 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeONEBench to Test Them All: Sample-Level Benchmarking Over Open-Ended Capabilities
Dec 09, 2024



Traditional fixed test sets fall short in evaluating open-ended capabilities of foundation models. To address this, we propose ONEBench(OpeN-Ended Benchmarking), a new testing paradigm that consolidates individual evaluation datasets into a unified, ever-expanding sample pool. ONEBench allows users to generate custom, open-ended evaluation benchmarks from this pool, corresponding to specific capabilities of interest. By aggregating samples across test sets, ONEBench enables the assessment of diverse capabilities beyond those covered by the original test sets, while mitigating overfitting and dataset bias. Most importantly, it frames model evaluation as a collective process of selecting and aggregating sample-level tests. The shift from task-specific benchmarks to ONEBench introduces two challenges: (1)heterogeneity and (2)incompleteness. Heterogeneity refers to the aggregation over diverse metrics, while incompleteness describes comparing models evaluated on different data subsets. To address these challenges, we explore algorithms to aggregate sparse measurements into reliable model scores. Our aggregation algorithm ensures identifiability(asymptotically recovering ground-truth scores) and rapid convergence, enabling accurate model ranking with less data. On homogenous datasets, we show our aggregation algorithm provides rankings that highly correlate with those produced by average scores. We also demonstrate robustness to ~95% of measurements missing, reducing evaluation cost by up to 20x with little-to-no change in model rankings. We introduce ONEBench-LLM for language models and ONEBench-LMM for vision-language models, unifying evaluations across these domains. Overall, we present a technique for open-ended evaluation, which can aggregate over incomplete, heterogeneous sample-level measurements to continually grow a benchmark alongside the rapidly developing foundation models.
How to Merge Your Multimodal Models Over Time?
Dec 09, 2024



Model merging combines multiple expert models - finetuned from a base foundation model on diverse tasks and domains - into a single, more capable model. However, most existing model merging approaches assume that all experts are available simultaneously. In reality, new tasks and domains emerge progressively over time, requiring strategies to integrate the knowledge of expert models as they become available: a process we call temporal model merging. The temporal dimension introduces unique challenges not addressed in prior work, raising new questions such as: when training for a new task, should the expert model start from the merged past experts or from the original base model? Should we merge all models at each time step? Which merging techniques are best suited for temporal merging? Should different strategies be used to initialize the training and deploy the model? To answer these questions, we propose a unified framework called TIME - Temporal Integration of Model Expertise - which defines temporal model merging across three axes: (1) Initialization Phase, (2) Deployment Phase, and (3) Merging Technique. Using TIME, we study temporal model merging across model sizes, compute budgets, and learning horizons on the FoMo-in-Flux benchmark. Our comprehensive suite of experiments across TIME allows us to uncover key insights for temporal model merging, offering a better understanding of current challenges and best practices for effective temporal model merging.
A Practitioner's Guide to Continual Multimodal Pretraining
Aug 26, 2024Multimodal foundation models serve numerous applications at the intersection of vision and language. Still, despite being pretrained on extensive data, they become outdated over time. To keep models updated, research into continual pretraining mainly explores scenarios with either (1) infrequent, indiscriminate updates on large-scale new data, or (2) frequent, sample-level updates. However, practical model deployment often operates in the gap between these two limit cases, as real-world applications often demand adaptation to specific subdomains, tasks or concepts -- spread over the entire, varying life cycle of a model. In this work, we complement current perspectives on continual pretraining through a research test bed as well as provide comprehensive guidance for effective continual model updates in such scenarios. We first introduce FoMo-in-Flux, a continual multimodal pretraining benchmark with realistic compute constraints and practical deployment requirements, constructed over 63 datasets with diverse visual and semantic coverage. Using FoMo-in-Flux, we explore the complex landscape of practical continual pretraining through multiple perspectives: (1) A data-centric investigation of data mixtures and stream orderings that emulate real-world deployment situations, (2) a method-centric investigation ranging from simple fine-tuning and traditional continual learning strategies to parameter-efficient updates and model merging, (3) meta learning rate schedules and mechanistic design choices, and (4) the influence of model and compute scaling. Together, our insights provide a practitioner's guide to continual multimodal pretraining for real-world deployment. Our benchmark and code is here: https://github.com/ExplainableML/fomo_in_flux.
Disentangled Continual Learning: Separating Memory Edits from Model Updates
Dec 27, 2023



The ability of machine learning systems to learn continually is hindered by catastrophic forgetting, the tendency of neural networks to overwrite existing knowledge when learning a new task. Existing continual learning methods alleviate this problem through regularisation, parameter isolation, or rehearsal, and are typically evaluated on benchmarks consisting of a handful of tasks. We propose a novel conceptual approach to continual classification that aims to disentangle class-specific information that needs to be memorised from the class-agnostic knowledge that encapsulates generalization. We store the former in a buffer that can be easily pruned or updated when new categories arrive, while the latter is represented with a neural network that generalizes across tasks. We show that the class-agnostic network does not suffer from catastrophic forgetting and by leveraging it to perform classification, we improve accuracy on past tasks over time. In addition, our approach supports open-set classification and one-shot generalization. To test our conceptual framework, we introduce Infinite dSprites, a tool for creating continual classification and disentanglement benchmarks of arbitrary length with full control over generative factors. We show that over a sufficiently long time horizon all major types of continual learning methods break down, while our approach enables continual learning over hundreds of tasks with explicit control over memorization and forgetting.
Multiscale Neural Operators for Solving Time-Independent PDEs
Nov 10, 2023Time-independent Partial Differential Equations (PDEs) on large meshes pose significant challenges for data-driven neural PDE solvers. We introduce a novel graph rewiring technique to tackle some of these challenges, such as aggregating information across scales and on irregular meshes. Our proposed approach bridges distant nodes, enhancing the global interaction capabilities of GNNs. Our experiments on three datasets reveal that GNN-based methods set new performance standards for time-independent PDEs on irregular meshes. Finally, we show that our graph rewiring strategy boosts the performance of baseline methods, achieving state-of-the-art results in one of the tasks.
Fake It Till You Make It: Face analysis in the wild using synthetic data alone
Oct 05, 2021
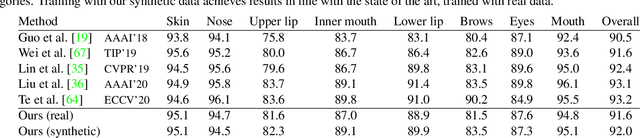


We demonstrate that it is possible to perform face-related computer vision in the wild using synthetic data alone. The community has long enjoyed the benefits of synthesizing training data with graphics, but the domain gap between real and synthetic data has remained a problem, especially for human faces. Researchers have tried to bridge this gap with data mixing, domain adaptation, and domain-adversarial training, but we show that it is possible to synthesize data with minimal domain gap, so that models trained on synthetic data generalize to real in-the-wild datasets. We describe how to combine a procedurally-generated parametric 3D face model with a comprehensive library of hand-crafted assets to render training images with unprecedented realism and diversity. We train machine learning systems for face-related tasks such as landmark localization and face parsing, showing that synthetic data can both match real data in accuracy as well as open up new approaches where manual labelling would be impossible.
A high fidelity synthetic face framework for computer vision
Jul 16, 2020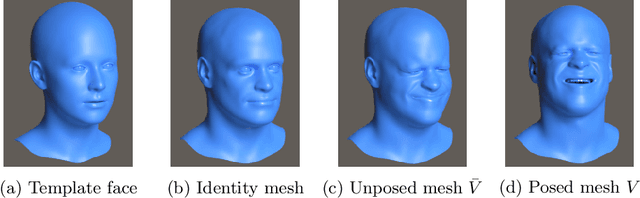

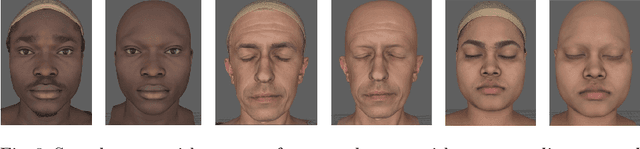

Analysis of faces is one of the core applications of computer vision, with tasks ranging from landmark alignment, head pose estimation, expression recognition, and face recognition among others. However, building reliable methods requires time-consuming data collection and often even more time-consuming manual annotation, which can be unreliable. In our work we propose synthesizing such facial data, including ground truth annotations that would be almost impossible to acquire through manual annotation at the consistency and scale possible through use of synthetic data. We use a parametric face model together with hand crafted assets which enable us to generate training data with unprecedented quality and diversity (varying shape, texture, expression, pose, lighting, and hair).