 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"autonomous cars": models, code, and papers
A Tutorial On Autonomous Vehicle Steering Controller Design, Simulation and Implementation
Mar 10, 2018
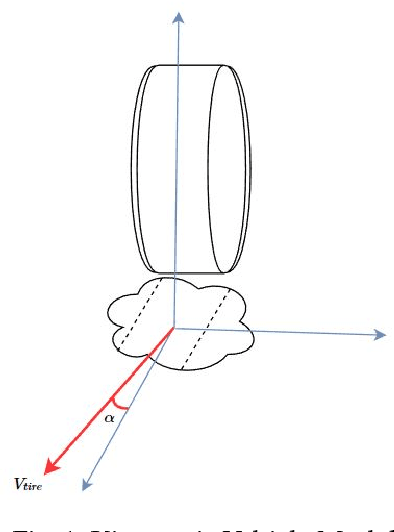
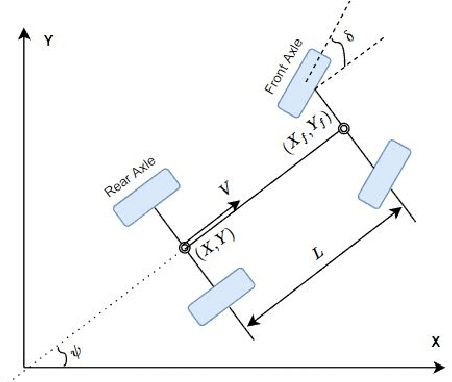
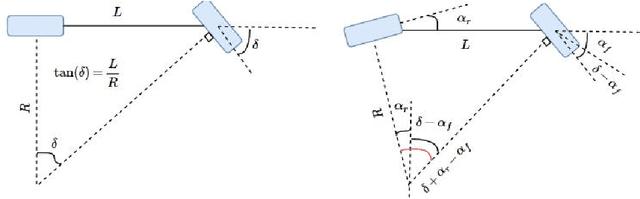
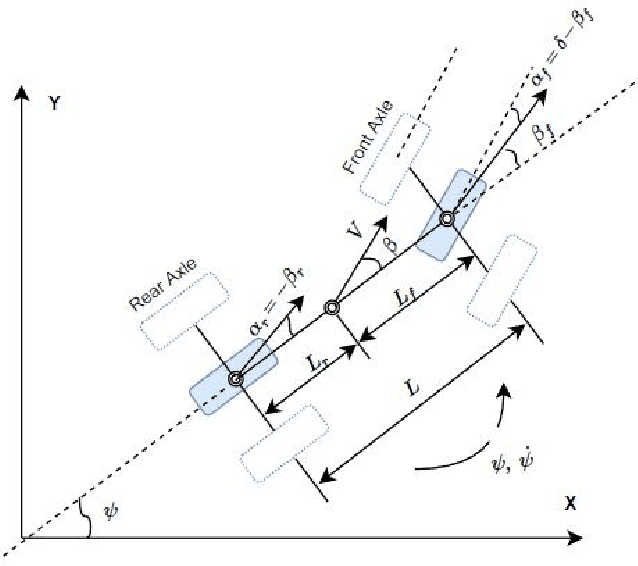
In this tutorial, we detailed simple controllers for autonomous parking and path following for self-driving cars and provided practical methods for curvature computation.
Input Prioritization for Testing Neural Networks
Jan 11, 2019
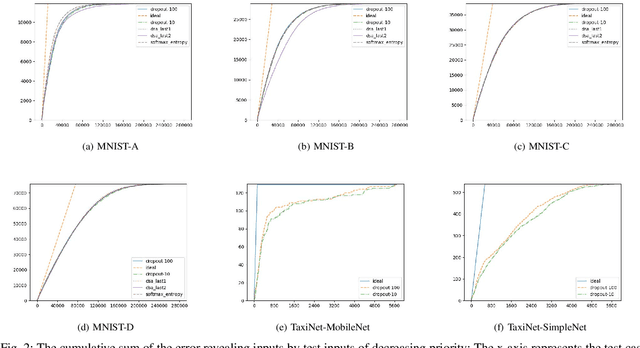


Deep neural networks (DNNs) are increasingly being adopted for sensing and control functions in a variety of safety and mission-critical systems such as self-driving cars, autonomous air vehicles, medical diagnostics, and industrial robotics. Failures of such systems can lead to loss of life or property, which necessitates stringent verification and validation for providing high assurance. Though formal verification approaches are being investigated, testing remains the primary technique for assessing the dependability of such systems. Due to the nature of the tasks handled by DNNs, the cost of obtaining test oracle data---the expected output, a.k.a. label, for a given input---is high, which significantly impacts the amount and quality of testing that can be performed. Thus, prioritizing input data for testing DNNs in meaningful ways to reduce the cost of labeling can go a long way in increasing testing efficacy. This paper proposes using gauges of the DNN's sentiment derived from the computation performed by the model, as a means to identify inputs that are likely to reveal weaknesses. We empirically assessed the efficacy of three such sentiment measures for prioritization---confidence, uncertainty, and surprise---and compare their effectiveness in terms of their fault-revealing capability and retraining effectiveness. The results indicate that sentiment measures can effectively flag inputs that expose unacceptable DNN behavior. For MNIST models, the average percentage of inputs correctly flagged ranged from 88% to 94.8%.
It Is Not the Journey but the Destination: Endpoint Conditioned Trajectory Prediction
Apr 04, 2020

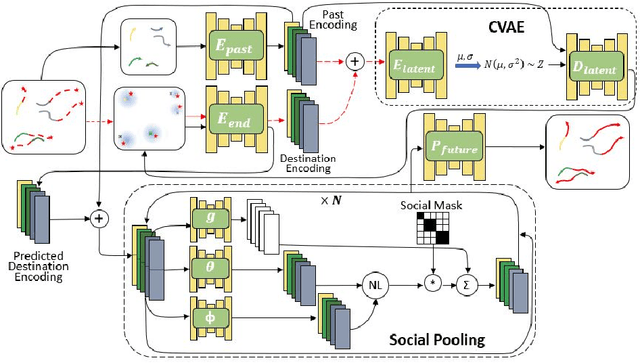
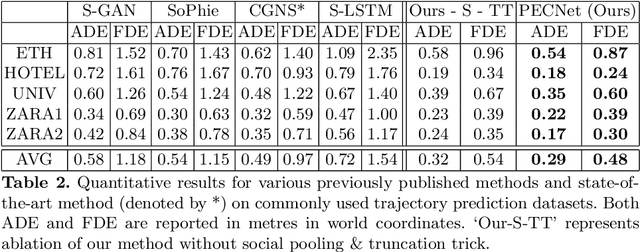
Human trajectory forecasting with multiple socially interacting agents is of critical importance for autonomous navigation in human environments, e.g., for self-driving cars and social robots. In this work, we present Predicted Endpoint Conditioned Network (PECNet) for flexible human trajectory prediction. PECNet infers distant trajectory endpoints to assist in long-range multi-modal trajectory prediction. A novel non-local social pooling layer enables PECNet to infer diverse yet socially compliant trajectories. Additionally, we present a simple "truncation-trick" for improving few-shot multi-modal trajectory prediction performance. We show that PECNet improves state-of-the-art performance on the Stanford Drone trajectory prediction benchmark by ~19.5% and on the ETH/UCY benchmark by ~40.8%.
Multi-agent RRT*: Sampling-based Cooperative Pathfinding (Extended Abstract)
Feb 12, 2013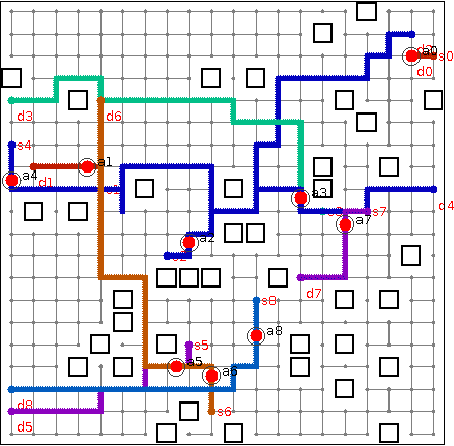
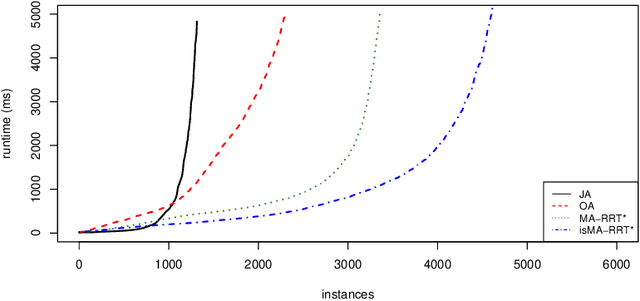
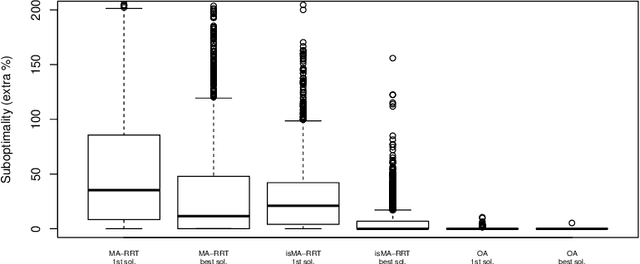
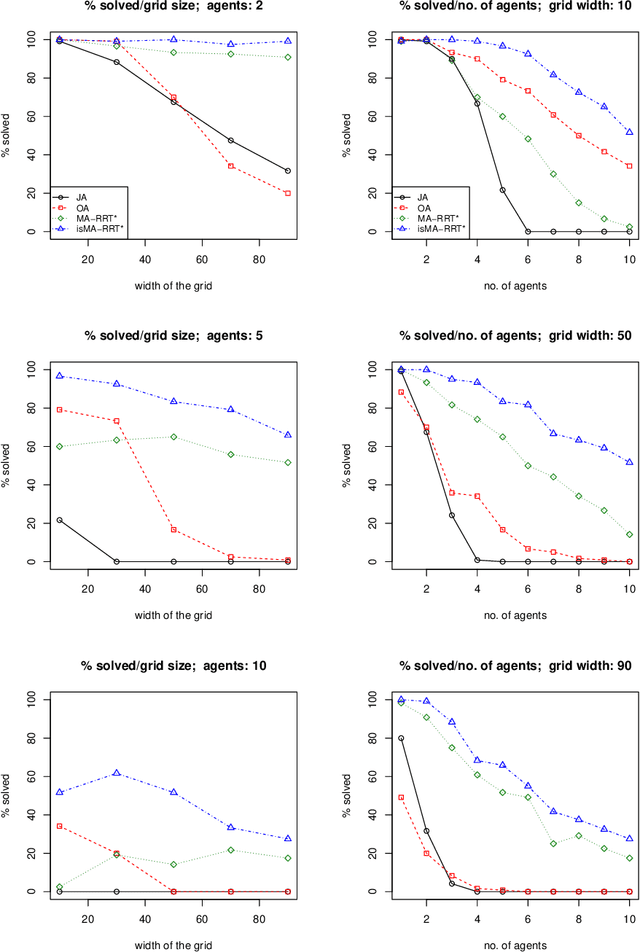
Cooperative pathfinding is a problem of finding a set of non-conflicting trajectories for a number of mobile agents. Its applications include planning for teams of mobile robots, such as autonomous aircrafts, cars, or underwater vehicles. The state-of-the-art algorithms for cooperative pathfinding typically rely on some heuristic forward-search pathfinding technique, where A* is often the algorithm of choice. Here, we propose MA-RRT*, a novel algorithm for multi-agent path planning that builds upon a recently proposed asymptotically-optimal sampling-based algorithm for finding single-agent shortest path called RRT*. We experimentally evaluate the performance of the algorithm and show that the sampling-based approach offers better scalability than the classical forward-search approach in relatively large, but sparse environments, which are typical in real-world applications such as multi-aircraft collision avoidance.
SELD-TCN: Sound Event Localization & Detection via Temporal Convolutional Networks
Mar 03, 2020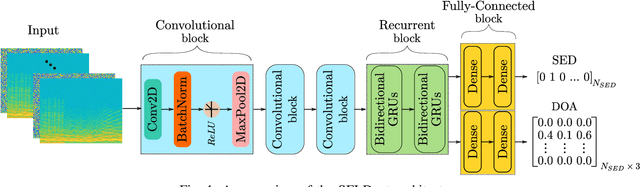
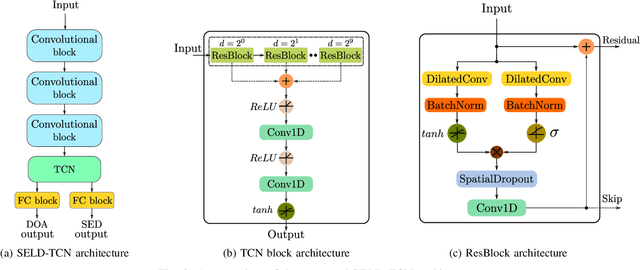
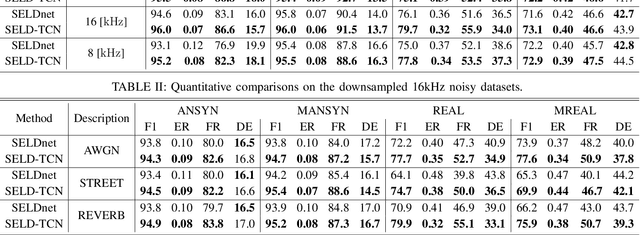
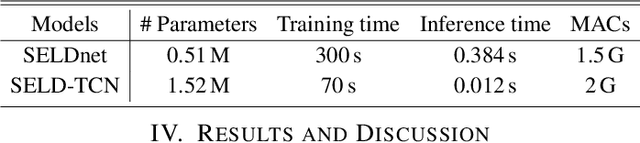
The understanding of the surrounding environment plays a critical role in autonomous robotic systems, such as self-driving cars. Extensive research has been carried out concerning visual perception. Yet, to obtain a more complete perception of the environment, autonomous systems of the future should also take acoustic information into account. Recent sound event localization and detection (SELD) frameworks utilize convolutional recurrent neural networks (CRNNs). However, considering the recurrent nature of CRNNs, it becomes challenging to implement them efficiently on embedded hardware. Not only are their computations strenuous to parallelize, but they also require high memory bandwidth and large memory buffers. In this work, we develop a more robust and hardware-friendly novel architecture based on a temporal convolutional network(TCN). The proposed framework (SELD-TCN) outperforms the state-of-the-art SELDnet performance on four different datasets. Moreover, SELD-TCN achieves 4x faster training time per epoch and 40x faster inference time on an ordinary graphics processing unit (GPU).
Crack-pot: Autonomous Road Crack and Pothole Detection
Sep 09, 2018
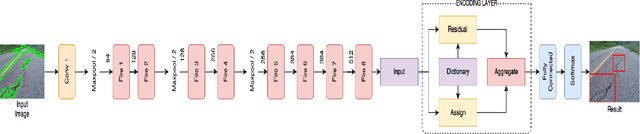
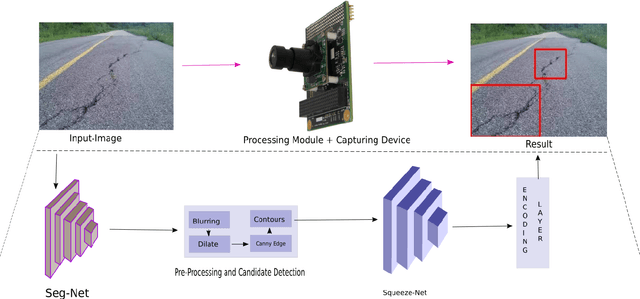

With the advent of self-driving cars and autonomous robots, it is imperative to detect road impairments like cracks and potholes and to perform necessary evading maneuvers to ensure fluid journey for on-board passengers or equipment. We propose a fully autonomous robust real-time road crack and pothole detection algorithm which can be deployed on any GPU based conventional processing boards with an associated camera. The approach is based on a deep neural net architecture which detects cracks and potholes using texture and spatial features. We also propose pre-processing methods which ensure real-time performance. The novelty of the approach lies in using texture- based features to differentiate between crack surfaces and sound roads. The approach performs well in large viewpoint changes, background noise, shadows, and occlusion. The efficacy of the system is shown on standard road crack datasets.
Learning Navigation Costs from Demonstration with Semantic Observations
Jun 11, 2020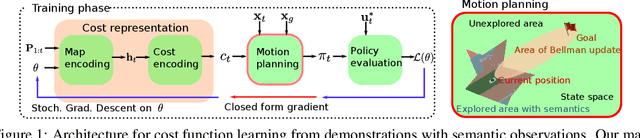

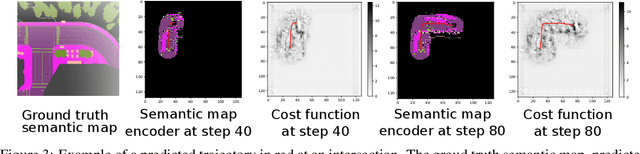
This paper focuses on inverse reinforcement learning (IRL) for autonomous robot navigation using semantic observations. The objective is to infer a cost function that explains demonstrated behavior while relying only on the expert's observations and state-control trajectory. We develop a map encoder, which infers semantic class probabilities from the observation sequence, and a cost encoder, defined as deep neural network over the semantic features. Since the expert cost is not directly observable, the representation parameters can only be optimized by differentiating the error between demonstrated controls and a control policy computed from the cost estimate. The error is optimized using a closed-form subgradient computed only over a subset of promising states via a motion planning algorithm. We show that our approach learns to follow traffic rules in the autonomous driving CARLA simulator by relying on semantic observations of cars, sidewalks and road lanes.
Y-GAN: A Generative Adversarial Network for Depthmap Estimation from Multi-camera Stereo Images
Jun 03, 2019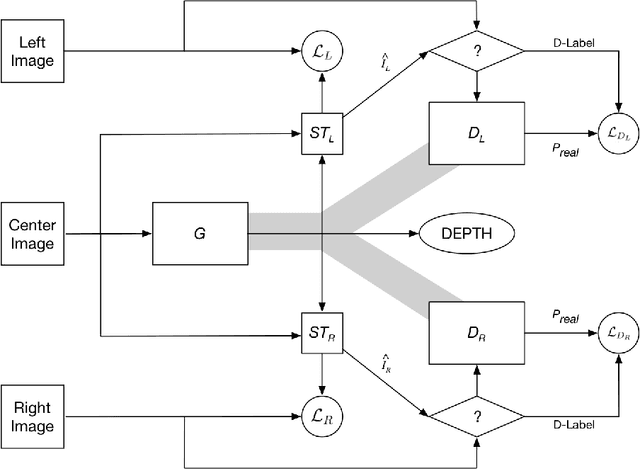
Depth perception is a key component for autonomous systems that interact in the real world, such as delivery robots, warehouse robots, and self-driving cars. Tasks in autonomous robotics such as 3D object recognition, simultaneous localization and mapping (SLAM), path planning and navigation, require some form of 3D spatial information. Depth perception is a long-standing research problem in computer vision and robotics and has had a long history. Many approaches using deep learning, ranging from structure from motion, shape-from-X, monocular, binocular, and multi-view stereo, have yielded acceptable results. However, there are several shortcomings of these methods such as requiring expensive hardware, needing supervised training data, no ground truth data for comparison, and disregard for occlusion. In order to address these shortcomings, this work proposes a new deep convolutional generative adversarial network architecture, called Y-GAN, that uses data from three cameras to estimate a depth map for each frame in a multi-camera video stream.
VTGNet: A Vision-based Trajectory Generation Network for Autonomous Vehicles in Urban Environments
Apr 27, 2020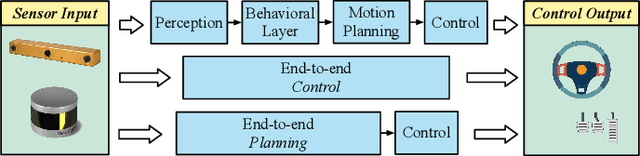

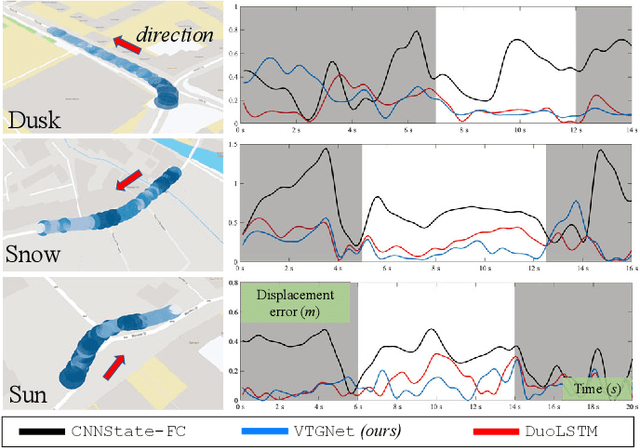

Reliable navigation like expert human drivers in urban environments is a critical capability for autonomous vehicles. Traditional methods for autonomous driving are implemented with many building blocks from perception, planning and control, making them difficult to generalize to varied scenarios due to complex assumptions and interdependencies. In this paper, we develop an end-to-end trajectory generation method based on imitation learning. It can extract spatiotemporal features from the front-view camera images for scene understanding, then generate collision-free trajectories several seconds into the future. The proposed network consists of three sub-networks, which are selectively activated for three common driving tasks: keep straight, turn left and turn right. The experimental results suggest that under various weather and lighting conditions, our network can reliably generate trajectories in different urban environments, such as turning at intersections and slowing down for collision avoidance. Furthermore, by integrating the proposed network into a navigation system, good generalization performance is presented in an unseen simulated world for autonomous driving on different types of vehicles, such as cars and trucks.
Explainable Goal-Driven Agents and Robots- A Comprehensive Review and New Framework
Apr 21, 2020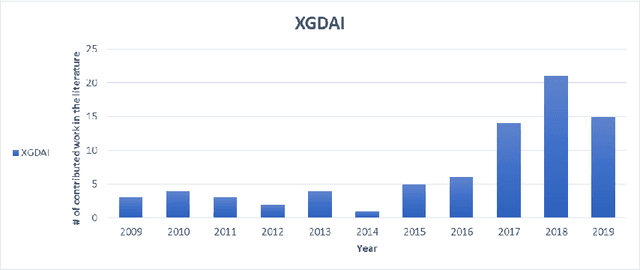
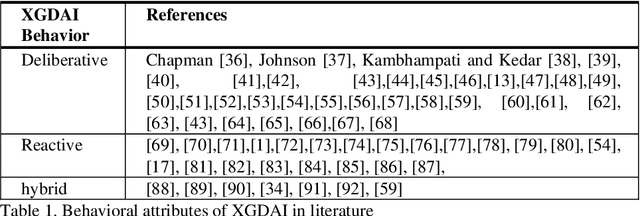
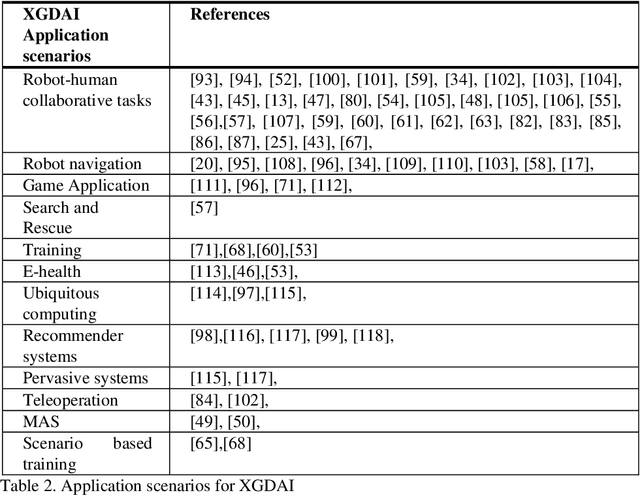
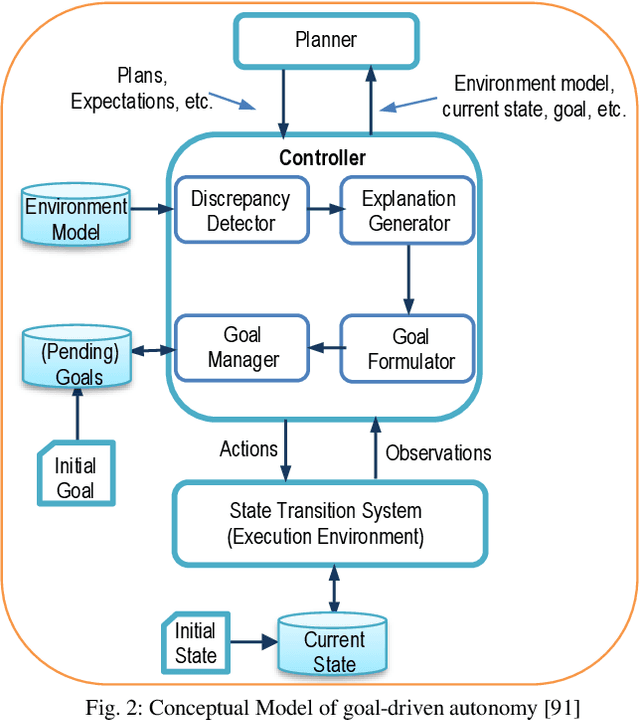
Recent applications of autonomous agents and robots, for example, self-driving cars, scenario-based trainers, exploration robots, service robots, have brought attention to crucial trust-related problems associated with the current generation of artificial intelligence (AI) systems. AI systems particularly dominated by the connectionist deep learning neural network approach lack capabilities of explaining their decisions and actions to others, despite their great successes. They are fundamentally non-intuitive black boxes, which renders their decision or actions opaque, making it difficult to trust them in safety-critical applications. The recent stance on the explainability of AI systems has witnessed several works on eXplainable Artificial Intelligence; however, most of the studies have focused on data-driven XAI systems applied in computational sciences. Studies addressing the increasingly pervasive goal-driven agents and robots are still missing. This paper reviews works on explainable goal-driven intelligent agents and robots, focusing on techniques for explaining and communicating agents perceptual functions (for example, senses, vision, etc.) and cognitive reasoning (for example, beliefs, desires, intention, plans, and goals) with humans in the loop. The review highlights key strategies that emphasize transparency and understandability, and continual learning for explainability. Finally, the paper presents requirements for explainability and suggests a roadmap for the possible realization of effective goal-driven explainable agents and robots