 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Supervised Contrastive Learning Pretrain-Finetune Approach for Time Series
Nov 21, 2023
Foundation models have recently gained attention within the field of machine learning thanks to its efficiency in broad data processing. While researchers had attempted to extend this success to time series models, the main challenge is effectively extracting representations and transferring knowledge from pretraining datasets to the target finetuning dataset. To tackle this issue, we introduce a novel pretraining procedure that leverages supervised contrastive learning to distinguish features within each pretraining dataset. This pretraining phase enables a probabilistic similarity metric, which assesses the likelihood of a univariate sample being closely related to one of the pretraining datasets. Subsequently, using this similarity metric as a guide, we propose a fine-tuning procedure designed to enhance the accurate prediction of the target data by aligning it more closely with the learned dynamics of the pretraining datasets. Our experiments have shown promising results which demonstrate the efficacy of our approach.
Sketching Multidimensional Time Series for Fast Discord Mining
Nov 05, 2023
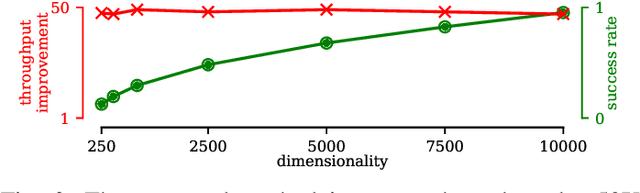
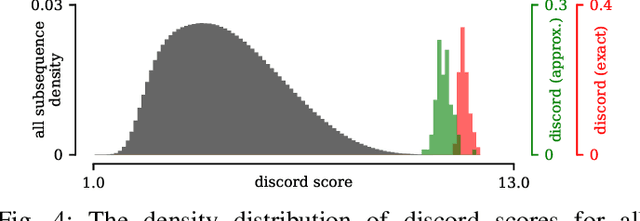
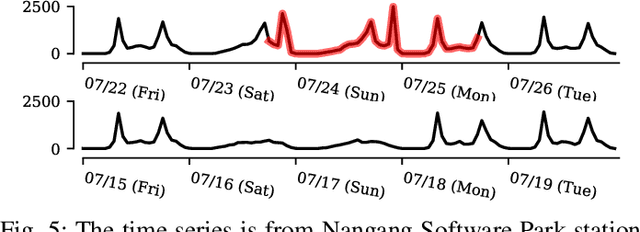
Time series discords are a useful primitive for time series anomaly detection, and the matrix profile is capable of capturing discord effectively. There exist many research efforts to improve the scalability of discord discovery with respect to the length of time series. However, there is surprisingly little work focused on reducing the time complexity of matrix profile computation associated with dimensionality of a multidimensional time series. In this work, we propose a sketch for discord mining among multi-dimensional time series. After an initial pre-processing of the sketch as fast as reading the data, the discord mining has runtime independent of the dimensionality of the original data. On several real world examples from water treatment and transportation, the proposed algorithm improves the throughput by at least an order of magnitude (50X) and only has minimal impact on the quality of the approximated solution. Additionally, the proposed method can handle the dynamic addition or deletion of dimensions inconsequential overhead. This allows a data analyst to consider "what-if" scenarios in real time while exploring the data.
Multiscale Neural Operators for Solving Time-Independent PDEs
Nov 10, 2023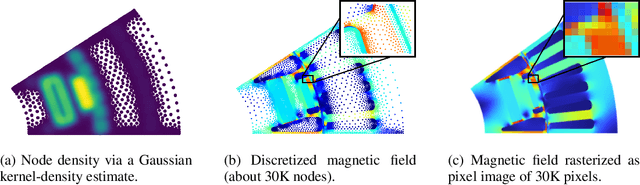
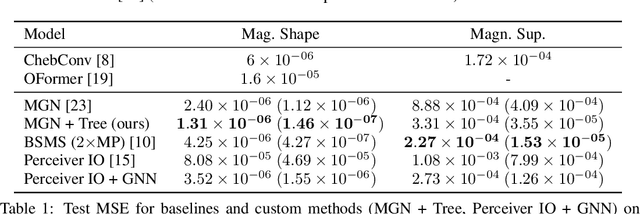
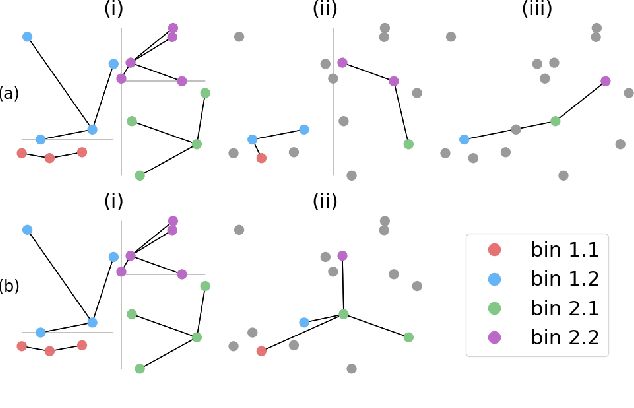

Time-independent Partial Differential Equations (PDEs) on large meshes pose significant challenges for data-driven neural PDE solvers. We introduce a novel graph rewiring technique to tackle some of these challenges, such as aggregating information across scales and on irregular meshes. Our proposed approach bridges distant nodes, enhancing the global interaction capabilities of GNNs. Our experiments on three datasets reveal that GNN-based methods set new performance standards for time-independent PDEs on irregular meshes. Finally, we show that our graph rewiring strategy boosts the performance of baseline methods, achieving state-of-the-art results in one of the tasks.
Conflict Detection for Temporal Knowledge Graphs:A Fast Constraint Mining Algorithm and New Benchmarks
Dec 18, 2023Temporal facts, which are used to describe events that occur during specific time periods, have become a topic of increased interest in the field of knowledge graph (KG) research. In terms of quality management, the introduction of time restrictions brings new challenges to maintaining the temporal consistency of KGs. Previous studies rely on manually enumerated temporal constraints to detect conflicts, which are labor-intensive and may have granularity issues. To address this problem, we start from the common pattern of temporal facts and propose a pattern-based temporal constraint mining method, PaTeCon. Unlike previous studies, PaTeCon uses graph patterns and statistical information relevant to the given KG to automatically generate temporal constraints, without the need for human experts. In this paper, we illustrate how this method can be optimized to achieve significant speed improvement. We also annotate Wikidata and Freebase to build two new benchmarks for conflict detection. Extensive experiments demonstrate that our pattern-based automatic constraint mining approach is highly effective in generating valuable temporal constraints.
Multimodal Classification of Teaching Activities from University Lecture Recordings
Dec 24, 2023The way of understanding online higher education has greatly changed due to the worldwide pandemic situation. Teaching is undertaken remotely, and the faculty incorporate lecture audio recordings as part of the teaching material. This new online teaching-learning setting has largely impacted university classes. While online teaching technology that enriches virtual classrooms has been abundant over the past two years, the same has not occurred in supporting students during online learning. {To overcome this limitation, our aim is to work toward enabling students to easily access the piece of the lesson recording in which the teacher explains a theoretical concept, solves an exercise, or comments on organizational issues of the course. To that end, we present a multimodal classification algorithm that identifies the type of activity that is being carried out at any time of the lesson by using a transformer-based language model that exploits features from the audio file and from the automated lecture transcription. The experimental results will show that some academic activities are more easily identifiable with the audio signal while resorting to the text transcription is needed to identify others. All in all, our contribution aims to recognize the academic activities of a teacher during a lesson.
* 18 pages
Fairness-Aware Structured Pruning in Transformers
Dec 24, 2023The increasing size of large language models (LLMs) has introduced challenges in their training and inference. Removing model components is perceived as a solution to tackle the large model sizes, however, existing pruning methods solely focus on performance, without considering an essential aspect for the responsible use of LLMs: model fairness. It is crucial to address the fairness of LLMs towards diverse groups, such as women, Black people, LGBTQ+, Jewish communities, among others, as they are being deployed and available to a wide audience. In this work, first, we investigate how attention heads impact fairness and performance in pre-trained transformer-based language models. We then propose a novel method to prune the attention heads that negatively impact fairness while retaining the heads critical for performance, i.e. language modeling capabilities. Our approach is practical in terms of time and resources, as it does not require fine-tuning the final pruned, and fairer, model. Our findings demonstrate a reduction in gender bias by 19%, 19.5%, 39.5%, 34.7%, 23%, and 8% for DistilGPT-2, GPT-2, GPT-Neo of two different sizes, GPT-J, and Llama 2 models, respectively, in comparison to the biased model, with only a slight decrease in performance.
Tuning the activation function to optimize the forecast horizon of a reservoir computer
Dec 20, 2023Reservoir computing is a machine learning framework where the readouts from a nonlinear system (the reservoir) are trained so that the output from the reservoir, when forced with an input signal, reproduces a desired output signal. A common implementation of reservoir computers is to use a recurrent neural network as the reservoir. The design of this network can have significant effects on the performance of the reservoir computer. In this paper we study the effect of the node activation function on the ability of reservoir computers to learn and predict chaotic time series. We find that the Forecast Horizon (FH), the time during which the reservoir's predictions remain accurate, can vary by an order of magnitude across a set of 16 activation functions used in machine learning. By using different functions from this set, and by modifying their parameters, we explore whether the entropy of node activation levels or the curvature of the activation functions determine the predictive ability of the reservoirs. We find that the FH is low when the activation function is used in a region where it has low curvature, and a positive correlation between curvature and FH. For the activation functions studied we find that the largest FH generally occurs at intermediate levels of the entropy of node activation levels. Our results show that the performance of reservoir computers is very sensitive to the activation function shape. Therefore, modifying this shape in hyperparameter optimization algorithms can lead to improvements in reservoir computer performance.
Audiobox: Unified Audio Generation with Natural Language Prompts
Dec 25, 2023Audio is an essential part of our life, but creating it often requires expertise and is time-consuming. Research communities have made great progress over the past year advancing the performance of large scale audio generative models for a single modality (speech, sound, or music) through adopting more powerful generative models and scaling data. However, these models lack controllability in several aspects: speech generation models cannot synthesize novel styles based on text description and are limited on domain coverage such as outdoor environments; sound generation models only provide coarse-grained control based on descriptions like "a person speaking" and would only generate mumbling human voices. This paper presents Audiobox, a unified model based on flow-matching that is capable of generating various audio modalities. We design description-based and example-based prompting to enhance controllability and unify speech and sound generation paradigms. We allow transcript, vocal, and other audio styles to be controlled independently when generating speech. To improve model generalization with limited labels, we adapt a self-supervised infilling objective to pre-train on large quantities of unlabeled audio. Audiobox sets new benchmarks on speech and sound generation (0.745 similarity on Librispeech for zero-shot TTS; 0.77 FAD on AudioCaps for text-to-sound) and unlocks new methods for generating audio with novel vocal and acoustic styles. We further integrate Bespoke Solvers, which speeds up generation by over 25 times compared to the default ODE solver for flow-matching, without loss of performance on several tasks. Our demo is available at https://audiobox.metademolab.com/
Rotation Equivariant Proximal Operator for Deep Unfolding Methods in Image Restoration
Dec 25, 2023The deep unfolding approach has attracted significant attention in computer vision tasks, which well connects conventional image processing modeling manners with more recent deep learning techniques. Specifically, by establishing a direct correspondence between algorithm operators at each implementation step and network modules within each layer, one can rationally construct an almost ``white box'' network architecture with high interpretability. In this architecture, only the predefined component of the proximal operator, known as a proximal network, needs manual configuration, enabling the network to automatically extract intrinsic image priors in a data-driven manner. In current deep unfolding methods, such a proximal network is generally designed as a CNN architecture, whose necessity has been proven by a recent theory. That is, CNN structure substantially delivers the translational invariant image prior, which is the most universally possessed structural prior across various types of images. However, standard CNN-based proximal networks have essential limitations in capturing the rotation symmetry prior, another universal structural prior underlying general images. This leaves a large room for further performance improvement in deep unfolding approaches. To address this issue, this study makes efforts to suggest a high-accuracy rotation equivariant proximal network that effectively embeds rotation symmetry priors into the deep unfolding framework. Especially, we deduce, for the first time, the theoretical equivariant error for such a designed proximal network with arbitrary layers under arbitrary rotation degrees. This analysis should be the most refined theoretical conclusion for such error evaluation to date and is also indispensable for supporting the rationale behind such networks with intrinsic interpretability requirements.
An Explainable AI Approach to Large Language Model Assisted Causal Model Auditing and Development
Dec 23, 2023Causal networks are widely used in many fields, including epidemiology, social science, medicine, and engineering, to model the complex relationships between variables. While it can be convenient to algorithmically infer these models directly from observational data, the resulting networks are often plagued with erroneous edges. Auditing and correcting these networks may require domain expertise frequently unavailable to the analyst. We propose the use of large language models such as ChatGPT as an auditor for causal networks. Our method presents ChatGPT with a causal network, one edge at a time, to produce insights about edge directionality, possible confounders, and mediating variables. We ask ChatGPT to reflect on various aspects of each causal link and we then produce visualizations that summarize these viewpoints for the human analyst to direct the edge, gather more data, or test further hypotheses. We envision a system where large language models, automated causal inference, and the human analyst and domain expert work hand in hand as a team to derive holistic and comprehensive causal models for any given case scenario. This paper presents first results obtained with an emerging prototype.