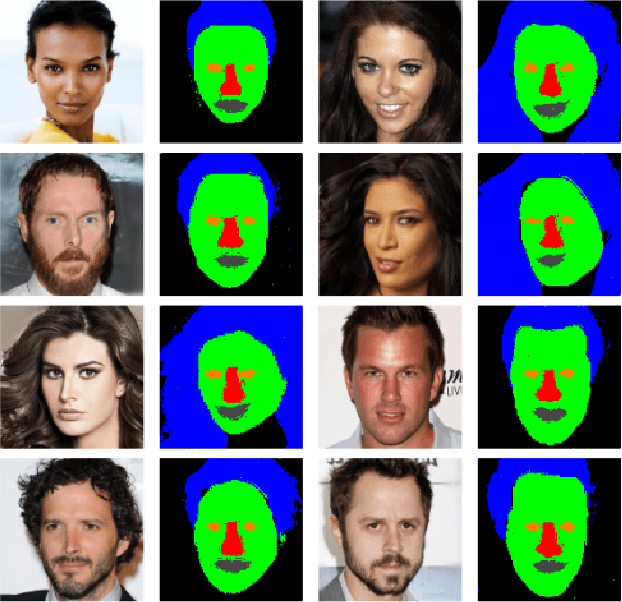
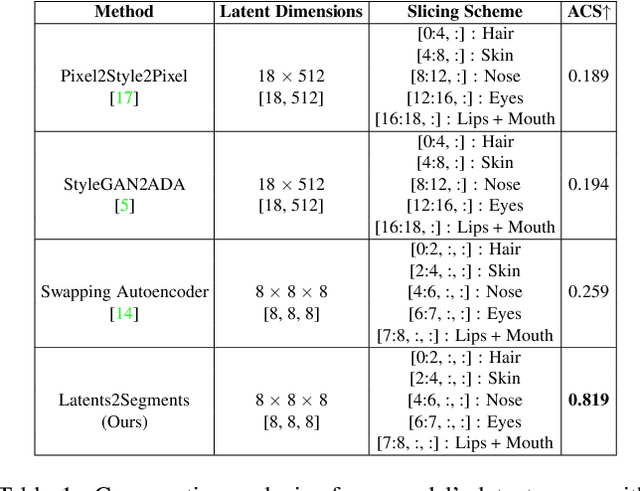
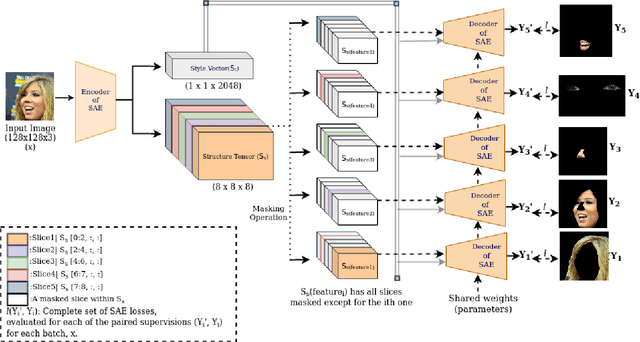

With the advent of an increasing number of Augmented and Virtual Reality applications that aim to perform meaningful and controlled style edits on images of human faces, the impetus for the task of parsing face images to produce accurate and fine-grained semantic segmentation maps is more than ever before. Few State of the Art (SOTA) methods which solve this problem, do so by incorporating priors with respect to facial structure or other face attributes such as expression and pose in their deep classifier architecture. Our endeavour in this work is to do away with the priors and complex pre-processing operations required by SOTA multi-class face segmentation models by reframing this operation as a downstream task post infusion of disentanglement with respect to facial semantic regions of interest (ROIs) in the latent space of a Generative Autoencoder model. We present results for our model's performance on the CelebAMask-HQ and HELEN datasets. The encoded latent space of our model achieves significantly higher disentanglement with respect to semantic ROIs than that of other SOTA works. Moreover, it achieves a 13% faster inference rate and comparable accuracy with respect to the publicly available SOTA for the downstream task of semantic segmentation of face images.
Face to Purchase: Predicting Consumer Choices with Structured Facial and Behavioral Traits Embedding
Jul 14, 2020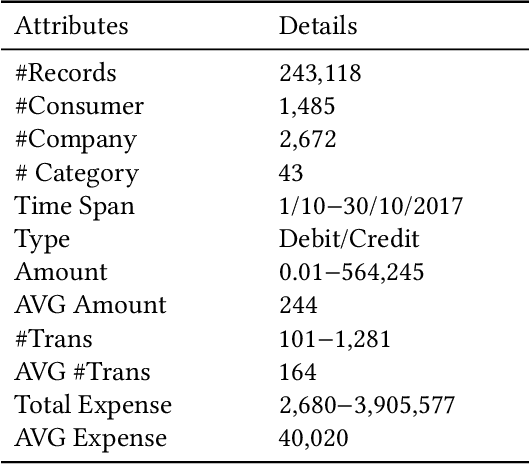
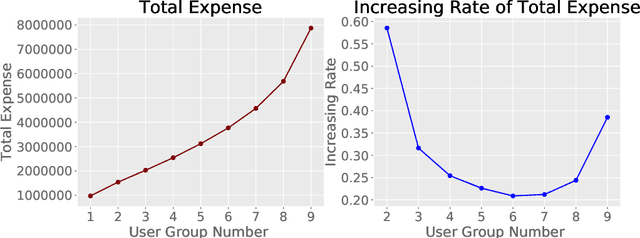
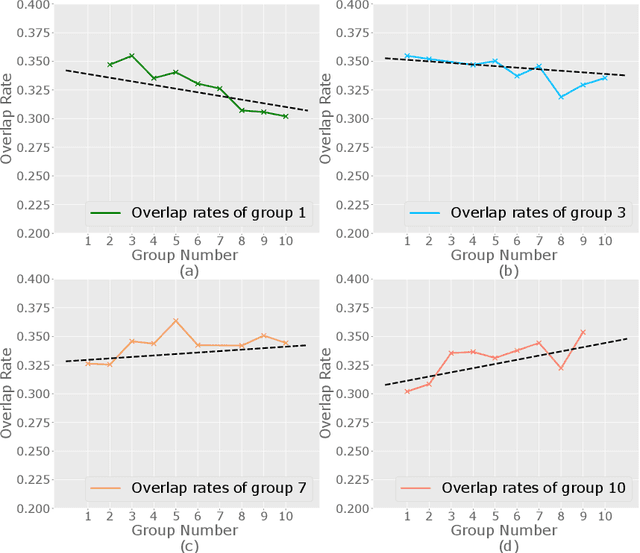
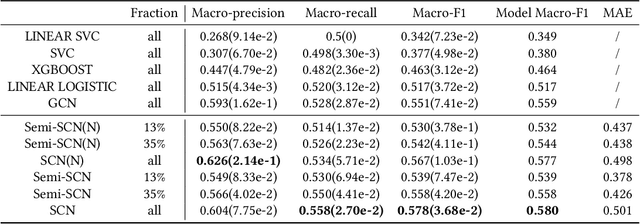
Predicting consumers' purchasing behaviors is critical for targeted advertisement and sales promotion in e-commerce. Human faces are an invaluable source of information for gaining insights into consumer personality and behavioral traits. However, consumer's faces are largely unexplored in previous research, and the existing face-related studies focus on high-level features such as personality traits while neglecting the business significance of learning from facial data. We propose to predict consumers' purchases based on their facial features and purchasing histories. We design a semi-supervised model based on a hierarchical embedding network to extract high-level features of consumers and to predict the top-$N$ purchase destinations of a consumer. Our experimental results on a real-world dataset demonstrate the positive effect of incorporating facial information in predicting consumers' purchasing behaviors.
Constrained Joint Cascade Regression Framework for Simultaneous Facial Action Unit Recognition and Facial Landmark Detection
Sep 23, 2017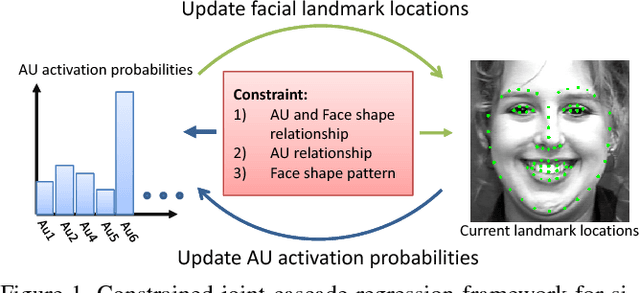
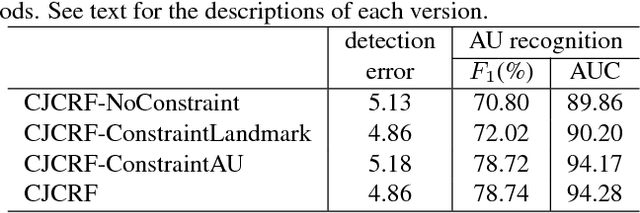
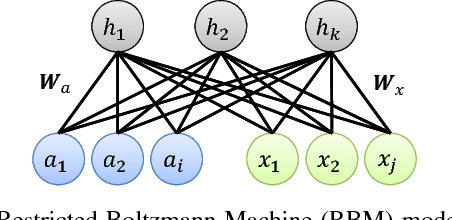
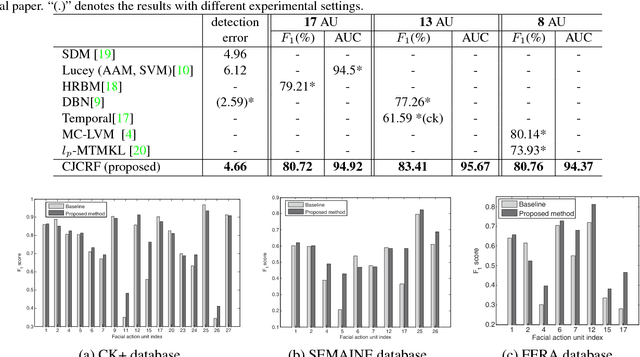
Cascade regression framework has been shown to be effective for facial landmark detection. It starts from an initial face shape and gradually predicts the face shape update from the local appearance features to generate the facial landmark locations in the next iteration until convergence. In this paper, we improve upon the cascade regression framework and propose the Constrained Joint Cascade Regression Framework (CJCRF) for simultaneous facial action unit recognition and facial landmark detection, which are two related face analysis tasks, but are seldomly exploited together. In particular, we first learn the relationships among facial action units and face shapes as a constraint. Then, in the proposed constrained joint cascade regression framework, with the help from the constraint, we iteratively update the facial landmark locations and the action unit activation probabilities until convergence. Experimental results demonstrate that the intertwined relationships of facial action units and face shapes boost the performances of both facial action unit recognition and facial landmark detection. The experimental results also demonstrate the effectiveness of the proposed method comparing to the state-of-the-art works.
Geometry-Contrastive GAN for Facial Expression Transfer
Oct 22, 2018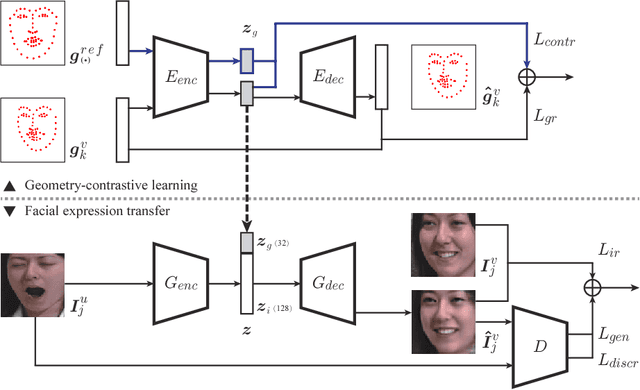
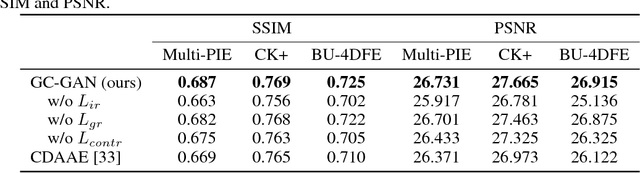


In this paper, we propose a Geometry-Contrastive Generative Adversarial Network (GC-GAN) for transferring continuous emotions across different subjects. Given an input face with certain emotion and a target facial expression from another subject, GC-GAN can generate an identity-preserving face with the target expression. Geometry information is introduced into cGANs as continuous conditions to guide the generation of facial expressions. In order to handle the misalignment across different subjects or emotions, contrastive learning is used to transform geometry manifold into an embedded semantic manifold of facial expressions. Therefore, the embedded geometry is injected into the latent space of GANs and control the emotion generation effectively. Experimental results demonstrate that our proposed method can be applied in facial expression transfer even there exist big differences in facial shapes and expressions between different subjects.
SunStage: Portrait Reconstruction and Relighting using the Sun as a Light Stage
Apr 07, 2022
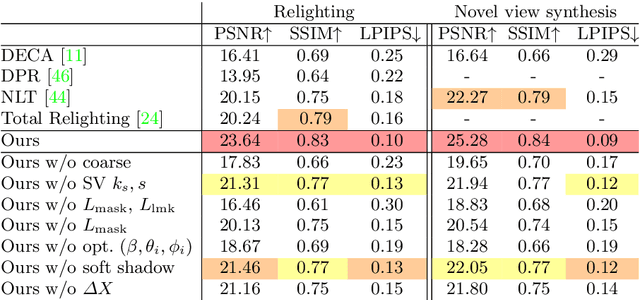
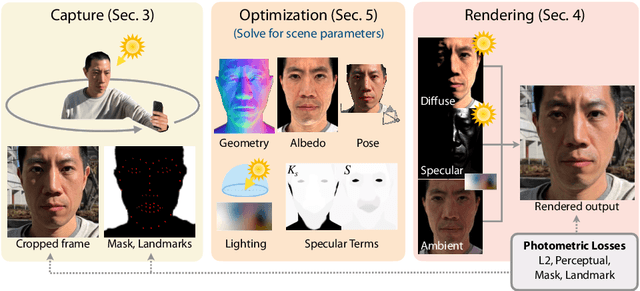

Outdoor portrait photographs are often marred by the harsh shadows cast under direct sunlight. To resolve this, one can use post-capture lighting manipulation techniques, but these methods either require complex hardware (e.g., a light stage) to capture each individual, or rely on image-based priors and thus fail to reconstruct many of the subtle facial details that vary from person to person. In this paper, we present SunStage, a system for accurate, individually-tailored, and lightweight reconstruction of facial geometry and reflectance that can be used for general portrait relighting with cast shadows. Our method only requires the user to capture a selfie video outdoors, rotating in place, and uses the varying angles between the sun and the face as constraints in the joint reconstruction of facial geometry, reflectance properties, and lighting parameters. Aside from relighting, we show that our reconstruction can be used for applications like reflectance editing and view synthesis. Results and interactive demos are available at https://grail.cs.washington.edu/projects/sunstage/.
Graph-based Facial Affect Analysis: A Review of Methods, Applications and Challenges
Mar 30, 2021
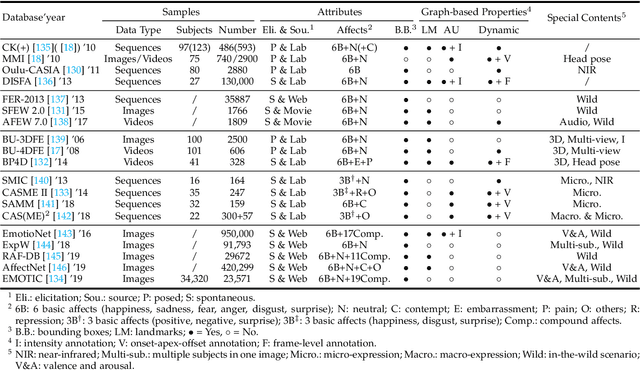
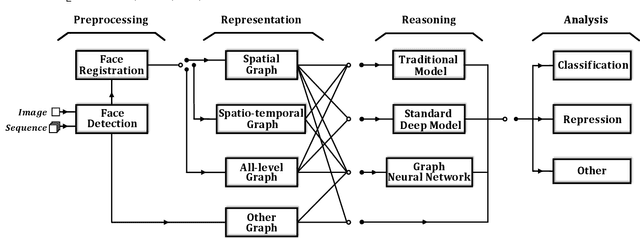
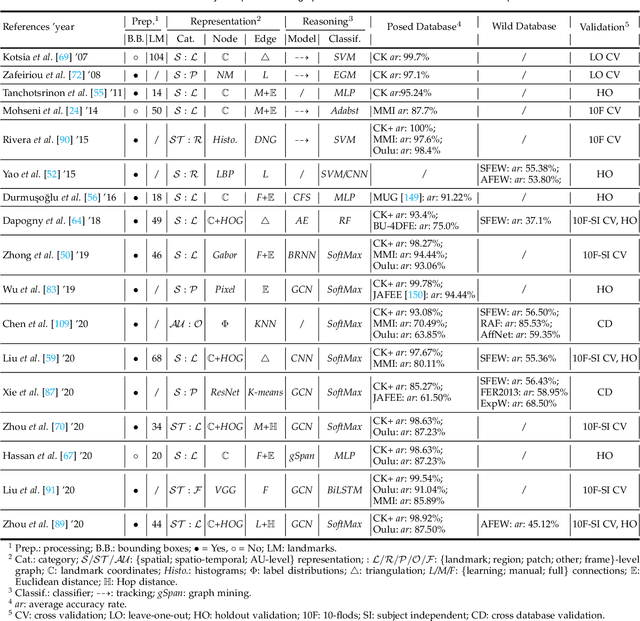
Facial affect analysis (FAA) using visual signals is a key step in human-computer interactions. Previous methods mainly focus on extracting appearance and geometry features associated with human affects. However, they do not consider the latent semantic information among each individual facial change, leading to limited performance and generalization. Recent trends attempt to establish a graph-based representation to model these semantic relationships and develop learning framework to leverage it for different FAA tasks. In this paper, we provide a comprehensive review of graph-based FAA, including the evolution of algorithms and their applications. First, we introduce the background knowledge of affect analysis, especially on the role of graph. We then discuss approaches that are widely used for graph-based affective representation in literatures and show a trend towards graph construction. For the relational reasoning in graph-based FAA, we classify existing studies according to their usage of traditional methods or deep models, with a special emphasis on latest graph neural networks. Experimental comparisons of the state-of-the-art on standard FAA problems are also summarized. Finally, we extend the review to the current challenges and potential directions. As far as we know, this is the first survey of graph-based FAA methods, and our findings can serve as a reference point for future research in this field.