 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeather-Aware Object Detection Transformer for Domain Adaptation
Apr 15, 2025



RT-DETRs have shown strong performance across various computer vision tasks but are known to degrade under challenging weather conditions such as fog. In this work, we investigate three novel approaches to enhance RT-DETR robustness in foggy environments: (1) Domain Adaptation via Perceptual Loss, which distills domain-invariant features from a teacher network to a student using perceptual supervision; (2) Weather Adaptive Attention, which augments the attention mechanism with fog-sensitive scaling by introducing an auxiliary foggy image stream; and (3) Weather Fusion Encoder, which integrates a dual-stream encoder architecture that fuses clear and foggy image features via multi-head self and cross-attention. Despite the architectural innovations, none of the proposed methods consistently outperform the baseline RT-DETR. We analyze the limitations and potential causes, offering insights for future research in weather-aware object detection.
DAREK -- Distance Aware Error for Kolmogorov Networks
Jan 08, 2025In this paper, we provide distance-aware error bounds for Kolmogorov Arnold Networks (KANs). We call our new error bounds estimator DAREK -- Distance Aware Error for Kolmogorov networks. Z. Liu et al. provide error bounds, which may be loose, lack distance-awareness, and are defined only up to an unknown constant of proportionality. We review the error bounds for Newton's polynomial, which is then generalized to an arbitrary spline, under Lipschitz continuity assumptions. We then extend these bounds to nested compositions of splines, arriving at error bounds for KANs. We evaluate our method by estimating an object's shape from sparse laser scan points. We use KAN to fit a smooth function to the scans and provide error bounds for the fit. We find that our method is faster than Monte Carlo approaches, and that our error bounds enclose the true obstacle shape reliably.
Omobot: a low-cost mobile robot for autonomous search and fall detection
Aug 09, 2024Detecting falls among the elderly and alerting their community responders can save countless lives. We design and develop a low-cost mobile robot that periodically searches the house for the person being monitored and sends an email to a set of designated responders if a fall is detected. In this project, we make three novel design decisions and contributions. First, our custom-designed low-cost robot has advanced features like omnidirectional wheels, the ability to run deep learning models, and autonomous wireless charging. Second, we improve the accuracy of fall detection for the YOLOv8-Pose-nano object detection network by 6% and YOLOv8-Pose-large by 12%. We do so by transforming the images captured from the robot viewpoint (camera height 0.15m from the ground) to a typical human viewpoint (1.5m above the ground) using a principally computed Homography matrix. This improves network accuracy because the training dataset MS-COCO on which YOLOv8-Pose is trained is captured from a human-height viewpoint. Lastly, we improve the robot controller by learning a model that predicts the robot velocity from the input signal to the motor controller.
DADEE: Well-calibrated uncertainty quantification in neural networks for barriers-based robot safety
Jun 30, 2024Uncertainty-aware controllers that guarantee safety are critical for safety critical applications. Among such controllers, Control Barrier Functions (CBFs) based approaches are popular because they are fast, yet safe. However, most such works depend on Gaussian Processes (GPs) or MC-Dropout for learning and uncertainty estimation, and both approaches come with drawbacks: GPs are non-parametric methods that are slow, while MC-Dropout does not capture aleatoric uncertainty. On the other hand, modern Bayesian learning algorithms have shown promise in uncertainty quantification. The application of modern Bayesian learning methods to CBF-based controllers has not yet been studied. We aim to fill this gap by surveying uncertainty quantification algorithms and evaluating them on CBF-based safe controllers. We find that model variance-based algorithms (for example, Deep ensembles, MC-dropout, etc.) and direct estimation-based algorithms (such as DEUP) have complementary strengths. Algorithms in the former category can only estimate uncertainty accurately out-of-domain, while those in the latter category can only do so in-domain. We combine the two approaches to obtain more accurate uncertainty estimates both in- and out-of-domain. As measured by the failure rate of a simulated robot, this results in a safer CBF-based robot controller.
Cross-view geo-localization: a survey
Jun 14, 2024Cross-view geo-localization has garnered notable attention in the realm of computer vision, spurred by the widespread availability of copious geotagged datasets and the advancements in machine learning techniques. This paper provides a thorough survey of cutting-edge methodologies, techniques, and associated challenges that are integral to this domain, with a focus on feature-based and deep learning strategies. Feature-based methods capitalize on unique features to establish correspondences across disparate viewpoints, whereas deep learning-based methodologies deploy convolutional neural networks to embed view-invariant attributes. This work also delineates the multifaceted challenges encountered in cross-view geo-localization, such as variations in viewpoints and illumination, the occurrence of occlusions, and it elucidates innovative solutions that have been formulated to tackle these issues. Furthermore, we delineate benchmark datasets and relevant evaluation metrics, and also perform a comparative analysis of state-of-the-art techniques. Finally, we conclude the paper with a discussion on prospective avenues for future research and the burgeoning applications of cross-view geo-localization in an intricately interconnected global landscape.
FogGuard: guarding YOLO against fog using perceptual loss
Mar 13, 2024



In this paper, we present a novel fog-aware object detection network called FogGuard, designed to address the challenges posed by foggy weather conditions. Autonomous driving systems heavily rely on accurate object detection algorithms, but adverse weather conditions can significantly impact the reliability of deep neural networks (DNNs). Existing approaches fall into two main categories, 1) image enhancement such as IA-YOLO 2) domain adaptation based approaches. Image enhancement based techniques attempt to generate fog-free image. However, retrieving a fogless image from a foggy image is a much harder problem than detecting objects in a foggy image. Domain-adaptation based approaches, on the other hand, do not make use of labelled datasets in the target domain. Both categories of approaches are attempting to solve a harder version of the problem. Our approach builds over fine-tuning on the Our framework is specifically designed to compensate for foggy conditions present in the scene, ensuring robust performance even. We adopt YOLOv3 as the baseline object detection algorithm and introduce a novel Teacher-Student Perceptual loss, to high accuracy object detection in foggy images. Through extensive evaluations on common datasets such as PASCAL VOC and RTTS, we demonstrate the improvement in performance achieved by our network. We demonstrate that FogGuard achieves 69.43\% mAP, as compared to 57.78\% for YOLOv3 on the RTTS dataset. Furthermore, we show that while our training method increases time complexity, it does not introduce any additional overhead during inference compared to the regular YOLO network.
Safe Control Synthesis with Uncertain Dynamics and Constraints
Feb 19, 2022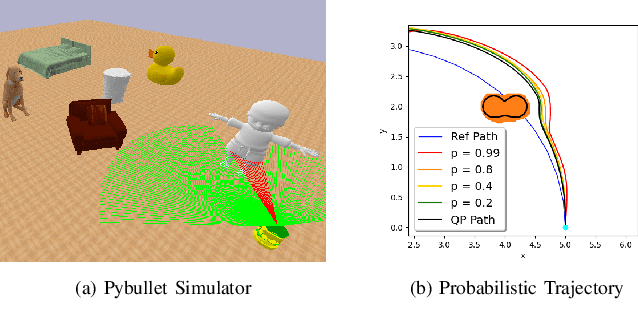
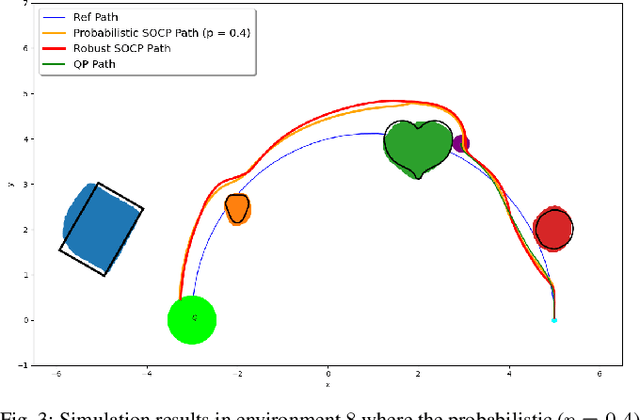
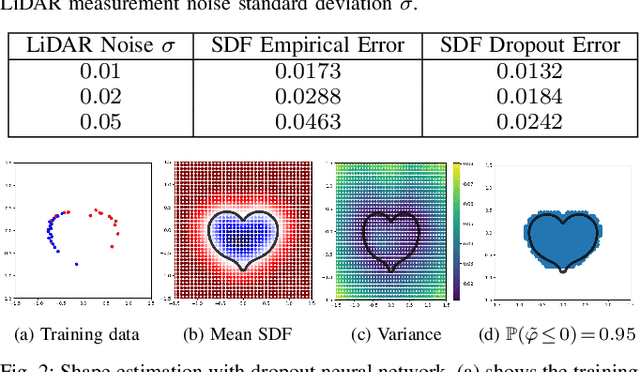
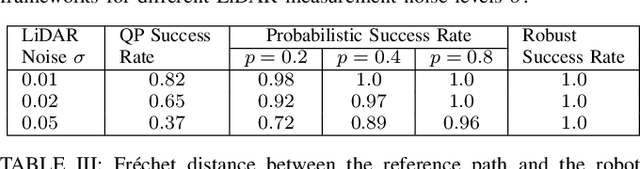
This paper considers safe control synthesis for dynamical systems in the presence of uncertainty in the dynamics model and the safety constraints that the system must satisfy. Our approach captures probabilistic and worst-case model errors and their effect on control Lyapunov function (CLF) and control barrier function (CBF) constraints in the control-synthesis optimization problem. We show that both the probabilistic and robust formulations lead to second-order cone programs (SOCPs), enabling safe and stable control synthesis that can be performed efficiently online. We evaluate our approach in PyBullet simulations of an autonomous robot navigating in unknown environments and compare the performance with a baseline CLF-CBF quadratic programming approach.
Inverse reinforcement learning for autonomous navigation via differentiable semantic mapping and planning
Jan 01, 2021

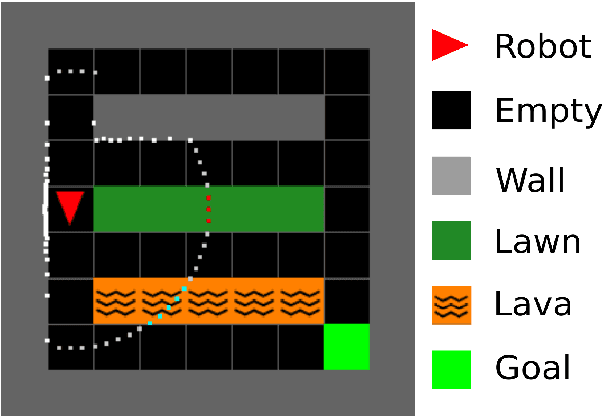

This paper focuses on inverse reinforcement learning for autonomous navigation using distance and semantic category observations. The objective is to infer a cost function that explains demonstrated behavior while relying only on the expert's observations and state-control trajectory. We develop a map encoder, that infers semantic category probabilities from the observation sequence, and a cost encoder, defined as a deep neural network over the semantic features. Since the expert cost is not directly observable, the model parameters can only be optimized by differentiating the error between demonstrated controls and a control policy computed from the cost estimate. We propose a new model of expert behavior that enables error minimization using a closed-form subgradient computed only over a subset of promising states via a motion planning algorithm. Our approach allows generalizing the learned behavior to new environments with new spatial configurations of the semantic categories. We analyze the different components of our model in a minigrid environment. We also demonstrate that our approach learns to follow traffic rules in the autonomous driving CARLA simulator by relying on semantic observations of buildings, sidewalks, and road lanes.
Control Barriers in Bayesian Learning of System Dynamics
Dec 29, 2020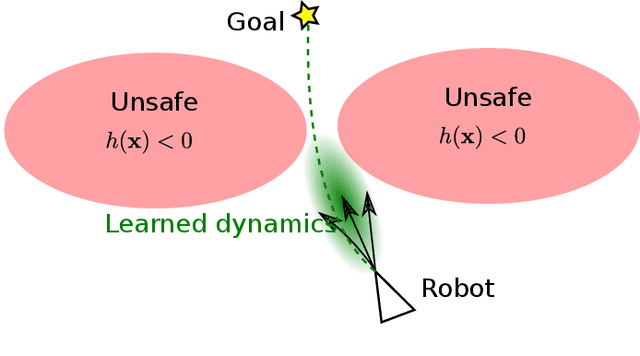
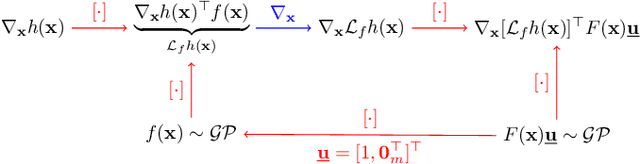
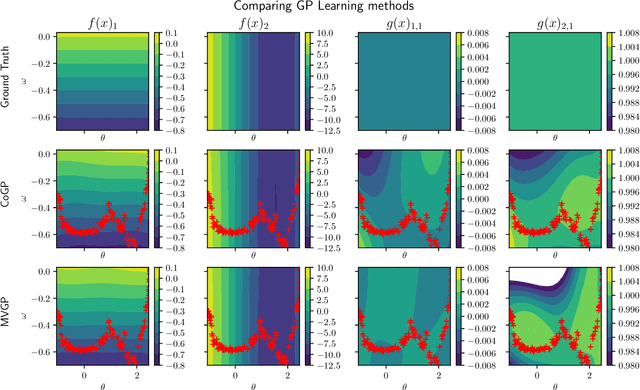
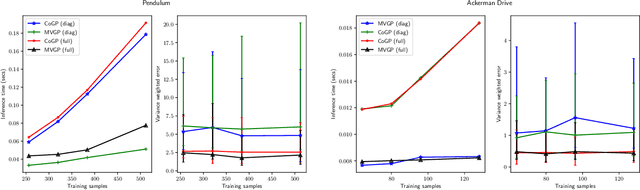
This paper focuses on learning a model of system dynamics online while satisfying safety constraints. Our objective is to avoid offline system identification or hand-specified models and allow a system to safely and autonomously estimate and adapt its own model during operation. Given streaming observations of the system state, we use Bayesian learning to obtain a distribution over the system dynamics. Specifically, we use a matrix variate Gaussian process (MVGP) regression approach with efficient covariance factorization to learn the drift and input gain terms of a nonlinear control-affine system. The MVGP distribution is then used to optimize the system behavior and ensure safety with high probability, by specifying control Lyapunov function (CLF) and control barrier function (CBF) chance constraints. We show that a safe control policy can be synthesized for systems with arbitrary relative degree and probabilistic CLF-CBF constraints by solving a second order cone program (SOCP). Finally, we extend our design to a self-triggering formulation, adaptively determining the time at which a new control input needs to be applied in order to guarantee safety.
Learning Navigation Costs from Demonstration with Semantic Observations
Jun 11, 2020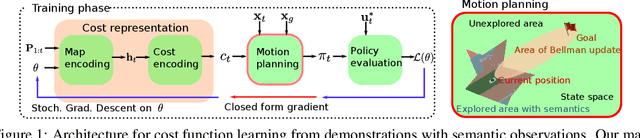

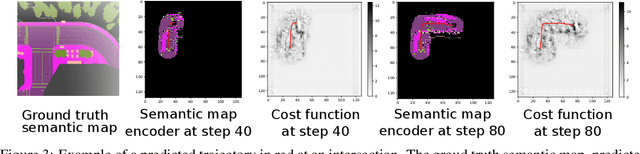
This paper focuses on inverse reinforcement learning (IRL) for autonomous robot navigation using semantic observations. The objective is to infer a cost function that explains demonstrated behavior while relying only on the expert's observations and state-control trajectory. We develop a map encoder, which infers semantic class probabilities from the observation sequence, and a cost encoder, defined as deep neural network over the semantic features. Since the expert cost is not directly observable, the representation parameters can only be optimized by differentiating the error between demonstrated controls and a control policy computed from the cost estimate. The error is optimized using a closed-form subgradient computed only over a subset of promising states via a motion planning algorithm. We show that our approach learns to follow traffic rules in the autonomous driving CARLA simulator by relying on semantic observations of cars, sidewalks and road lanes.