 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA longitudinal health agent framework
Apr 13, 2026Although artificial intelligence (AI) agents are increasingly proposed to support potentially longitudinal health tasks, such as symptom management, behavior change, and patient support, most current implementations fall short of facilitating user intent and fostering accountability. This contrasts with prior work on supporting longitudinal needs, where follow-up, coherent reasoning, and sustained alignment with individuals' goals are critical for both effectiveness and safety. In this paper, we draw on established clinical and personal health informatics frameworks to define what it would mean to orchestrate longitudinal health interactions with AI agents. We propose a multi-layer framework and corresponding agent architecture that operationalizes adaptation, coherence, continuity, and agency across repeated interactions. Through representative use cases, we demonstrate how longitudinal agents can maintain meaningful engagement, adapt to evolving goals, and support safe, personalized decision-making over time. Our findings underscore both the promise and the complexity of designing systems capable of supporting health trajectories beyond isolated interactions, and we offer guidance for future research and development in multi-session, user-centered health AI.
A pipeline for enabling path-specific causal fairness in observational health data
Jan 14, 2026When training machine learning (ML) models for potential deployment in a healthcare setting, it is essential to ensure that they do not replicate or exacerbate existing healthcare biases. Although many definitions of fairness exist, we focus on path-specific causal fairness, which allows us to better consider the social and medical contexts in which biases occur (e.g., direct discrimination by a clinician or model versus bias due to differential access to the healthcare system) and to characterize how these biases may appear in learned models. In this work, we map the structural fairness model to the observational healthcare setting and create a generalizable pipeline for training causally fair models. The pipeline explicitly considers specific healthcare context and disparities to define a target "fair" model. Our work fills two major gaps: first, we expand on characterizations of the "fairness-accuracy" tradeoff by detangling direct and indirect sources of bias and jointly presenting these fairness considerations alongside considerations of accuracy in the context of broadly known biases. Second, we demonstrate how a foundation model trained without fairness constraints on observational health data can be leveraged to generate causally fair downstream predictions in tasks with known social and medical disparities. This work presents a model-agnostic pipeline for training causally fair machine learning models that address both direct and indirect forms of healthcare bias.
Explainable AI as a Double-Edged Sword in Dermatology: The Impact on Clinicians versus The Public
Dec 14, 2025Artificial intelligence (AI) is increasingly permeating healthcare, from physician assistants to consumer applications. Since AI algorithm's opacity challenges human interaction, explainable AI (XAI) addresses this by providing AI decision-making insight, but evidence suggests XAI can paradoxically induce over-reliance or bias. We present results from two large-scale experiments (623 lay people; 153 primary care physicians, PCPs) combining a fairness-based diagnosis AI model and different XAI explanations to examine how XAI assistance, particularly multimodal large language models (LLMs), influences diagnostic performance. AI assistance balanced across skin tones improved accuracy and reduced diagnostic disparities. However, LLM explanations yielded divergent effects: lay users showed higher automation bias - accuracy boosted when AI was correct, reduced when AI erred - while experienced PCPs remained resilient, benefiting irrespective of AI accuracy. Presenting AI suggestions first also led to worse outcomes when the AI was incorrect for both groups. These findings highlight XAI's varying impact based on expertise and timing, underscoring LLMs as a "double-edged sword" in medical AI and informing future human-AI collaborative system design.
ADHAM: Additive Deep Hazard Analysis Mixtures for Interpretable Survival Regression
Sep 08, 2025Survival analysis is a fundamental tool for modeling time-to-event outcomes in healthcare. Recent advances have introduced flexible neural network approaches for improved predictive performance. However, most of these models do not provide interpretable insights into the association between exposures and the modeled outcomes, a critical requirement for decision-making in clinical practice. To address this limitation, we propose Additive Deep Hazard Analysis Mixtures (ADHAM), an interpretable additive survival model. ADHAM assumes a conditional latent structure that defines subgroups, each characterized by a combination of covariate-specific hazard functions. To select the number of subgroups, we introduce a post-training refinement that reduces the number of equivalent latent subgroups by merging similar groups. We perform comprehensive studies to demonstrate ADHAM's interpretability at the population, subgroup, and individual levels. Extensive experiments on real-world datasets show that ADHAM provides novel insights into the association between exposures and outcomes. Further, ADHAM remains on par with existing state-of-the-art survival baselines in terms of predictive performance, offering a scalable and interpretable approach to time-to-event prediction in healthcare.
CEHR-GPT: A Scalable Multi-Task Foundation Model for Electronic Health Records
Sep 03, 2025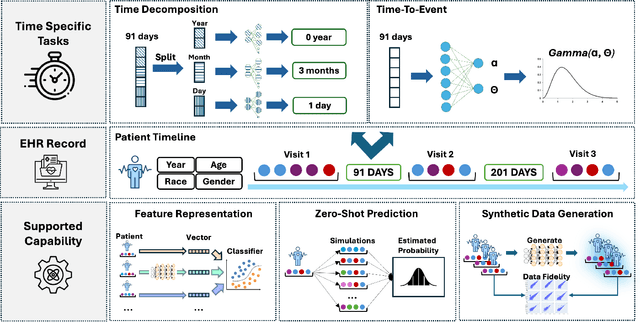


Electronic Health Records (EHRs) provide a rich, longitudinal view of patient health and hold significant potential for advancing clinical decision support, risk prediction, and data-driven healthcare research. However, most artificial intelligence (AI) models for EHRs are designed for narrow, single-purpose tasks, limiting their generalizability and utility in real-world settings. Here, we present CEHR-GPT, a general-purpose foundation model for EHR data that unifies three essential capabilities - feature representation, zero-shot prediction, and synthetic data generation - within a single architecture. To support temporal reasoning over clinical sequences, \cehrgpt{} incorporates a novel time-token-based learning framework that explicitly encodes patients' dynamic timelines into the model structure. CEHR-GPT demonstrates strong performance across all three tasks and generalizes effectively to external datasets through vocabulary expansion and fine-tuning. Its versatility enables rapid model development, cohort discovery, and patient outcome forecasting without the need for task-specific retraining.
Incorporating Human Explanations for Robust Hate Speech Detection
Nov 09, 2024
Given the black-box nature and complexity of large transformer language models (LM), concerns about generalizability and robustness present ethical implications for domains such as hate speech (HS) detection. Using the content rich Social Bias Frames dataset, containing human-annotated stereotypes, intent, and targeted groups, we develop a three stage analysis to evaluate if LMs faithfully assess hate speech. First, we observe the need for modeling contextually grounded stereotype intents to capture implicit semantic meaning. Next, we design a new task, Stereotype Intent Entailment (SIE), which encourages a model to contextually understand stereotype presence. Finally, through ablation tests and user studies, we find a SIE objective improves content understanding, but challenges remain in modeling implicit intent.
Variational Shapley Network: A Probabilistic Approach to Self-Explaining Shapley values with Uncertainty Quantification
Feb 06, 2024Shapley values have emerged as a foundational tool in machine learning (ML) for elucidating model decision-making processes. Despite their widespread adoption and unique ability to satisfy essential explainability axioms, computational challenges persist in their estimation when ($i$) evaluating a model over all possible subset of input feature combinations, ($ii$) estimating model marginals, and ($iii$) addressing variability in explanations. We introduce a novel, self-explaining method that simplifies the computation of Shapley values significantly, requiring only a single forward pass. Recognizing the deterministic treatment of Shapley values as a limitation, we explore incorporating a probabilistic framework to capture the inherent uncertainty in explanations. Unlike alternatives, our technique does not rely directly on the observed data space to estimate marginals; instead, it uses adaptable baseline values derived from a latent, feature-specific embedding space, generated by a novel masked neural network architecture. Evaluations on simulated and real datasets underscore our technique's robust predictive and explanatory performance.
CEHR-GPT: Generating Electronic Health Records with Chronological Patient Timelines
Feb 06, 2024



Synthetic Electronic Health Records (EHR) have emerged as a pivotal tool in advancing healthcare applications and machine learning models, particularly for researchers without direct access to healthcare data. Although existing methods, like rule-based approaches and generative adversarial networks (GANs), generate synthetic data that resembles real-world EHR data, these methods often use a tabular format, disregarding temporal dependencies in patient histories and limiting data replication. Recently, there has been a growing interest in leveraging Generative Pre-trained Transformers (GPT) for EHR data. This enables applications like disease progression analysis, population estimation, counterfactual reasoning, and synthetic data generation. In this work, we focus on synthetic data generation and demonstrate the capability of training a GPT model using a particular patient representation derived from CEHR-BERT, enabling us to generate patient sequences that can be seamlessly converted to the Observational Medical Outcomes Partnership (OMOP) data format.
SPEER: Sentence-Level Planning of Long Clinical Summaries via Embedded Entity Retrieval
Jan 04, 2024



Clinician must write a lengthy summary each time a patient is discharged from the hospital. This task is time-consuming due to the sheer number of unique clinical concepts covered in the admission. Identifying and covering salient entities is vital for the summary to be clinically useful. We fine-tune open-source LLMs (Mistral-7B-Instruct and Zephyr-7B-\b{eta}) on the task and find that they generate incomplete and unfaithful summaries. To increase entity coverage, we train a smaller, encoder-only model to predict salient entities, which are treated as content-plans to guide the LLM. To encourage the LLM to focus on specific mentions in the source notes, we propose SPEER: Sentence-level Planning via Embedded Entity Retrieval. Specifically, we mark each salient entity span with special "{{ }}" boundary tags and instruct the LLM to retrieve marked spans before generating each sentence. Sentence-level planning acts as a form of state tracking in that the model is explicitly recording the entities it uses. We fine-tune Mistral and Zephyr variants on a large-scale, diverse dataset of ~167k in-patient hospital admissions and evaluate on 3 datasets. SPEER shows gains in both coverage and faithfulness metrics over non-guided and guided baselines.
Maximum Likelihood Estimation of Flexible Survival Densities with Importance Sampling
Nov 03, 2023



Survival analysis is a widely-used technique for analyzing time-to-event data in the presence of censoring. In recent years, numerous survival analysis methods have emerged which scale to large datasets and relax traditional assumptions such as proportional hazards. These models, while being performant, are very sensitive to model hyperparameters including: (1) number of bins and bin size for discrete models and (2) number of cluster assignments for mixture-based models. Each of these choices requires extensive tuning by practitioners to achieve optimal performance. In addition, we demonstrate in empirical studies that: (1) optimal bin size may drastically differ based on the metric of interest (e.g., concordance vs brier score), and (2) mixture models may suffer from mode collapse and numerical instability. We propose a survival analysis approach which eliminates the need to tune hyperparameters such as mixture assignments and bin sizes, reducing the burden on practitioners. We show that the proposed approach matches or outperforms baselines on several real-world datasets.