 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Localizing the Common Action Among a Few Videos
Aug 25, 2020
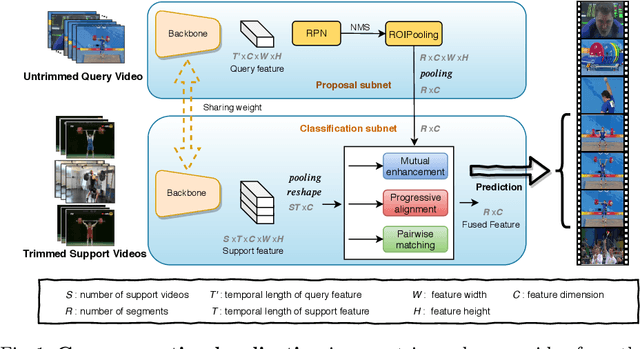
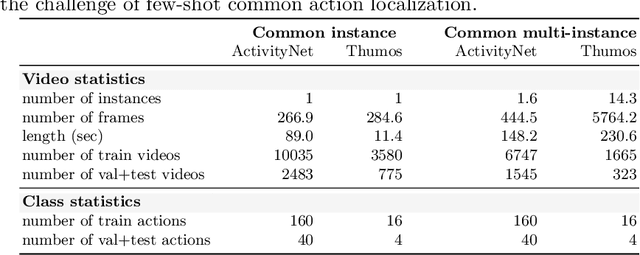
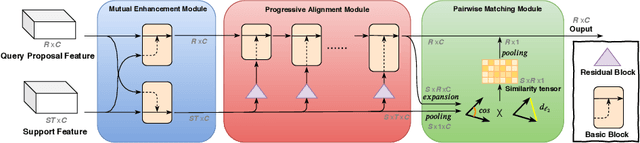
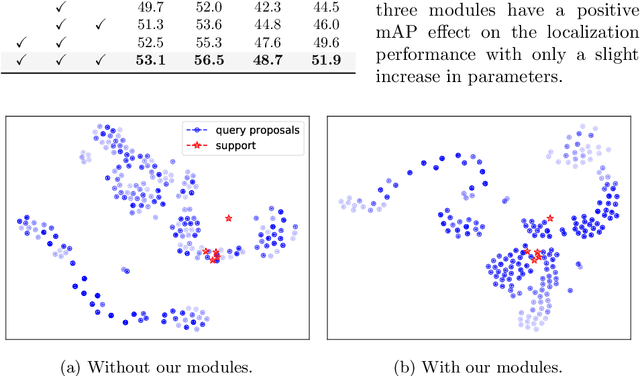
This paper strives to localize the temporal extent of an action in a long untrimmed video. Where existing work leverages many examples with their start, their ending, and/or the class of the action during training time, we propose few-shot common action localization. The start and end of an action in a long untrimmed video is determined based on just a hand-full of trimmed video examples containing the same action, without knowing their common class label. To address this task, we introduce a new 3D convolutional network architecture able to align representations from the support videos with the relevant query video segments. The network contains: (\textit{i}) a mutual enhancement module to simultaneously complement the representation of the few trimmed support videos and the untrimmed query video; (\textit{ii}) a progressive alignment module that iteratively fuses the support videos into the query branch; and (\textit{iii}) a pairwise matching module to weigh the importance of different support videos. Evaluation of few-shot common action localization in untrimmed videos containing a single or multiple action instances demonstrates the effectiveness and general applicability of our proposal.
AIM 2020 Challenge on Video Extreme Super-Resolution: Methods and Results
Sep 14, 2020This paper reviews the video extreme super-resolution challenge associated with the AIM 2020 workshop at ECCV 2020. Common scaling factors for learned video super-resolution (VSR) do not go beyond factor 4. Missing information can be restored well in this region, especially in HR videos, where the high-frequency content mostly consists of texture details. The task in this challenge is to upscale videos with an extreme factor of 16, which results in more serious degradations that also affect the structural integrity of the videos. A single pixel in the low-resolution (LR) domain corresponds to 256 pixels in the high-resolution (HR) domain. Due to this massive information loss, it is hard to accurately restore the missing information. Track 1 is set up to gauge the state-of-the-art for such a demanding task, where fidelity to the ground truth is measured by PSNR and SSIM. Perceptually higher quality can be achieved in trade-off for fidelity by generating plausible high-frequency content. Track 2 therefore aims at generating visually pleasing results, which are ranked according to human perception, evaluated by a user study. In contrast to single image super-resolution (SISR), VSR can benefit from additional information in the temporal domain. However, this also imposes an additional requirement, as the generated frames need to be consistent along time.
Real-Time Inference with Large-Scale Temporal Bayes Nets
Dec 12, 2012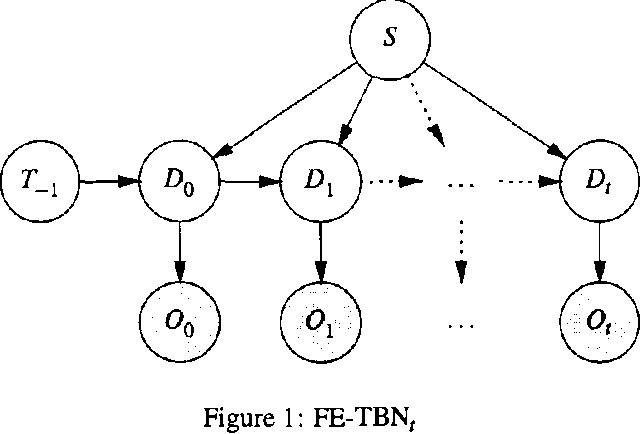

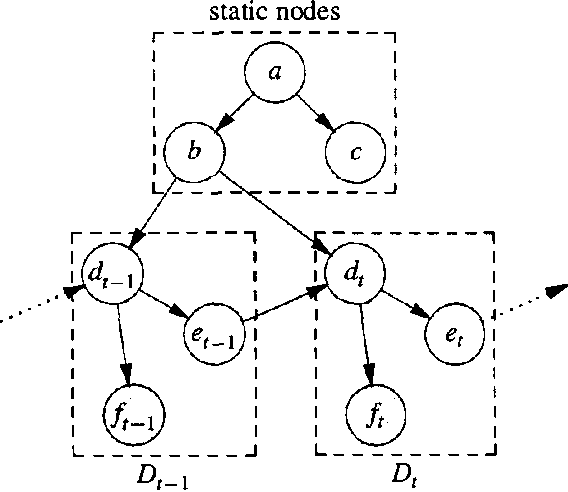
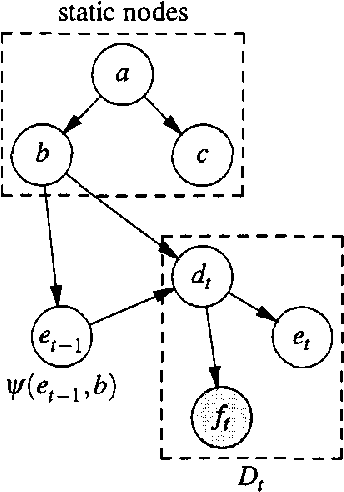
An increasing number of applications require real-time reasoning under uncertainty with streaming input. The temporal (dynamic) Bayes net formalism provides a powerful representational framework for such applications. However, existing exact inference algorithms for dynamic Bayes nets do not scale to the size of models required for real world applications which often contain hundreds or even thousands of variables for each time slice. In addition, existing algorithms were not developed with real-time processing in mind. We have developed a new computational approach to support real-time exact inference in large temporal Bayes nets. Our approach tackles scalability by recognizing that the complexity of the inference depends on the number of interface nodes between time slices and by exploiting the distinction between static and dynamic nodes in order to reduce the number of interface nodes and to factorize their joint probability distribution. We approach the real-time issue by organizing temporal Bayes nets into static representations, and then using the symbolic probabilistic inference algorithm to derive analytic expressions for the static representations. The parts of these expressions that do not change at each time step are pre-computed. The remaining parts are compiled into efficient procedural code so that the memory and CPU resources required by the inference are small and fixed.
Ensemble Forecasting of Monthly Electricity Demand using Pattern Similarity-based Methods
Mar 29, 2020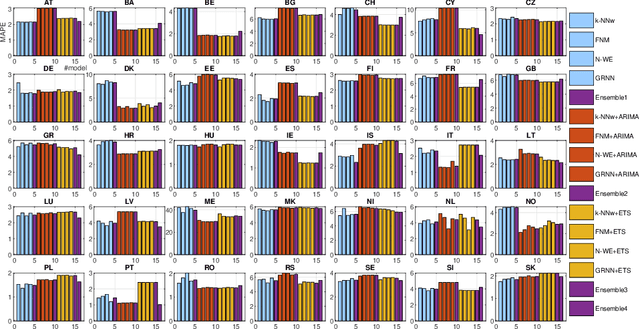
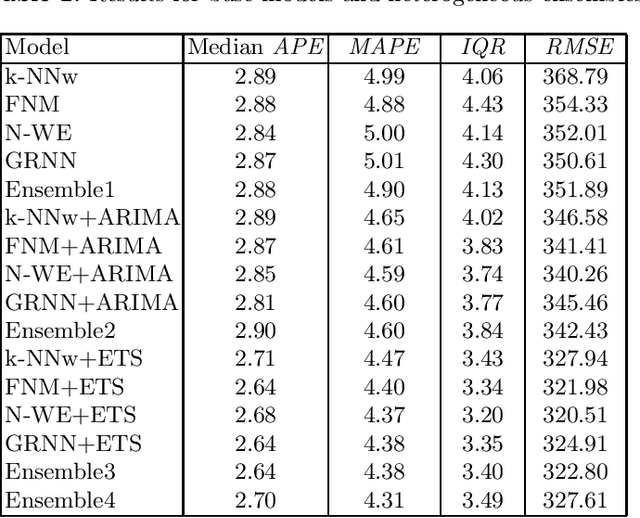
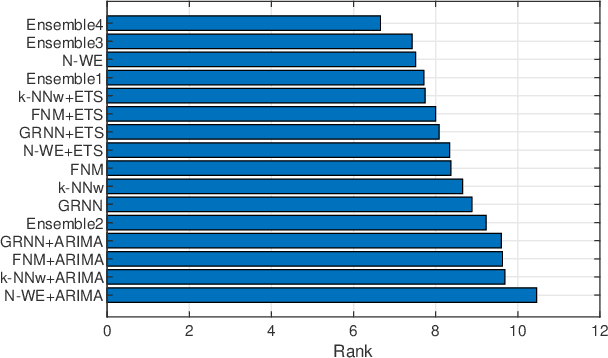
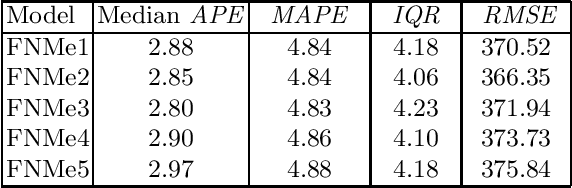
This work presents ensemble forecasting of monthly electricity demand using pattern similarity-based forecasting methods (PSFMs). PSFMs applied in this study include $k$-nearest neighbor model, fuzzy neighborhood model, kernel regression model, and general regression neural network. An integral part of PSFMs is a time series representation using patterns of time series sequences. Pattern representation ensures the input and output data unification through filtering a trend and equalizing variance. Two types of ensembles are created: heterogeneous and homogeneous. The former consists of different type base models, while the latter consists of a single-type base model. Five strategies are used for controlling a diversity of members in a homogeneous approach. The diversity is generated using different subsets of training data, different subsets of features, randomly disrupted input and output variables, and randomly disrupted model parameters. An empirical illustration applies the ensemble models as well as individual PSFMs for comparison to the monthly electricity demand forecasting for 35 European countries.
Brain Emotional Learning-based Prediction Model For the Prediction of Geomagnetic Storms
Aug 01, 2020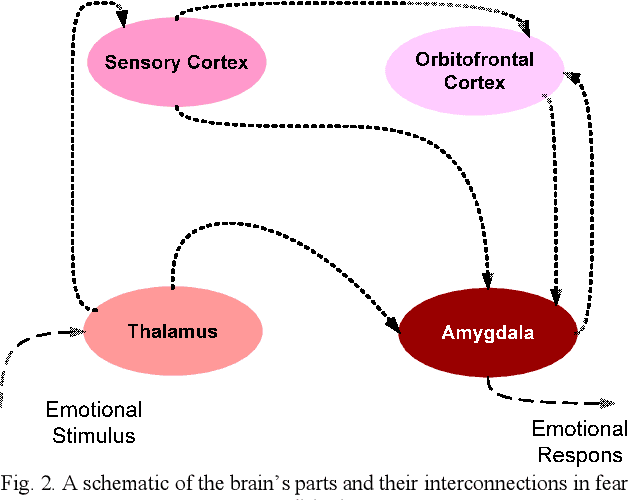
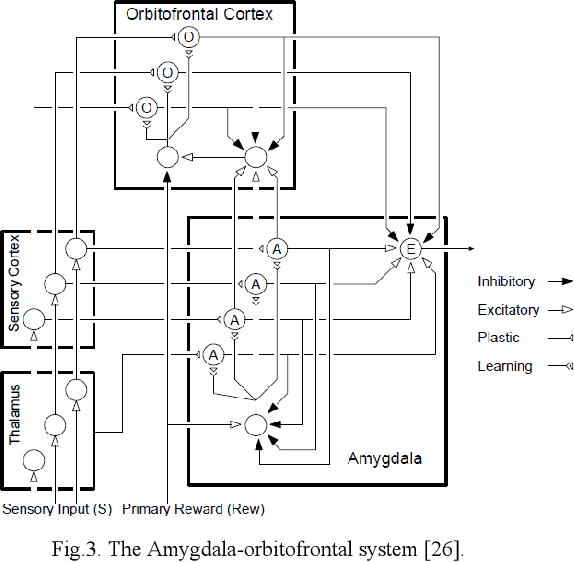
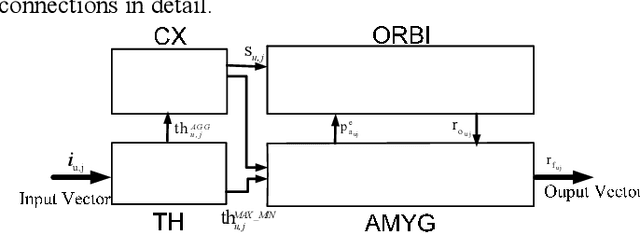
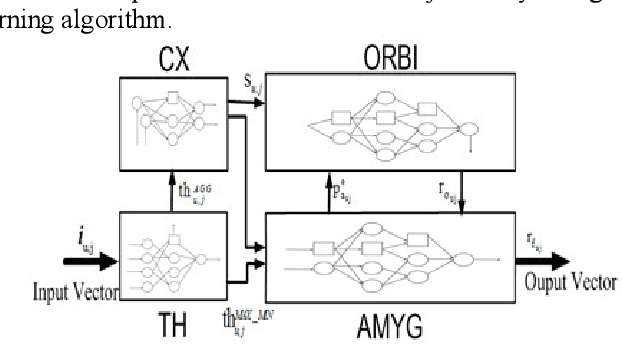
This study suggests a new data-driven model for the prediction of geomagnetic storm. The model which is an instance of Brain Emotional Learning Inspired Models (BELIMs), is known as the Brain Emotional Learning-based Prediction Model (BELPM). BELPM consists of four main subsystems; the connection between these subsystems has been mimicked by the corresponding regions of the emotional system. The functions of these subsystems are explained using adaptive networks. The learning algorithm of BELPM is defined using the steepest descent (SD) and the least square estimator (LSE). BELPM is employed to predict geomagnetic storms using two geomagnetic indices, Auroral Electrojet (AE) Index and Disturbance Time (Dst) Index. To evaluate the performance of BELPM, the obtained results have been compared with ANFIS, WKNN and other instances of BELIMs. The results verify that BELPM has the capability to achieve a reasonable accuracy for both the short-term and the long-term geomagnetic storms prediction.
Database Learning: Toward a Database that Becomes Smarter Every Time
Mar 28, 2017

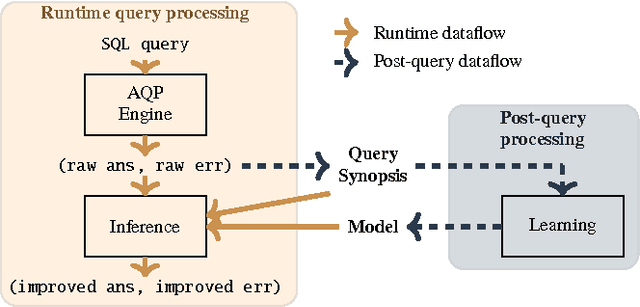
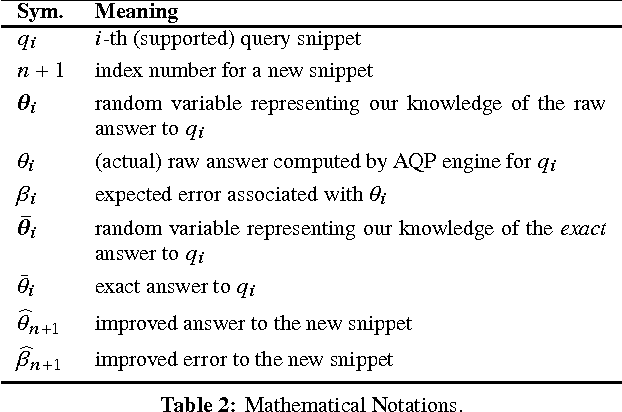
In today's databases, previous query answers rarely benefit answering future queries. For the first time, to the best of our knowledge, we change this paradigm in an approximate query processing (AQP) context. We make the following observation: the answer to each query reveals some degree of knowledge about the answer to another query because their answers stem from the same underlying distribution that has produced the entire dataset. Exploiting and refining this knowledge should allow us to answer queries more analytically, rather than by reading enormous amounts of raw data. Also, processing more queries should continuously enhance our knowledge of the underlying distribution, and hence lead to increasingly faster response times for future queries. We call this novel idea---learning from past query answers---Database Learning. We exploit the principle of maximum entropy to produce answers, which are in expectation guaranteed to be more accurate than existing sample-based approximations. Empowered by this idea, we build a query engine on top of Spark SQL, called Verdict. We conduct extensive experiments on real-world query traces from a large customer of a major database vendor. Our results demonstrate that Verdict supports 73.7% of these queries, speeding them up by up to 23.0x for the same accuracy level compared to existing AQP systems.
Bipartite Distance for Shape-Aware Landmark Detection in Spinal X-Ray Images
May 28, 2020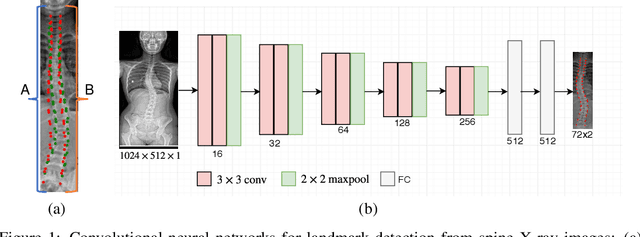
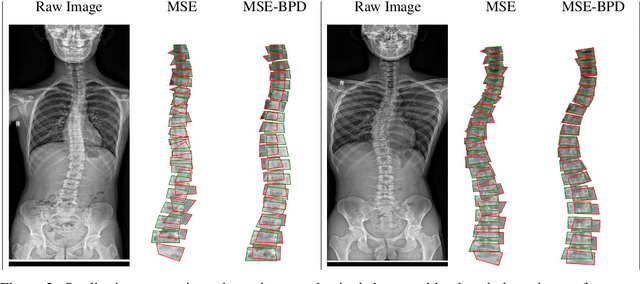
Scoliosis is a congenital disease that causes lateral curvature in the spine. Its assessment relies on the identification and localization of vertebrae in spinal X-ray images, conventionally via tedious and time-consuming manual radiographic procedures that are prone to subjectivity and observational variability. Reliability can be improved through the automatic detection and localization of spinal landmarks. To guide a CNN in the learning of spinal shape while detecting landmarks in X-ray images, we propose a novel loss based on a bipartite distance (BPD) measure, and show that it consistently improves landmark detection performance.
Extending the Hint Factory for the assistance dilemma: A novel, data-driven HelpNeed Predictor for proactive problem-solving help
Oct 08, 2020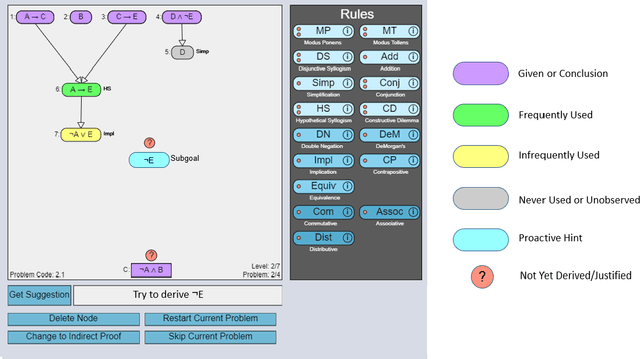
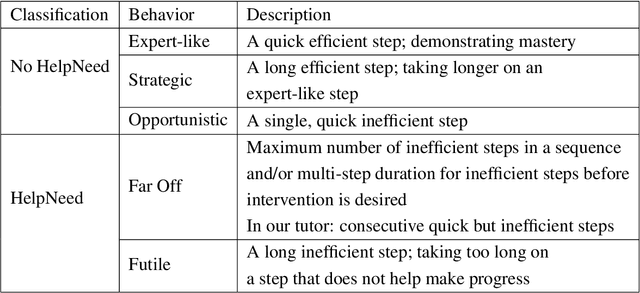
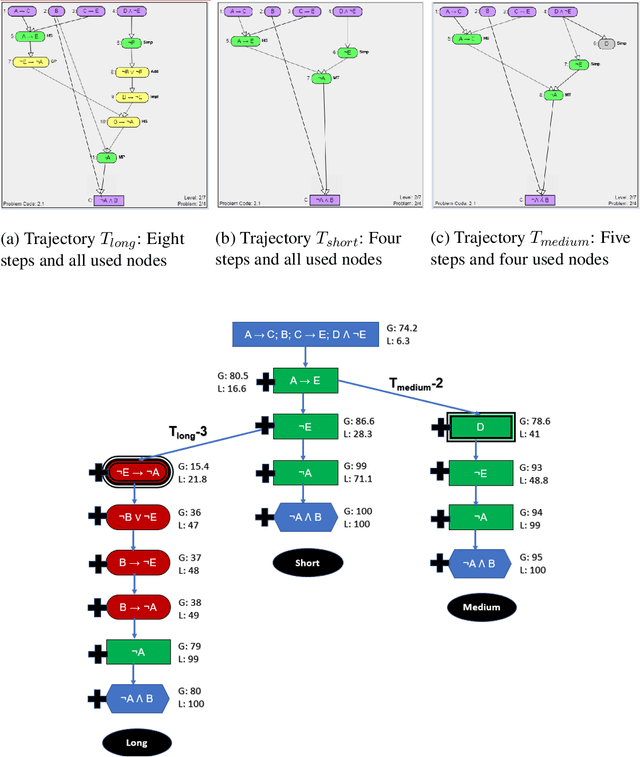

Determining when and whether to provide personalized support is a well-known challenge called the assistance dilemma. A core problem in solving the assistance dilemma is the need to discover when students are unproductive so that the tutor can intervene. Such a task is particularly challenging for open-ended domains, even those that are well-structured with defined principles and goals. In this paper, we present a set of data-driven methods to classify, predict, and prevent unproductive problem-solving steps in the well-structured open-ended domain of logic. This approach leverages and extends the Hint Factory, a set of methods that leverages prior student solution attempts to build data-driven intelligent tutors. We present a HelpNeed classification, that uses prior student data to determine when students are likely to be unproductive and need help learning optimal problem-solving strategies. We present a controlled study to determine the impact of an Adaptive pedagogical policy that provides proactive hints at the start of each step based on the outcomes of our HelpNeed predictor: productive vs. unproductive. Our results show that the students in the Adaptive condition exhibited better training behaviors, with lower help avoidance, and higher help appropriateness (a higher chance of receiving help when it was likely to be needed), as measured using the HelpNeed classifier, when compared to the Control. Furthermore, the results show that the students who received Adaptive hints based on HelpNeed predictions during training significantly outperform their Control peers on the posttest, with the former producing shorter, more optimal solutions in less time. We conclude with suggestions on how these HelpNeed methods could be applied in other well-structured open-ended domains.
Context-Dependent Implicit Authentication for Wearable Device User
Aug 25, 2020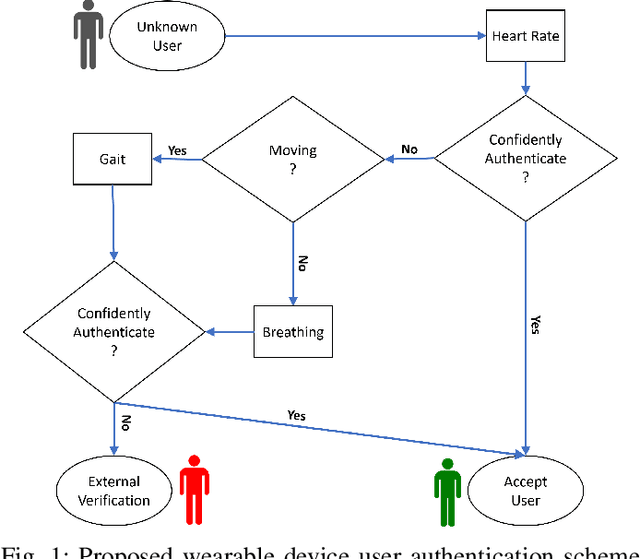
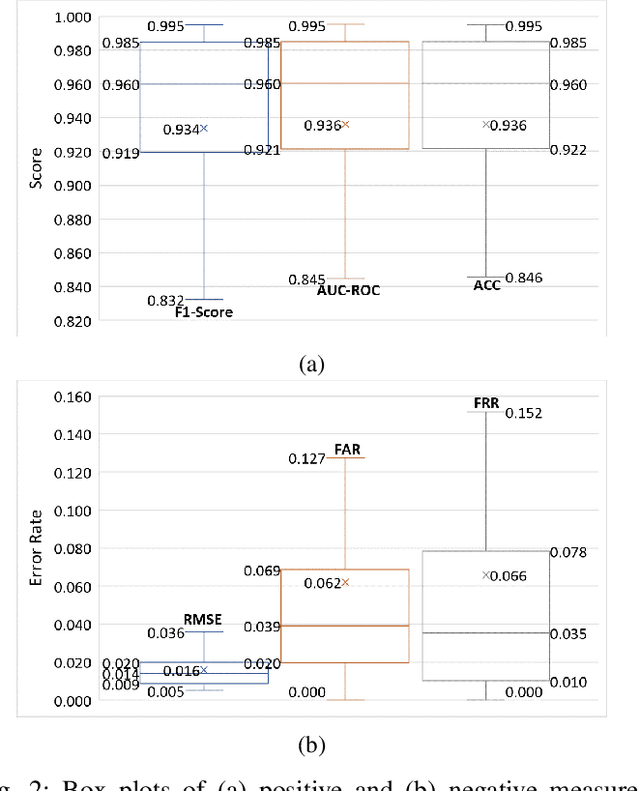
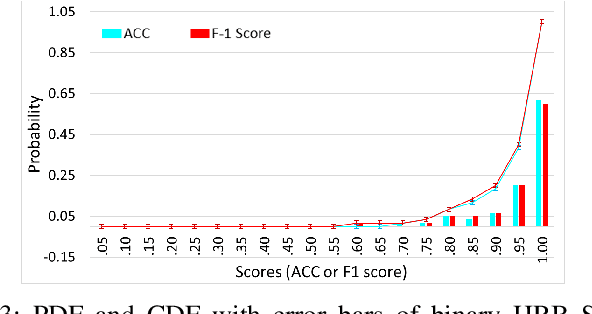
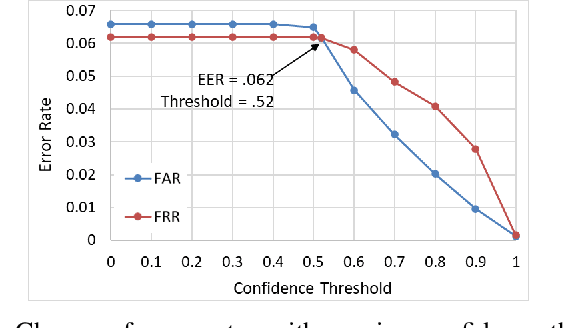
As market wearables are becoming popular with a range of services, including making financial transactions, accessing cars, etc. that they provide based on various private information of a user, security of this information is becoming very important. However, users are often flooded with PINs and passwords in this internet of things (IoT) world. Additionally, hard-biometric, such as facial or finger recognition, based authentications are not adaptable for market wearables due to their limited sensing and computation capabilities. Therefore, it is a time demand to develop a burden-free implicit authentication mechanism for wearables using the less-informative soft-biometric data that are easily obtainable from the market wearables. In this work, we present a context-dependent soft-biometric-based wearable authentication system utilizing the heart rate, gait, and breathing audio signals. From our detailed analysis, we find that a binary support vector machine (SVM) with radial basis function (RBF) kernel can achieve an average accuracy of $0.94 \pm 0.07$, $F_1$ score of $0.93 \pm 0.08$, an equal error rate (EER) of about $0.06$ at a lower confidence threshold of 0.52, which shows the promise of this work.
A Hybrid Residual Dilated LSTM end Exponential Smoothing Model for Mid-Term Electric Load Forecasting
Mar 29, 2020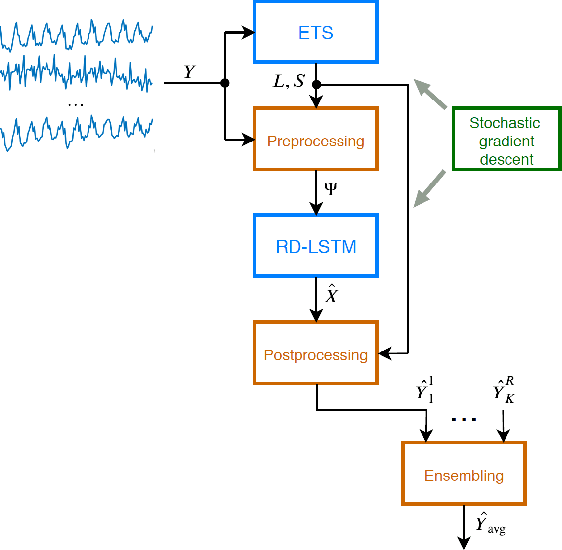
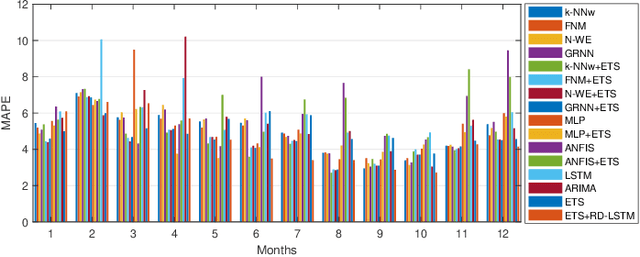
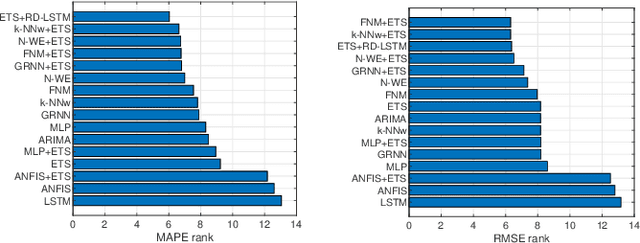
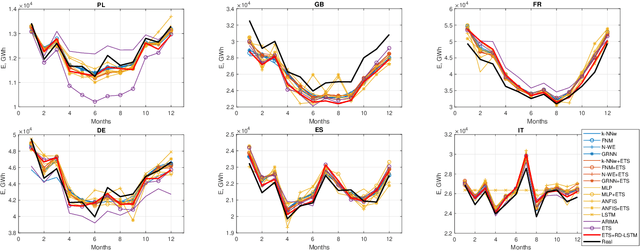
This work presents a hybrid and hierarchical deep learning model for mid-term load forecasting. The model combines exponential smoothing (ETS), advanced Long Short-Term Memory (LSTM) and ensembling. ETS extracts dynamically the main components of each individual time series and enables the model to learn their representation. Multi-layer LSTM is equipped with dilated recurrent skip connections and a spatial shortcut path from lower layers to allow the model to better capture long-term seasonal relationships and ensure more efficient training. A common learning procedure for LSTM and ETS, with a penalized pinball loss, leads to simultaneous optimization of data representation and forecasting performance. In addition, ensembling at three levels ensures a powerful regularization. A simulation study performed on the monthly electricity demand time series for 35 European countries confirmed the high performance of the proposed model and its competitiveness with classical models such as ARIMA and ETS as well as state-of-the-art models based on machine learning.