 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Privacy-Preserving Federated Learning over Vertically and Horizontally Partitioned Data for Financial Anomaly Detection
Oct 30, 2023
The effective detection of evidence of financial anomalies requires collaboration among multiple entities who own a diverse set of data, such as a payment network system (PNS) and its partner banks. Trust among these financial institutions is limited by regulation and competition. Federated learning (FL) enables entities to collaboratively train a model when data is either vertically or horizontally partitioned across the entities. However, in real-world financial anomaly detection scenarios, the data is partitioned both vertically and horizontally and hence it is not possible to use existing FL approaches in a plug-and-play manner. Our novel solution, PV4FAD, combines fully homomorphic encryption (HE), secure multi-party computation (SMPC), differential privacy (DP), and randomization techniques to balance privacy and accuracy during training and to prevent inference threats at model deployment time. Our solution provides input privacy through HE and SMPC, and output privacy against inference time attacks through DP. Specifically, we show that, in the honest-but-curious threat model, banks do not learn any sensitive features about PNS transactions, and the PNS does not learn any information about the banks' dataset but only learns prediction labels. We also develop and analyze a DP mechanism to protect output privacy during inference. Our solution generates high-utility models by significantly reducing the per-bank noise level while satisfying distributed DP. To ensure high accuracy, our approach produces an ensemble model, in particular, a random forest. This enables us to take advantage of the well-known properties of ensembles to reduce variance and increase accuracy. Our solution won second prize in the first phase of the U.S. Privacy Enhancing Technologies (PETs) Prize Challenge.
Time-Parameterized Convolutional Neural Networks for Irregularly Sampled Time Series
Aug 09, 2023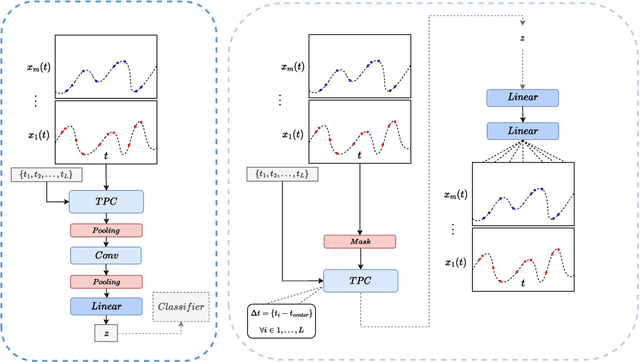
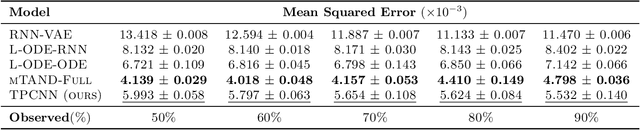
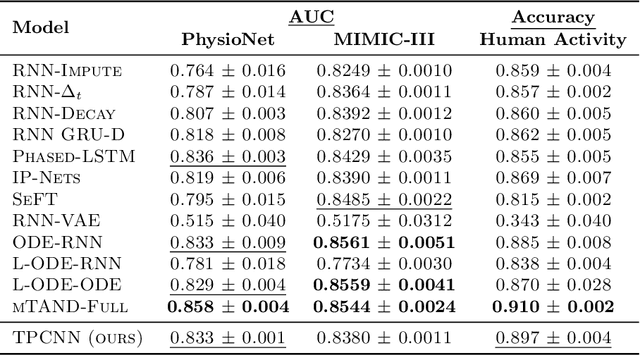
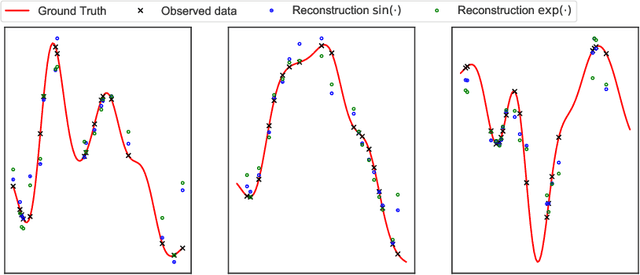
Irregularly sampled multivariate time series are ubiquitous in several application domains, leading to sparse, not fully-observed and non-aligned observations across different variables. Standard sequential neural network architectures, such as recurrent neural networks (RNNs) and convolutional neural networks (CNNs), consider regular spacing between observation times, posing significant challenges to irregular time series modeling. While most of the proposed architectures incorporate RNN variants to handle irregular time intervals, convolutional neural networks have not been adequately studied in the irregular sampling setting. In this paper, we parameterize convolutional layers by employing time-explicitly initialized kernels. Such general functions of time enhance the learning process of continuous-time hidden dynamics and can be efficiently incorporated into convolutional kernel weights. We, thus, propose the time-parameterized convolutional neural network (TPCNN), which shares similar properties with vanilla convolutions but is carefully designed for irregularly sampled time series. We evaluate TPCNN on both interpolation and classification tasks involving real-world irregularly sampled multivariate time series datasets. Our experimental results indicate the competitive performance of the proposed TPCNN model which is also significantly more efficient than other state-of-the-art methods. At the same time, the proposed architecture allows the interpretability of the input series by leveraging the combination of learnable time functions that improve the network performance in subsequent tasks and expedite the inaugural application of convolutions in this field.
FreeNoise: Tuning-Free Longer Video Diffusion Via Noise Rescheduling
Oct 23, 2023With the availability of large-scale video datasets and the advances of diffusion models, text-driven video generation has achieved substantial progress. However, existing video generation models are typically trained on a limited number of frames, resulting in the inability to generate high-fidelity long videos during inference. Furthermore, these models only support single-text conditions, whereas real-life scenarios often require multi-text conditions as the video content changes over time. To tackle these challenges, this study explores the potential of extending the text-driven capability to generate longer videos conditioned on multiple texts. 1) We first analyze the impact of initial noise in video diffusion models. Then building upon the observation of noise, we propose FreeNoise, a tuning-free and time-efficient paradigm to enhance the generative capabilities of pretrained video diffusion models while preserving content consistency. Specifically, instead of initializing noises for all frames, we reschedule a sequence of noises for long-range correlation and perform temporal attention over them by window-based function. 2) Additionally, we design a novel motion injection method to support the generation of videos conditioned on multiple text prompts. Extensive experiments validate the superiority of our paradigm in extending the generative capabilities of video diffusion models. It is noteworthy that compared with the previous best-performing method which brought about 255% extra time cost, our method incurs only negligible time cost of approximately 17%. Generated video samples are available at our website: http://haonanqiu.com/projects/FreeNoise.html.
Sky Imager-Based Forecast of Solar Irradiance Using Machine Learning
Oct 26, 2023Ahead-of-time forecasting of the output power of power plants is essential for the stability of the electricity grid and ensuring uninterrupted service. However, forecasting renewable energy sources is difficult due to the chaotic behavior of natural energy sources. This paper presents a new approach to estimate short-term solar irradiance from sky images. The~proposed algorithm extracts features from sky images and use learning-based techniques to estimate the solar irradiance. The~performance of proposed machine learning (ML) algorithm is evaluated using two publicly available datasets of sky images. The~datasets contain over 350,000 images for an interval of 16 years, from 2004 to 2020, with the corresponding global horizontal irradiance (GHI) of each image as the ground truth. Compared to the state-of-the-art computationally heavy algorithms proposed in the literature, our approach achieves competitive results with much less computational complexity for both nowcasting and forecasting up to 4 h ahead of time.
* Published in MDPI Electronics Journal
Interacting Diffusion Processes for Event Sequence Forecasting
Oct 26, 2023Neural Temporal Point Processes (TPPs) have emerged as the primary framework for predicting sequences of events that occur at irregular time intervals, but their sequential nature can hamper performance for long-horizon forecasts. To address this, we introduce a novel approach that incorporates a diffusion generative model. The model facilitates sequence-to-sequence prediction, allowing multi-step predictions based on historical event sequences. In contrast to previous approaches, our model directly learns the joint probability distribution of types and inter-arrival times for multiple events. This allows us to fully leverage the high dimensional modeling capability of modern generative models. Our model is composed of two diffusion processes, one for the time intervals and one for the event types. These processes interact through their respective denoising functions, which can take as input intermediate representations from both processes, allowing the model to learn complex interactions. We demonstrate that our proposal outperforms state-of-the-art baselines for long-horizon forecasting of TPP.
A Call to Arms: AI Should be Critical for Social Media Analysis of Conflict Zones
Nov 01, 2023
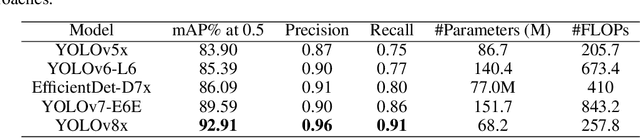

The massive proliferation of social media data represents a transformative moment in conflict studies. This data can provide unique insights into the spread and use of weaponry, but the scale and types of data are problematic for traditional open-source intelligence. This paper presents preliminary, transdisciplinary work using computer vision to identify specific weapon systems and the insignias of the armed groups using them. There is potential to not only track how weapons are distributed through networks of armed units but also to track which types of weapons are being used by the different types of state and non-state military actors in Ukraine. Such a system could ultimately be used to understand conflicts in real-time, including where humanitarian and medical aid is most needed. We believe that using AI to help automate such processes should be a high-priority goal for our community, with near-term real-world payoffs.
Like an Open Book? Read Neural Network Architecture with Simple Power Analysis on 32-bit Microcontrollers
Nov 02, 2023Model extraction is a growing concern for the security of AI systems. For deep neural network models, the architecture is the most important information an adversary aims to recover. Being a sequence of repeated computation blocks, neural network models deployed on edge-devices will generate distinctive side-channel leakages. The latter can be exploited to extract critical information when targeted platforms are physically accessible. By combining theoretical knowledge about deep learning practices and analysis of a widespread implementation library (ARM CMSIS-NN), our purpose is to answer this critical question: how far can we extract architecture information by simply examining an EM side-channel trace? For the first time, we propose an extraction methodology for traditional MLP and CNN models running on a high-end 32-bit microcontroller (Cortex-M7) that relies only on simple pattern recognition analysis. Despite few challenging cases, we claim that, contrary to parameters extraction, the complexity of the attack is relatively low and we highlight the urgent need for practicable protections that could fit the strong memory and latency requirements of such platforms.
A Coreset-based, Tempered Variational Posterior for Accurate and Scalable Stochastic Gaussian Process Inference
Nov 02, 2023We present a novel stochastic variational Gaussian process ($\mathcal{GP}$) inference method, based on a posterior over a learnable set of weighted pseudo input-output points (coresets). Instead of a free-form variational family, the proposed coreset-based, variational tempered family for $\mathcal{GP}$s (CVTGP) is defined in terms of the $\mathcal{GP}$ prior and the data-likelihood; hence, accommodating the modeling inductive biases. We derive CVTGP's lower bound for the log-marginal likelihood via marginalization of the proposed posterior over latent $\mathcal{GP}$ coreset variables, and show it is amenable to stochastic optimization. CVTGP reduces the learnable parameter size to $\mathcal{O}(M)$, enjoys numerical stability, and maintains $\mathcal{O}(M^3)$ time- and $\mathcal{O}(M^2)$ space-complexity, by leveraging a coreset-based tempered posterior that, in turn, provides sparse and explainable representations of the data. Results on simulated and real-world regression problems with Gaussian observation noise validate that CVTGP provides better evidence lower-bound estimates and predictive root mean squared error than alternative stochastic $\mathcal{GP}$ inference methods.
Conformal Policy Learning for Sensorimotor Control Under Distribution Shifts
Nov 02, 2023This paper focuses on the problem of detecting and reacting to changes in the distribution of a sensorimotor controller's observables. The key idea is the design of switching policies that can take conformal quantiles as input, which we define as conformal policy learning, that allows robots to detect distribution shifts with formal statistical guarantees. We show how to design such policies by using conformal quantiles to switch between base policies with different characteristics, e.g. safety or speed, or directly augmenting a policy observation with a quantile and training it with reinforcement learning. Theoretically, we show that such policies achieve the formal convergence guarantees in finite time. In addition, we thoroughly evaluate their advantages and limitations on two compelling use cases: simulated autonomous driving and active perception with a physical quadruped. Empirical results demonstrate that our approach outperforms five baselines. It is also the simplest of the baseline strategies besides one ablation. Being easy to use, flexible, and with formal guarantees, our work demonstrates how conformal prediction can be an effective tool for sensorimotor learning under uncertainty.
Map-assisted TDOA Localization Enhancement Based On CNN
Nov 02, 2023For signal processing related to localization technologies, non line of sight (NLOS) multipaths have great impact over the localization error level. This study proposes a localization correction method based on convolution neural network (CNN) that extracts obstacles' features from maps to predict the localization errors caused by NLOS effects. A novel compensation scheme is developed and structured around the localization error predicted by the CNN. Four prediction tasks are executed over the building distributions within the maps and the propagation model in urban zones, resulting in CNN models with high prediction accuracy. Finally, a thorough comparison of the accuracy performance between the time difference of arrival (TDOA) localization algorithm and the results after the error compensation reveals that, generally, the CNN prediction approach demonstrates a great localization error correction performance. It can be observed that the powerful feature extraction capability of CNN can be exploited by processing surrounding maps to predict localization error distribution, which has great potential in further enhancement of TDOA performance under challenging scenarios with rich multi-path propagation.