 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Registry-Bound LLM Pipeline for Evidence-Grounded Trait Extraction across Tropical Plants, Aquatic Species, and Exotic Pets
May 31, 2026We describe a registry-bound large-language-model extraction pipeline producing evidence-grounded structured trait records at scale, on cultivated tropical plant, aquatic, and pet species. Four mechanisms render LLM-derived rows auditable: a versioned 39-key closed-vocabulary trait registry constraining every admitted value to a typed schema; a per-row verbatim evidence quote tying each value to source text; a per-row confidence label (high or medium; low dropped pre-persist); and multi-version preservation. Applied to 409,880 publishable species from the Tropical Species Encyclopedia, the pipeline executed 706,220 runs and persisted 5,489,881 trait records across 409,820 species (99.985%), 81.57% at high confidence. We report three validation layers in descending evidentiary strength: at full population, 90.12% of 5,427,588 evidence-bearing rows have their quote as a verbatim source substring (93.49% excluding one compliance meta-trait); a quote-supports-value audit on n=100 stratified non-red-zone rows yielded 100/100 (lower bound 96.30%); face-validity on n=50 red-zone rows yielded 50/50 Accept (lower bound 92.86%). Per-record correctness is not claimed; 100% pending human curation. The contribution is the four-mechanism framework.
Unveiling the Black Box: A Multi-Layer Framework for Explaining Reinforcement Learning-Based Cyber Agents
May 16, 2025



Reinforcement Learning (RL) agents are increasingly used to simulate sophisticated cyberattacks, but their decision-making processes remain opaque, hindering trust, debugging, and defensive preparedness. In high-stakes cybersecurity contexts, explainability is essential for understanding how adversarial strategies are formed and evolve over time. In this paper, we propose a unified, multi-layer explainability framework for RL-based attacker agents that reveals both strategic (MDP-level) and tactical (policy-level) reasoning. At the MDP level, we model cyberattacks as a Partially Observable Markov Decision Processes (POMDPs) to expose exploration-exploitation dynamics and phase-aware behavioural shifts. At the policy level, we analyse the temporal evolution of Q-values and use Prioritised Experience Replay (PER) to surface critical learning transitions and evolving action preferences. Evaluated across CyberBattleSim environments of increasing complexity, our framework offers interpretable insights into agent behaviour at scale. Unlike previous explainable RL methods, which are often post-hoc, domain-specific, or limited in depth, our approach is both agent- and environment-agnostic, supporting use cases ranging from red-team simulation to RL policy debugging. By transforming black-box learning into actionable behavioural intelligence, our framework enables both defenders and developers to better anticipate, analyse, and respond to autonomous cyber threats.
Audiobox: Unified Audio Generation with Natural Language Prompts
Dec 25, 2023



Audio is an essential part of our life, but creating it often requires expertise and is time-consuming. Research communities have made great progress over the past year advancing the performance of large scale audio generative models for a single modality (speech, sound, or music) through adopting more powerful generative models and scaling data. However, these models lack controllability in several aspects: speech generation models cannot synthesize novel styles based on text description and are limited on domain coverage such as outdoor environments; sound generation models only provide coarse-grained control based on descriptions like "a person speaking" and would only generate mumbling human voices. This paper presents Audiobox, a unified model based on flow-matching that is capable of generating various audio modalities. We design description-based and example-based prompting to enhance controllability and unify speech and sound generation paradigms. We allow transcript, vocal, and other audio styles to be controlled independently when generating speech. To improve model generalization with limited labels, we adapt a self-supervised infilling objective to pre-train on large quantities of unlabeled audio. Audiobox sets new benchmarks on speech and sound generation (0.745 similarity on Librispeech for zero-shot TTS; 0.77 FAD on AudioCaps for text-to-sound) and unlocks new methods for generating audio with novel vocal and acoustic styles. We further integrate Bespoke Solvers, which speeds up generation by over 25 times compared to the default ODE solver for flow-matching, without loss of performance on several tasks. Our demo is available at https://audiobox.metademolab.com/
Seamless: Multilingual Expressive and Streaming Speech Translation
Dec 08, 2023



Large-scale automatic speech translation systems today lack key features that help machine-mediated communication feel seamless when compared to human-to-human dialogue. In this work, we introduce a family of models that enable end-to-end expressive and multilingual translations in a streaming fashion. First, we contribute an improved version of the massively multilingual and multimodal SeamlessM4T model-SeamlessM4T v2. This newer model, incorporating an updated UnitY2 framework, was trained on more low-resource language data. SeamlessM4T v2 provides the foundation on which our next two models are initiated. SeamlessExpressive enables translation that preserves vocal styles and prosody. Compared to previous efforts in expressive speech research, our work addresses certain underexplored aspects of prosody, such as speech rate and pauses, while also preserving the style of one's voice. As for SeamlessStreaming, our model leverages the Efficient Monotonic Multihead Attention mechanism to generate low-latency target translations without waiting for complete source utterances. As the first of its kind, SeamlessStreaming enables simultaneous speech-to-speech/text translation for multiple source and target languages. To ensure that our models can be used safely and responsibly, we implemented the first known red-teaming effort for multimodal machine translation, a system for the detection and mitigation of added toxicity, a systematic evaluation of gender bias, and an inaudible localized watermarking mechanism designed to dampen the impact of deepfakes. Consequently, we bring major components from SeamlessExpressive and SeamlessStreaming together to form Seamless, the first publicly available system that unlocks expressive cross-lingual communication in real-time. The contributions to this work are publicly released and accessible at https://github.com/facebookresearch/seamless_communication
SeamlessM4T-Massively Multilingual & Multimodal Machine Translation
Aug 23, 2023



What does it take to create the Babel Fish, a tool that can help individuals translate speech between any two languages? While recent breakthroughs in text-based models have pushed machine translation coverage beyond 200 languages, unified speech-to-speech translation models have yet to achieve similar strides. More specifically, conventional speech-to-speech translation systems rely on cascaded systems that perform translation progressively, putting high-performing unified systems out of reach. To address these gaps, we introduce SeamlessM4T, a single model that supports speech-to-speech translation, speech-to-text translation, text-to-speech translation, text-to-text translation, and automatic speech recognition for up to 100 languages. To build this, we used 1 million hours of open speech audio data to learn self-supervised speech representations with w2v-BERT 2.0. Subsequently, we created a multimodal corpus of automatically aligned speech translations. Filtered and combined with human-labeled and pseudo-labeled data, we developed the first multilingual system capable of translating from and into English for both speech and text. On FLEURS, SeamlessM4T sets a new standard for translations into multiple target languages, achieving an improvement of 20% BLEU over the previous SOTA in direct speech-to-text translation. Compared to strong cascaded models, SeamlessM4T improves the quality of into-English translation by 1.3 BLEU points in speech-to-text and by 2.6 ASR-BLEU points in speech-to-speech. Tested for robustness, our system performs better against background noises and speaker variations in speech-to-text tasks compared to the current SOTA model. Critically, we evaluated SeamlessM4T on gender bias and added toxicity to assess translation safety. Finally, all contributions in this work are open-sourced and accessible at https://github.com/facebookresearch/seamless_communication
OPT-IML: Scaling Language Model Instruction Meta Learning through the Lens of Generalization
Dec 28, 2022



Recent work has shown that fine-tuning large pre-trained language models on a collection of tasks described via instructions, a.k.a. instruction-tuning, improves their zero and few-shot generalization to unseen tasks. However, there is a limited understanding of the performance trade-offs of different decisions made during the instruction-tuning process. These decisions include the scale and diversity of the instruction-tuning benchmark, different task sampling strategies, fine-tuning with and without demonstrations, training using specialized datasets for reasoning and dialogue, and finally, the fine-tuning objectives themselves. In this paper, we characterize the effect of instruction-tuning decisions on downstream task performance when scaling both model and benchmark sizes. To this end, we create OPT-IML Bench: a large benchmark for Instruction Meta-Learning (IML) of 2000 NLP tasks consolidated into task categories from 8 existing benchmarks, and prepare an evaluation framework to measure three types of model generalizations: to tasks from fully held-out categories, to held-out tasks from seen categories, and to held-out instances from seen tasks. Through the lens of this framework, we first present insights about instruction-tuning decisions as applied to OPT-30B and further exploit these insights to train OPT-IML 30B and 175B, which are instruction-tuned versions of OPT. OPT-IML demonstrates all three generalization abilities at both scales on four different evaluation benchmarks with diverse tasks and input formats -- PromptSource, FLAN, Super-NaturalInstructions, and UnifiedSKG. Not only does it significantly outperform OPT on all benchmarks but is also highly competitive with existing models fine-tuned on each specific benchmark. We release OPT-IML at both scales, together with the OPT-IML Bench evaluation framework.
No Language Left Behind: Scaling Human-Centered Machine Translation
Jul 11, 2022
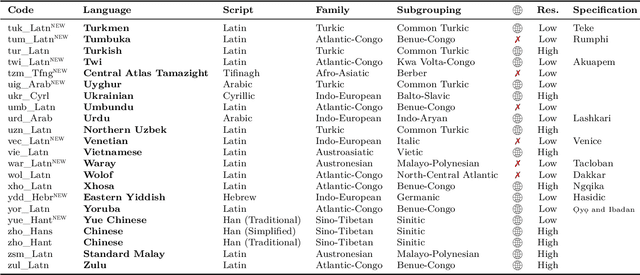
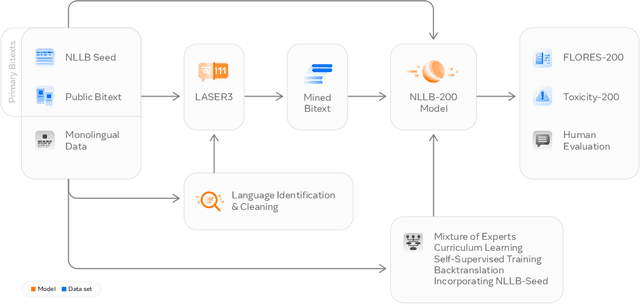
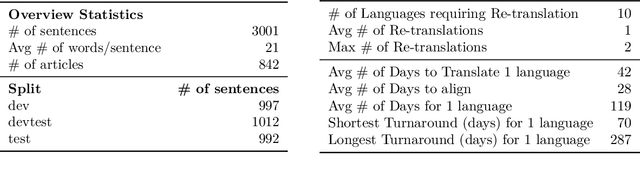
Driven by the goal of eradicating language barriers on a global scale, machine translation has solidified itself as a key focus of artificial intelligence research today. However, such efforts have coalesced around a small subset of languages, leaving behind the vast majority of mostly low-resource languages. What does it take to break the 200 language barrier while ensuring safe, high quality results, all while keeping ethical considerations in mind? In No Language Left Behind, we took on this challenge by first contextualizing the need for low-resource language translation support through exploratory interviews with native speakers. Then, we created datasets and models aimed at narrowing the performance gap between low and high-resource languages. More specifically, we developed a conditional compute model based on Sparsely Gated Mixture of Experts that is trained on data obtained with novel and effective data mining techniques tailored for low-resource languages. We propose multiple architectural and training improvements to counteract overfitting while training on thousands of tasks. Critically, we evaluated the performance of over 40,000 different translation directions using a human-translated benchmark, Flores-200, and combined human evaluation with a novel toxicity benchmark covering all languages in Flores-200 to assess translation safety. Our model achieves an improvement of 44% BLEU relative to the previous state-of-the-art, laying important groundwork towards realizing a universal translation system. Finally, we open source all contributions described in this work, accessible at https://github.com/facebookresearch/fairseq/tree/nllb.
Efficient Large Scale Language Modeling with Mixtures of Experts
Dec 20, 2021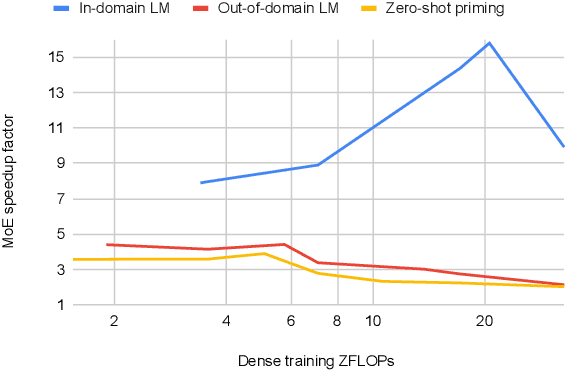
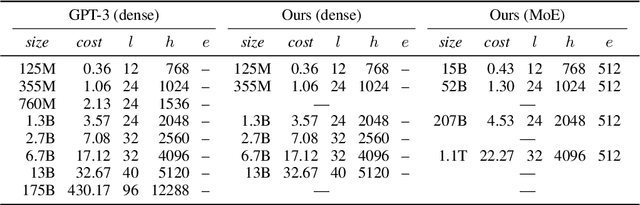
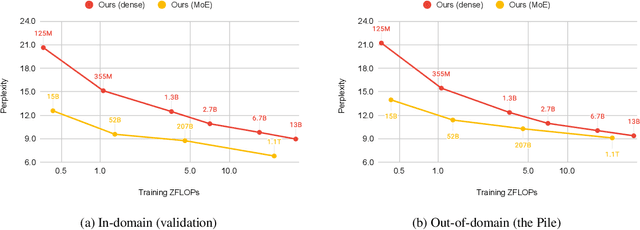
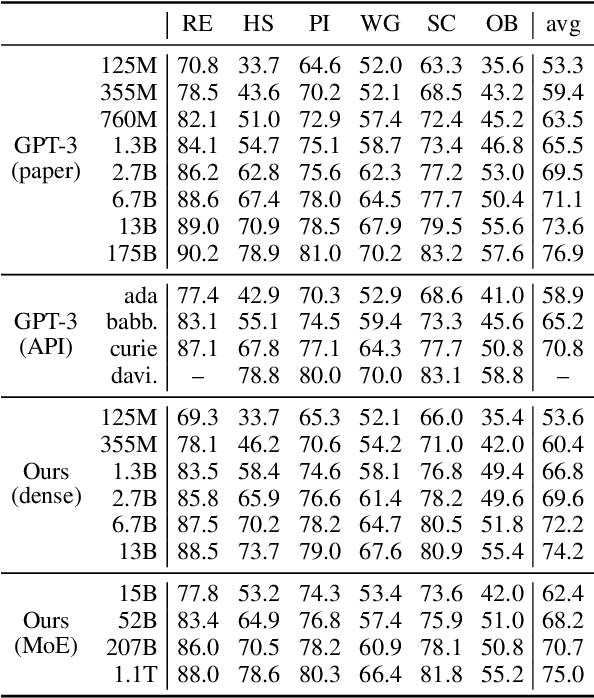
Mixture of Experts layers (MoEs) enable efficient scaling of language models through conditional computation. This paper presents a detailed empirical study of how autoregressive MoE language models scale in comparison with dense models in a wide range of settings: in- and out-of-domain language modeling, zero- and few-shot priming, and full fine-tuning. With the exception of fine-tuning, we find MoEs to be substantially more compute efficient. At more modest training budgets, MoEs can match the performance of dense models using $\sim$4 times less compute. This gap narrows at scale, but our largest MoE model (1.1T parameters) consistently outperforms a compute-equivalent dense model (6.7B parameters). Overall, this performance gap varies greatly across tasks and domains, suggesting that MoE and dense models generalize differently in ways that are worthy of future study. We make our code and models publicly available for research use.
Few-shot Learning with Multilingual Language Models
Dec 20, 2021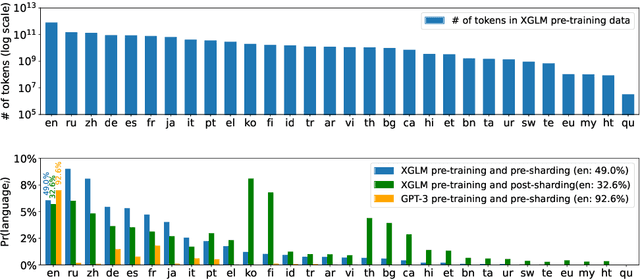
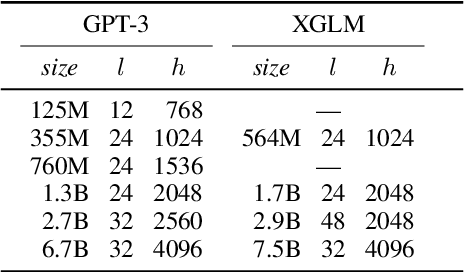
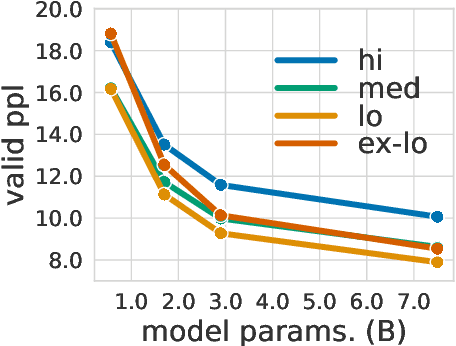

Large-scale autoregressive language models such as GPT-3 are few-shot learners that can perform a wide range of language tasks without fine-tuning. While these models are known to be able to jointly represent many different languages, their training data is dominated by English, potentially limiting their cross-lingual generalization. In this work, we train multilingual autoregressive language models on a balanced corpus covering a diverse set of languages, and study their few- and zero-shot learning capabilities in a wide range of tasks. Our largest model with 7.5 billion parameters sets new state of the art in few-shot learning in more than 20 representative languages, outperforming GPT-3 of comparable size in multilingual commonsense reasoning (with +7.4% absolute accuracy improvement in 0-shot settings and +9.4% in 4-shot settings) and natural language inference (+5.4% in each of 0-shot and 4-shot settings). On the FLORES-101 machine translation benchmark, our model outperforms GPT-3 on 171 out of 182 translation directions with 32 training examples, while surpassing the official supervised baseline in 45 directions. We present a detailed analysis of where the model succeeds and fails, showing in particular that it enables cross-lingual in-context learning on some tasks, while there is still room for improvement on surface form robustness and adaptation to tasks that do not have a natural cloze form. Finally, we evaluate our models in social value tasks such as hate speech detection in five languages and find it has limitations similar to comparable sized GPT-3 models.
Region-specific Dictionary Learning-based Low-dose Thoracic CT Reconstruction
Oct 20, 2020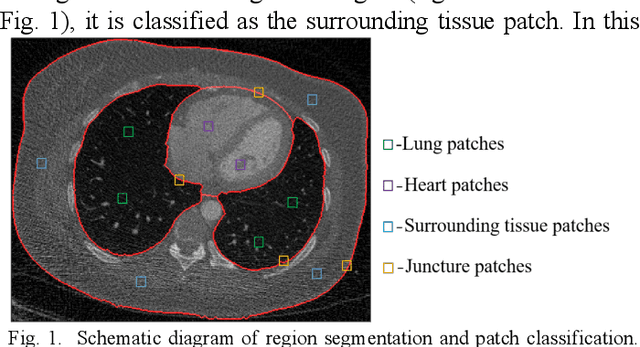
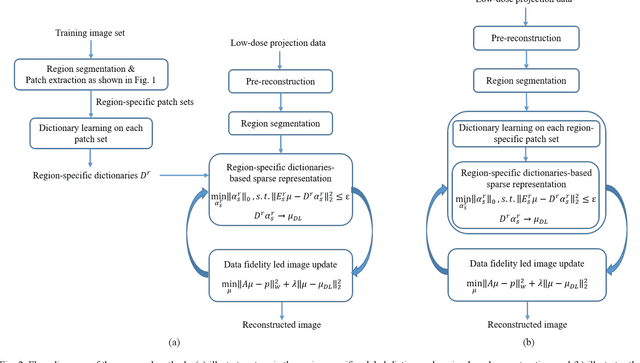

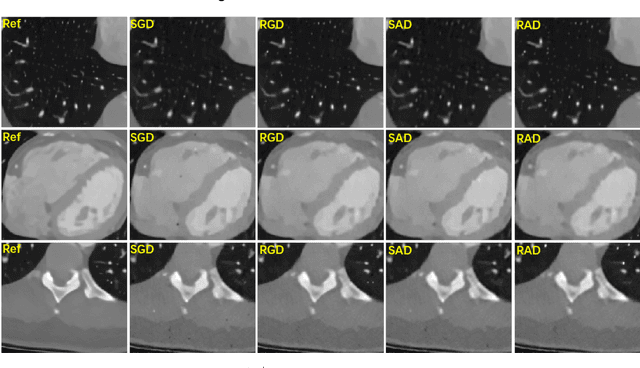
This paper presents a dictionary learning-based method with region-specific image patches to maximize the utility of the powerful sparse data processing technique for CT image reconstruction. Considering heterogeneous distributions of image features and noise in CT, region-specific customization of dictionaries is utilized in iterative reconstruction. Thoracic CT images are partitioned into several regions according to their structural and noise characteristics. Dictionaries specific to each region are then learned from the segmented thoracic CT images and applied to subsequent image reconstruction of the region. Parameters for dictionary learning and sparse representation are determined according to the structural and noise properties of each region. The proposed method results in better performance than the conventional reconstruction based on a single dictionary in recovering structures and suppressing noise in both simulation and human CT imaging. Quantitatively, the simulation study shows maximum improvement of image quality for the whole thorax can achieve 4.88% and 11.1% in terms of the Structure-SIMilarity (SSIM) and Root-Mean-Square Error (RMSE) indices, respectively. For human imaging data, it is found that the structures in the lungs and heart can be better recovered, while simultaneously decreasing noise around the vertebra effectively. The proposed strategy takes into account inherent regional differences inside of the reconstructed object and leads to improved images. The method can be readily extended to CT imaging of other anatomical regions and other applications.